


Scaling massive, real-time data pipelines with Go

Nov 21, 2017
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Last week at the Open Source Summit in Prague, Jean de Klerk held a talk called Scaling massive, real-time data pipelines with Go.
This article goes over the main points of the talk, detailing the steps Jean went through when optimising his pipelines, explaining critical parts of his code and reproducing his benchmark results.
All of Jean’s code, as well as the slides he used during his talk, are available in this Github repository.
What is Go?
Go, or Golang, is a programming language created by Google in 2007. Like C or Algol, it is a compiled, statically typed language. It provides garbage collection and supports concurrency at the language level. Go’s syntax is straightforward and easy to understand, and it compiles very quickly.
Because of its core features, Go is best applied to networking, systems, and concurrency. As Mark C. Chu-Caroll put it:
Goroutines and channels provide the best support I’ve seen outside of Erlang for making use of concurrency. And frankly, I think Go is a lot less ugly than Erlang. (Sorry Erlang fans, but I really don’t like Erlong.) Compared to Java, which I think is the main competitor to Go in this area, Go’s goroutines and channels are just so much easier to work with than Java threads and locks, there’s just absolutely no comparison at all. Go pretty much destroys the competition in this area.
Our data pipelines
We want our data pipelines to be highly available, to have a little message drop rate, and to have high throughput.
High availability is achieved by implementing our pipelines as stateless, horizontally scaled microservices. Enabling highly concurrent access will result in high throughput. To limit message drop rate, we will work with small buffers with flush capability.
Example pipelines
Pipelines are a simple concept: gateways process messages - packs of data - sent from a source before being sent on to a destination.
Example 1: IoT devices, like smart lightbulbs, send data through gateways to a server that provides services, like auto-dimming.
Example 2: Messaging apps send messages through gateways where they are forwarded to other messaging apps.
Example 3: Logs or metrics are sent through gateways where they are processed and stored in a database.
So what do gateways do precisely? It can often be broken down into four necessary steps: ingestion, parsing, processing, and passing along.
Our barebone pipeline
To benchmark different optimizations, Jean created an example application structure:
type Queue interface {
Enqueue(data [fusion_builder_container hundred_percent="yes" overflow="visible"][fusion_builder_row][fusion_builder_column type="1_1" background_position="left top" background_color="" border_size="" border_color="" border_style="solid" spacing="yes" background_image="" background_repeat="no-repeat" padding="" margin_top="0px" margin_bottom="0px" class="" id="" animation_type="" animation_speed="0.3" animation_direction="left" hide_on_mobile="no" center_content="no" min_height="none"][]byte)
Dequeue() ([]byte, bool)
}
type inputter interface {
StartAccepting(q queues.Queue)
}
type outputter interface {
StartOutputting(q queues.Queue)
}
type Processor struct {
i inputter
q queues.Queue
o outputter
wg *sync.WaitGroup
}
func (p *Processor) Start() {
go p.i.StartAccepting(p.q)
go p.o.StartOutputting(p.q)
p.wg.Wait()
}This code defines interfaces for functions that can be implemented in different ways. Which way is best is precisely the point of Jean’s talk.
The StartAccepting and StartOutputting functions determine which network protocols are used to send messages to gateways, which is the first aspect we will optimise. The Enqueue and Dequeue functions define which data structures our gateways use to store messages as they pass through, which we will also optimise later on.
Optimising network I/O
Jean’s talk looked at several different methods of Network I/O:
- Unary HTTP
- Unary HTTP/2 with gRPC
- UDP
- Streaming TCP
- Streaming web sockets
- Streaming HTTP/2 with gRPC
Unary HTTP
Unary HTTP allows sending one message through a typical HTTP connection.
Advantages:
- It is easy to know if the connection succeeded and the gateway correctly received the message.
- It is easy to implement.
Disadvantages:
- Unary connections are slow.
Here is Jean’s implementation:
func (l *HttpListener) StartAccepting(q queues.Queue) {
fmt.Printf("Starting HTTP listening on port %d\n", l.port)
m := http.NewServeMux()
m.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
body, err := ioutil.ReadAll(r.Body)
if err != nil {
panic(err)
}
q.Enqueue(body)
})
log.Fatal(http.ListenAndServe(fmt.Sprintf(":%d", l.port), m))
}The above code is simple: it listens for incoming HTTP requests and adds incoming data to the gateway’s queue.
Unary HTTP/2 with gRPC
Moving from HTTP to HTTP/2, this next implementation uses gRPC instead of a typical HTTP request.
