


Cloudera Sessions Paris 2017

16 oct. 2017
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Adaltas était présent le 5 octobre aux Cloudera Sessions, la journée de présentation des nouveaux produits Cloudera. Voici un compte rendu de ce que nous avons pu voir.
Note : les informations ont été aggrégées dans cet article avec le concours de David Worms (Adaltas), Axel Tifrani (Le Figaro) et Aargan Cointepas (Le Figaro). Vous trouverez également à la fin de l’article une liste de liens proposant des informations plus détaillées sur chacun des produits présentés.
Résumé
À l’occasion de cette journée, les équipes de Cloudera ont commencé par la présentation des nouveaux produits de la distribution avec pour objectif d’établir le cloud et les architectures hybrides (local / cloud) comme une alternative viable à un cluster Hadoop on-premise :
- Cloudera Shared Data Experience
- Cloudera Director
- Cloudera Altus
La suite fût consacrée à la Data Science soutenue par la présentation du Cloudera Data Science Workbench.
Lors de la matinée de keynotes et de présentations, nous avons également assisté à une table ronde sur les tenants et aboutissants de la transition vers le Big Data en entreprise.
Enfin, nous avons eu l’occasion de discuter avec les équipes d’HPE sur les architectures hybrides (hardware) de calcul qui commencent à se démocratiser en entreprise.
Produits
Voici ce que nous avons retenu de ces différents produits :
Cloudera Director
Director a déjà été présenté l’année dernière et était donc moins en lumière cette année, cependant il s’inscrit dans la démarche de promotion du cloud et a donc tout son sens ici.
Il s’agit d’un composant de la suite entreprise au même titre que Navigator ou Manager, permettant de déployer et gérer en quelques clics un ou plusieurs clusters CDH sur les plateformes de cloud publique (AWS & Azure, Google Cloud n’est que partiellement couvert) et privé (RedHat OpenStack et VMWare) avec un Cloudera Manager fonctionnel. Une fois un cluster installé, on peut ajouter ou retirer des noeuds à la volée.
Director permet de complètement s’affranchir des interfaces et consoles habituelles des multiples plateformes de cloud et de la préparation des machines pour des instances Hadoop.
Un détail intéressant donné par le présentateur, l’infrastructure hardware mise en place par Cloudera pour tester et valider des solutions et pour s’assurer de leur validité s’appuie sur des clusters de 1000 noeuds. Ce fut par exemple le cas pour les tests menés sur la plateforme RedHat OpenStack.
Cloudera Altus
Altus était le produit phare de la journée car il s’agit du premier service Cloudera en Platform-as-a-Service (PAAS) !
Il s’agit d’un service permettant de créer à la volée chez un provider de cloud publique un cluster Hadoop avec une distribution CDH, y déployer et exécuter un job traitant des données d’un cluster existant (ou d’autres sources comme S3), puis supprimer (ou réutiliser pour un autre job) ledit serveur. Cela permet de venir jouer sur le tableau de service tel qu’Amazon EMR couplé à des EC2 spot instance tout en restant dans l’écosystème Cloudera.

Pour les personnes qui ne sont pas familières avec les services AWS, EMR est un service permettant de créer un cluster Hadoop sur des instances EC2 et les EC2 spot instances permettent de participer à des enchères sur les instances EC2 non utilisées afin de les avoir à un meilleur prix. Cela permet de répondre au cas “que faire si j’ai besoin de traiter un job rapide mais que mon cluster est déjà plein ?”, il suffit de créer un cluster temporaire !
À noter que j’utilise les services AWS pour illustrer mon propos, cependant Azure est aussi supporté à 100%.
Contrairement à Director qui cible les Administrateurs Hadoop, Altus a pour vocation d’être utilisé par des développeurs ou des Data Analystes.
Architecture
Altus est une plateforme “as-a-service” (PAAS), elle est donc portée par les serveurs de Cloudera avec des accès en web via une interface de gestion, en CLI ou en API.
