


Introducing Trunk Data Platform: the Open-Source Big Data Distribution Curated by TOSIT

Apr 14, 2022
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Ever since Cloudera and Hortonworks merged, the choice of commercial Hadoop distributions for on-prem workloads essentially boils down to CDP Private Cloud. CDP can be seen as the “best of both worlds” between CDH and HDP. With HDP 3.1’s End of Support coming in December 2021, Cloudera’s clients are “forced” to migrate to CDP.
What about clients that are not capable of upgrading regularly to follow EOS dates? Some other clients are not interested in the cloud features highlighted by Cloudera and just want to keep running their “legacy” Hadoop workloads. Hortonworks’ HDP used to be downloadable for free and some companies are still interested in having a Big Data distribution without support for non business critical workloads.
Finally, some are worried about the sensible decrease in open-source contributions since the two companies have merged.
Trunk Data Platform (TDP) was designed with these problematics in mind: shared governance on the future of the distribution, accessible for free and 100% open-source.
TOSIT

TOSIT (The Open Source I Trust) is a French non-profit organization promoting open-source software. Some founding members include industry leaders such as Carrefour (retail), EDF (energy) and Orange (telecommunications) as well as the French Ministry for the Economy and Finance.
The work on “Trunk Data Platform” (TDP) has been initiated through talks between EDF and the French Ministry for the Economy and Finance regarding the status of their enterprise Big Data platforms.
Trunk Data Platform
Apache Components
The core idea of Trunk Data Platform (TDP) is to have a secure, robust base of well-known Apache projects of the Hadoop ecosystem. These projects should cover most of the Big Data use cases: distributed filesystem and computing resources as well as SQL and NoSQL abstractions to query the data.
The following table summarizes the components of TDP:
| Component | Version | Base Apache Branch Name |
|---|---|---|
| Apache ZooKeeper | 3.4.6 | release-3.4.6 |
| Apache Hadoop | 3.1.1-TDP-0.1.0-SNAPSHOT | rel/release-3.1.1 |
| Apache Hive | 3.1.3-TDP-0.1.0-SNAPSHOT | branch-3.1 |
| Apache Hive 1 | 1.2.3-TDP-0.1.0-SNAPSHOT | branch-1.2 |
| Apache Tez | 0.9.1-TDP-0.1.0-SNAPSHOT | branch-0.9.1 |
| Apache Spark | 2.3.5-TDP-0.1.0-SNAPSHOT | branch-2.3 |
| Apache Ranger | 2.0.1-TDP-0.1.0-SNAPSHOT | ranger-2.0 |
| Apache HBase | 2.1.10-TDP-0.1.0-SNAPSHOT | branch-2.1 |
| Apache Phoenix | 5.1.3-TDP-0.1.0-SNAPSHOT | 5.1 |
| Apache Phoenix Query Server | 6.0.0-TDP-0.1.0-SNAPSHOT | 6.0.0 |
| Apache Knox | 1.6.1-TDP-0.1.0-SNAPSHOT | v1.6.1 |
Note: The versions of the components have been chosen to ensure inter-compatibility. They are approximately based on the latest version of HDP 3.1.5.
The table above is maintained in the main TDP repository.
Our repositories are mainly forks of specific tags or branches as mentioned in the above table. There is no deviation from the Apache codebase except for the version naming and some backports of patches. Should we contribute meaningful code to any of the components that would benefit the community, we will go through the process to submit these contributions to the Apache code base of each project.
Another core concept of TDP is to master everything from building to deploying the components. Let’s see the implications.
Building TDP
Building TDP boils down to building the underlying Apache projects from source code with some slight modifications.
The difficulty lies in the complexity of the projects and their many inter-dependences. For instance, Apache Hadoop is a 15+ years old project with more than 200000 lines of code. While most of the components of TDP are Java projects, the code we are compiling also includes C, C++, Scala, Ruby and JavaScript. To ensure reproducible and reliable builds, we are using a Docker image containing everything needed for building and testing the components above. This image was heavily inspired by the one present in Apache Hadoop project but we are planning on making our own.
Most of the components of TDP have some dependencies on other components. For example, here is an excerpt of TDP Hive’s pom.xml file:
<storage-api.version>2.7.0</storage-api.version>
<tez.version>0.9.1-TDP-0.1.0-SNAPSHOT</tez.version>
<super-csv.version>2.2.0</super-csv.version>
<spark.version>2.3.5-TDP-0.1.0-SNAPSHOT</spark.version>
<scala.binary.version>2.11</scala.binary.version>
<scala.version>2.11.8</scala.version>
<tempus-fugit.version>1.1</tempus-fugit.version>In this case, Hive depends on both Tez and Spark.