Google developed then open-sourced gRPC, and now they describe it like this:
gRPC is a modern, open source remote procedure call (RPC) framework that can run anywhere. It enables client and server applications to communicate transparently, and makes it easier to build connected systems.
Google developed protocol buffers, or protobuf, and describes them as follows:
Protocol buffers are Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages.
Advantages:
- gRPC uses protobuf, which allows for binary-decoding into models.
- gRPC uses protobuf, which makes service and spec language agnostic.
- HTTP/2 is better than HTTP.
- gRPC is built with load balancing in mind.
Disadvantages:
- Unary connections are slow.
Here is Jean’s implementation:
func (l *UnaryGrpcListener) StartAccepting(q queues.Queue) {
fmt.Printf("Starting gRPC listening on port %d\n", l.port)
lis, err := net.Listen("tcp", fmt.Sprintf(":%d", l.port))
if err != nil {
panic(err)
}
s := grpc.NewServer()
r := unaryGrpcServerReplier{q: q}
model.RegisterGrpcUnaryInputterServiceServer(s, r)
reflection.Register(s)
if err := s.Serve(lis); err != nil {
panic(err)
}
}
func (r unaryGrpcServerReplier) MakeRequest(ctx context.Context, in *model.Request) (*model.Empty, error) {
r.q.Enqueue([]byte(in.Message))
return &model.Empty{}, nil
}This code uses the gRPC framework to receive messages and insert them into the gateway’s queue.
UDP
HTTP uses TCP on the transport layer. An alternative transport layer protocol is UDP, which this next implementation uses to achieve increased speed.
As opposed to TCP, UDP is a connection-less protocol, which means that the sender does not get any acknowledgment from the receiver stating whether or not the desired data was received.
Advantages:
- UDP is fast since no time is lost acknowledging.
Disadvantages:
- UDP is lossy since no connection is established.
- It is hard to know how much is lost during transmission.
I exchanged a few emails with Jean, and he explained what could impact UDP’s lossyness:
The lossyness of UDP is excaberated the more ‘busy’ intermediary nodes are; TCP will resend dropped packets (and in fact treated dropped packets as rate limiting indication), but in UDP’s case they are just lost. The more ‘busy’ a node is (router, proxy, load balancer, whatever) the more likely it is for a packet to be dropped. Loss of connection and those types of things can also cause packet loss.
Here is Jean’s implementation:
func (l *UdpListener) StartAccepting(q queues.Queue) {
fmt.Printf("Starting UDP listening on port %d\n", l.port)
addr, err := net.ResolveUDPAddr("udp", fmt.Sprintf(":%d", l.port))
if err != nil {
fmt.Println(err)
}
conn, err := net.ListenUDP("udp", addr)
if err != nil {
fmt.Println(err)
}
defer conn.Close()
buf := make([]byte, 65536)
for {
n, _, err := conn.ReadFromUDP(buf)
if err != nil {
fmt.Println("Error: ", err)
}
message := buf[0:n]
q.Enqueue(message)
}
}This code continuously listens for messages sent through UDP and adds those messages to the gateway’s queue.
Streaming TCP
Moving away from unary connections, we can try streaming, which will allow us to send multiple messages through a single connection. Let’s start with TCP.
Advantages:
- Streaming is fast because only one connection is made.
Disadvantages:
- This requires building your protocol.
- This requires building your security model.
- This requires building your status codes.
- etc.
Here is Jean’s implementation:
func (l *TcpListener) StartAccepting(q queues.Queue) {
fmt.Printf("Starting TCP listening on port %d\n", l.port)
ln, err := net.Listen("tcp", fmt.Sprintf(":%d", l.port))
if err != nil {
panic(err)
}
for {
conn, err := ln.Accept()
if err != nil {
panic(err)
}
go readFromConn(conn, q) // incl process buffer manually, retry logic, etc
}
}
func readFromConn(c net.Conn, q queues.Queue) {
var add = make(chan ([]byte), 1024)
go processBuffer(add, q)
for {
msg := make([]byte, 1024)
_, err := c.Read(msg)
if err != nil {
if err == io.EOF {
c.Close()
return
}
panic(err)
}
add <- msg
}
}
func processBuffer(add chan ([]byte), q queues.Queue) {
b := bytes.NewBuffer([]byte{})
for {
select {
case msg := <-add:
b.Write(msg)
break
default:
l, err := b.ReadBytes('\n')
if err != nil {
if err == io.EOF {
break
}
panic(err)
}
if len(l) <= 1 || l[0] == 0 { // kinda hacky way to check if it's a fully-formed message
break
}
q.Enqueue(l)
}
}
}This code listens for incoming TCP connections and continuously reads data into a buffer which it then adds to the gateway’s queue once an entire message is received.