Pour pouvoir gérer la plateforme cloud et l’accès au cluster existant, le service nécessite :
- D’avoir des droits create / delete sur les instances cloud
- D’avoir des droits R/W sur le cluster existant et donc d’accéder à votre infrastructure. Cela peut se faire en automatisé ou en manuel via un tutoriel simple.
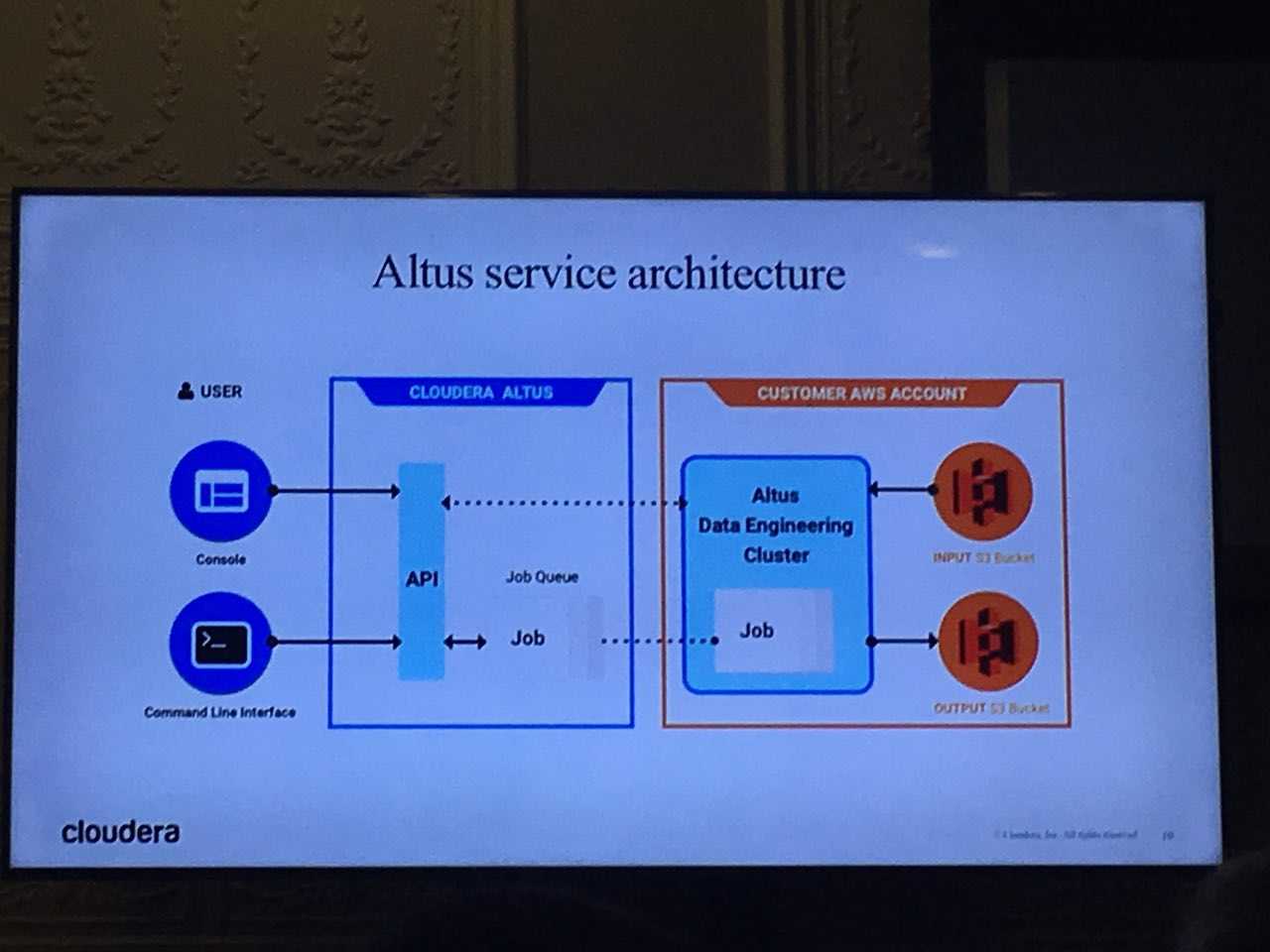
Notes
Voici les points que j’ai noté suite à la présentation du produit :
- Altus permet de créer des clusters à la volée en précisant un seul type d’instance souhaité et le prix max que l’on est prêt à mettre dans les enchères. C’est un point fort, cependant un détail important d’EMR est que le prix est fixe par type d’instance et lorsque le prix dépasse l’enchère on perd l’instance, il aurait été intéressant de pouvoir indiquer plusieurs types d’instances afin de limiter les risques de décommissionnement sur un type d’instance.
