


Databricks logs collection with Azure Monitor at a Workspace Scale

By Claire PLAYE
May 10, 2022
- Categories
- Cloud Computing
- Data Engineering
- Adaltas Summit 2021
- Tags
- Metrics
- Monitoring
- Spark
- Azure
- Databricks
- Log4j [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Databricks is an optimized data analytics platform based on Apache Spark. Monitoring Databricks plateform is crucial to ensure data quality, job performance, and security issues by limiting access to production workspaces.
Spark application metrics, logs, and events produced by a Databricks workspace can be customized, sent, and centralized to various monitoring platforms including Azure Monitor Logs. This tool, formerly called Log Analytics by Microsoft, is an Azure cloud service integrated into Azure Monitor that collects and stores logs from cloud and on-premises environments. It provide a mean for querying logs from data collected using a read-only query language named “Kusto”, for building “Workbooks” dashboards and setting up alerts on identified patterns.
This article focus on automating the export of Databricks logs to a Log Analytics workspace by using the Spark-monitoring library at a workspace scale.
Overview of Databricks log sending
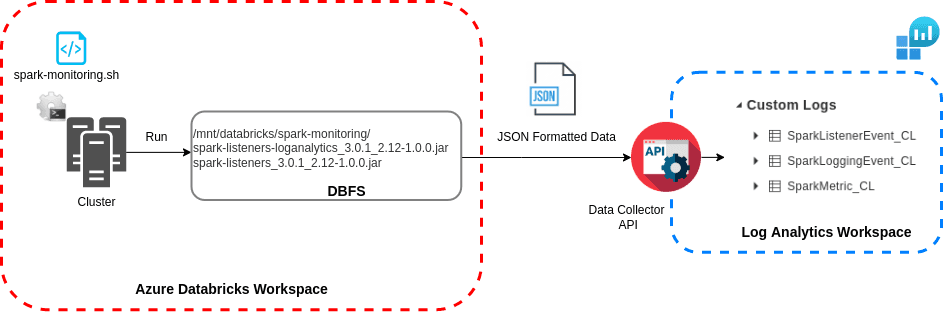
This section is an overview of the architecture. More detailed information and the associated source code are provided further down in the article.
Spark-monitoring is a Microsoft Open Source project to export Databricks logs at a cluster level. Once downloaded, the library is locally built with Docker or Maven according to the Databricks Runtime version of the cluster to configure (Spark and Scala versions). The build of the library generates two jar files:
spark-listeners_${spark-version}_${scala_version}-${version}: collects data from a running cluster;spark-listeners-loganalytics_${spark-version}_${scala_version}-${version}: extendsspark-listenersby collecting data, connecting to a Log Analytics workspace, parsing and sending logs via Data Collector API
In the documentation, once the jars are built, they are put on the DBFS. An init script spark-monitoring.sh is edited locally with workspace and cluster’s configurations and manually added through Databricks interface at cluster level.
At cluster’s launch, logs are sent in streaming in JSON format to Log Analytics Data Collector API and stored in 3 different tables, one for each type of log sent:
- SparkMetric_CL: Execution metrics of Spark applications (memory usage, number of jobs, stages tasks submitted/completed/running);
- SparkListenerEvent_CL: All events intercepted by SparkListener during the execution of the Spark application (jobs, stages and tasks start/end);
- SparkLoggingEvent_CL: Logs from log4j appender.
Some configurations allow to automate the set up of log sending at the workspace level by configuring all clusters in a given workspace. It involves downloading the project, building it with Docker or Maven, editing spark-monitoring.sh script and cluster’s environment variables. Once all the configurations have been made, running the PowerShell script configures the Databricks workspace. It is based on 3 bash scripts:
spark-monitoring-vars.sh: define workspace’s environments variables;spark-monitoring.sh: sends logs in streaming to Log Analytics;spark-monitoring-global-init.sh: this script at workspace scale runsspark-monitoring-vars.shthenspark-monitoring.sh.
The PowerShell script dbx-monitoring-deploy.ps1 runs locally and it deploys configurations at a workspace level. It fills spark-monitoring-vars.sh with workspace variables, copies scripts and jars to DBFS and posts global init script to Databricks.
Configuration of a workspace
1. Building the jar files
Clone the repository Spark-monitoring and build locally the jar files with Docker or Maven in Databricks runtime versions of all the clusters that need to be configured in the workspace according to the documentation.
With Docker:
In the root of the spark-monitoring folder, run the build command in the desired Spark and Scala versions. In this example, the library is built for Scala 2.12 and Spark 3.0.1.
docker run -it --rm -v pwd:/spark-monitoring -v "$HOME/.m2":/root/.m2 -w /spark-monitoring/src maven:3.6.3-jdk-8 mvn install -P "scala-2.12_spark-3.0.1"Jars are built in the spark-monitoring/src/target folder. The spark-monitoring.sh is located inside the spark-monitoring/src/spark-listeners/scripts folder.
