


Machine Learning model deployment

Sep 30, 2019
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
“Enterprise Machine Learning requires looking at the big picture […] from a data engineering and a data platform perspective,” lectured Justin Norman during the talk on the deployment of Machine Learning models at this year’s DataWorks Summit in Barcelona. Indeed, an industrial Machine Learning system is a part of a vast data infrastructure, which renders an end-to-end ML workflow particularly complex. The challenges linked to the development, deployment, and maintenance of the real-world ML systems should not be overlooked as we pursue the finest ML algorithms.
Machine Learning is not necessarily meant to replace human decision making, it is mainly about helping humans make complex judgment base decisions.
The talk I attended, Machine Learning Model Deployment: Strategy to Implementation, was given by Cloudera’s experts, Justin Norman and Sagar Kewalramani. They gave a presentation on the challenges encountered by an end-to-end ML workflow, focusing on delivering Machine Learning to production.
The AI pyramid of needs
More and more businesses use Machine Learning and AI to improve their services and get ahead of the competition. Unfortunately, many enterprises go through the AI transformation without a proper data platform, nor with the understanding of deploying ML models. Several Big Data and Data Science technical needs should be satisfied first:
- Big Data infrastructure to collect, ingest, store, clean, and move data between different parts of the system usually handled by Data Engineers
- Analytics strategies to explore, visualize, transform, and preprocess data into useful ML input variables
- A framework to experiment with algorithms, collaborate on them, and to deploy them while keeping track of all the models’ parameters, accuracy, and performance
- Established baseline with simplest Data Science algorithms
Apart from those, you need to keep some important characteristics of ML Platforms in mind:
- A deep integration with business processes
- Continuous delivery (CI/CD like any classical code
- Close feedback loop
In the presentation, these needs were represented with a pyramid, in a similarity to Maslow’s hierarchy of needs. The points from the list above are viewed as levels of a pyramid, starting from the pyramid’s base for the first point. This concept, also known as “The AI Hierarchy of Needs”, helps to understand an important point:
There is no artificial intelligence (that corresponds to self-actualization) without a basic infrastructure for calculations (food, water, warmth). You must be able to reason about the past and make basic insights about the future before you can successfully use Machine Learning algorithms. You cannot expect a neural network to give great results if the used dataset is misunderstood and unprepared.
Often aiming the efforts at fundamental system aspects can improve the accuracy of predictions more than adjusting the current predictive algorithm. For example, working on the representation of the input data can lead to better results than tuning the ML model. When all basic engineering needs are satisfied and the accuracy isn’t sufficient, only then efforts should be directed to more complex algorithms.
Hidden technical debt in ML systems
The importance of software engineering work within an enterprise ML system is evident considering Google’s paper entitled “Hidden Technical Debt in Machine Learning Systems” (pdf). In it, the authors argue that only a small fraction of real-world ML systems is composed of the ML code. The ML code can be even less than 10% of the whole ML system.
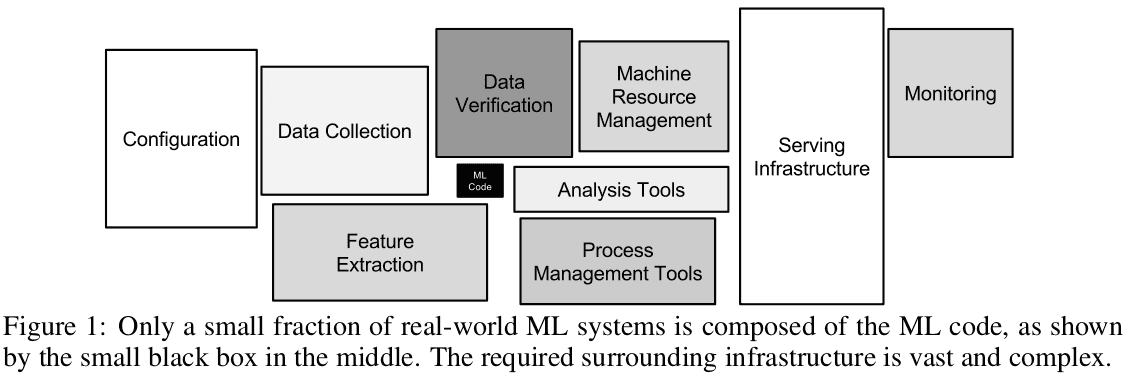
Although the ML code drives all the decisions, it’s almost irrelevant from the perspective of the whole software system that has to be developed to solve a problem for an end-user. The tiny ML part providing decisions is important, but there are numerous other important components in the system. Spending time on the design of a system’s architecture, model hardening, deployment, monitoring, etc. is at least as valuable as spending time on ML.
