


Introduction to Cloudera Data Science Workbench

Feb 28, 2019
- Categories
- Data Science
- Tags
- Azure
- Cloudera
- Docker
- Git
- Kubernetes
- Machine Learning
- MLOps
- Notebook [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Cloudera Data Science Workbench is a platform that allows Data Scientists to create, manage, run and schedule data science workflows from their browser. Thus it enables them to focus on their main task that is deriving insights from data, without thinking about the complexity that lies in the background. CDSW was released after Cloudera’s acquisition of the Data Science startup Sense.io. It is a powerful platform to automate the delivery of Machine Learning into production and push your models between edge/fog/cloud/on-premise hybrid platforms and environments.
Before digging in the features of CDSW, let’s talk a bit about the targeted audience this platform was created for.
Data scientists struggles
There is a lot, and maybe too much, hype around AI lately. Data Scientists have being referred to as rock stars because of the expectation AI could deliver to organizations as new opportunities.
A Data Scientist job consists of using data to impact the company business and operations. He gathers 3 mains skills: domain expertise, mathematics and computer science. Being a problem solver, he is expected to have good comprehension skills and to be a great communicator. He has some good math and statistic skills as well as a strong understanding of the business domain. He also has the responsibility to manipulate the data and write algorithms which are shippable into production environments. The reality of who we call Data Scientists has diverged a bit. Most of them have intermediate programming knowledge which doesn’t empower them to face the data challenges they are facing: working with batch and streaming data ingestion workflows, publishing KPI and APIs, sharing models between multiple platforms and environments, scaling or tuning performances, leveraging DevOps tools and practices, placing the code into production with security and operational constraints…
The Big Data stack is complex. Time is limited. The proliferation of tools and technologies and the pace of the industry can be overwhelming. Choosing the right tools for the right problem is crucial. The learning curve may be steep. Tools are expected to make life easier, not harder.
Data Scientists are facing many struggles to get to the right data at the right moment. Especially, in secured and operational environments. IT imposes high standards which is underestimated by companies, schools and Data Scientists. It impacts their productivity and slows down the overall progression of the projects. Hence it limits the benefits expected by companies who invest on Data Science.
That being said, let’s look at what CDSW is providing to its users and what makes it suitable for Data Scientists working with Hadoop clusters. We started testing CDSW in its first releases more than a year ago. Lately, in version 1.4, CDSW was updated with some exciting new features.
CDSW under the hood
Overview
Cloudera Data Science Workbench (CDSW) can run on-premise or in the cloud. It provides out-of-the-box secure access to Hadoop clusters. It was first developed to work with Cloudera’ Distribution of Hadoop (CDH). But very recently, and after the merge of Cloudera and Hortonworks, CDSW 1.5 is now supporting the integration of the Hortonworks Data Platform (HDP) in both 2.x and 3.x.
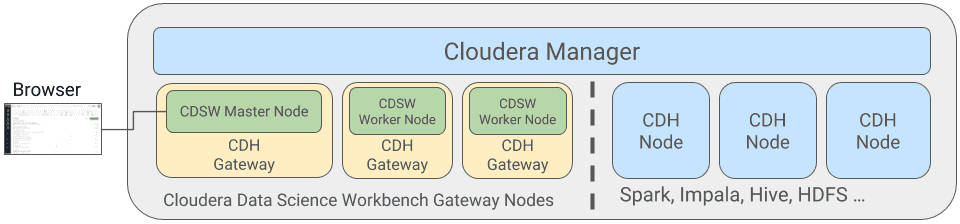
CDSW is deployed on dedicated gateway hosts. A gateway host is updated with the client configuration of the services running on the Hadoop cluster. There are two types of CDSW nodes: masters and workers nodes. A master node which is responsible for running the Web application, persisting project files, and stateful data. Workers, on the other hand, are not required, they only serve as computing units. They can be added if needed or removed depending on the users’ workloads.
CDSW is providing per-session/job resources (memory and CPU) isolation through the use of Docker containers. It delegates the orchestration of these containers to Kubernetes. At the session launch, project files, libraries, and client configurations are mounted to a newly started Docker container preconfigured with secured access to the Hadoop cluster.
This architecture is transparent to the end users. They don’t actually have to care about these components, and will only be interacting with the platform through the web UI.
Deployment types
CDSW is supporting two types of deployment. The package-based deployment and the CSD-based one. CSD stands for Custom Service Descriptor, it’s a jar file that contains the description and the binaries needed to manage, monitor and configure a service from Cloudera Manager.
