


Curing the Kafka blindness with the UI manager

Jun 20, 2018
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Today it’s really difficult for developers, operators and managers to visualize and monitor what happens in a Kafka cluster. This articles covers a new graphical interface to oversee Kafka. It was given by George Vetticaden, VP Management product at Hortonworks, during the DataWorks Summit at the San Jose Conference Center in June 2018.
Context
George described the inception and conception process to create a new product they call “streams messaging manager”. In other words, The Kafka Manager.
Hortonworks focused on HDF 3.2’s finalization in order to think about what they can add to it. They prioritized HDF 3.2 delivering and used a Trello dashboard to organise evolutions. As a reminder, Kafka is part of HDF since HDF 3.0 and will not to be packaged anymore in HDP after version 3.0.
Once finalized, they took all their ideas and started to look at and share them with:
- Hortonworks Support Engineer
- Hortonworks Professional Service
- Hortonworks Backlogs
- Customers
A polished UI
What came out was the need for Kafka monitoring because, whatever workload and use cases customers had, they did not know what happened inside Kafka or what was the state of their topics (at least for HDP/HDFKafka customers). Indeed, in this version there was no UI or API to monitor Kafka, the only solution left was enabling JMX and collecting metrics on your own.
As a consequence, they started working on a UI which aimed to give the state of a Kafka cluster. This UI would give insight about the Kafka cluster metrics including the number of brokers, the timeline of events, the created topics and partitions, the number of producers and consumers, the number of messages being consumed and produced per topic or per broker, …
They designed a few UI and submitted them directly to pre-selected consumers who had volunteered to test it.
Finally they came out with the following UI, which makes me think How did I do it before? It was hard before, wasn’t it?
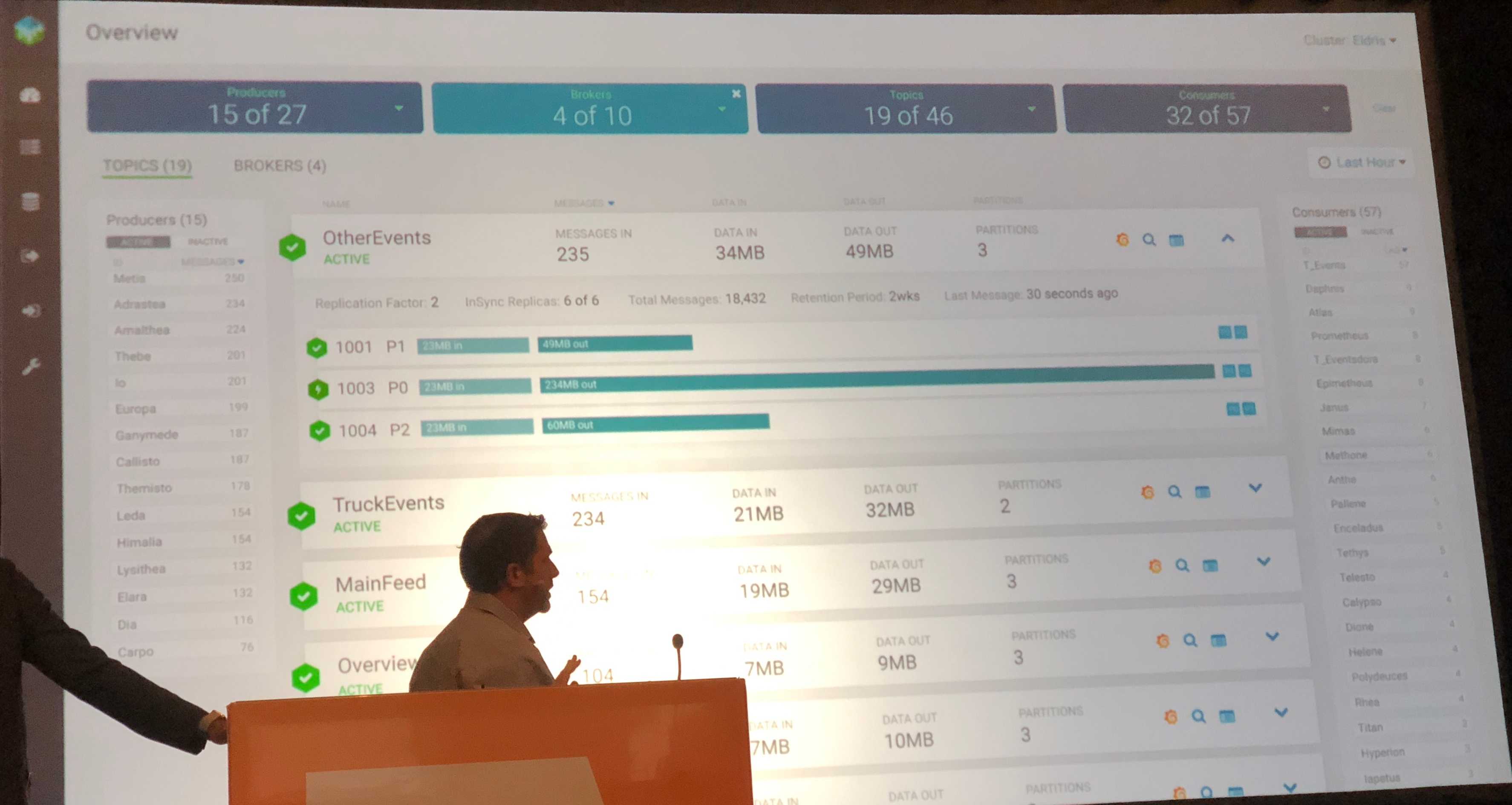
Beautiful.
This UI is the latest iteration, and, you can really see every information about a Kafka cluster at first glance: number of producers and their ids, events… On top of the UI are two tabs: Topics and Brokers. On the picture you can see the Topics tab which has been placed in first position after customers suggested it. Indeed, as an engineer and a software developer, I also would have placed the Broker tab in first position, but customer survey and opinion showed that topics is the most important part. The final user wants to know how a topic was created and he also want insights about how the broker performs with produced and consumed messages
Of course, the UI integrates with enterprise environments and kerberized clusters are supported even in the first MVP. Nowadays, you cannot have an MVP without Kerberos, how things have changed in a few years. The UI integrates with LDAP and ADs for authentication and with Ranger for authorization.
How does it work?
The manager reads JMX data from Kafka, metadata informations from Zookeeper and the main metrics from Ambari Metrics. The UI then combines these three sources to display the rich dashboard.
This UI is powered and will be available as a module of Hortonworks’ DataPlane Services (DPS). DPS runs on a single host and as an agent capable to connect to Ambari Managed clusters to get configuration information. As a consequence, one DPS host can manage several Ambari managed clusters and centralizes information on running services. Kafka Manager will be part of DPS (so neither in HDP nor HDF).
Conclusion
The demo given was really convincing. The product will be released in the next two months (around August 2018 or so) and will be part of Hortonwork’s DataPlane Services stack.
Can’t wait for it!
