


Modern Python part 3: run a CI pipeline & publish your package to PiPy

By Faouzi BRAZA
Jun 28, 2021
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
To propose a well-maintained and usable Python package to the open-source community or even inside your company, you are expected to accomplish a set of critical steps. First ensure that your code is unit tested. Second respect the common writing and format styles. Automate these steps and integrate them in a continuous integration pipeline to avoid any regression that stems from modifications applied to your source code. Finally, provide enough documentation for future users. Once done it is common to publish your Python package on the Python Package Index (PyPI). Here we are going to see how to accomplish each of these steps using Poetry, Tox and GitHub Actions. The code used for our use case can be found on our repository.
This article is the last one from a series of three in which we share our best practices.
- Part 1: project initialization with pyenv and poetry
- Part 2: unit testing and commit enforcement
- Part 3: CI pipeline with GitHub Actions and publication on PiPy
Automate linter checks and tests with tox
If not done, activate your virtual environment.
poetry shellTo check the conformity of our code, we use a couple of packages that are going to evaluate if the code respects the common Python writing guidelines. Then, to automate their execution as well as our unit tests, we use tox. To install them run:
poetry add black flake8 pylint tox --devtox and poetry don’t work well together by default. They are somewhat redundant. To use them together, we need to implement a few tricks (see issues 1941 and 1745). tox install its own environment and dependencies to run its tasks. But to install dependencies, you have to declare the command poetry install in our tox configuration. This brings redundancy and can lead to some issues. Moreover, this does not allow to install developers dependencies needed to execute our tests. It is more productive to let tox use the poetry.lock file to install necessary dependencies. For this, I advise you to use the tox-poetry-installer package developed to solve these problems:
poetry add tox-poetry-installer[poetry] --devNow we declare our tox configuration in a tox.ini file whose content is:
[tox]
envlist = py38
isolated_build = true
[testenv]
description = Linting, checking syntax and running tests
require_locked_deps = true
install_dev_deps = true
commands =
poetry run black summarize_dataframe/summarize_df.py
poetry run flake8 summarize_dataframe/summarize_df.py
poetry run pylint summarize_dataframe/summarize_df.py
poetry run pytest -vYou can see two sections here:
[tox]: Define the global settings for yourtoxautomation pipeline including the Python version of the test environments.[testenv]: Define the test environments. In our case we have some extra-variablesrequire_locked_depsandinstall_dev_depsthat are brought by the tox-poetry-installer package.require_locked_depsis to choose whether or not you wanttoxto harness thepoetry.lockfile to install dependencies.install_dev_depsis to choose iftoxinstalls the developer dependencies.
Refer to the
toxdocumentation to learn more about the configuration as well as thetox-poetry-installerdocumentation to learn more about it extra configuration.
Run the tox pipeline:
tox
py38 run-test: commands[0] | poetry run black summarize_dataframe/summarize_df.py
All done! ✨ 🍰 ✨
1 file left unchanged.
py38 run-test: commands[1] | poetry run flake8 summarize_dataframe/summarize_df.py
py38 run-test: commands[2] | poetry run pylint summarize_dataframe/summarize_df.py
************* Module summarize_dataframe.summarize_df
summarize_dataframe/summarize_df.py:1:0: C0114: Missing module docstring (missing-module-docstring)
summarize_dataframe/summarize_df.py:4:0: C0103: Argument name "df" doesn't conform to snake_case naming style (invalid-name)
summarize_dataframe/summarize_df.py:11:4: C0103: Argument name "df" doesn't conform to snake_case naming style (invalid-name)
summarize_dataframe/summarize_df.py:23:4: C0103: Argument name "df" doesn't conform to snake_case naming style (invalid-name)
summarize_dataframe/summarize_df.py:43:0: C0103: Argument name "df" doesn't conform to snake_case naming style (invalid-name)
------------------------------------------------------------------
Your code has been rated at 7.62/10 (previous run: 7.62/10, +0.00)
ERROR: InvocationError for command /home/fbraza/Documents/python_project/summarize_dataframe/.tox/py38/bin/poetry run pylint summarize_dataframe/summarize_df.py (exited with code 16)
________________________________________________________ summary ________________________________________________________________
ERROR: py38: commands failedAn error is raised because pylint shed light on some style inconsistencies. By default, tox quits if any warnings or errors occurred during the execution of the commands. The errors are by themselves quite explicit. After correcting them, run again the pipeline:
tox
# shorten for brevety [...]
py38 run-test: commands[0] | poetry run black summarize_dataframe/summarize_df.py
All done! ✨ 🍰 ✨
1 file left unchanged.
