


Omid : Traitement de transactions scalables et hautement disponibles pour Apache Phoenix

24 mai 2018
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Apache Omid fournit une couche transactionnelle au-dessus des bases de données clés/valeurs NoSQL.
Crédits à Ohad Shacham pour son discours et son travail pour Apache Omid. Cet article est le résultat de ma compréhension d’Apache Omid à travers la documentation en ligne et la conférence donnée au Dataworks Summit 2018 à Berlin.
Apache Omid fournit une couche transactionnelle au-dessus des bases de données clés / valeurs NoSQL. En pratique, il est généralement utilisé par dessus HBase. Bien que vous puissiez travailler directement avec Omid, il vise à être intégré en tant que moteur de transaction pour Apache Phoenix. Actuellement, les transactions Phoenix sont toujours une fonctionnalité bêta avec le moteur Tephra. Grâce à un Transaction Abstraction Layer, vous pourrez bientôt basculer entre le backend transactionnel Omid et Tephra sur Phoenix.
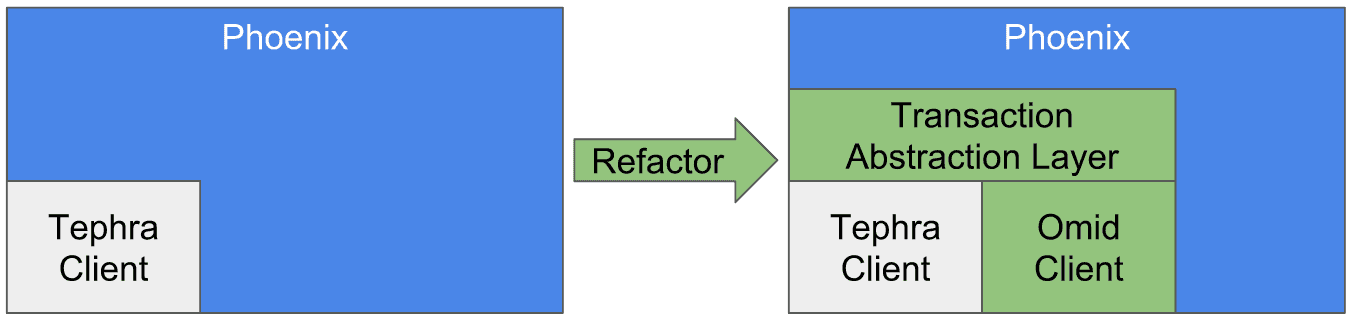
Pourquoi Tephra et Omid sont tous les deux incubés par Apache ?
D’après la proposition d’incubation d’Omid (traduit de l’anglais) :
Très récemment, une nouvelle proposition d’incubateur pour un projet similaire appelé Tephra a été soumise à l’ASF. Nous pensons que c’est bon pour la communauté Apache, et nous pensons qu’il y a de la place pour les deux propositions car la conception de chacune d’entre elles est basée sur des principes différents (par exemple, Omid ne nécessite pas de maintenir l’état des transactions en cours côté serveur) et en raison du fait que les deux - Tephra et Omid - ont également gagné une certaine traction dans la communauté Open Source.
Ces projets sont toujours très proches, mais des améliorations futures pourront justifier le choix de l’un par rapport à l’autre pour des cas d’utilisation spécifiques.
Objectifs d’Omid
Omid assure les transactions qui suivent les propriétés ACID :
- Atomique : “tout ou rien” - aucun effet partiel observable ;
- Cohérent : la base de données passe d’un état valide à un autre ;
- Isolé : semble être exécuté de manière isolée (comme si elle était la seule transaction en cours sur le système) ;
- Durable : les données validées ne peuvent pas disparaître.
Avec son intégration dans Phoenix, cela peut être réalisé avec des transactions SQL.
Fonctionnement d’Omid
Omid doit s’assurer que les transactions n’ont pas d’opérations conflictuelles. Le rôle du composant principal (TSO: The Server Oracle) est de détecter ces conflits.
