


Apache Beam: a unified programming model for data processing pipelines

May 24, 2018
- Categories
- Data Engineering
- DataWorks Summit 2018
- Tags
- Apex
- Beam
- Pipeline
- Flink
- Spark [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
In this article, we will review the concepts, the history and the future of Apache Beam, that may well become the new standard for data processing pipelines definition.
At Dataworks Summit 2018 in Berlin, I attended the conference Present and future of unified, portable and efficient data processing with Apache Beam by Davor Bonaci, V.P. of Apache Beam and previously working on Google Cloud Dataflow. This conference piqued my curiosity and led me to write this article which is divided into 2 parts:
- The concepts behind Apache Beam that were briefly exposed in the conference;
- The presentation of Beam itself, with a bit of history, current state, and future of the project.
The concepts behind Apache Beam
Before talking about Beam itself, we will explore the concepts that it implements. This introduction is based on two articles written by Tyler Akidau (Streaming 101 and Streaming 102), Tech Lead for Data Processing Languages & Systems group at Google. He is one of the main authors of the Dataflow modelpaper, on which is based Google Cloud Dataflow, the predecessor of Apache Beam.
Streaming
First, let’s see what streaming means when talking about data processing.
A type of data processing engine that is designed with infinite data sets in mind
— Tyler Akidau
Streaming can be characterized by:
- Unbounded data sets (in opposition to finite data sets);
- Unbounded data processing (in time);
- Low-latency, approximate and/or speculative results.
Because of their approximate results, streaming systems were often put in conjunction with more capable batch systems that delivered the correct results. The Lambda Architecture is a good example of this idea. It is composed of two systems:
- A streaming system that provides low-latency, inaccurate results;
- A batch system that provides correct results later on.
The Lambda Architecture works well but is introducing a maintenance problem: you have to build, provision, and maintain two versions of the data pipeline and merge the results.
To reduce the complexity of the architecture, Jay Kreps merged the streaming and batch layers to define the Kappa Architecture. This architecture is made of single pipeline applying successive data transformations and uses a data storage capable of both streaming and storing data (e.g. Apache Kafka).
Tyler Akidau takes things a step further by questioning the need for batch systems as they exist today. For him, streaming systems need only two things to beat batch:
- Correctness, which is brought by exactly-once processing and therefore consistent partition tolerant storage (to be sure of what data has already been processed);
- Tools for reasoning about time, for dealing with unbounded, unordered data of varying event-time skew.
New data will arrive, old data may be retracted or updated, and any system we build should be able to cope with these facts on its own, with notions of completeness being a convenient optimization rather than a semantic necessity.
— Tyler Akidau
Tyler Akidau’s team defined a model for this kind of data processing, on which is based Google Cloud Dataflow, as well as Apache Beam: the Dataflow model.
Vocabulary
To understand the Dataflow model, we have to introduce a few keywords.
Event time vs. processing time
When processing data, the two domains of time to care about are:
- Event time, the time at which an event actually occurred;
- Processing time, the time at which the event is observed in the system.
In real life, the skew between event time and processing time is highly variable (due to hardware resources, software logic, emission of data itself):
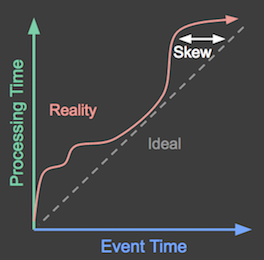
Windows
To process an unbounded data set, it is necessary to split it into finite pieces. These finite data chunks are called windows. Windows are defined by a length and a period:
- Fixed windows: fixed and equal length and period;
- Sliding windows: fixed length and period but the period can be less than the length (leading to overlapping);
- Sessions: neither the length nor the period is fixed. The windows are defined by sequences of events separated by gaps of inactivity.
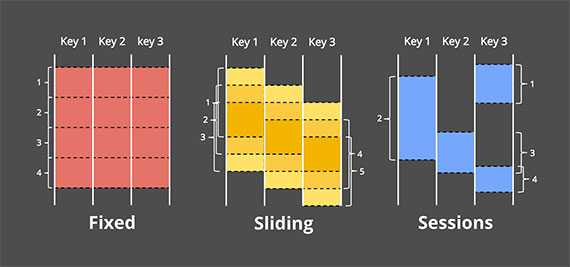
When defining the temporal boundaries of a window, we have two options:
- Rely on the processing time, as many existing systems do, but then some data will end up in the wrong processing windows (because of the skew between event time and processing time);
- Rely on the event time, but this is actually not possible because you cannot know that all the data that occurred within a time window has been observed.
Watermark
A watermark links an event time E to a processing time P with the statement: “at time P, all data generated prior to E have been observed”. The watermark depends on the data source and we set it regarding our knowledge of the data. With Apache Beam, the calculation of the watermark is done by the system, refining as data is processed.
Trigger
A trigger defines when the output should be materialized for a window. If we set multiple triggers, we end up with multiple results. These results can be speculative if they are calculated before all the data is observed.
The Dataflow model
The Dataflow model allows to define data pipelines by answering 4 questions:
- What results are calculated?
- Where in event time are results calculated?
- When in processing time are results materialized?
- How do refinements of results relate?
To better understand how these questions can be applied to a real-life use case, I will use the nice GIFS of one example provided on Apache Beam website. Tyler Akidau gives a more complex example which he links to Google Cloud DataflowSDK in his article Streaming 102.
What results are calculated?
In other words: what transformations are applied to the data?