The package-based deployment can be used with CDH and HDP distributions. it requires to manually install CDSW package on both master and workers gateway hosts. The gateway hosts must be managed by Cloudera manager in the case of CDH, or Ambari in the case of HDP. CDSW can be deployed on a 1-node or multi-node cluster. In the multi-node architecture, CDSW needs to be installed, configured and started on the master node. And then worker nodes can be configured to join the cluster.
The CSD-based deployment was introduced in CDSW 1.2, and it made things much easier. it gives the ability to install, upgrade and monitor Cloudera Data Science Workbench from Cloudera Manager (CM). since then, CDSW is available as a service that can be managed from CM. All that is needed is to add the Custom Service Descriptor (CSD) of CDSW to the CM Server host, install and deploy the CDSW parcel to the gateway hosts through CM and… that’s it, CDSW can be added easily as a service from CM. Unfortunately, this deployment model can only be used with a CDH cluster.
CDSW is linked to one cluster while most of our clients have at least 2 environments (DEV/PROD), deploying (job or model) from one environment to the other seems to be a point still to be addressed.
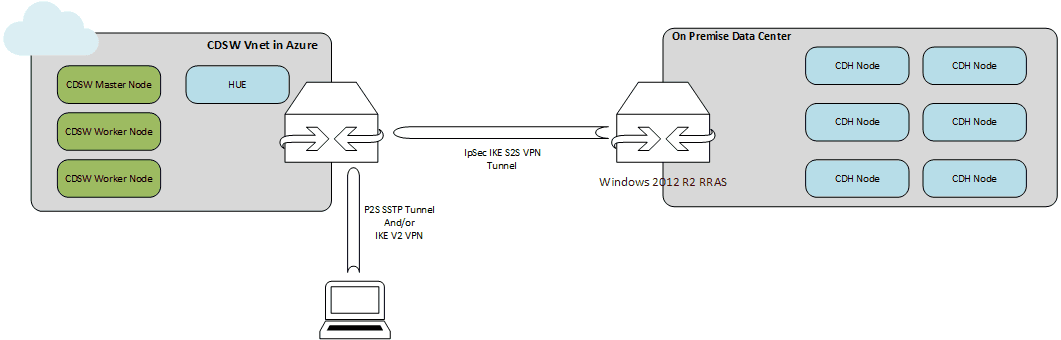
Hybrid deployment: CDSW on Microsoft Azure + CDH on-premise
We had at our disposal an on-premise deployment of CDH but no additional node to deploy CDSW. Purchasing new hardware was not an option, so we investigated a hybrid architecture: The idea was to deploy CDSW nodes on a public cloud (Microsoft Azure in our case) connected to our on-premise CDH platform. To push the concept of deploying some edge roles in the public cloud, we decided to install a CDH node running HUE on Azure too.
The recommended instance types are DS13-DS14 v2 on all hosts (the DSv2 series are memory optimized VM sizes with a high memory-to-CPU ratio, in-memory analytics is one of the targeted workloads). A quick look at cloudera director scripts shows that the VMs should use premium LRS storage, with 3 disks attached to the master and 2 to the workers. Based on the Cloudera Reference Architecture for Azure deployments, the connectivity with the on-premise data center should be based on ExpressRoute.
We went for a way lighter infrastructure, 4 standard DS4 v2 instances (1 CDSW master, 2 CDSW workers, 1 edge HUE), based on the Cloudera CentOS 7.4 image available in Azure marketplace (image including some OS level optimization for CDH but no JDK). The whole setup has been implemented by connecting the on-premise datacenter and the Azure VNET through a site to site VPN. We used Windows 2012 R2 RRAS as the on-premise gateway (we tried OpenSwan default configuration provided by Microsoft but it didn’t work, we’ll probably get back to it). On the Azure side, the Microsoft Virtual network gateway is the default choice. We also sat up a point-to-site VPN and dissociated any public IPs from the Azure VMs.
CDSW has then been installed using Cloudera Manager.
The final deployment looked like this:
The CDSW nodes are still managed by Cloudera Manager, and can access data in CDH and take advantage of Spark on YARN, so big jobs with intensive data crunching still run on the cluster made of JBOD/directly attached disks.
