


YARN and GPU Distribution for Machine Learning

By Grégor JOUET
May 30, 2018
- Categories
- Data Science
- DataWorks Summit 2018
- Tags
- GPU
- YARN
- Machine Learning
- Neural Network
- Storage [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
This article goes over the fundamental principles of Machine Learning and what tools are currently used to run machine learning algorithms. We will then see how a resource manager such as YARN can be useful in this context and how it can help the algorithms to run smoothly. This article stems from a conference at the 2018 DataWork Summit in Berlin, by Wangda Tan and Sunil Govindan.
Machine Learning Basics
Let’s take an example: we want to build a software that can say whether or not a given image is the picture of a cat:

A CAT

NOT A CAT
Starting from scratch, we begin by searching for a great amount of labeled images, ImageNet can provide us with all the data that we need.
We can’t just have raw images of cat and non-cat subjects, we must have meta.
data saying precisely if this image is a cat or not because we will be doing supervised training, we have to know the expected output of our model in order to train it.
Speaking of model, now is a good time to create one. our model will have an input, which is the image, an output, a number between 0 and 1 saying if this image is a cat or not (for example 0 means “not a cat” and 1 means “is a cat”). We won’t go over the technical details of such a model here but further reading is available with this article on Image Classification.
We are ready to begin the implementation and the training of our model, but before that we have to choose a framework: it can be one of Tensorflow, Caffe or MxNet for example. There’s a lot of them available, the choice will depend on the use case and the framework you’re comfortable with.
The model is now training and should be ready in a few hours thanks to the speed of GPUs. Indeed, you may have heard that machine learning models are trained on graphic cards, that is correct, but why? Basically, GPUs are used because there is a massive amount of operations to do, but these operations are simple and can be made simultaneously. GPUs have proven to be very efficient in that case.
Finally, we have a fresh model that we can put to the test with a portion of our data that wasn’t used for training (the test set), and if the model shows interesting results, it may be considered ready to be used in production.
Machine Learning Requirements
As we saw, a simple machine learning model demanded a lot of resources, mainly:
-
Storage capacity: the amount of data required to properly train a model can be astonishing, but the larger the dataset the better model we will have.
-
GPU: the graphic unit is a strong constraint to have model training that completes in a decent amount of time. When the model is required to respond in real time or in critical areas such as autonomous driving, the GPU constraint is very strong if we don’t want to experience latency.
Machine Learning models in production
What we have seen so far is only a small part of what happens when we train a model while aiming to be production ready.
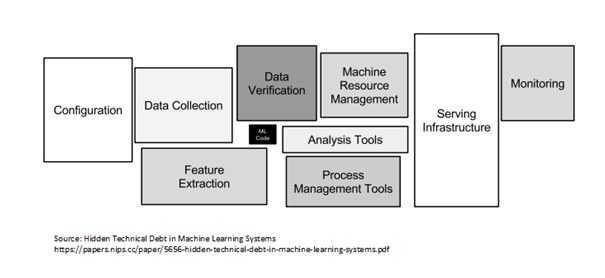
The writing of the model is a small part of the work, especially when considering the rapid pace at which scientific research is going. The findings and achievements of the research can be found on the well known Arxiv website. The writing of the models is a lot easier when you have solid research papers and examples to base your work on.
In practice, the time-consuming task is all that comes around the model in itself. In our previous example, it would have been to check the validity of the labeled images, to set up our infrastructure, our model registry, our monitoring tools etc…
How can YARN help?

YARN (Yet Another Ressource Negotiator) is a resource manager part of the Hadoop ecosystem.
Basically what YARN does is allocating resources to applications requesting them, it ensures that specific applications always have sufficient resources and can deny access to resources in case of a shortage. Such resources are storage space (SATA, SSD), CPUs, RAM, and, available from version 3.1 and above, GPUs.
YARN provides a way to reserve a resource, you can make a planning for a reservation just like you would for an airplane ticket. It can also provide monitoring data visualisable through tools like Grafana. You can control user’s access to a specific resource, define quotas, isolate each resource and isolate users from each other when using managed resources.
This is very interesting on its own but why is it helpful in a machine learning context?
It is not uncommon for a model training process to exceed the maximum available GPU memory (OutOfMemory errors). In some specific use cases, the required amount of memory can be extremely large.
This can be a serious problem if you do not have your training session isolated from the rest of your infrastructure. Let’s consider an example without a resource manager: if we have a model running in production mode and we start a poorly configured training session that ends up requesting all the available GPU memory, at least one of the two applications will crash because of the memory shortage.
YARN is even more helpful when we consider distribution issues. Indeed, it is rare nowadays to train a model on a single GPU, we train the most resource consuming models on clusters of several GPUs. The majority of frameworks now have a functionality to run a model (usage and training) on multiple machines at the same time, which means these machines have to be available at the same time, the idea of a resource manager and scheduler appears naturally.
It is worth noting that YARN now supports the use of Docker containers, which solves the graphic driver dependency nightmare and adds a layer of abstraction and isolation as well as multiple other tools.
Conclusion
YARN can be of great use in a machine learning environment. Its capabilities in terms of scheduler and resource management are precious when applied to something as volatile as GPUs.