Let’s say that we receive scores from different players and that we want to sum the scores made by each user within a day. This corresponds to one single transformation: sum by key (one key corresponding to one user). If we process data once a day, it will give us something like that:
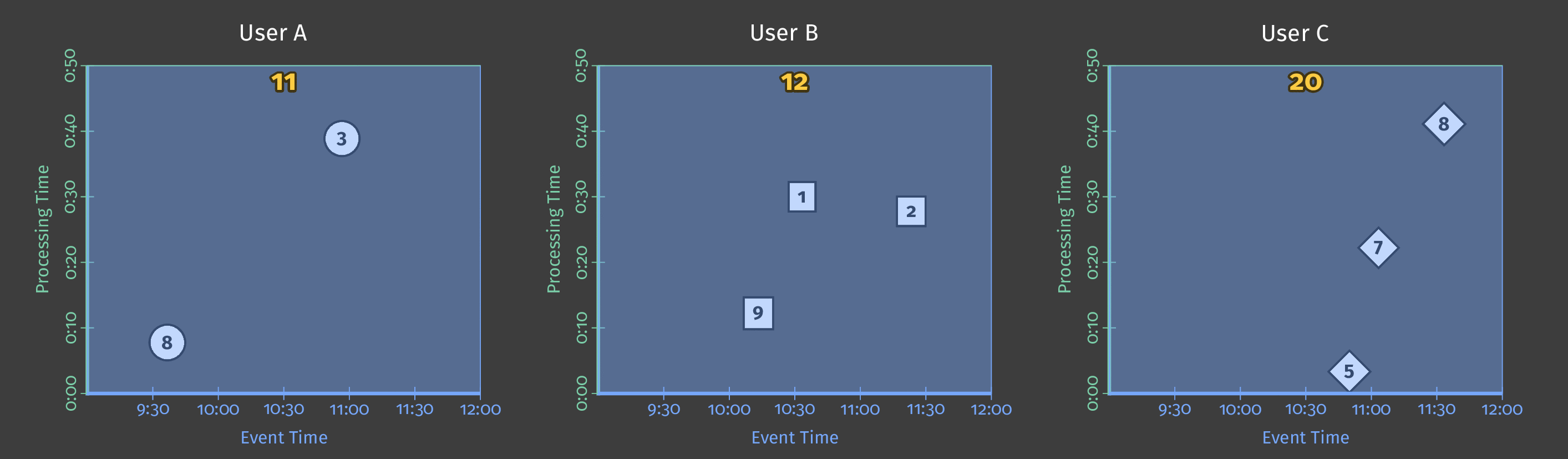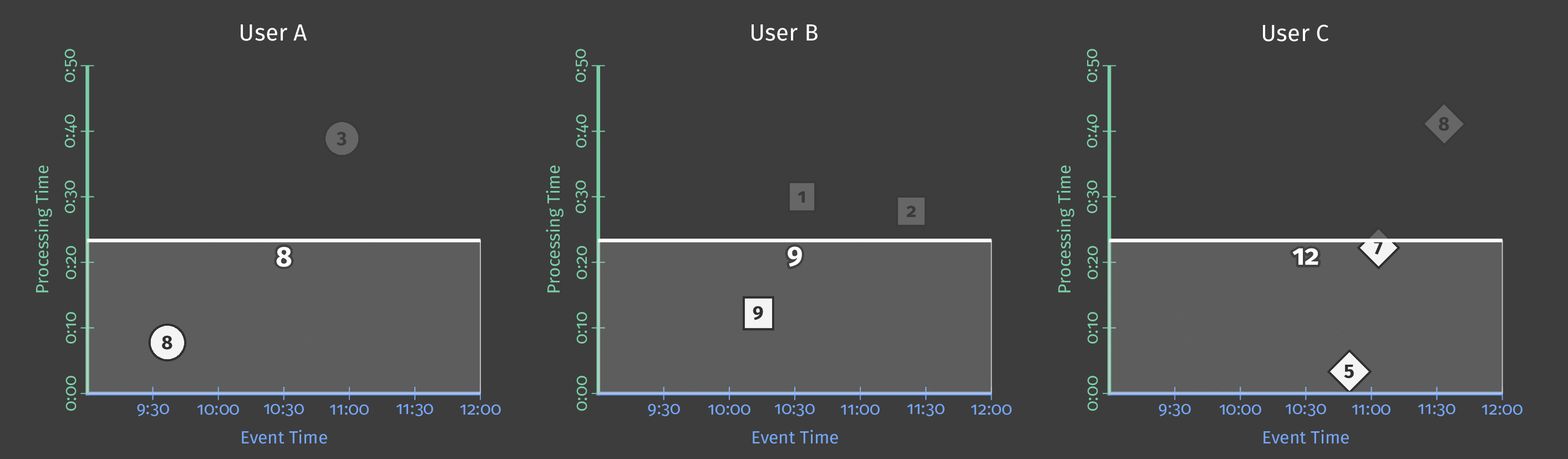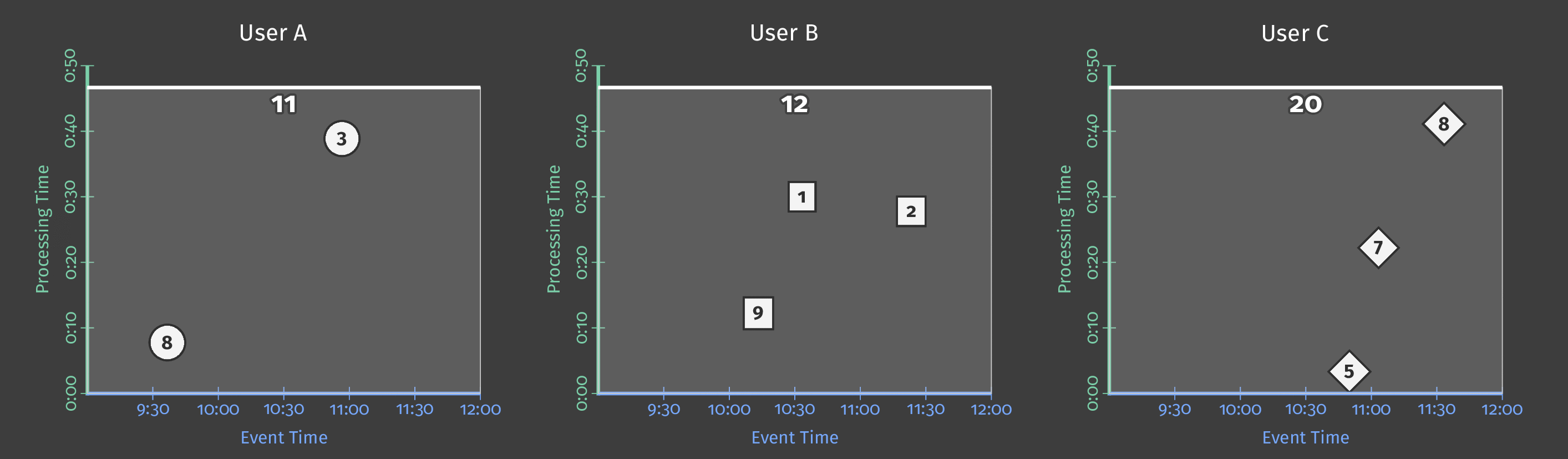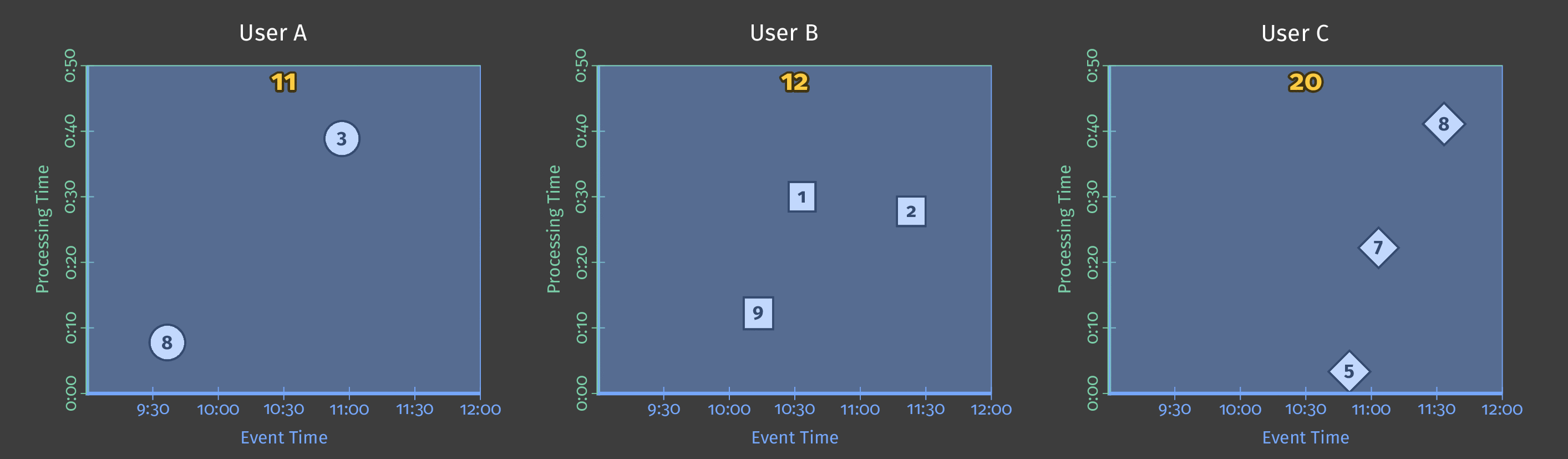
In this animation (and all the next ones in this articles), the data received are represented by circles, squares, and diamonds, the white line represents the progress of the processing time and the results switch to yellow when they are materialized.