Challenges of an end-to-end ML workflow
An ML workflow should address all the pyramid’s levels to ensure that it doesn’t incur a hidden technical debt. In an attempt to summarize the first half of the talk, three main challenges in an end-to-end ML workflow can be identified: complexity, scale, and experimentation. The challenges aren’t exclusive, they are all related to each other.
Complexity
Enterprise Machine Learning workflow requires:
- Data infrastructure and a lot of data processing to provide prepared data for ML models
- Building ML models through many experiments
- A great deal of effort to deploy ML models into production and monitor them
Three distinct professions can be associated with the points of the list above: Data Engineer, Data Scientist, and DevOps Engineer, respectively. They have distinct views on the project, different expectations about the outputs, and use different tools. Example technologies present in ML systems are Hadoop, Kafka, Spark, Tensorflow, xgboost, Docker, and Kubernetes. These tools must be integrated, and the mechanism to securely move data between them must be implemented.
The differences in people’s reasoning and toolsets can lead to issues that can undermine the whole project. For example, Data Scientists tend to produce code using notebooks and packages that can’t be parallelized and aren’t production-ready as it can’t be deployed on distributed systems. A notebook is like a specification (recipe) for the desired output model (cake). As Data Engineers and DevOps aren’t experts in Data Science, they may misunderstand the recipe and a different cake is baked. An ML model in production could turn out to mismatch the expected product and fail to satisfy the use case, simply due to misinterpretations between teams. Additional complexity arises from the fact that each use case needs a different specific ML model, different data preparation, and special considerations for the deployment.
Scale
Large scales are an important characteristic of industrial Machine Learning. An ML solution may need to scale to serve millions of clients, which implies big datasets. A lot of computing power is needed to preprocess these big datasets and use them for training ML models. Big Data technologies and techniques are generally used to provide that computing capability through parallel computing in a secured cluster environment. The deployment of trained ML models into production at large scales also means the need for DevOps strategies and tools.
Experimentation
Creating ML models is a gradual process involving numerous experiments. A unique challenge to ML is keeping track of those experiments. One has to provide a Data Scientist with a mean to book keep information from each training of the model: its parameters, used libraries, versions, etc.
CI tools and systems have to be robust enough to allow flexibility for different ML models (each has specific dependencies) and compatibility to rapidly scale, promote and downgrade ML models in production. Then, many ML models have to be monitored and managed.
Strategies and lifecycle of end-to-end ML workflows
A product with ML capabilities has to treat the ML pipeline as a part of the data infrastructure. Similarly, the ML output has to be viewed as a subset of the results obtained in the bigger system. Without integration, putting ML models into production would take too long to stay competitive.
Three parts of the ML workflow will be addressed:
- Versioned and reproducible ML model training
- ML model deployment
- ML model management in production
As an important remark, whatever tool is used for the development of ML models, it’s preferable to avoid moving data around. Work on data where it resides. Instead of sending data across multiple platforms, select a single scalable distributed solution such as inside the on-premise or the cloud environment.
it is preferable to avoid moving data around such as inside the on-premise or the cloud environment where the data reside.
Versioned and reproducible ML model training
Machine Learning models are created in an iterative process. A final ML model that goes into production is obtained through many experiments, in which models’ parameters and hyperparameters are gradually adjusted in a trial-and-error fashion.
Unfortunately, keeping track of those experiments isn’t a common practice and intermediary versions leading to the final model tend to get lost. An ML workflow should provide a way to easily track and manage emerging ML models.
A final model should be preceded by a series of snapshots of previous models’ meta-information such as who and when to create the model, the model’s code, the dependencies configurations, the parameters, the comments, etc.