- On peut choisir la version de CDH à déployer (aujoud’hui 5.11 et 5.12)
- Les jobs peuvent être Spark, Hive, MR2 ou Hive-on-Spark
- On ne peut pas déployer Altus en local sur son infra (pour gérer un cloud privé, se tourner plutôt vers Director et réimplémenter les mécaniques d’automatisation)
- Le PaaS permet d’avoir une plateforme toujours à jour avec les dernières nouveautés
- La facturation du service est en crédit horaire, on peut pré-payer ou recevoir une facture à la fin du mois (ne comprend pas la facturation du service cloud)
- Une fois un job terminé (en échec ou non)
- on peut spécifier d’automatiquement détruire le cluster
- on peut cloner le job pour le relancer
- Altus propose des outils analytiques tels que :
- un résumé des étapes ainsi que leur temps de traitement
- un aggrégat des logs
- des analyses de temps moyen, pratique si le job a été exécuté plusieurs fois et qu’on souhaite identifier des goulôts
- Les logs rapatriés sont stockés sur les serveurs d’Altus et récupérables (pour les pousser dans un ELK par exemple)
- Les similitudes avec Director sont frappantes, le moteur d’Altus est en effet un fork du moteur de Director.
Cloudera Shared Data Experience
Avec les deux produits précédents, Cloudera permet à ses clients de créer des architectures variables intégrant cloud et on-premise ainsi que des clusters permanents comme des instances temporaires, ce qui repose les questions suivantes :
- Qui utilise la donnée / quand / comment ?
- Comment sécuriser l’accès à ma donnée ?
- Comment m’assurer que je n’ai pas perdu de données ?
- …
Ce sont des questions que des produits comme Navigator ou Sentry ont adressées par le passé, cependant comment faire si ma donnée est dans tant d’endroits différents ? C’est là qu’intervient la solution Cloudera Shared Data Experience.
Il s’agit d’un framework de centralisation des métadatas d’un cluster “logique” afin d’assurer la sécurité et la gouvernance de la donnée ainsi qu’une consistance des worfklows et jobs de traitement à travers les différentes sources de la donnée. C’est la technologie qui permet à Cloudera de proposer avec Altus une plateforme assurant la pérénnité de vos données à travers des sources pérennes comme temporaires et qui vous assurera le même niveau de service dans la prochaine version de CDH (5.13).