Here, we process all the data at one time and get a single result, which corresponds a classical batch processing.
Where in event time are results calculated?
In other words: what windows are used to split the data?
Let’s say that we now want the sum of each user’s scores for every hour. For that, we define a fixed window of 1 hour in event time, and every window will give us a score sum:
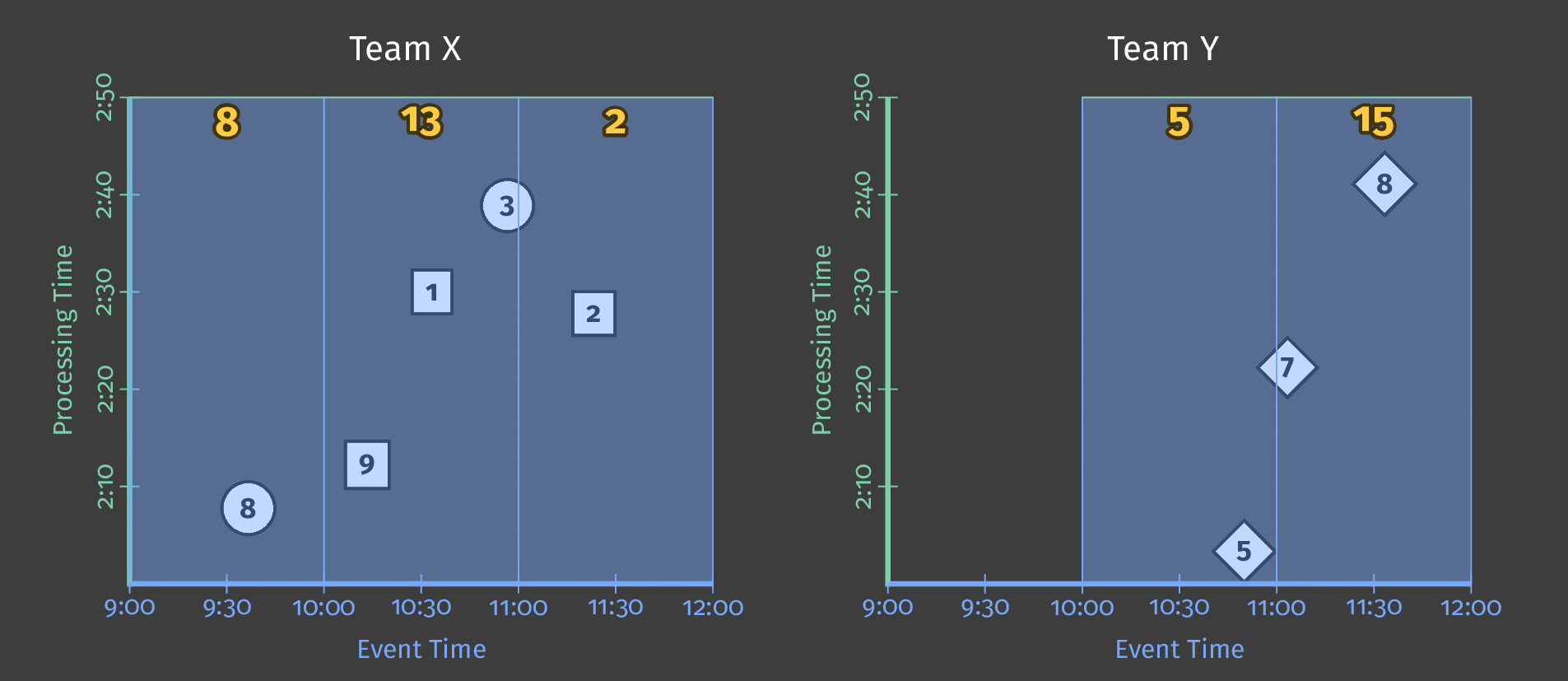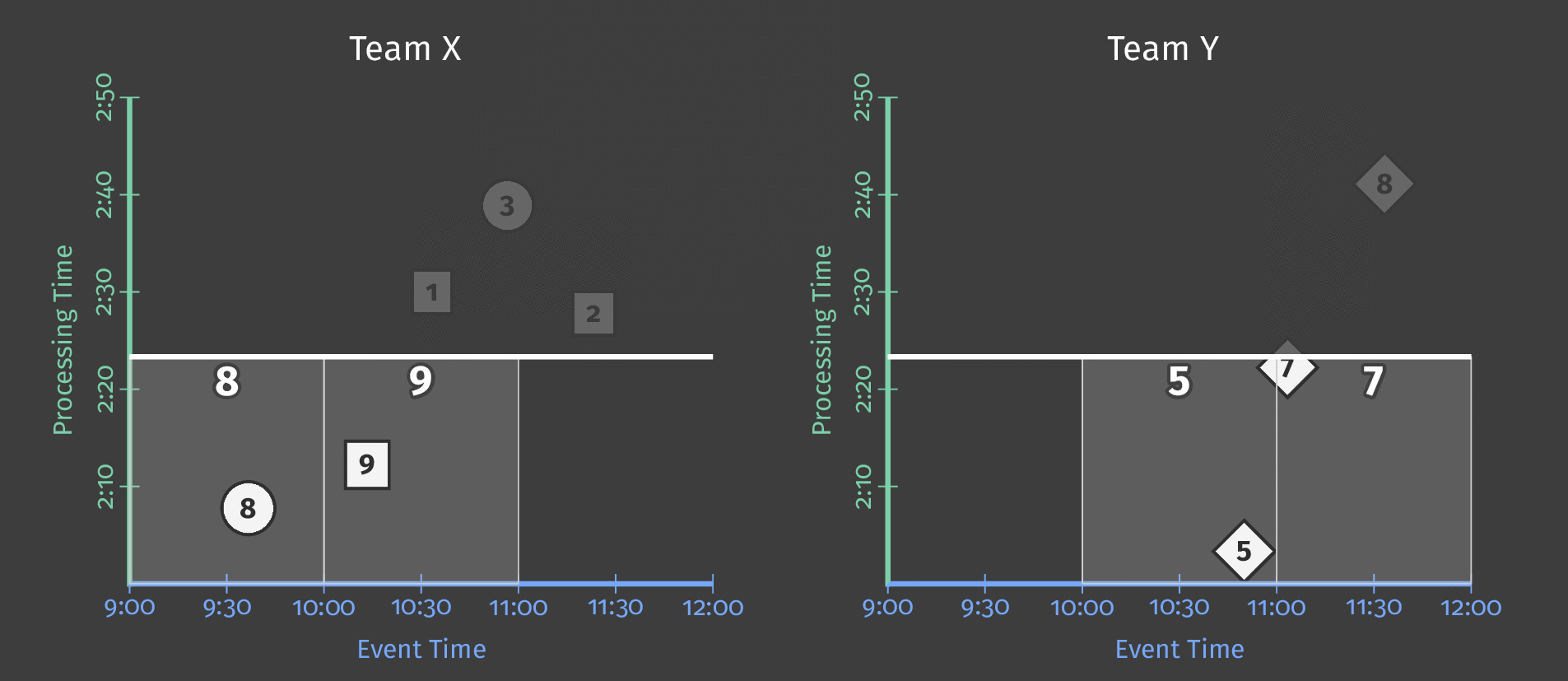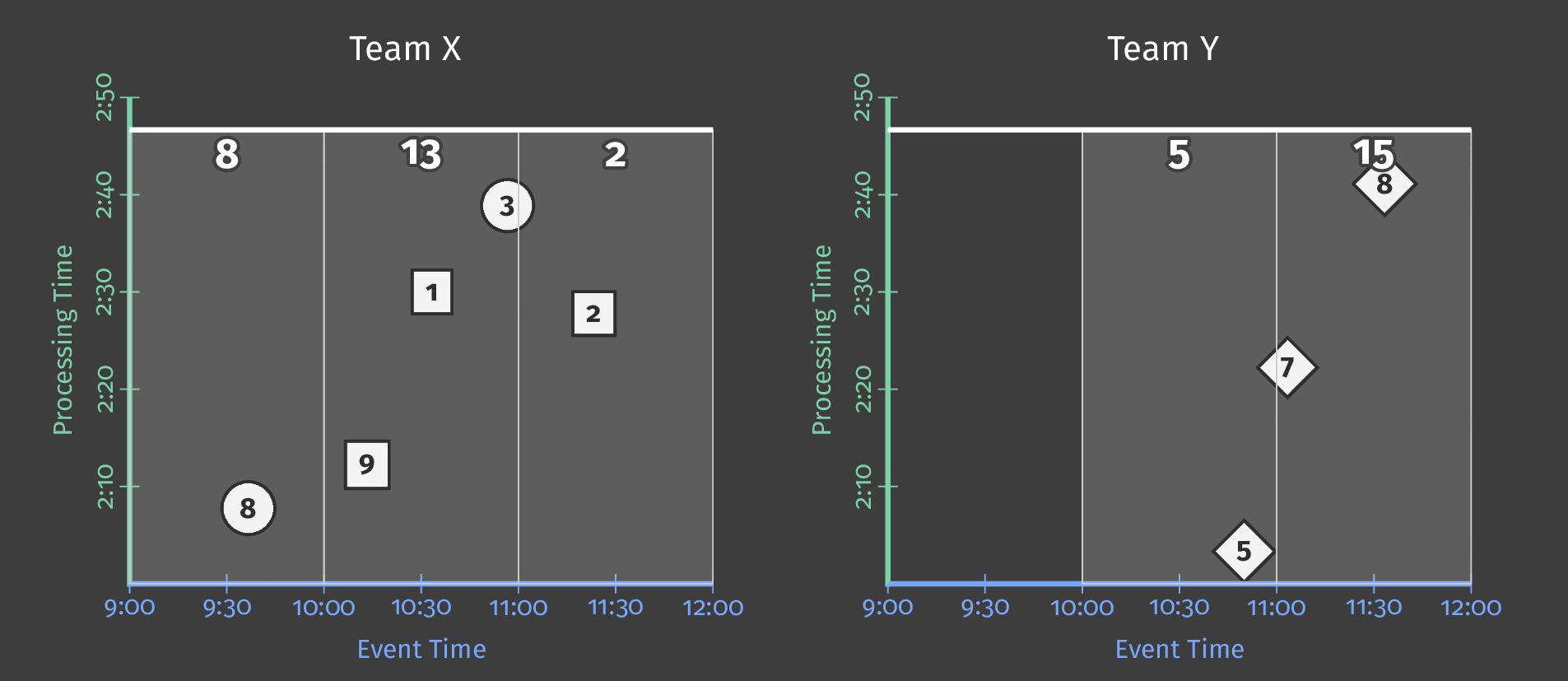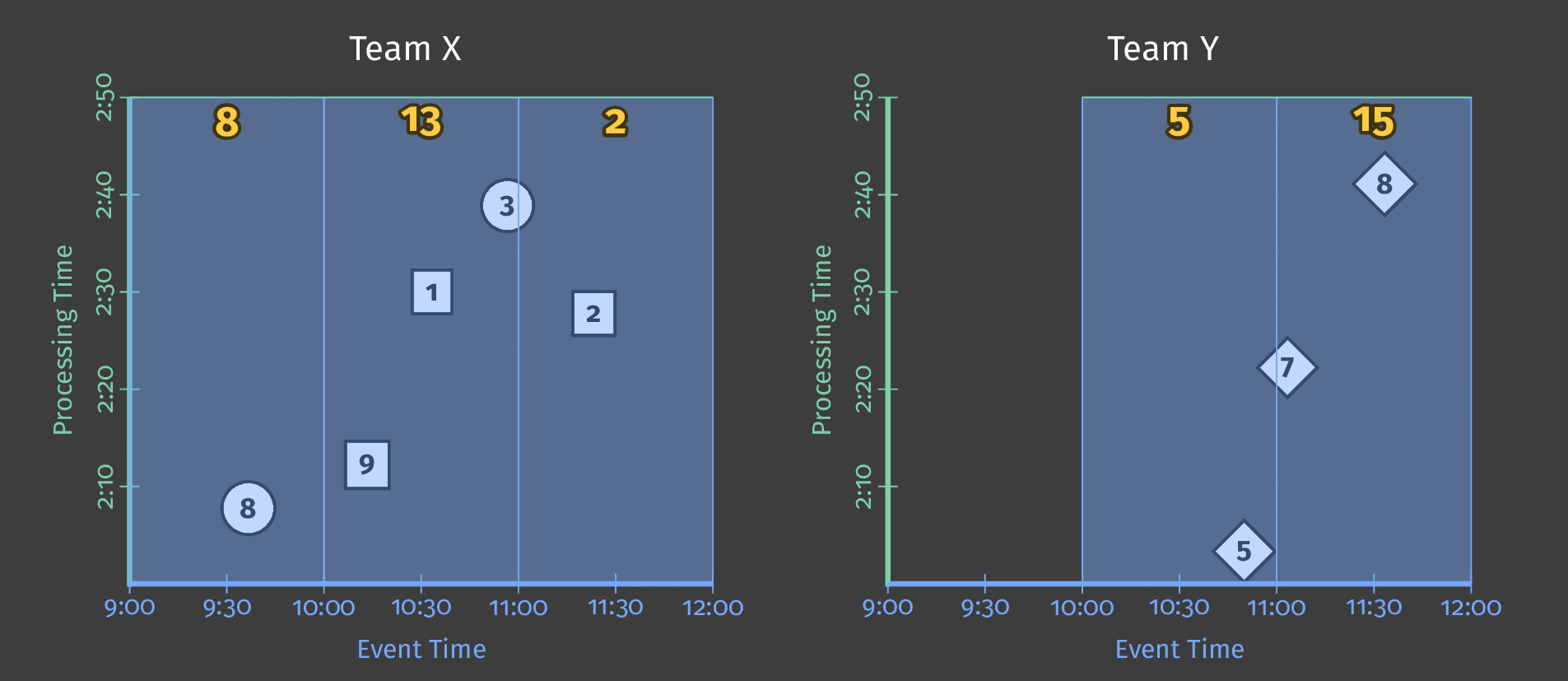
We are still in a batch processing pipeline because we wait for all the results before materializing the results, but we get 3 independent results.