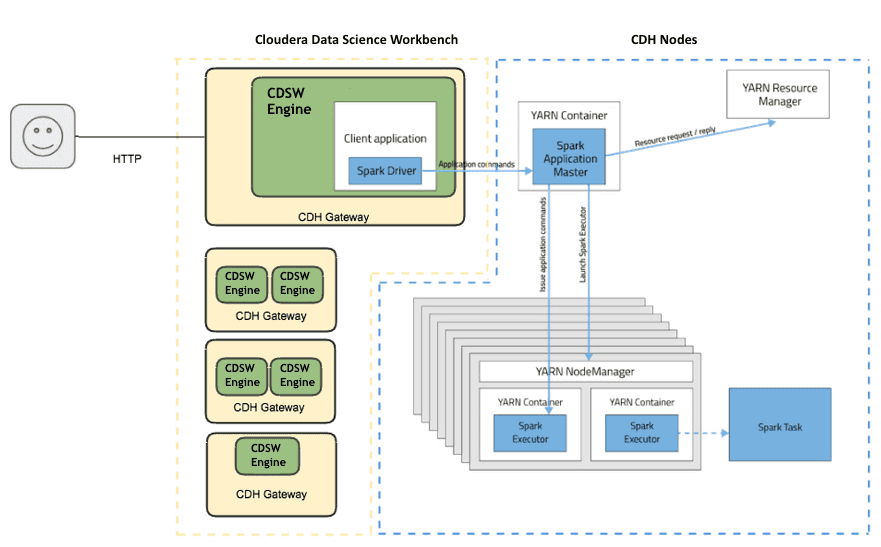
We didn’t production proof this architecture or checked if it’s supported by Cloudera, but it worked for us and definitely opened a lot of new perspectives, with new hybrid architectures at the edge, new ways to try new components, and last but not least the ability to use GPU based VMs not available on premise.
CDSW deploys and manage its own Kubernetes cluster. It’s not possible to connect it to an external cluster. It seems important to us to be able to connect to an existant cluster to profile available resources or, in this case, to pilot an Azure Kubernetes service instance.
Cloudera Data Science Workbench features and capabilities
Projects, the heart of CDSW
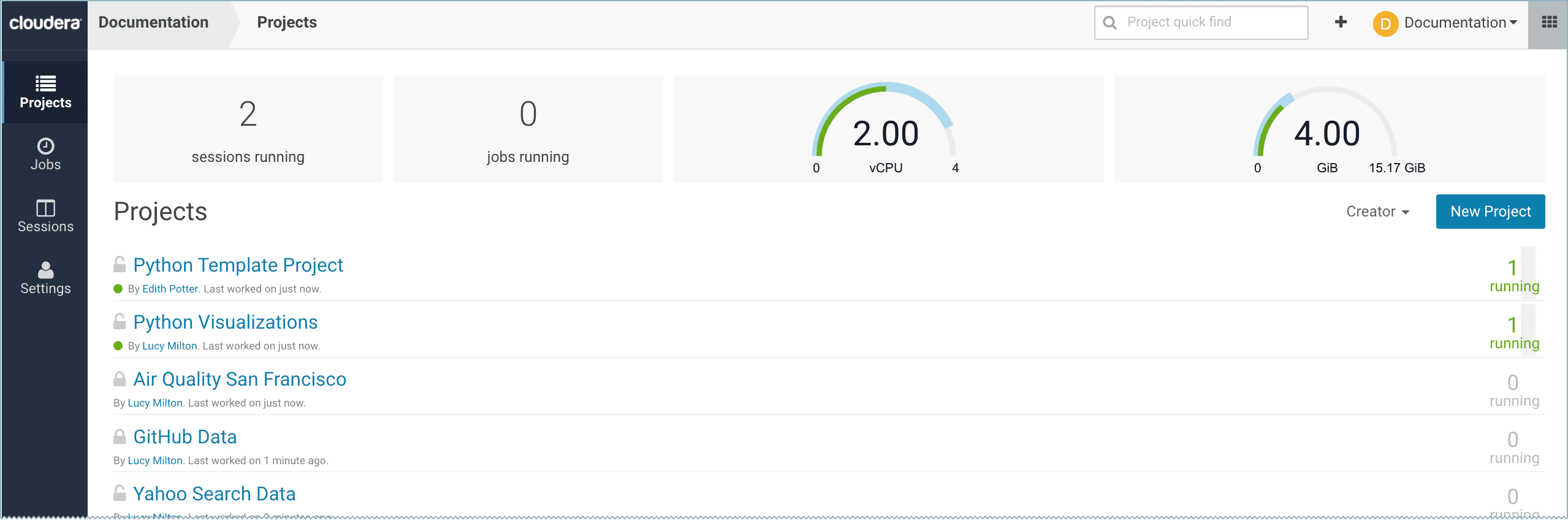
CDSW provides an intuitive and easy to use web application. That gives the ability to do all data analysis through a browser. The users can organize their work in projects. Each project is independent and serves to group the code, libs, and configuration. Project visibility can be private, team or public. If the project is Private only the owner will have access to its content. If it is in Public mode, every user will have the right to view the content. Aside from the project visibility, when there is a need to work together on the same project, which brings us to the collaboration part, the owner/admin can add collaborators to the project and grant access level to them.