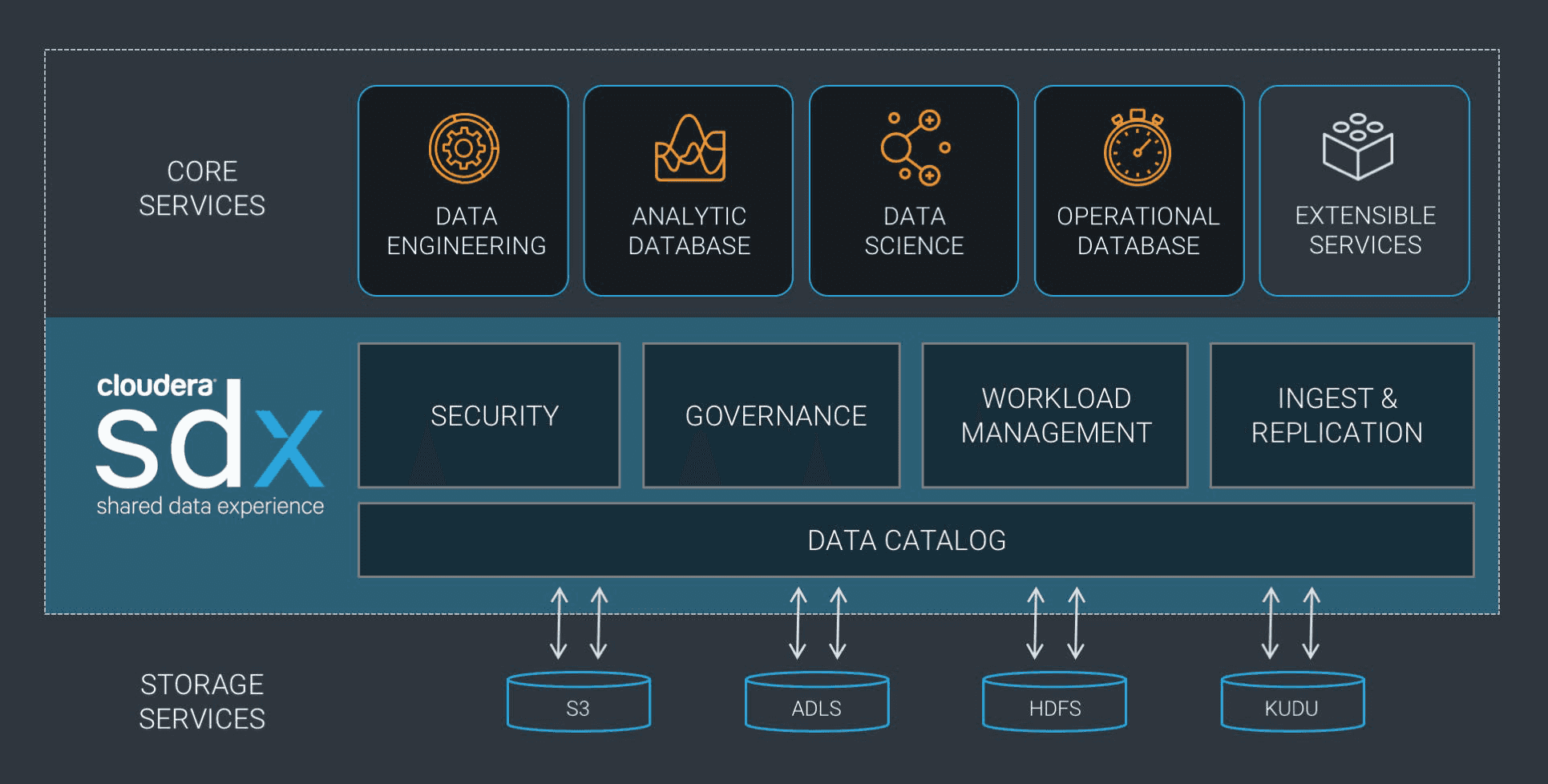
A noter que contrairement à des solutions comme Navigator, Sentry ou Manager, il ne s’agit pas d’un service actif à déployer et surveiller, mais d’un framework intégré à la suite d’outils de Cloudera.
Cloudera Datascience Workbench
Cloudera frappe un grand coup dans le monde des “notebooks” et plateformes de développement décentralisées avec l’annonce de Datascience Workbench (abrégé CDSW). Il s’agit d’un composant externe à la suite CDH proposant un environnement de développement multi-tenant dédié aux projets métiers orientés Data Science.
A la manière d’un Jupyter ou Zeppelin (Open Source) ou encore Dataïku (privé), CDSW permet via une interface web à une équipe de créer un espace de projet collaboratif, développer et expérimenter divers jobs et les exécuter sur un cluster CDH. Les utilisateurs ont accès à plusieurs langages (R, python et scala pour Spark, …) et le code peut être versionné de manière totalement transparente grâce à l’intégration de Git depuis un serveur de versionning existant.