When in processing time are results materialized?
In other words: regarding what triggers will results be materialized?
If we want to switch from our batch pipeline to a steaming one, we will face a problem addressed earlier: we cannot be certain that all the data for a window has been observed.
That’s why we will use triggers that can be based on:
- Watermark progress, to provide a result that is likely the final result for a window (when the watermark matches the end of the window);
- Processing time progress, to provide regular periodic results (e.g. every 10 minutes);
- Element count, to provide results after N new elements have been observed (e.g. every 5 elements);
- Punctuations, to provide results when a special feature is detected in a record (e.g. an EOF element).
Here is an example of triggering the sum result every 10 minutes in processing time if a new element has been observed:
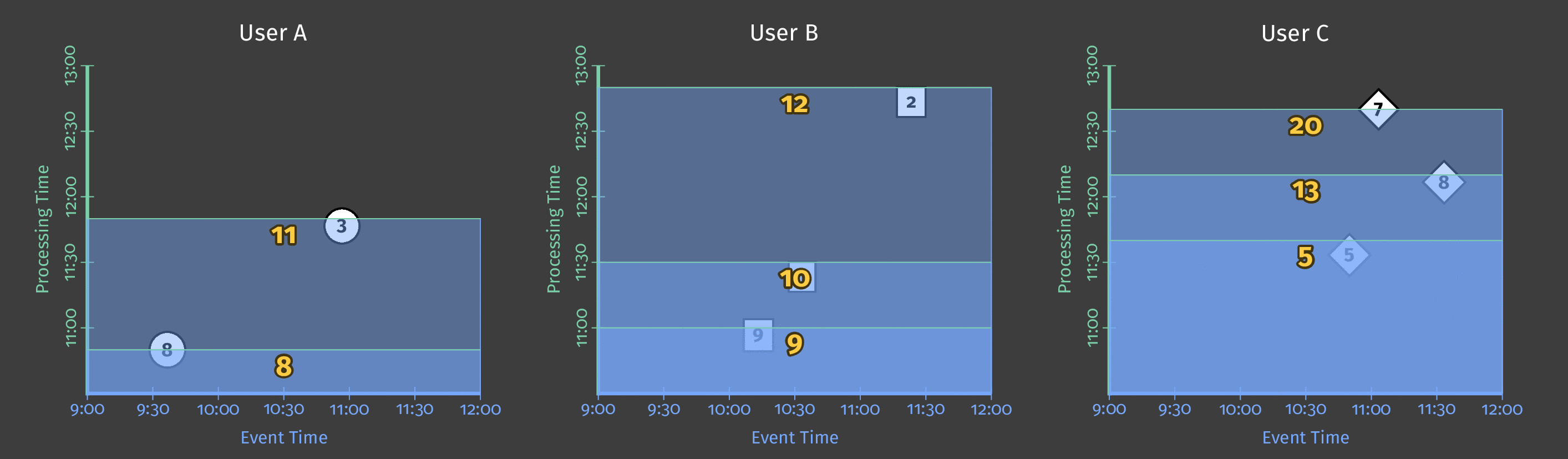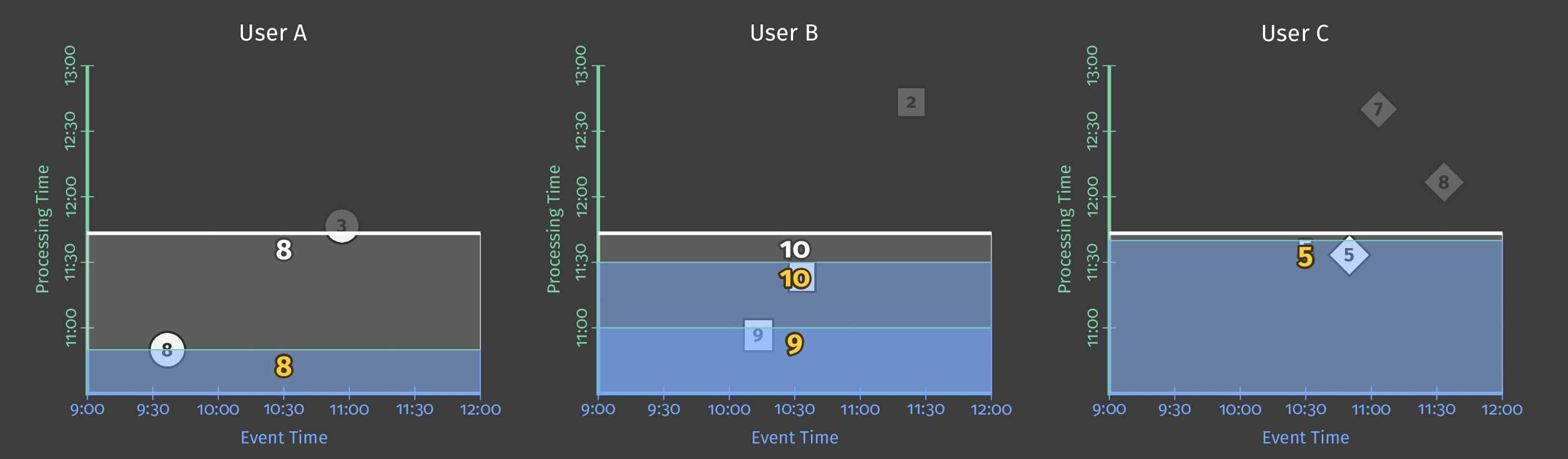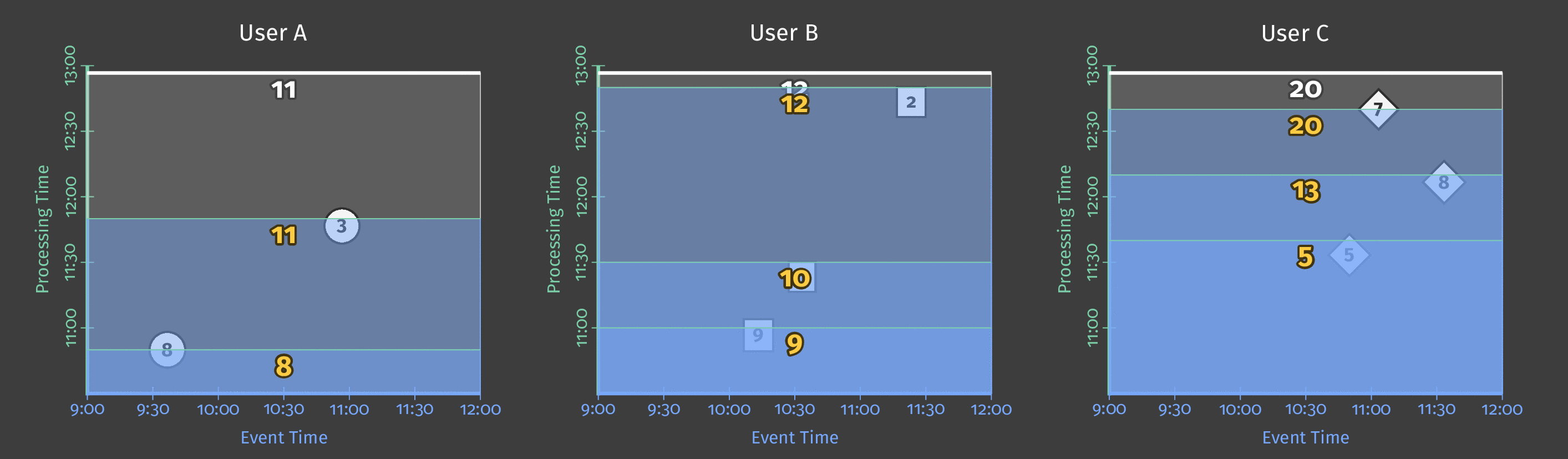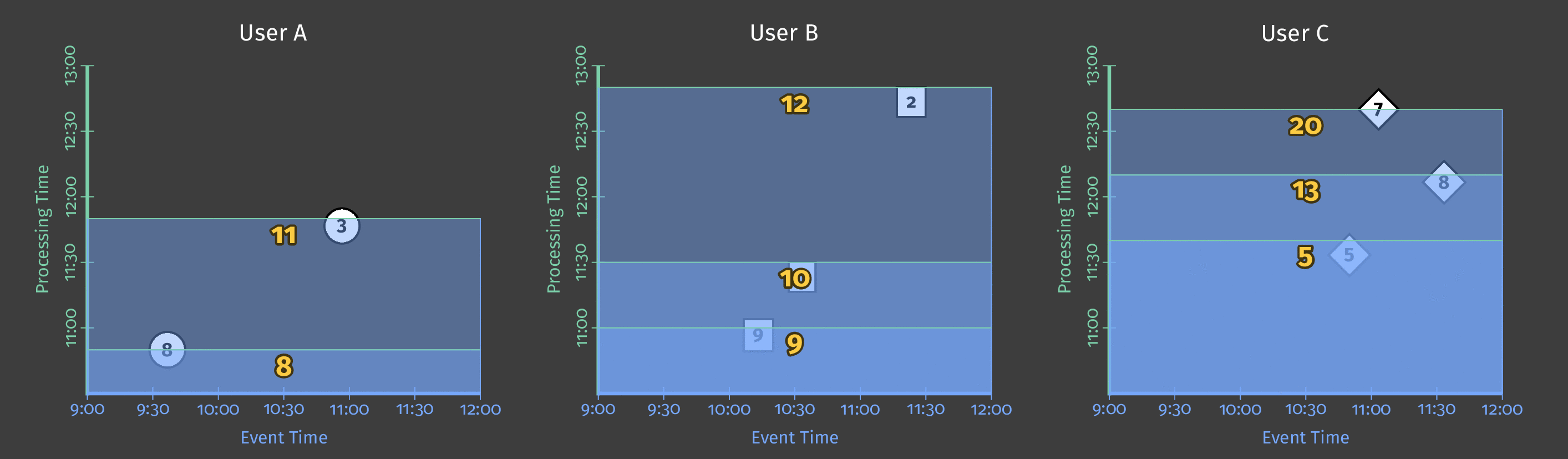
We can use multiple triggers in a data pipeline and define composite triggers (based on repetitions, conjunctions, sequences of other triggers).
The Dataflow model tags results in 3 categories regarding the watermark:
- Early when materialized before the watermark;
- On-time when materialized at the watermark;
- Late when materialized after the watermark.
In the animation below, we choose to trigger results at each new element observed (the watermark is drawn in green).
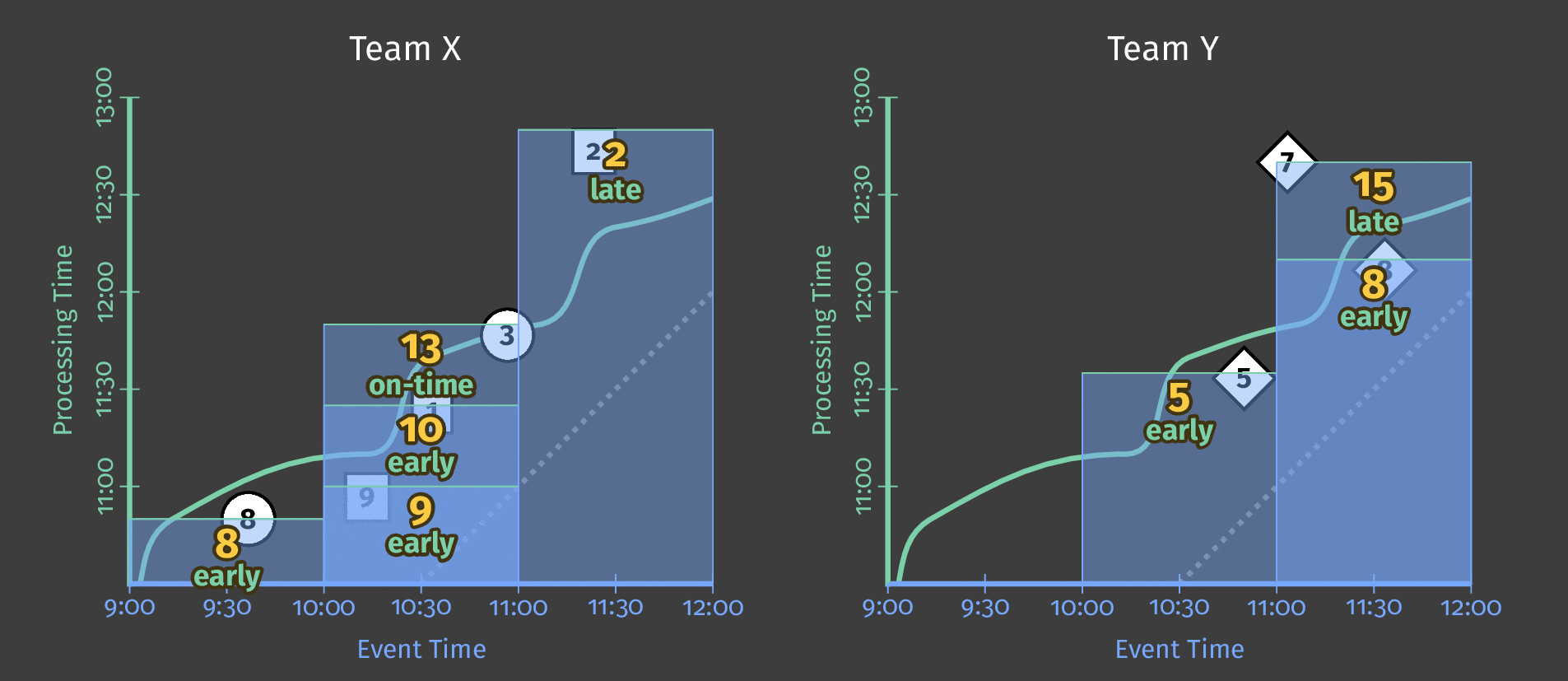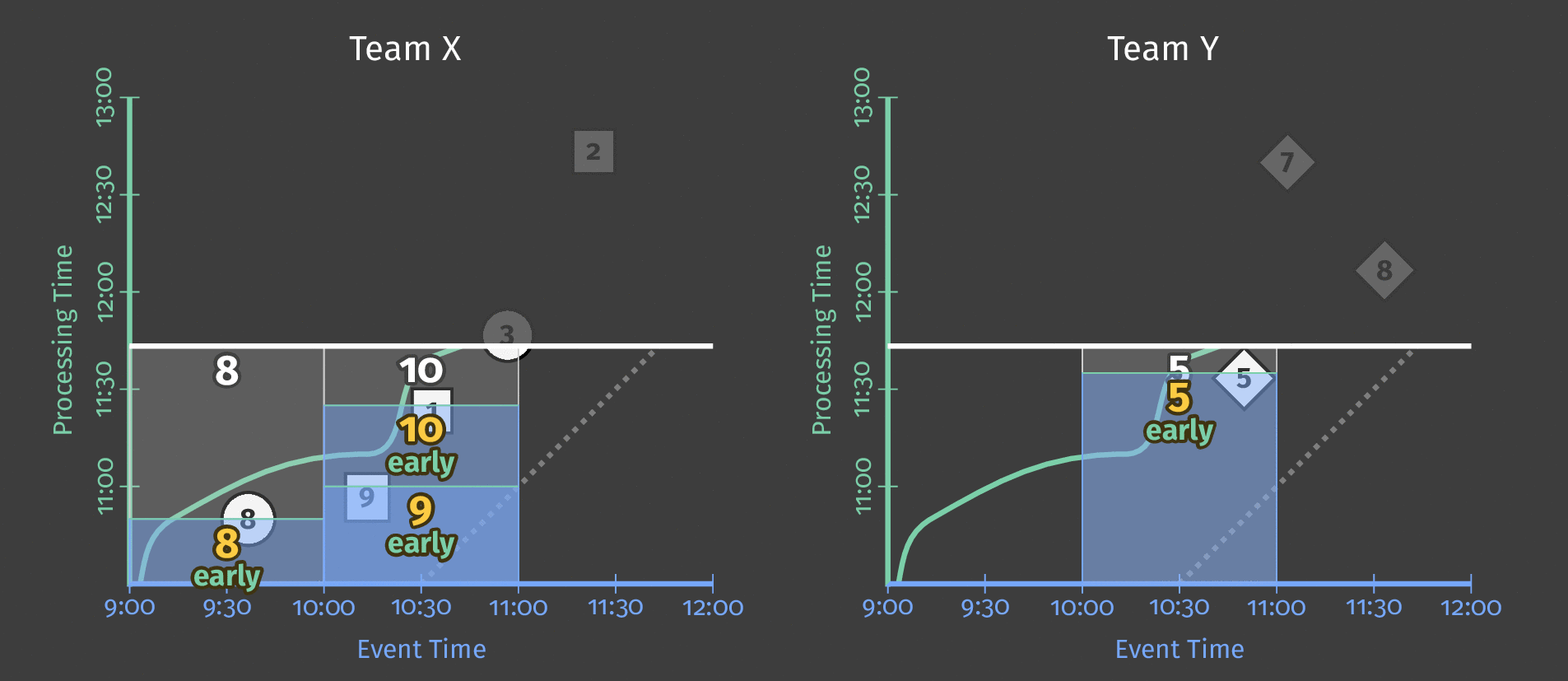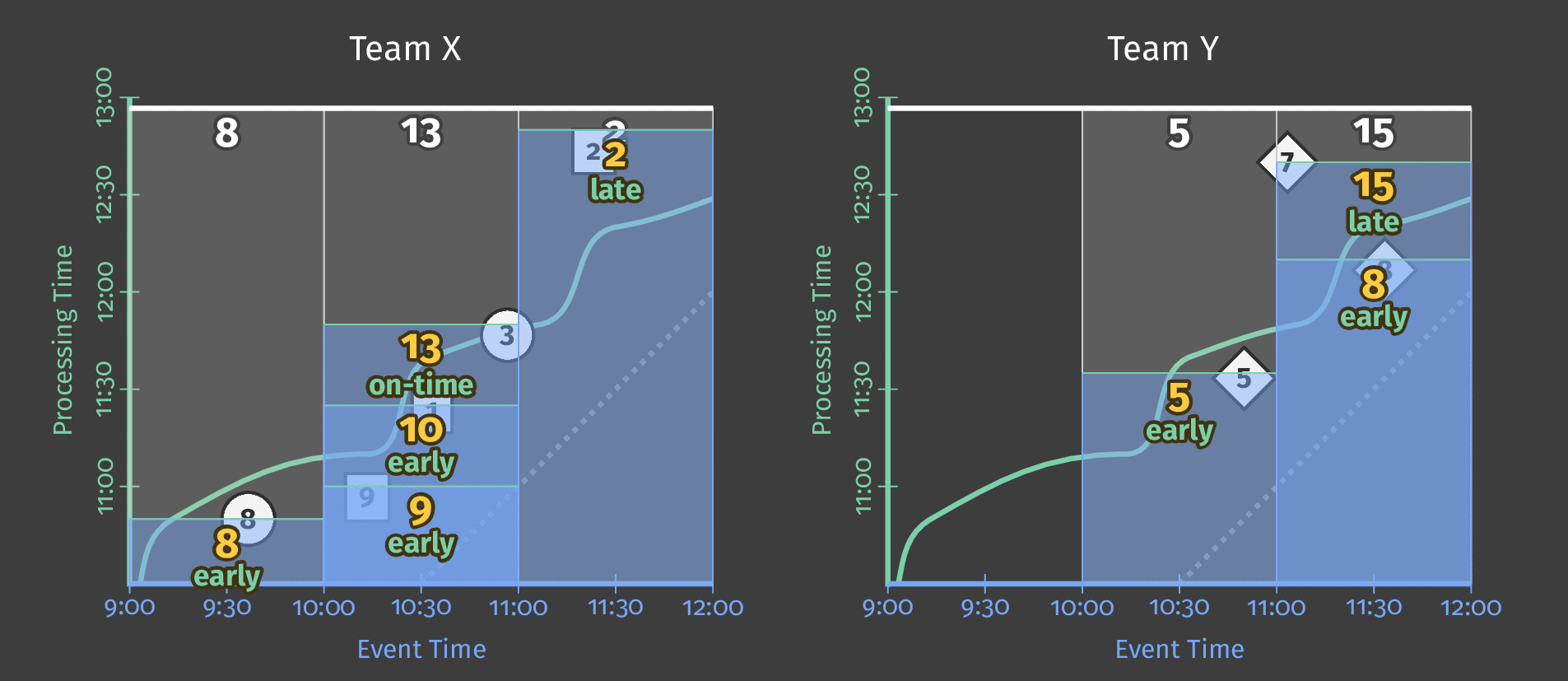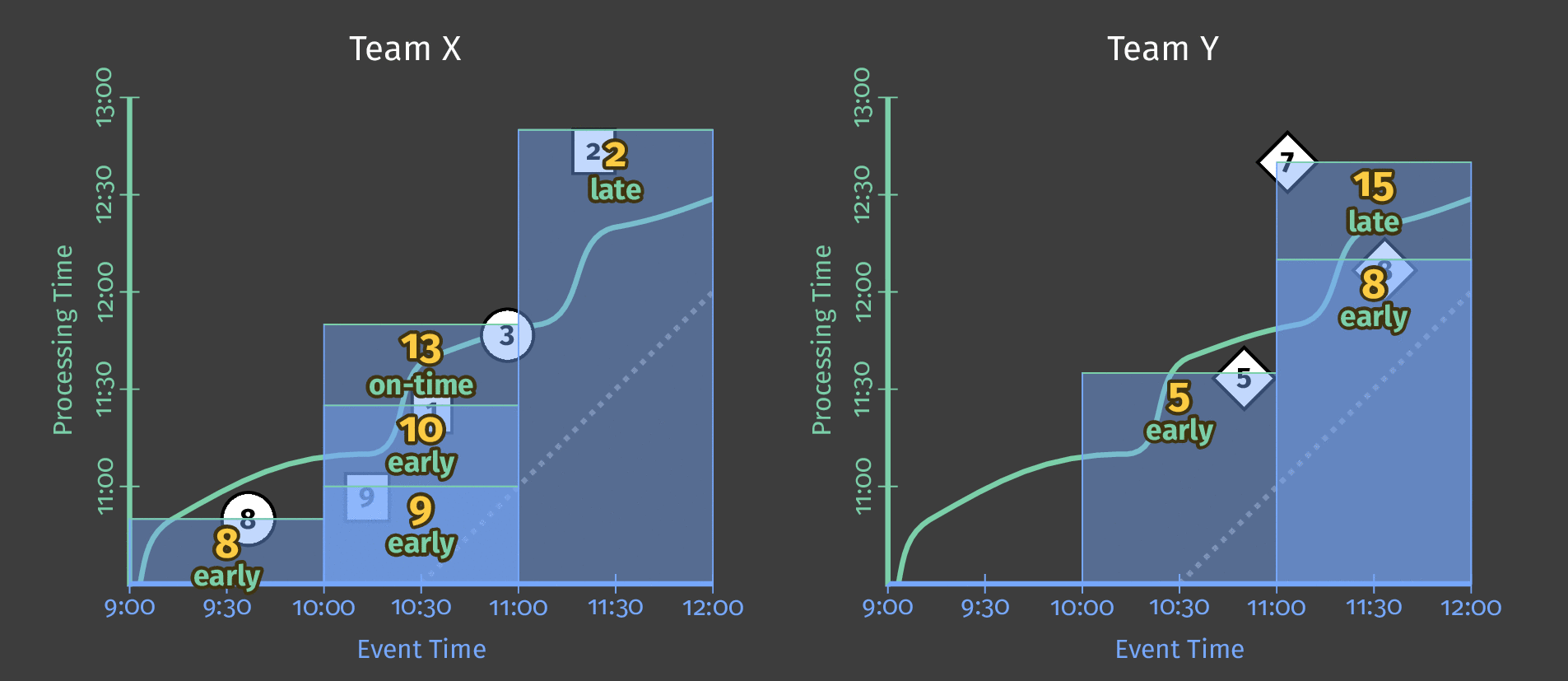
How do refinements of results relate?