py38 run-test: commands[1] | poetry run flake8 summarize_dataframe/summarize_df.py
py38 run-test: commands[2] | poetry run pylint summarize_dataframe/summarize_df.py
--------------------------------------------------------------------
Your code has been rated at 10.00/10 (previous run: 10.00/10, +0.00)
py38 run-test: commands[3] | poetry run pytest -v
================================================= test session starts =============================================================
platform linux -- Python 3.8.7, pytest-5.4.3, py-1.10.0, pluggy-0.13.1 -- /home/fbraza/Documents/python_project/summarize_dataframe/.tox/py38/bin/python
cachedir: .tox/py38/.pytest_cache
rootdir: /home/fbraza/Documents/python_project/summarize_dataframe
collected 2 items
tests/test_summarize_dataframe.py::TestDataSummary::test_data_summary PASSED [ 50%]
tests/test_summarize_dataframe.py::TestDataSummary::test_display PASSED [100%]
================================================= 2 passed in 0.30s ===============================================================
______________________________________________________ summary ____________________________________________________________________
py38: commands succeeded
congratulations :)Perfect. The tox automation pipeline succeed locally. The next step start implements the CI pipeline with GitHub Actions.
Continuous Integration with GitHub Actions
GitHub Actions make it easy to automate all your software workflows. This service is event-driven meaning that a set of commands is triggered when a specific event occurs. Such events could be a commit pushed to the branch or a pull request. GitHub Actions are pretty convenient to run all needed tests against your code.
Most importantly, GitHub Actions provide the ability to test your Python package using several Python versions and on different operating systems (Linux, macOS and Windows). The only thing you need is an existing repository and a .github/workflows/ file:
mkdir -p .github/workflows
touch .github/workflows/ci.ymlThe content of the .github/workflows/ci.yml file is:
name: CI Pipeline for summarize_df
on:
- push
- pull_request
jobs:
build:
runs-on: ${{matrix.platform}}
strategy:
matrix:
platform: [ubuntu-latest, macos-latest, windows-latest]
python-version: [3.7, 3.8, 3.9]
steps:
- uses: actions/checkout@v1
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v2
with:
python-version: ${{ matrix.python-version }}
- name: Install dependencies
run: |
python -m pip install poetry
poetry install
- name: Test with tox
run: poetry run toxA few words about the different fields:
on: this field defines the type of event that is going to trigger the pipeline.jobs: this field defines the multiple steps of your pipeline. They run in an instance of a virtual environment.build: this is where all the magic happens:- The
strategy.matrix.platformfield defines the different OS you want to use to test your package. Use templating to pass these values to thebuild.runs-onfield (${{matrix.platform}}) . - The
strategy.matrix.python-versionfield defines the different versions of Python you want to use to test your package. - The
stepsfield permits you to specify which actions you use (steps.uses) and which command you want to run (steps.run)
- The
Before finishing, alter the tox.ini and pyporject.toml files accordingly. Initially we chose the 3.8 Python version for tox. But we want it to be compatible with 3.7 and 3.9. For the pyproject.toml file, choose a version expected to be compatible with your package. Here we choose to make our package compatible from 3.7.1 and above. Below are the changes added to our files:
# content of: tox.ini
[tox]
envlist = py37,py38,py39
isolated_build = true
skip_missing_interpreters = true
[...]# content of: pyproject.toml
[...]
[tool.poetry.dependencies]
python = "^3.7.1"
[...]When you modify the
pyproject.tomlfile, always run thepoetry updatecommand that can check some unexpected incompatibilities between your dependencies and the version of Python you wish to use.
