


Insert rows in BigQuery tables with complex columns

Nov 22, 2019
- Categories
- Cloud Computing
- Data Engineering
- Tags
- GCP
- BigQuery
- Schema
- SQL [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Google’s BigQuery is a cloud data warehousing system designed to process enormous volumes of data with several features available. Out of all those features, let’s talk about the support of Struct data types and repeated columns.
Complex columns
Struct type columns (we’ll call them complex columns) allow you to define the content of the column as a struct with multiple typed properties (STRUCT).
For example, let’s say we want to store the following informations about a person:
- First name
- Last name
- Date of birth
- Address
- Street
- City
- Zip code
- Country
In a traditional SQL system, you could make a second table to keep the addresses and have a foreign key on your person’s row or flatten the address object in the person’s row, or a number of other possibilities.
With BigQuery, complex columns allows us to store addresses as objects so we’re adding only one column to our schema and we don’t have to use joins to access the information.
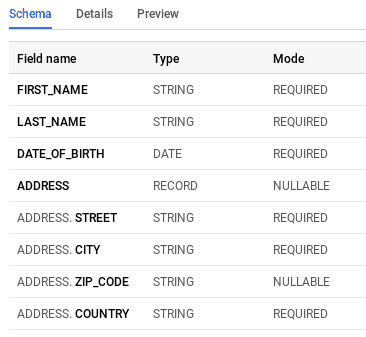
To define the schema of a complex column, you set the column type value to RECORD and add the property fields which is an array of fields. Here’s what the schema of our table would look like in JSON:
[
{
"name": "FIRST_NAME",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "LAST_NAME",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "DATE_OF_BIRTH",
"type": "DATE",
"mode": "REQUIRED"
},
{
"name": "ADDRESS",
"type": "RECORD",
"mode": "NULLABLE",
"fields": [
{
"name": "STREET",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "CITY",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "ZIP_CODE",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "COUNTRY",
"type": "STRING",
"mode": "REQUIRED"
}
]
}
]When reading the schema in BigQuery’s UI, the complex column will first appear with it’s defined type and mode (record, nullable) and then be repeated for each fields with the format column.field and the type and mode of the field.
Now that the schema is defined, let’s see how to insert data. There’s a lot of documentation from Google on how to insert rows but, surprisingly, not with plain old SQL INSERT INTO (at publication time of this article). Basically, you set the complex values between parenthesis (as a tuple). However, to not have issues with the fields type you should specify the columns you are inserting into and might have to cast the values if your inserting NULL. For example:
INSERT INTO `project.dataset.person_table` (FIRST_NAME, LAST_NAME, DATE_OF_BIRTH, ADDRESS)
VALUES
("Jeff", "Smith", "1980-10-10", ("#1 7th Avenue", "New York", "100011", "United States")),
("Charlotte", "Lalande", "1990-01-01", ("3Bis Avenue des Champs Élysées", "Paris", STRING(NULL), "France"))To display complex columns, BigQuery’s UI will apply the same logic as to the schema, each field of the complex column appears and is named column.field.

Repeated columns
BigQuery also allows us to define repeated columns, which basically amounts to setting the type to ARRAY.
We’ll update our previous table to apply the following changes:
- A person can have middle names
- A person can have a secondary adresses which we’ll translate as a column of repeated adresses.
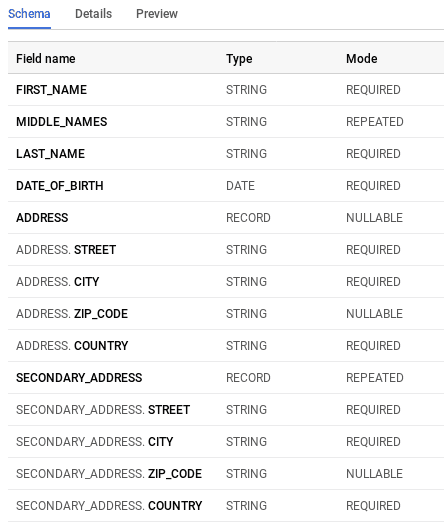
Here’s our new schema:
[
{
"name": "FIRST_NAME",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "MIDDLE_NAMES",
"type": "STRING",
"mode": "REPEATED"
},
{
"name": "LAST_NAME",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "DATE_OF_BIRTH",
"type": "DATE",
"mode": "REQUIRED"
},
{
"name": "ADDRESS",
"type": "RECORD",
"mode": "NULLABLE",
"fields": [
{
"name": "STREET",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "CITY",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "ZIP_CODE",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "COUNTRY",
"type": "STRING",
"mode": "REQUIRED"
}
]
},
{
"name": "SECONDARY_ADDRESS",
"type": "RECORD",
"mode": "REPEATED",
"fields": [
{
"name": "STREET",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "CITY",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "ZIP_CODE",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "COUNTRY",
"type": "STRING",
"mode": "REQUIRED"
}
]
}
]BigQuery UI’s will display them in the schema like any other column except that its mode is REPEATED.
To insert in a repeated field you have to set the value to [VALUE1, VALUE2, ...]:
INSERT INTO `project.dataset.person_table` (FIRST_NAME, MIDDLE_NAMES, LAST_NAME, DATE_OF_BIRTH, ADDRESS, SECONDARY_ADDRESS)
VALUES
("Jeff", ["Pierre", "Jack"], "Smith", "1980-10-10", ("#1 7th Avenue", "New York", "100011", "United States"), [("3Bis Avenue des Champs Élysées", "Paris", "75008", "France")]),
("Charlotte", ["Marie"], "Lalande", "1990-01-01", ("3Bis Avenue des Champs Élysées", "Paris", STRING(NULL), "France"), NULL)To show the repeated fields, the UI will add more lines to the same row: each line containing a new value of the repeated field, and non-repeated fields will be grayed out.

One thing to note, repeated fields are not optimized for querying. If you are looking to filter a data from a repeated field in your table, it is better to duplicate this data on a specific column or simply not to put it in the repeated field.
Congratulations, now you know how to manually insert data in complex & repeated columns!