We created a tdp directory in every repository of the TDP projects (example here for Hadoop) in which we provide the commands used to build, test (covered in the next section) and package.
Note: Make sure to check our previous articles “Build your open source Big Data distribution with Hadoop, HBase, Spark, Hive & Zeppelin” and “Installing Hadoop from source: build, patch and run” if you want to have more details on the process of building inter-dependent Apache projects of the Hadoop ecosystem.
Testing TDP
Testing is a critical part of the process of releasing TDP. Because we are packaging our own releases for each project in an interdependent fashion, we need to make sure that these releases are compatible with each other. This can be achieved by running unit tests and integration tests.
As most of our projects are written in Java, we chose to use Jenkins to automate the building and testing of the TDP distribution. Jenkins’ JUnit plugin is very useful for a complete reporting of the tests we run on each project after compiling the code.
Here is an example output for the test report of Apache Hadoop:
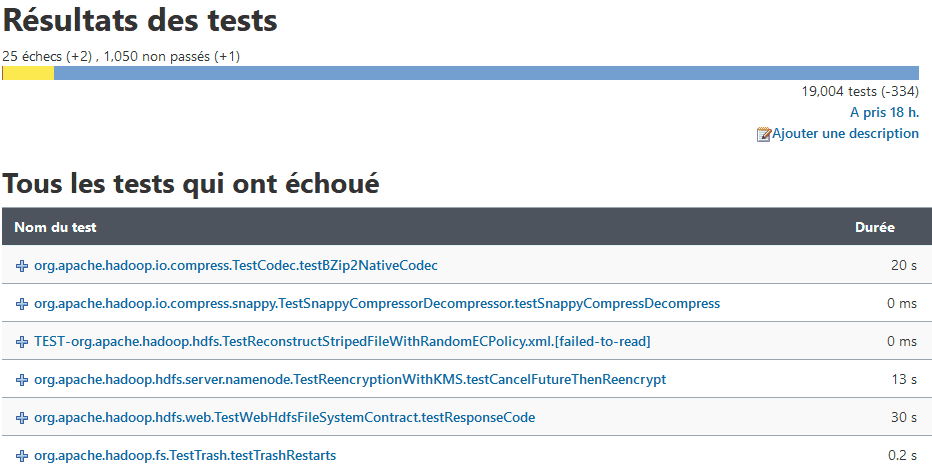
Just like the builds, we also committed the TDP testing commands and flags in each of the repositories’ tdp/README.md files.
Note: Some high-level information about our Kubernetes-based building/testing environment can be found here on our repository.
Deploying TDP
After the building phase we just described, we are left with .tar.gz files of the components of our Hadoop distribution. These archives package binaries, compiled JARs and configuration files. Where do we go from here?
To keep consistent with our philosophy of keeping control over the whole stack, we decided to write our own Ansible collection. It comes with roles and playbooks to manage the deployment and configuration of the TDP stack.
The tdp-collection is designed to deploy all the components with security (Kerberos authentication and TLS) and high availability by default (when possible).
Here is an excerpt of the “hdfs_nn” subtask of the Hadoop role which deploys the Hadoop HDFS Namenode:
- name: Create HDFS Namenode directory
file:
path: "{{ hdfs_site['dfs.namenode.name.dir'] }}"
state: directory
group: '{{ hadoop_group }}'
owner: '{{ hdfs_user }}'
- name: Create HDFS Namenode configuration directory
file:
path: '{{ hadoop_nn_conf_dir }}'
state: directory
group: '{{ hadoop_group }}'
owner: '{{ hdfs_user }}'
- name: Template HDFS Namenode service file
template:
src: hadoop-hdfs-namenode.service.j2
dest: /usr/lib/systemd/system/hadoop-hdfs-namenode.serviceTDP Lib
The Ansible playbooks can be run manually or through the TDP Lib which is a Python CLI we developed for TDP. Using it provides multiple advantages:
- The lib uses a generated DAG based on the dependencies between the components to deploy everything in the correct order;
- All the deployment logs are saved in a database;
- The lib also manages the configuration versioning of the components.
What about Apache Ambari?
Apache Ambari is an open-source Hadoop cluster management UI. It was maintained by Hortonworks and has been discontinued in favor of Cloudera Manager which is not open-source. While it is an open-source Apache project, Ambari was strongly tied to HDP and was only capable of managing Hortonworks Data Platform (HDP) clusters. HDP was distributed as RPM packages and the process used by Hortonworks to build those RPMs (ie: the underlying spec files) was never open-source.
We assessed that the technical debt of maintaining Ambari for the sake of TDP was too much to be profitable and decided to start from scratch and automate the deployment of our Hadoop distribution using the industry standard for IT automation: Ansible.
What’s next?
TDP is still a work in progress. While we already have a solid base of Hadoop-oriented projects, we are planning on expanding the list of components in the distribution and experimenting with new Apache Incubator projects like Apache Datalab or Apache Yunikorn. We also hope to be able soon to contribute code to the Apache trunk of each project.
The designing of a Web UI is also in the works. It should be able to handle everything from configuration management to service monitoring and alerting. This Web UI will be powered by the TDP lib.
We invested a lot of time in the Ansible roles and we are planning to leverage these in the future admin interface.
Getting involved
The easiest way to get involved with TDP is to go through the Getting started repository in which you will be able to run a fully functional, secured and highly available TDP installation in virtual machines. You can also contribute via pull requests or report issues in the Ansible collection or at any of the TOSIT-IO repositories.
If you have any questions, feel free to reach out at david@adaltas.com.