To finish, we are going to install a package, called tox-gh-actions, to run tox in parallel on GitHub while using several versions of Python:
poetry add tox-gh-actions --devThe pipeline is ready. Add, commit and push your changes to see the pipeline running:
echo "!.github/" >> .gitignore
git add .gitignore
git commit -m "build: update .gitignore to unmask .github/ folder"
git add pyproject.toml tox.ini poetry.lock `.github/workflows/ci.yml`
git commit -m "build: tox pipeline + github actions CI pipeline"Go to your GitHub repository and click on the Actions tab:

You see all the previous and ongoing pipelines:
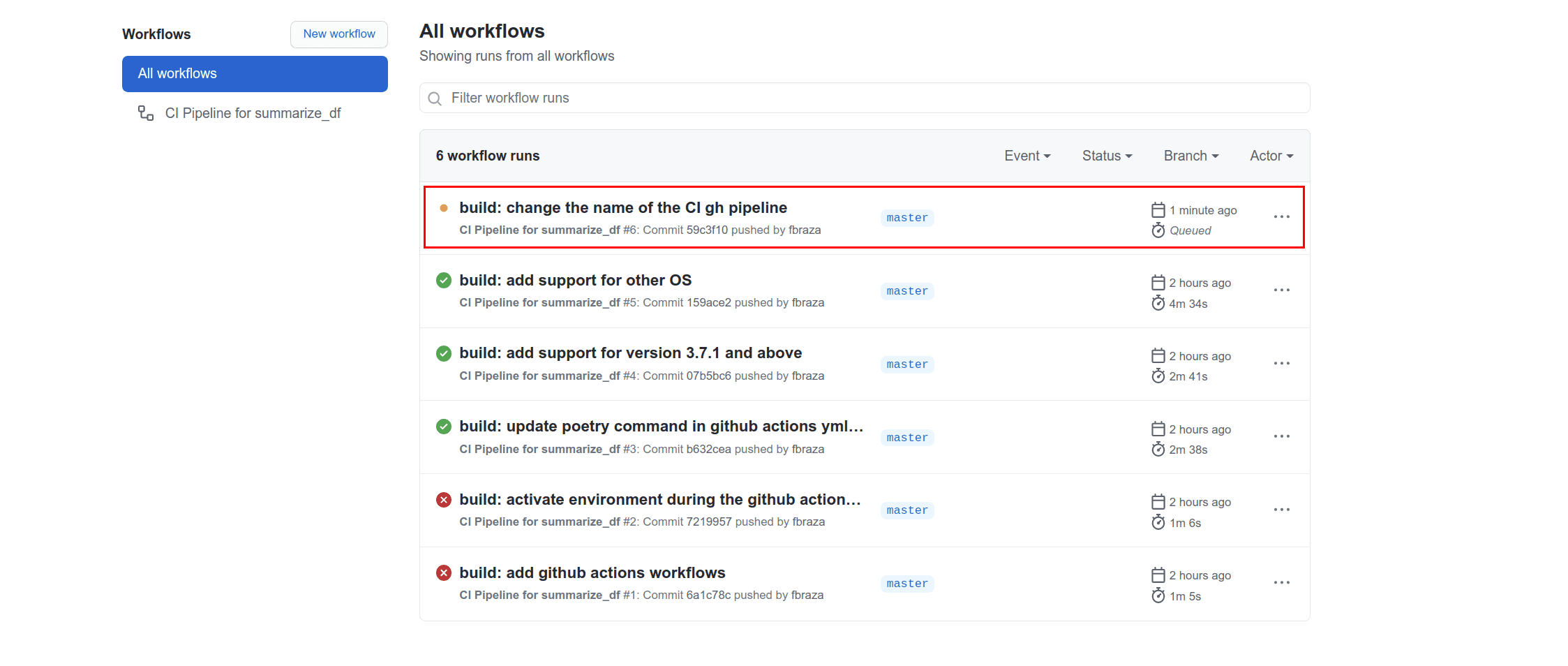
Let’s click on the ongoing pipeline. The pipeline runs on each OS and for each Python version. Wait a couple of minutes to see the results:
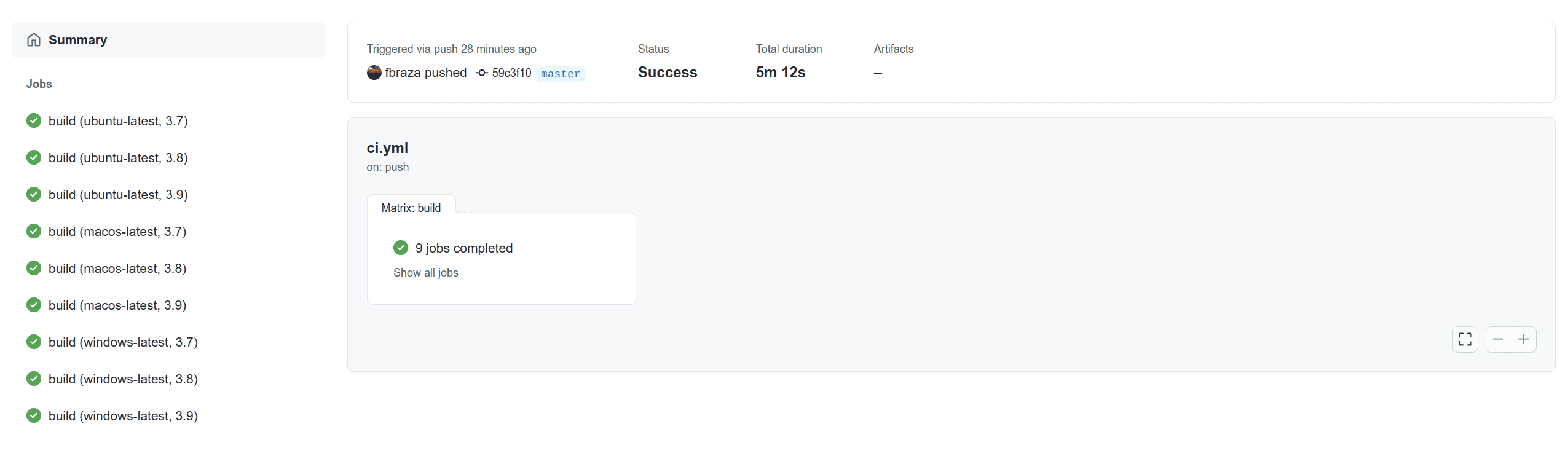
All the pipelines succeed! We are ready to publish our package on the PyPi registry.
Publish packages on PyPi with poetry
To make your package publishable, add some details in the [tool.poetry] section of your pyproject.toml file:
[tool.poetry]
name = "summarize_dataframe"
version = "0.1.0"
description = "A package to provide summary data about pandas DataFrame"
license = "MIT"
authors = ["fbraza <fbraza@tutanota.com>"]
keywords = ["pandas", "dataframe"]
readme = "README.md"
homepage = "https://github.com/fbraza/summarize_dataframe"
repository = "https://github.com/fbraza/summarize_dataframe"
include = ["CHANGELOG.md"]
[...]All the variables here are quite explicit. These are metadata needed for the publication of the package. The include variable is interesting to add any files you want. In our case we are going to add a CHANGELOG.md file. Do you remember commitizen? If not please take the time to read our article on commitizen and conventional commits. Use the following command:
cz bumpIt prints the semantic version from your pyproject.toml file and ask you to create a Git tag. The version will be updated based on your Git commit. Next we create the CHANGELOG.md:
cz changelog
cat CHANGELOG.md
## Unreleased
## 0.1.0 (2021-04-28)
### Refactor
- correct pylint warnings
- split the function into two: one returning df other for output
### Feat
- implementation of the summary function to summarize dataframeYour CHANGELOG.md has been created based on the Git history you generated thanks to commitizen. Pretty neat isn’t it?! Once done let’s focus on publishing our package:
poetry build
Building summarize_dataframe (0.1.0)
- Building sdist
- Built summarize_dataframe-0.1.0.tar.gz
- Building wheel
- Built summarize_dataframe-0.1.0-py3-none-any.whlThis creates a folder called dist where the built package is located. To test if everything works you can use pip:
Do this outside of your virtual environment to not pollute it.