In other words: what accumulation mode do we choose for the results?
The Dataflow model offers 3 accumulation modes for the multiple results of a window:
- Discarding: The current result doesn’t take into account the past ones. If we want to sum the results, we have to do it manually when we consume them.
- Accumulating: The current result accumulates all the past ones. In the case of summing, the last result of a window will be the total sum.
- Accumulating and discarding: The current result accumulates all the past ones but an independent retraction is produced for past results (“I previously told you the result was X, but I was wrong. Get rid of the X I told you last time and replace it with Y.”).
That’s it for the Dataflow model! If the Dataflow team is right, answering these 4 questions should allow describing every data pipeline, both for batch or streaming processing. If you want to dig deeper into the theoretical concepts of the Dataflow model, I invite you to read the articles of Tyler Akidau that are very well written (Streaming 101 and Streaming 102).
Apache Beam
Apache Beam aims to provide a portable standard for expressing robust, out-of-order data processing pipelines in a variety of languages across a variety of platforms.
Initiated by Google and widely backed
Apache Beam was founded in early 2016 when Google and other partners (contributors on Cloud Dataflow) made the decision to move the Google Cloud DataflowSDKs and runners to the Apache Beam Incubator. The reasons behind Google’s decision are well described by Tyler Akidau himself in the post Why Apache Beam.
A lot of organizations that support the legitimacy of the Beam model and contribute to Apache Beam’s development are data processing leaders like Talend (article) or data Artisans (article).