Two examples of projects specifically addressing versioned, reproducible ML model training are:
ML model deployment
The deployment should be fast and adaptive to business needs. The deployed models should be monitored and easy to manage. Three main deployment patterns can be employed, depending on the business use case:
- Batch deployment - ML model is used in an offline fashion. For instance, daily reports with predictions are generated for managers to aid their decisions
- Real-time deployment - ML model is used to automate time-sensitive decisions. For example, in recommendation systems and fraud detection systems
- Edge deployment - ML model is used in time-critical systems where the decision needs to be taken instantly. Both previous deployment types have a central unit running ML model, whereas edge deployments have the model executed directly on the external system. For example, in an autonomous drone
ML model can be deployed for example as a Java/C++/Python application, Spark application, or as a REST API. The deployment of the model as an application is more costly and slower than the API powered model deployment but offers more reliability, higher speed, and better security. The deployment format remains a decision largely dependent on the use case.
Use case conditions what kind of pattern deployment is applicable, which in turn conditions the deployment format and used tools. For example, in batch deployment scenarios, a Scala Spark job running on a Hadoop cluster could be chosen. In a real-time scenario, one needs a stream processing engine like Flink or Kafka Stream. Finally, deployment at the edge may demand rewrites to C/C++ and specific processor architectures.
ML model management in production
Similarly to keeping track of experiments in the training phase, ML models should be tracked in production ML.
- At the deployment, all the metadata should be collected: Who and when deployed the model, what is the model, which version of it, the parameters, etc.
- The performance of deployed models must be monitored and various metrics collected such as accuracy, F1 score (which measures a test’s accuracy), business KPIs, resource usage, response time, etc. A degrading model needs to be identified and its performance metrics analyzed. Which metric drifted, how much, when, etc.
The tracking of ML models in production allows the Data Scientists to reevaluate models and reconsider the selected learning algorithm. Also, one could deploy a few variants of a model and compare them. The comparison should be made based on performances, statistical significance, and practical significance for the use case.
There are tools which target specifically ML model management (e.g. Datmo), but more commonly this is a feature of the whole Machine Learning platform.
Containerization
As mentioned earlier, each model deployment format corresponds to the specific use case and has many specific requirements: language, framework, libraries, packages. Often, these dependencies must have a specific version. This creates a plethora of different software prerequisites, often conflicting ones. Installing different software on cluster’s nodes may be a hurdle due to version mismatches between dependencies and other software conflicts. Containerization can be a solution. We can leverage containerization to host ML models in the isolated Docker environment that has all the needed software already packed. Different versions of the project code could be packed into multiple Docker containers with different Docker images.
Kubernetes is a great tool to deploy and manage scalable containerized applications. It’s commonly used for orchestration of Docker containers. Alternatively, Hadoop 3 can orchestrate Docker containers.
Machine Learning platforms
Just a few years ago, there were no tooling to build ML systems at scale. Big companies had to create their platforms such as Uber’s Machine Learning Platform, Michelangelo. In a way, such proprietary platforms created standards for ML workflows which were then adopted in the open source ecosystem.
Nowadays, a couple of Machine Learning platforms/toolkits are available to aid the ML workflow. The most notable option that was pitched during the talk is Cloudera Data Science Workbench (CDSW) which integrates with the commonly used data platforms CDH and HDP.
An interesting option for ML projects on a Hadoop cluster is Apache’s Hadoop Submarine which I discovered during another talk, Hadoop {Submarine} Project: Running Deep Learning Workloads on YARN given by Sunil Govindan and Zhankun Tang. Submarine allows computing unmodified Tensorflow applications on a Hadoop cluster. Submarine leverages Hadoop YARN for orchestration of ML workloads, and Hadoop HDFS to collect and store data in the system. This solution is possible because of Hadoop 3 supports GPU scheduling and isolation on YARN, as well as Docker containers.
MLflow platform seems like a promising choice. Yet another 2 alternatives are Polyaxon and Kubeflow which are suitable for use with Kubernetes.
Conclusions
AI and Machine Learning are going through the industrialization phase. A large scale, complexity, and the experimental character of training ML models are the main challenges in the enterprise ML workflow. New tools and platforms are being created to develop, train, and deploy ML models in the industry.