pip install path/to/your/package/summarize_dataframe-0.1.0-py3-none-any.whlNow we need to create an account on PyPi. Just enter the expected details, validate your email and execute:
poetry publish
Username: ***********
Password: ***********
Publishing summarize_dataframe (0.1.0) to PyPI
- Uploading summarize_dataframe-0.1.0-py3-none-any.whl 100%
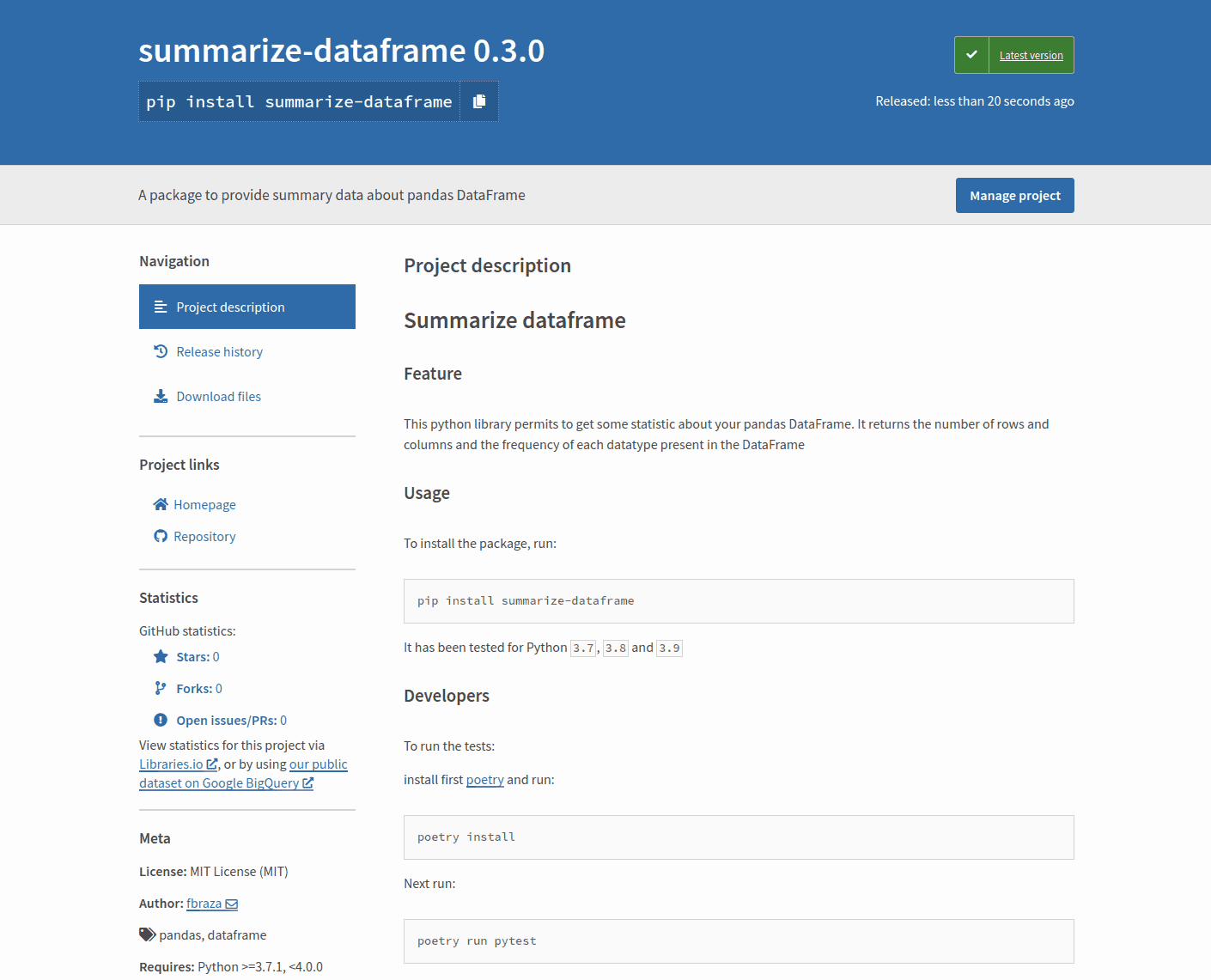
- Uploading summarize_dataframe-0.1.0.tar.gz 100%The package is now online and shared with the community.
Conclusion
tox provides a nice interface to automate all your unit tests and validation checks. The ecosystem around poetry is getting more mature and provides solutions to work with tox without too much hassle. Collectively, these two solutions permit to establish a very efficient and coherent CI pipeline. To run the pipeline and test your packages against different OS or versions of Python, you can leverage GitHub Actions as described above.
poetry was at the center of our approach. From the project initialization to its publication and going through the management of its packages and dependencies. poetry demonstrated its ease of use and efficacy that will definitely facilitate the life of developers, Data Scientists or Data Engineers who develop projects in Python.
Our articles describe a full setup that you can leverage to build your own Python project to respect good software engineering practices.
Cheat Sheet
tox
-
Run your tox pipeline
tox
poetry
-
Build your package
poetry build -
Publish your package
poetry publish