Note: This implementation is simple and does not work when sending large messages.
Streaming web sockets
Instead of streaming through TCP, perhaps we can use a higher-level protocol like web socket.
Mozilla describes web sockets like this:
WebSockets is an advanced technology that makes it possible to open an interactive communication session between the user’s browser and a server. With this API, you can send messages to a server and receive event-driven responses without having to poll the server for a reply.
Advantages:
- Streaming with web sockets is very fast.
Disadvantages:
- It is difficult to know if the web socket connection is alive.
- Load balancing can be tricky with web sockets.
Here is Jean’s implementation:
func (l *WebsocketListener) StartAccepting(q queues.Queue) {
fmt.Printf("Starting websocket listening on port %d\n", l.port)
m := http.NewServeMux()
m.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
c, err := upgrader.Upgrade(w, r, nil)
if err != nil {
return
}
defer c.Close()
for {
_, message, err := c.ReadMessage()
if err != nil {
break
}
q.Enqueue(message)
}
})
log.Fatal(http.ListenAndServe(fmt.Sprintf("localhost:%d", l.port), m))
}This code listens continuously on a web socket, adding incoming messages to the gateway’s queue.
Streaming HTTP/2 with gRPC
gRPC can work through streaming, adding the strengths of the technology to the speed of streaming.
Advantages:
- Streaming with gRPC is very fast.
- gRPC uses protobuf, which allows for binary-decoding into models.
- gRPC uses protobuf, which makes service and spec language agnostic.
- gRPC uses protobuf, which allows for smaller packets moving through the network.
- HTTP/2 is better than HTTP.
- gRPC is built with load balancing in mind.
Disadvantages:
- It is difficult to know if the connection is alive.
Here is Jean’s implementation:
func (l *StreamingGrpcListener) StartAccepting(q queues.Queue) {
fmt.Printf("Starting gRPC listening on port %d\n", l.port)
lis, err := net.Listen("tcp", fmt.Sprintf(":%d", l.port))
if err != nil {
panic(err)
}
s := grpc.NewServer()
model.RegisterGrpcStreamingInputterServiceServer(s, &streamingGrpcServerReplier{q: q})
s.Serve(lis)
}
func (r streamingGrpcServerReplier) MakeRequest(request model.GrpcStreamingInputterService_MakeRequestServer) error {
for {
req, err := request.Recv()
if err != nil {
return err
}
r.q.Enqueue([]byte(req.Message))
}
return nil
}This code uses the gRPC framework to continuously receive messages and insert them into the gateway’s queue.
Benchmarks
Jean wrote code to benchmark the different methods described above. I ran those benchmarks and here are the results.
| Protocol | Parallel Sending | Small Message | Medium Message | Large Message | Very Large Message |
|---|---|---|---|---|---|
| Unary HTTP | No | 46942 | 57682 | 58412 | 170765 |
| Unary HTTP | Yes | 44874 | 40308 | 40461 | 98686 |
| Unary UDP | No | 10647 | 12890 | 13388 | |
| Unary UDP | Yes | 1775 | 2801 | 3063 | |
| Unary gRPC | No | 70816 | 93274 | 92594 | 212194 |
| Unary gRPC | Yes | 18813 | 25950 | 28199 | 127414 |
| Streaming TCP | No | 3261 | |||
| Streaming TCP | Yes | 3106 | |||
| Streaming UDP | No | 1955 | 3544 | 4400 | |
| Streaming UDP | Yes | 2324 | 4010 | 4543 | |
| Streaming Websocket | No | 3769 | 10107 | 10646 | 120604 |
| Streaming Websocket | Yes | 1090 | 4498 | 4951 | 47776 |
| Streaming gRPC | No | 3004 | 9883 | 13296 | 123162 |
| Streaming gRPC | Yes | 1075 | 6810 | 8813 | 73845 |
Results are in nanoseconds per operation.
Here are the different message sizes:
- Small: 18 bytes
- Medium: 4266 bytes
- Large: 6786 bytes
- Very Large: 79435 bytes
Some results are missing. Extensive messages sent through UDP seem to have been lost, and Jean’s implementation of streaming TCPwas unable to process messages of too high a size. As he put it in an email:
The TCP decoding is just a reference implementation, and isn’t able to handle stitching together incomplete data transmission. Small packets tend to arrive whole, and larger packets tend to arrive broken up.