En pratique, CDSW est un cluster avec un master node exposant une interface d’accès et des workers pour l’exécution des jobs, chaque noeud étant connecté à votre cluster via des gateways. Les noeuds sont des containers Docker orchestrés avec Kubernetes de manière complètement transparente pour les administrateurs et utilisateurs du service. Chaque job exécuté avec CDSW est également un container Docker avec ses propres accès au cluster CDH permettant une isolation complète vis-à-vis des autres jobs et une réelle gestion de la multi-tenancy ainsi que l’utilisation de librairies et dépendances multiples en fonction du besoin.
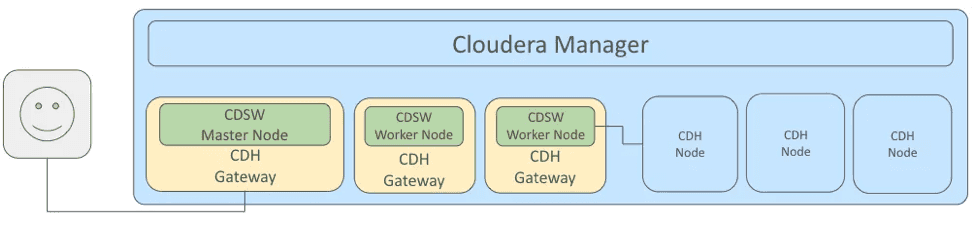
À noter qu’il s’agit du premier produit Cloudera se basant sur des containers.
Lors de la journée, M. Xavier Illy de Covéa est venu nous faire un retour d’expérience sur la bêta de CDSW qu’ils ont utilisé pendant plusieurs mois et qui leur a permis de rapidement monter un Datalab avec de multiples équipes travaillant sur des projets en parallèle. Le thème principal de la présentation était la facilité d’adaptation à la plateforme CDSW qui leur a permis de mettre en place des équipes hétérogènes intégrant sur une seule plateforme les différents profils nécessaires au bon fonctionnement d’un projet.

CDSW est déjà disponible pour installation sur un cluster existant via les RPMs ouverts au téléchargement sur les serveurs de Cloudera.
Table ronde - transition vers le Big Data en entreprise
Présentée comme une table ronde, la séance tenait plus d’une session de Q&A scriptée extrêmement bien préparée. Les sujets étaient pertinents et le background des trois intervenants a permis une bonne diversité de points de vue.
Intervenants
- Didier Mamma, Global Head of Commercial Travel Intelligencechez Amadeus (A)
- Damien Gralan, OSS Chief Data Officerchez Bouygues Telecom (BT)
- Jean Christophe Prandini, Chef de Bureau Adjoint au Service des Technologies et des SIdu Ministère de l’intérieur (MI)
Réunis à cette table étaient donc présent des représentants de la vente de service, de la télécommunication et du service publique.

Compte rendu
Voici les questions posées et les différentes réponses apportées :
Quelles sont les étapes de la transformation vers le numérique ?
Note : Il s’agit plutôt du passage vers les technologies du Big Data, cependant nous conservons la formulation utilisée.
- MI - Le SI du ministère étant un agrégat de besoins fonctionnels traduits en infrastructure, la transformation consistait à apporter une meilleure structure et compréhension des données existantes en déterminant la plus value des technologies à disposition. M. Prandini a également reconnu que les données concernées ne valaient pas l’utilisation du Big Data en terme de taille, mais nécessitait les nouveaux traitements possibles (prédictif, …)
- A - Pour M. Mamma, la première étape est de désapprendre les habitudes et paradigmes des systèmes relationnels habituels, pour travailler dans un mode “data-driven” avec des nouvelles architectures et de nouveaux usages, ce qui implique une conduite du changement dans toute l’entreprise. Il remarquait avec justesse que les entreprises qui sont aujourd’hui les plus disruptives (AirBnb, Uber, …) profitent de ne pas avoir à désapprendre.