Very quickly, it became apparent to us that the Dataflow model […] is the correct model for stream and batch data processing. […] The Flink Datastream API […] faithfully implements the Beam model
— Kostas Tzoumas, CEO of data Artisans and founder of Apache Flink
This gives a lot of credibility to Apache Beam that became a Top-Level Apache Software Foundation Project on January 10, 2017.
Mix and match SDKs and runtimes
Near half of the conference given by Davor Bonaci in Berlin was actually about Beam’s vision: allow developers to easily express data pipelines based on the Beam model (=Dataflow model) and to choose between:
- multiple SDKs to write pipelines:
- Java
- Python (only on Google Cloud Dataflow runner for now)
- Go (experimental)
- multiple Runners to execute pipelines:
- Apache Apex
- Apache Flink
- Apache Spark
- Google Cloud Dataflow
- Apache Gearpump (edit: now retired)
Here is how we would write the data pipeline shown in Fig. 6 with the Java SDK:
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardHours(1)))
.triggering(
AtWatermark()
.withEarlyFirings(AtCount(1))
.withLateFirings(AtCount(1)))
.accumulatingPanes())
.apply(Sum.integersPerKey());Beam’s future
Given the strong confidence in the Beam model from the main data processing engines, it is likely that a lot of extensions to the Beam ecosystem will be developed in the next years (languages, runners, as well as DSLs, libraries, databases, etc). Davor Bonaci strongly encouraged to contribute to Beam if we miss pieces to integrate it into our environment.
Some of the Beam model concepts are not yet available with all the Beam runners as we can see in the capability matrix (especially for Spark that misses a lot of triggers’ types). Here again, the growing acceptance of Beam model should push the different runners to adapt their frameworks.