By looking at these benchmark results, we can see that streaming messages to our gateway is much faster than using unary connections. The increased speed is even more visible when sending multiple messages concurrently.
Optimising data ingestion
Once the messages have reached our gateway, they must be stored in a queue as they wait for processing. While some threads will write - or add - new messages into the queue, others will read - or remove - them to process them.
Jean’s talk looked at several different data structures:
- Array-backed queue using mutices
- Channel-backed queue
- Ring-buffer-backed queue using mutices
- Ring-buffer-backed queue using atomics
Array-backed queue using mutices
This queue is implemented as a simple array, with a mutex to avoid simultaneous writing or reading by different threads.
If you don’t know what a mutex, or MUTually EXclusive semaphore, is then Xetius and Петър Петров’s explanation should help:
When I am having a big heated discussion at work, I use a rubber chicken which I keep in my desk for just such occasions. The person holding the chicken is the only person who is allowed to talk. If you don’t hold the chicken you cannot speak. You can only indicate that you want the chicken and wait until you get it before you speak. Once you have finished speaking, you can hand the chicken back to the moderator who will hand it to the next person to speak. This ensures that people do not speak over each other, and also have their own space to talk.
Replace Chicken with Mutex and person with thread and you basically have the concept of a mutex.
The chicken is the mutex. People holding the mu… chicken are competing threads. The Moderator is the OS. When people requests the chicken, they do a lock request. When you call mutex.lock(), your thread stalls in lock() and makes a lock request to the OS. When the OS detects that the mutex was released from a thread, it merely gives it to you, and lock() returns - the mutex is now yours and only yours. Nobody else can steal it, because calling lock() will block him. There is also try_lock() that will block and return true when mutex is yours and immediately false if mutex is in use.
Advantages:
- None. This is not a proper implementation.
Disadvantages:
- Continually locking and unlocking the mutex is slow.
- Resizing the array is agonizingly slow.
- If your reads are slower than your writes, then the array will grow and grow uncontrollably.
Here is Jean’s implementation:
func (q *MutexArrayQueue) Enqueue(data []byte) {
q.mu.Lock()
defer q.mu.Unlock()
q.data = append(q.data, data)
}
func (q *MutexArrayQueue) Dequeue() ([]byte, bool) {
q.mu.Lock()
defer q.mu.Unlock()
if len(q.data) == 0 {
return nil, false
}
data := q.data[0]
q.data = q.data[1:len(q.data)]
return data, true
}This code adds/writes new messages to the end of the array/queue and removes/reads the oldest messages from the beginning of the array/queue.
While this is probably the most straightforward and most intuitive solution, it is one of the slowest.
Channel-backed queue
In Go, channels are pre-allocated structures into which one thread can add/write data into one end or remove/read data from the other end. Channels are, in essence, queues.
Advantages:
- Channels are fast, as they are a core feature of Go.
Disadvantages:
- Channels eventually fill up, dropping newest data. The oldest data is prioritized.
- Channels sometimes internally use mutices, which can slow them down a bit.
Here is Jean’s implementation:
func (q *ChannelQueue) Enqueue(data []byte) {
select {
case q.c <- data:
default:
// Queue was full! Data dropped
// metrics.Record("dropped_messages", 1)
}
}
func (q *ChannelQueue) Dequeue() ([]byte, bool) {
select {
case data := <-q.c:
return data, true
default:
return nil, false
}
}This code writes/adds messages to the queue if it is not full. If the queue is full, then any new messages are dropped. Messages in the channel can be read/removed.
Ring-buffer-backed queue using mutices
If our writes are faster than our reads, our queue will fill up. Channels prioritize older messages, but we would prefer to prioritize newer messages by flushing out older messages when writes are too far ahead of reads.
The solution for this is to use a ring buffer. A ring buffer is an array that loops around onto itself. When you reach the end, you start back at the start. Two pointers keep track of where messages should be written to or read from. A mutex is used to avoid simultaneous writing or reading by different threads.
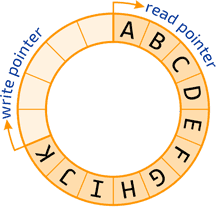

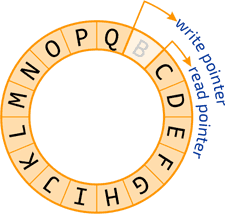
Advantages:
- If the writes exceed the reads by a full loop, then the buffer flushes: reads act on new messages, and oldest messages are overwritten. This prioritizes new messages.
Disadvantages:
- Continually locking and unlocking the mutex is slow.