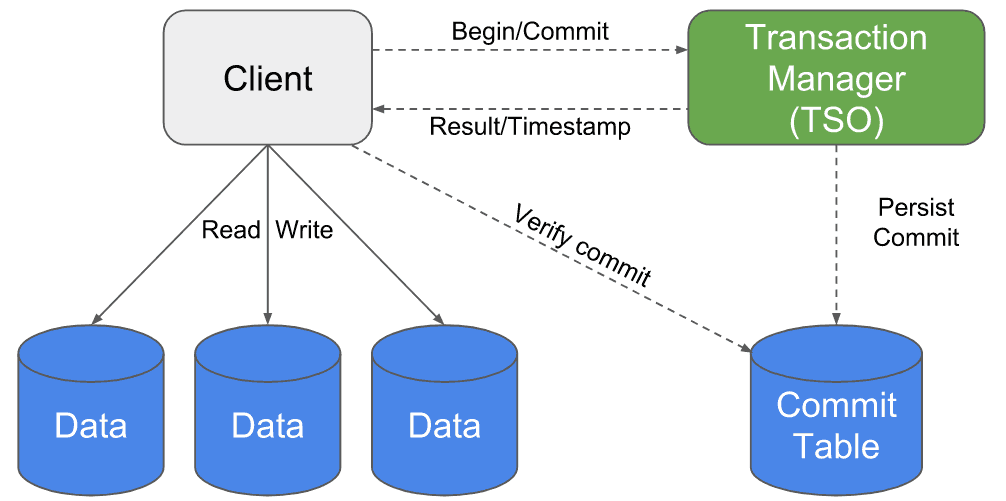
Voici une explication étape par étape simplifiée :
- D’abord, le client commence (begin) une transaction. Le TSO renvoie un timestamp de lecture, de sorte que la transaction ne lit jamais les données qui dépassent ce timestamp. Il écrit des données dans la base de données en utilisant un timestamp temporaire (null) indiquant que l’opération n’a pas encore été validée (appelée tentative update) ;
- Il commit ensuite l’opération auprès du TSO. Si aucun conflit n’est trouvé, le TSO conserve la validation dans la table de commit (CT) avec un timestamp de commit donné ;
- Le client vérifie si le commit a été persisté dans la table de commit.Dans ce cas, il met à jour les données pour leur donner leur vrai timestamp (timestamp de commit). Il supprime ensuite le commit de la table de commit.
Lorsqu’une transaction lit des données, elle doit vérifier si le timestamp de commit des données est inférieur au timestamp de lecture de la transaction. Sinon, elle passe sur la version précédente des données et effectue le même processus.
Cependant, nous avons dit qu’une transaction écrit d’abord des données avec un timestamp null (tentative update) avant qu’elle ne soit validée. Dans le cas où une transaction lit des données avec un timestamp null, elle doit vérifier directement dans la table de commit si son timestamp de commit est inférieur au timestamp de lecture de la transaction. S’il est trouvé dans la CT, le client transactionnel met à jour les données avec le timestamp de commit correct (c’est ce qu’on appelle le processus de guérison, qui optimise l’accès à la CT pour les autres clients). Sinon, il va à la version précédente des données.
Fonctionnalités récentes et futures d’Omid
Extended snapshot isolation
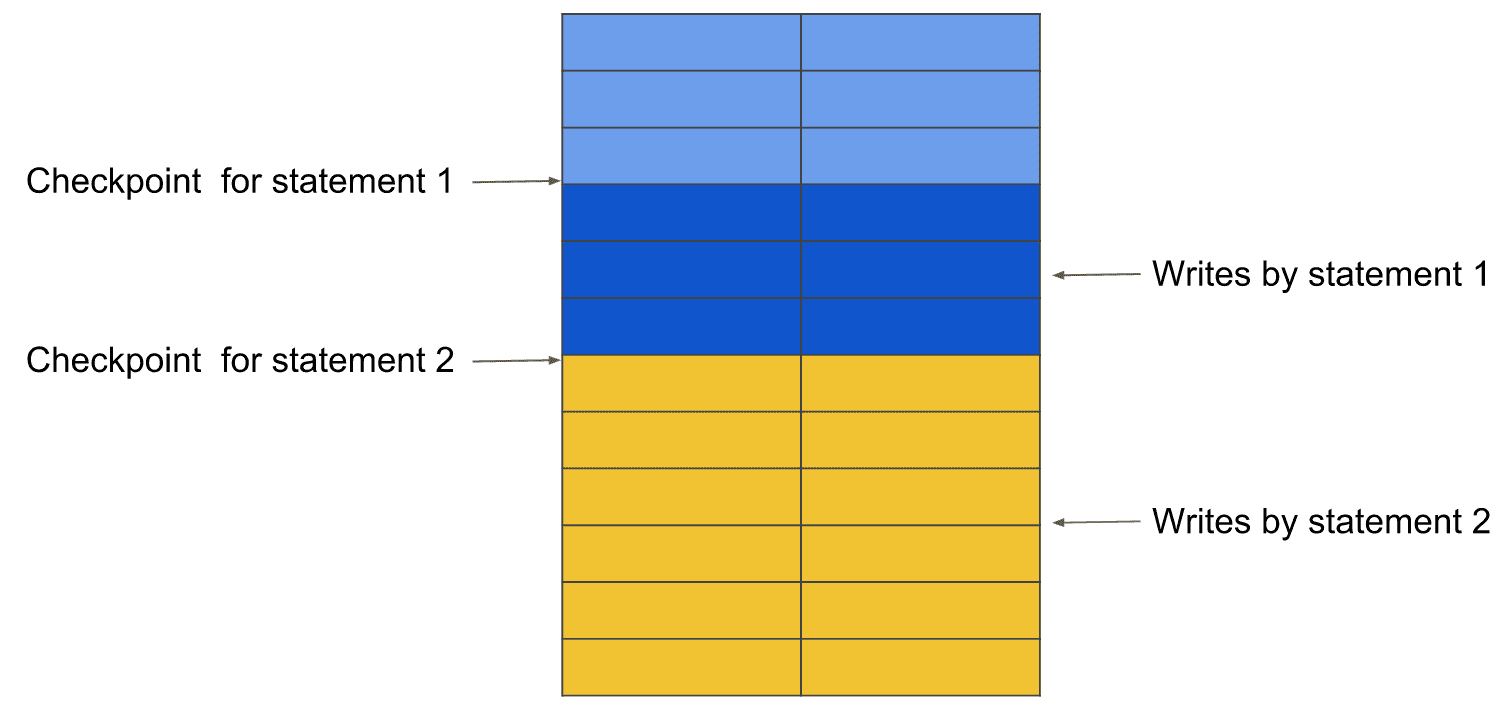
Lorsqu’une transaction commence, la snapshot isolation garantit que les autres transactions qui se produisent en même temps sur les mêmes lignes n’affecteront pas la transaction en cours. Dans le cas où un conflit d’écriture-écriture se produit, il sera simplement détecté par le TSO et l’une des transactions sera annulée.
L’extended snapshot isolation garantit que vous pouvez écrire et lire simultanément dans la même transaction. Ce que vous écrivez dans le snapshot actuel sera pris en compte pour la requête suivante.
Considérez la transaction suivante :
CREATE TABLE T (ID INT);
...
BEGIN;
INSERT INTO T
SELECT ID+10 FROM T;
INSERT INTO T