All these steps are explained in the chapter Build the Azure Databricks monitoring library from the Microsoft patterns & practices GitHub repository.
2. Setting Log Analytics environment variables
The Log Analytics workspace Id and Key are stored in Azure Key Vault’s secrets and referenced in the environment variables of all clusters configured. Azure Databricks accesses the Key Vault through Databricks workspace Secret Scope.
After creating the secrets of Log Analytics workspace Id and Key, configure every cluster manually referencing the secrets following the instructions on how to set up the Azure Key Vault-Backed Secret Scope.
LOG_ANALYTICS_WORKSPACE_KEY={{secrets/secret-scope-name/pw-log-analytics}}
LOG_ANALYTICS_WORKSPACE_ID={{secrets/secret-scope-name/id-log-analytics}}3. Adding spark-monitoring-global-init.sh and spark-monitoring-vars.sh scripts
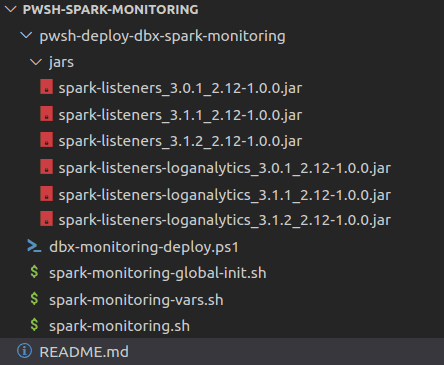
Create a jars folder, upload all jars and configurations files respecting the following file tree:
-
spark-monitoring-global-init.sh: This script is started at the launch of every cluster in the workspace.#!/bin/bash # Directory of spark-monitoring STAGE_DIR=/dbfs/databricks/spark-monitoring # Script defining variables in workspace environment VARS_SCRIPT=$STAGE_DIR/spark-monitoring-vars.sh # Script sending logs to Log Analytics MONITORING_SCRIPT=$STAGE_DIR/spark-monitoring.sh # If directory exists if [ -d "$STAGE_DIR" -a -f "$VARS_SCRIPT" -a -f "$MONITORING_SCRIPT" ]; then # If scripts exists run them /bin/bash $VARS_SCRIPT; /bin/bash $MONITORING_SCRIPT; else echo "Directory $STAGE_DIR does not exist or one of the scripts needed is missing" fi -
spark-monitoring-vars.sh: This script is a template of all environment variables needed at the cluster and workspace level.#!/bin/bash # These environment variables would normally be set by Spark scripts. # However, for a Databricks init script, they have not been set yet. # We will keep the names the same here, but not export them. # These must be changed if the associated Spark environment variables # are changed. DB_HOME=/databricks SPARK_HOME=$DB_HOME/spark SPARK_CONF_DIR=$SPARK_HOME/conf tee -a "$SPARK_CONF_DIR/spark-env.sh" << EOF # Id of Azure subscription export AZ_SUBSCRIPTION_ID="$AZ_SUBSCRIPTION_ID" # Resource group name of workspace export AZ_RSRC_GRP_NAME="$AZ_RSRC_GRP_NAME" export AZ_RSRC_PROV_NAMESPACE=Microsoft.Databricks export AZ_RSRC_TYPE=workspaces # Name of Databricks workspace export AZ_RSRC_NAME="$AZ_RSRC_NAME" EOF
4. Editing and adding spark-monitoring.sh
Copy spark-monitoring.sh from the cloned project, add it to the file tree and edit environment variables like the following:
DB_HOME=/databricks
SPARK_HOME=$DB_HOME/spark
SPARK_CONF_DIR=$SPARK_HOME/conf
tee -a "$SPARK_CONF_DIR/spark-env.sh" << EOF
# Export cluster id and name from environment variables
export DB_CLUSTER_ID=$DB_CLUSTER_ID
export DB_CLUSTER_NAME=$DB_CLUSTER_NAME
EOFGiven the large storage costs associated with a Log Analytics workspace, in the context of Spark metrics, apply filters based on REGEX expressions to only preserve the most relevant logs information. This event filtering documentation gives you the different variables to set.
5. Editing, adding and launching the PowerShell script
The script dbx-monitoring-deploy.ps1 is used to configure the export of cluster logs from a Databricks workspace to Log Analytics.
It performs the following actions:
- Fills
spark-monitoring-vars.shwith correct values for workspace. - Uploads
spark-monitoring-vars.sh,spark-monitoring.shand all jar files on DBFS’ workspace. - Posts through Databricks API content of the global init script.
It assumes there are 3 different Azure subscriptions (DEV/ PREPROD/ PROD) to separate development, test and production phases of a continuous integration. A preproduction subscription is used for integration tests and business acceptance testing before going into production.