Also available is the team visibility option. Colleagues working on the same projects or problems can create teams on CDSW. There is a notion of context that is used to distinguish the personal account from team accounts that a user can be part of. Now, to answer the question, the team visibility makes a project visible for the members of a team only.
The platform allows using Git to version control the projects, which is a welcome addition to ease collaboration and code sharing.
The Workbench: Where the magic happens
Now let’s look at Workbench console, it’s a simplistic IDE for R, Python, and Scala that includes a code editor, an output pan where the results are displayed, a command prompt to run commands interactively and a full web-based terminal that we will talk about later.
After opening the workbench, we need to launch a session to be able to execute the code. For each launched session, CDSW fires up an engine. It is actually a container responsible for running the code. It is providing an isolated environment per-session, while still having all that’s needed (CDH dependencies and client configuration, managed by Cloudera Manager) to allow secure access to CDH cluster services such as HDFS, Spark 2, Hive, and Impala. Each engine can be customized with a kernel. An engine runs a kernel with either an R, Python or Scala process that can be used to execute code. Engine profiles define the resources that CDSW will reserve for a particular session in term of memory and vCPU. When the session is running, the user can use the terminal provided by the UI to install any packages or libraries required, just as he would do on its local computer.
A user might want to work interactively or automate workloads, the second need can also be satisfied through Jobs.
Execute the workload
A job enables the automation of the actions that the user is doing manually, including configuring an engine, launching a session and running a workload. It launches as a batch process and provides the ability to track the results in real-time and/or configure email alerts. Each Job can be scheduled to run recurrently (every X minutes, or on an hourly, daily, weekly or monthly schedule) or to be dependent on another Job event, conditioning the execution to the success of the preceding job. The latter option enables the creation of pipelines (sequence of jobs).
There is also a feature called experiment, which can be used to run the same job with different configurations, datasets, input parameters. It gives the possibility to track different versions of code, input, and output which can be a simple variable or a whole file content. This latter feature can be beneficial in the training phase of a model, when Data Scientists need to try multiple parameters, to track its accuracy and tune accordingly.
Ship it into production
CDSW integrates smoothly with CDH, opening the access of your Data Lake and complementary data sources to the Data Scientists in a secured manner including Kerberos authentication, authorization rules, and data-in-motion encryption. By relying on Kubernetes, it leverages the benefits of containers architectures such as the operation of the platform, the speed of execution, the isolation of jobs, the scalability of the resources or the resilience of the process executions.
The workbench provides a comprehensive platform for Data Scientists to build, train and deploy Machine Learning models.
Recently, the platform allowed the teams of Data Scientists to expose the models developed as REST APIs easily, without the need for the assistance of the DevOps teams. Data Scientists only have to select a function within a project file. This function could be the implementation of a prediction model, that can be used to make predictions. CDSW will take care of the deployment of each model in an isolated environment. There is also the possibility to create up to 9 replicas of the same model with load balancing.
There is an example that can be found in the documentation of Cloudera, in which they are using CDSW to build a model that predicts the width of a flower’s petal based on the petal’s length. this example leverages the capabilities of CDSW to train a model using Experiments, to build and expose the model.
The image below present the creation of a model. It is needed to specify the function name that will be exposed, which is “predict” in the example, and the script which contains this function.