Quels ont été les impacts pour le métier et le secteur d’activité ?
- BT - Le passage au Big Data a été l’occasion de changer les manières internes de travailler, en passant d’une volonté de qualité de service (surveillance des équipements) à une qualité d’expérience cliente (que fait le client ?). Cela a entraîné une destruction des silos métiers de l’entreprise et la favorisation d’échanges entre les équipes.
- A - Étant une société de vente de service de voyage, M. Mamma nous a présenté les enjeux de ses clients, les compagnies aériennes. “Que faire de la donnée ? Comment survivre face aux low-costs ?” sont les questions qui ont poussé ces compagnies à proposer une hyper-personnalisation de l’expérience client, ce qui passe par des traitements prédictifs et permettre à leurs différentes équipes de réagir en temps réel.
- MI - Plus que des impacts, M. Prandini nous a présenté deux utilisations de la donnée : une aggrégation des données pour présenter une vue globale d’un dossier et le contrôle qualité de ladite donnée, ce qui amène également le sujet de la prédiction.
Jusqu’où aller avec la donnée ? (Législativement parlant)
-
BT - Les télécoms en France sont cadrés par plusieurs niveaux de sécurité :
- La CNIL faisant appliquer la Loi Informatique et Libertés
- La législation Européenne de protection des données (GDPR)
- Un code Français pour les sociétés de télécommunication
- Un code d’éthique interne
En conséquence, nos données sont anonymisées à la volée dès leur récupération.
-
A - Les compagnies aériennes sont confrontées à un dilemne, protéger la vie privée des clients et proposer une ultra-personnalisation de l’expérience. Pour y répondre, ils demandent au client ce qu’ils souhaitent donner (dans les petites lignes des conditions d’utilisation !)
-
MI - Étant un organisme publique, la question ne se pose pas et les règles du GDPR sont déjà intégrées !
Entretien avec HPE
Nous avons abordé le sujet des architectures hybrides de calcul dans le monde du Big Data. J’entends par là des machines comprenant des cartes graphiques et donc des GPUs.
Longtemps un fantasme des mathématiciens nécessitant d’énormes capacités de calcul matriciel couplées à du Big Data, plusieurs entreprises se sont lancées dans l’acquisition de telles machines dont Sanofi pour du séquencage de génôme ou du calcul de molécule.
Deux points à noter sur les architectures hybrides :
- Le GPU est un processeur optimisé pour du calcul matriciel, c’est à dire une opération répétitive sur un énorme set de données (à l’origine un rendu visuel), il faut donc bien cibler le besoin et les traitements pour lequel on l’utilise
- Le GPU ne va pas chercher lui même la donnée, il faut la préparer et lui envoyer, ce qui nécessite donc d’avoir des CPUs très puissants si l’on souhaite en exploiter pleinement la puissance, forcément on arrive à des machines extrêmement coûteuses.
Conclusion
Entre les multiples produits présentés et les sujets de ses conférences et table ronde, Cloudera continue dans sa volonté de faire de sa suite un couteau suisse du traitement de la donnée en entreprise et affiche clairement ses objectifs futurs de mettre en avant le cloud en s’affranchissant des limites physiques d’un cluster Hadoop conventionnel et de faciliter l’accès au machine learning.
Bibliographie
- Cloudera Altus getting started : https://blog.cloudera.com/blog/2017/05/data-engineering-with-cloudera-altus/
- Introduction SDX : https://vision.cloudera.com/introducing-cloudera-sdx-a-shared-data-experience-for-the-hybrid-cloud/
- Présentation technique SDX : https://blog.cloudera.com/blog/2017/09/cloudera-sdx-under-the-hood/
- Présentation technique CDSW : https://blog.cloudera.com/blog/2017/05/getting-started-with-cloudera-data-science-workbench/
- Documentation CDSW - Intégration de Git : https://www.cloudera.com/documentation/data-science-workbench/latest/topics/cdsw_using_git.html