Edit this section according to your subscriptions.
param(
[Parameter(Mandatory=$true,ValueFromPipeline=$true)]$p,
[Parameter(Mandatory=$true,ValueFromPipeline=$true)]$e,
[Parameter(Mandatory=$true,ValueFromPipeline=$true)]$n,
[Parameter(Mandatory=$true,ValueFromPipeline=$true)]$rg,
[Parameter(Mandatory=$true,ValueFromPipeline=$true)]$w
)
$armFolder = $p.TrimEnd("/","\")
$deploymentName = $n.ToLower()
$varsTemplatePath = "$armFolder/spark-monitoring-vars.sh"
if ($e -like "dev")
{
$AZ_SUBSCRIPTION_ID = ""
}
elseif ($e -like 'prod') {
$AZ_SUBSCRIPTION_ID = ""
}
elseif ($e -like 'preprod') {
$AZ_SUBSCRIPTION_ID = ""
}
else{
Write-Output "no environment provided - exiting"
Exit-PSSession
}
# Fill spark-monitoring-vars.sh with correct values for workspace
$AZ_RSRC_GRP_NAME = $rg
$AZ_RSRC_NAME = $w
$environment = $e.ToLower()
$parametersPath = "$armFolder/$environment/$deploymentName/spark-monitoring-vars-$environment-$deploymentName.sh"
$template = Get-Content "$varsTemplatePath" -Raw
$filledTemplate = Invoke-Expression "@`"`r`n$template`r`n`"@"
mkdir -p $armFolder/$environment/$deploymentName
Out-File -FilePath $parametersPath -InputObject $filledTemplate
# Set Azure Context to Databricks workspace subscription
try {
$context = get-azContext
if(!$context)
{
Write-Output "No context, please connect !"
$Credential = Get-Credential
Connect-AzAccount -Credential $Credential -ErrorAction Stop
}
if ($environment -like "dev")
{
set-azcontext "AD-DEV01" -ErrorAction Stop
}
elseif ($environment -like 'prod') {
set-azcontext "AD-PROD01" -ErrorAction Stop
}
elseif ($environment -like 'preprod') {
set-azcontext "AD-PREPROD01" -ErrorAction Stop
}
else{
Write-Output "no context found for provided environment- exiting"
Exit
}
}
catch{
Write-Output "error setting context - exiting"
Exit
}
# Upload spark-monitoring-vars.sh, spark-monitoring-vars.sh and all jar files on DBFS workspace
$mydbx=Get-AzDatabricksWorkspace -ResourceGroupName $AZ_RSRC_GRP_NAME
$hostVar = "https://" + $mydbx.Url
$myToken = Get-AzAccessToken -Resource "2ff814a6-3304-4ab8-85cb-cd0e6f879c1d"
$env:DATABRICKS_AAD_TOKEN=$myToken.Token
databricks configure --aad-token --host $hostVar
databricks fs mkdirs dbfs:/databricks/spark-monitoring
databricks fs cp --overwrite $armFolder/spark-monitoring.sh dbfs:/databricks/spark-monitoring
databricks fs cp --overwrite $armFolder/$environment/$deploymentName/spark-monitoring-vars-$environment-$deploymentName.sh dbfs:/databricks/spark-monitoring/spark-monitoring-vars.sh
databricks fs cp --recursive --overwrite $armFolder/jars dbfs:/databricks/spark-monitoring
# Post through Databricks API content of global init script
$inputfile = "$armFolder/spark-monitoring-global-init.sh"
$fc = get-content $inputfile -Encoding UTF8 -Raw
$By = [System.Text.Encoding]::UTF8.GetBytes($fc)
$etext = [System.Convert]::ToBase64String($By, 'InsertLineBreaks')
$Body = @{
name = "monitoring"
script = "$etext"
position = 1
enabled = "true"
}
$JsonBody = $Body | ConvertTo-Json
$Uri = "https://" + $mydbx.Url + "/api/2.0/global-init-scripts"
$Header = @{Authorization = "Bearer $env:DATABRICKS_AAD_TOKEN"}
Invoke-RestMethod -Method Post -Uri $Uri -Headers $Header -Body $JsonBodyEnrich and launch the script with those parameters:
| Parameter | Description |
|---|---|
| p | Path to script |
| e | Environment (DEV, PREPROD, PROD) |
| n | Deployment name |
| rg | Workspace resource group |
| w | Workspace name |
Call the script like the following:
pwsh dbx-monitoring-deploy.ps1 -p /home/Documents/pwsh-spark-monitoring/pwsh-deploy-dbx-spark-monitoring -e DEV -n deploy_log_analytics_wksp_sales -rg rg-dev-datalake -w dbx-dev-datalake-salesThanks to this script, you can easily deploy the Spark-monitoring library on all your Databricks workspaces.
The logs natively sent allow to monitor cluster health, job execution and report errors from notebooks. Another way to monitor daily data processing is to perform custom logging using log4j appender. This way, you can add steps to implement data quality validation over ingested and cleaned data and custom tests with a predefined list of expectations to validate the data against.
We can imagine using custom logs to log bad records, apply checks and constraints on data and then send quality metrics to Log Analytics for reporting and alerting. To do so, you can build your own data quality library or use existing tools like Apache Griffin or Amazon Deeque.