The Beam team and contributors are also working on the integration of new features like:
- Streaming analytics: analyze and perform actions on real-time data through the use of continuous queries;
- Complex Event Processing: match patterns of events in streams to detect important patterns in data and react to them. This feature would be inspired by the FlinkCEP library (JIRA).
Conclusion
We have seen that Apache Beam is a project that aims at unifying multiple data processing engines and SDKs around the Dataflow model, that offers a way to easily express any data pipeline. These characteristics make Beam a really ambitious project that could bring the biggest actors of data processing to build a new ecosystem sharing the same language, what has in fact already started.
References
- Streaming 101, Tyler Akidau, O’Reilly, https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
- Streaming 102, Tyler Akidau, O’Reilly, https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102
- The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing, Tyler Akidau, Robert Bradshaw, Craig Chambers, Slava Chernyak, Rafael J. Fernandez-Moctezuma, Reuven Lax, Sam McVeety, Daniel Mills, ´ Frances Perry, Eric Schmidt, Sam Whittle, http://www.vldb.org/pvldb/vol8/p1792-Akidau.pdf
- Apache Beam website, https://beam.apache.org/
- Apache Beam in 2017: Use Cases, Progress and Continued Innovation, Jean-Baptiste Onofre, Talend, https://www.talend.com/blog/2018/01/30/apache-beam-look-back-2017
- Why Apache Beam?, Kostas Tzoumas, data Artisans, https://data-artisans.com/blog/why-apache-beam
Images
- Figures 1, 2: Tyler Akidau
- Figures 3, 4, 5, 6: https://beam.apache.org/get-started/mobile-gaming-example/