This is Jean’s implementation:
func (q *MutexRingBufferQueue) Enqueue(data []byte) {
q.mu.Lock()
defer q.mu.Unlock()
q.buffer[q.inputCursor] = data
if q.inputCursor == len(q.buffer)-1 {
q.inputCursor = -1
}
q.inputCursor++
}
func (q *MutexRingBufferQueue) Dequeue() ([]byte, bool) {
q.mu.Lock()
defer q.mu.Unlock()
if q.outputCursor == q.inputCursor {
return nil, false
}
data := q.buffer[q.outputCursor]
if q.outputCursor == len(q.buffer)-1 {
q.outputCursor = -1
}
q.outputCursor++
return data, true
}This code implements a ring buffer as a queue. The pointers that keep track of where to write to and read from are called cursorshere.
Ring-buffer-backed queue using atomics
In Go, atomics are low-level implementations of simple operations like adding, swapping, etc. Because of their atomic nature, these actions do not require mutices.
We can reimplement a ring buffer without mutices by using Go’s atomics.
Advantages:
- If the writes exceed the reads by a full loop, then the buffer effectively flushes: reads act on new messages, and oldest messages are overwritten. This prioritizes new messages.
- Atomics are fast.
Disadvantages:
- None.
Here is Jean’s implementation:
func (d *OneToOne) Enqueue(data []byte) {
writeIndex := atomic.AddUint64(&d.writeIndex, 1)
idx := writeIndex % uint64(len(d.buffer))
newBucket := &bucket{
data: data,
seq: writeIndex,
}
atomic.StorePointer(&d.buffer[idx], unsafe.Pointer(newBucket))
}
func (d *OneToOne) Dequeue() ([]byte, bool) {
readIndex := atomic.LoadUint64(&d.readIndex)
idx := readIndex % uint64(len(d.buffer))
value, ok := d.tryNext(idx)
if ok {
atomic.AddUint64(&d.readIndex, 1)
}
return value, ok
}
func (d *OneToOne) tryNext(idx uint64) ([]byte, bool) {
result := (*bucket)(atomic.SwapPointer(&d.buffer[idx], nil))
if result == nil {
return nil, false
}
if result.seq > d.readIndex {
atomic.StoreUint64(&d.readIndex, result.seq)
}
return result.data, true
}This code implements a ring buffer with atomics instead of mutices. It requires a bit more code than the previous implementation precisely because of this.
Benchmarks
Jean wrote code to benchmark the different data structures described above. I ran those benchmarks and here are the results.
| Data Structure | Small Message | Medium Message | Large Message | Very Large Message |
|---|---|---|---|---|
| Array & Mutices | 15969 | 16370 | 15961 | 15947 |
| Channel | 6888 | 6862 | 6805 | 6416 |
| Ring Buffer & Mutices | 11812 | 11869 | 13097 | 11891 |
| Ring Buffer & Atomics | 6339 | 6199 | 6317 | 6177 |
Results are in nanoseconds per operation.
Here are the different message sizes:
- Small: 18 bytes
- Medium: 4266 bytes
- Large: 6786 bytes
- Very Large: 79435 bytes
These results don’t seem to depend on message size, only because when a message is added to or removed from the queue, it is not copied. Just its address in memory is.
By looking at these benchmark results, we can see that using mutices is quite slow so using atomics can be better. While the ring buffer requires more complex code than channels, it prioritizes newer data over older data. Fancy data structures can be advantageous.
Profiling in Go
Before you start optimising, Jean recommends that you profile your code.
Wikipedia explains what profiling is reasonably well:
In software engineering, profiling is a form of dynamic program analysis that measures, for example, the space (memory) or time complexity of a program, the usage of particular instructions, or the frequency and duration of function calls. Most commonly, profiling information serves to aid program optimization.
You can profile your code using pprof, which gives a runtime trace of execution time, or with gotrace, which creates a dynamic graph of all threads at execution time.
Conclusion
After trying all these different optimisations, we can safely say that to obtain the best performance we need to stream our messages to our gateways, and our gateways should implement their queues as atomic ring buffers.
Jean shared some insight at the end of his talk:
- Metrics are more useful than logs, and they also tend to be smaller.
- Queues are great, mainly when they are correctly implemented.
- Be sure to profile your applications.
- Channels are fantastic, but not always perfect; you may need to profile your code to be sure.
On a personal note, I believe that all developers should have some knowledge of algorithms and data structures, so that they may optimise their code in the best possible way. Optimisation starts with knowing your options.
