


Hadoop Ozone part 3: advanced replication strategy with Copyset

Dec 3, 2019
- Categories
- Infrastructure
- Tags
- HDFS
- Ozone
- Cluster
- Kubernetes
- Node [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Hadoop Ozone provide a way of setting a ReplicationType for every write you make on the cluster. Right now is supported HDFS and Ratis but more advanced replication strategies can be achieved. In this final part we will discuss the flaws in common replication strategy and present the Copyset replication.
This article is the third and last part of a three-part series presenting Ozone, demonstrating its usage and proposing an advanced replication strategy using Copyset.
Random replication in HDFS
In HDFS each file is splitted into blocks. Each block is replicated on three random nodes on the cluster. The only rule enforced is that these 3 datanodes cannot be on the same rack. This is the “Random Replication”.
The benefits of this strategy are:
- Easy to understand and develop.
- Simple to maintain (adding or removing datanodes is a no-brain)
- Load is equally distributed across all nodes
Now let’s discuss data loss. Since blocks are scattered equally across datanodes. Losing 3 datanodes on different racks will cause data loss if the cluster contains at least 3 times more blocks than datanodes.
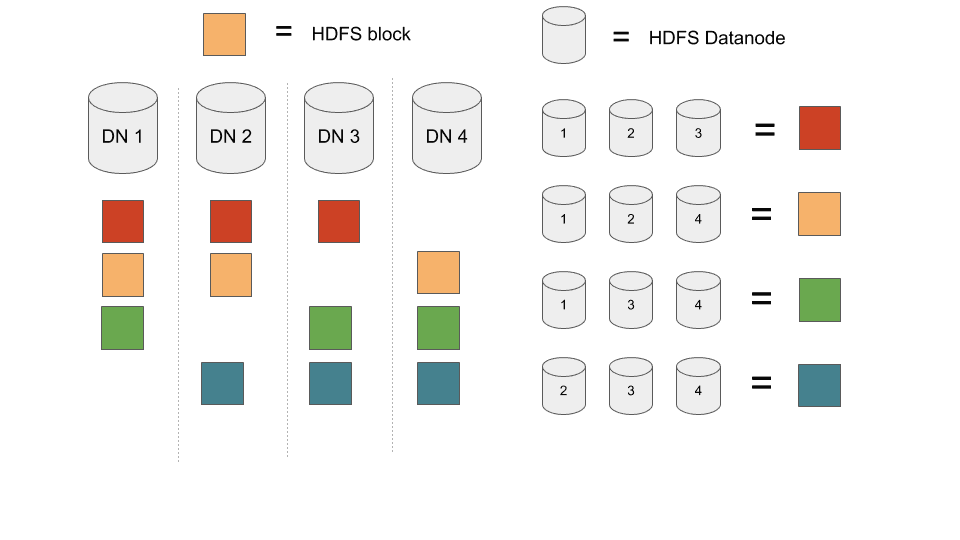
On this distribution, the load is perfectly balanced (as all things should be) with 4 data blocks per node. In the event of a 3 nodes crash there will be data loss since each three nodes combination holds a particular set of blocks.
While it is very unlikely to have 3 DataNode or 3 disks to fail on small cluster, the probability grow with the size of the cluster. Facebook or Yahoo already encountered power breakout on a whole datacenter. On the restart of the cluster it can happen that 1% of the DataNodes will not restart. We can easily count that on a 300 DataNodes cluster 1% is equal to 3 Datanodes which means data will be lost.
Data recovery is really not cheap and comes with high fixed costs:
- Recompute all the data
- Recover the data from some other sources or on the disks that failed
These operations are very expensive and does not really scale with the amount of data lost in the event.
This is the main problem that try to solve CopySet Replication: reduce the frequency of data loss at the cost of more data lost.
Copyset replication
The principle of CopySet can be easily understood on a 6 nodes cluster with a replication factor of 3.
Using typical HDFS replication, a set of blocks can be on any 3 nodes among 6: 20 sets. Once the cluster contains 21 blocks or more, data will be lost in the event of a 3 nodes crash.
Using copyset: we fix that we only use the set (1,2,3) and (4,5,6)
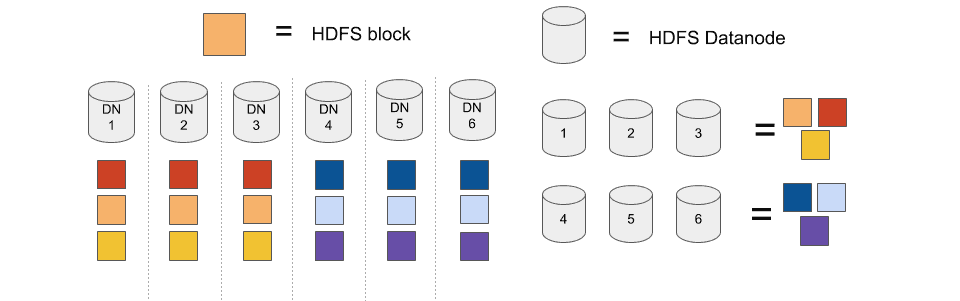
On this configuration blocks can be replicated on only 2 sets. Data will be lost if and only if we lose all 3 nodes of one of this set.
Let’s do a bit of math. On a 300 nodes cluster we lost 1% of the machine (3 nodes), it means we will lose one set.
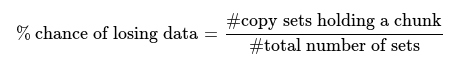
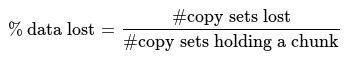
On the random replication cluster each set contains at least one chunk, the probability of data lost is 100%. 3 nodes among 300 is 4455100 sets, we will lose on average 1/4455100=0.00002% of our data.
On the copyset cluster, we only write to 100 differents sets. Losing one these sets means losing 1% of our data. But losing one set is very unlikely since it is only 100/4455100=0.002%.
| % chance of losing data | % of data loss | |
|---|---|---|
| Random replication | 100 | 0.00002 |
| Copyset replication | 0.002 | 1 |
Conclusion
Copyset replication is all about compromise. Are you willing to lose data very rarely at the cost of more data lost every incident?
Such questions are to be answered when using a very large storage infrastructure storing critical data. Knowing the flaw of the current replication strategy is fundamental.
Ozone allowing more complex replication like Copyset is very promising.