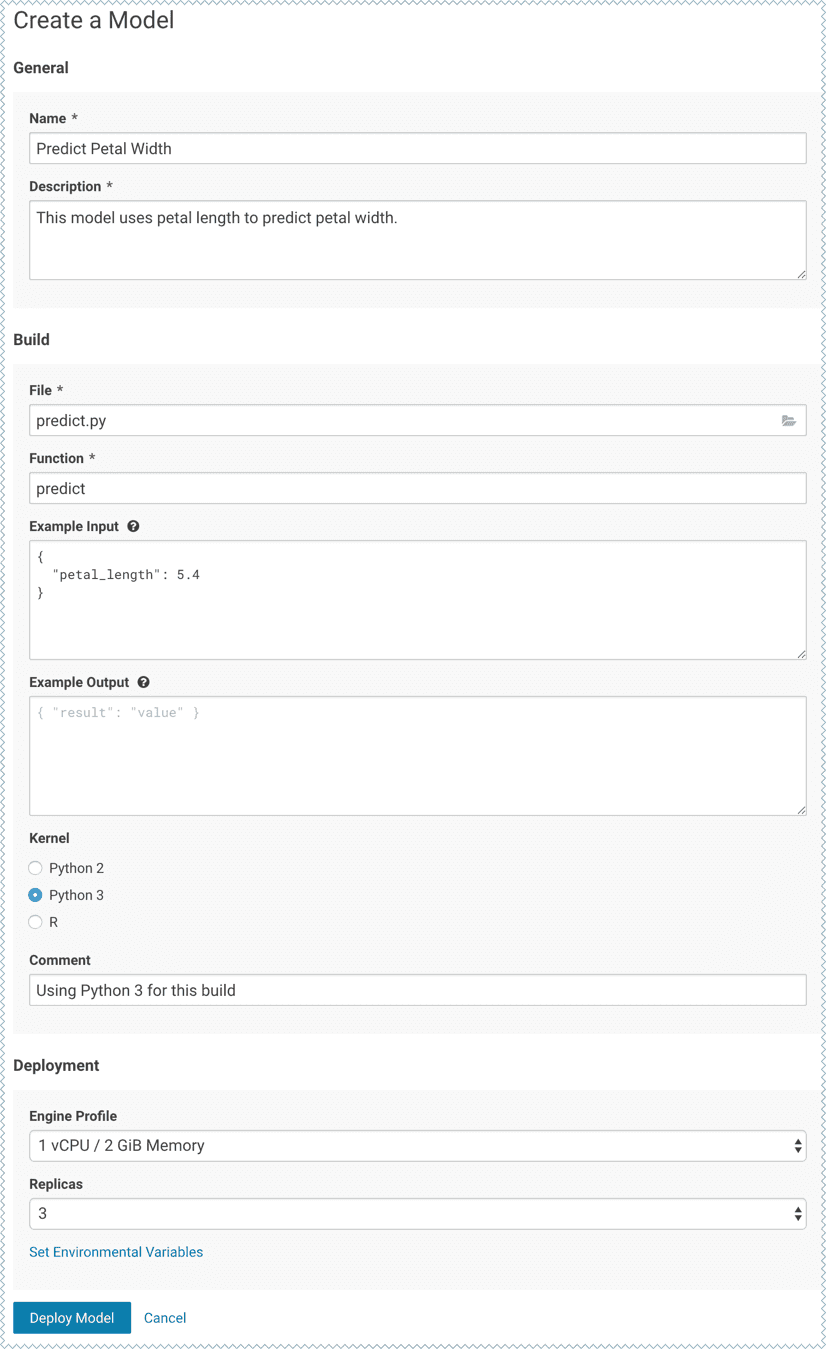
The predict function loads a trained model, computes the prediction based on the input parameters and returns the output. Here is the content of the file predict.py:
# Read the fitted model from the file model.pkl
# and define a function that uses the model to
# predict petal width from petal length
import pickle
import numpy as np
model = pickle.load(open('model.pkl', 'rb'))
def predict(args):
iris_x = np.reshape(float(args.get('petal_length')), (-1,1))
result = model.predict(iris_x)
return result[0][0]CDSW gives the ability to monitor the model once it has been deployed. For each replica of the model, there is a bunch of useful informations that are displayed in the Monitoring page. Such as the replica status, the number of processed requests, the number of succeeded and failed operations and its logs.
Also, it can be interesting if CDSW in the future could rely on federation to deploy ML models on architectures like Edge and Fog Computing.
These features can make the data scientist’s work smooth. Being able to work with data without limits and to develop and deploy machine learning applications at scale with the favorite tools/libs. Being all the time around teams with different skills and experiences. Going faster and efficiently from the exploration phase to production. All that without caring about the details nor the security around data can make a huge impact on the business.
Conclusion and thoughts
CDSW was mainly built to provide the teams of Data Scientists the flexibility and simplicity they need to be innovative and productive, without neglecting the security concerns of the IT teams. Besides the fact that it only works with Hadoop, the product is great and it doesn’t need much time to deploy nor to master and get going.
The overall user experience is nice, but there are some points that which I think need improvement. Especially, the security part when collaborating on the same projects. A collaborator can use the identity of a user through its running sessions to interact with the Hadoop cluster. I think that the owner of the session should have the ability to manage the permissions that the collaborators have. Less important but still needs to be mentioned, the Scala language lovers can be a bit disappointed. The code completion is available just for R and Python, still not for Scala which I think is a must-have functionality. The Scala Experiments lacks functionalities. For instance, specifying arguments that will be used during the experiment run, and the capability of tracking metrics and the content of files. The Scala models are also not supported. Finally, the addition of some out-of-the-box visualization capabilities like the ones provided by Zeppelin for example, would be more than welcome.