SELECT ID+100 FROM T;
COMMIT; La première transaction voit seulement le snapshot jusqu’au premier checkpoint. Le checkpointest ensuite poussé vers la dernière ligne écrite par la première instruction. Il se passe de même pour la deuxième déclaration.
Haute disponibilité
Dans l’architecture actuelle, le TSO est un point de défaillance unique (SPOF). Pour activer la haute disponibilité, nous ajoutons un TSO secondaire afin que nous puissions avoir un système primaire / backup. Pour éviter un scénario de split-brain (dans le cas où le TSO primaire n’est pas réellement en panne), le TSO primaire vérifie régulièrement s’il a été remplacé par un TSO secondaire et, le cas échéant, se tue lui-même. Nous ne voulons pas utiliser des mécanismes de synchronisation (par exemple un mécanisme de lock), car cela impliquerait une vérification pour chaque commit, affectant ainsi les performances du système.
Comme il n’y a pas de mécanisme de synchronisation, il y a un délai avant que le TSO principal ne se tue lui-même. Pendant ce temps, nous pouvons avoir des transactions conflictuelles qui doivent être traitées. Pour éviter cela, deux conditions doivent être remplies :
- Tous les timestamps attribués par le nouveau TSO doivent être supérieurs aux timestamps assignés par l’ancien TSO ;
- Le TSO ne peut pas conserver les commits qui effectuent des mises à jour avec un timestamp de validation inférieur au timestamp de lecture des autres transactions.
Latence faible
Une alternative à faible latence à la conception actuelle a été mentionnée lors de cette conférence.Plutôt que de laisser le TSO persister dans la table de commit, l’opération d’écriture sur la CT sera traitée directement par le client.
Pour conclure, un point clé à retenir est qu’Apache Phoenix peut désormais gérer des transactions (beta), et il proposera un nouveau backend pour ses transactions : Omid. Alors que la plupart de ce que nous avons discuté ici n’est pas encore disponible, cela viendra dans un avenir proche.
Références
- https://omid.incubator.apache.org/
- https://fr.slideshare.net/Hadoop_Summit/omid-scalable-and-highly-available-transaction-processing-for-apache-phoenix
- https://wiki.apache.org/incubator/OmidProposal
- http://yahoohadoop.tumblr.com/post/132695603476/omid-architecture-and-protocol
- http://yahoohadoop.tumblr.com/post/138682361161/high-availability-in-omid
- https://issues.apache.org/jira/browse/PHOENIX-3623
- https://issues.apache.org/jira/browse/OMID-82
