


Spark on Hadoop integration with Jupyter

Sep 1, 2022
- Categories
- Adaltas Summit 2021
- Infrastructure
- Tech Radar
- Tags
- Infrastructure
- Jupyter
- Spark
- YARN
- CDP
- HDP
- Notebook
- TDP [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
For several years, Jupyter notebook has established itself as the notebook solution in the Python universe. Historically, Jupyter is the tool of choice for data scientists who mainly develop in Python. Over the years, Jupyter has evolved and now has a wide range of features thanks to its plugins. Also, one of the main advantages of Jupyter is its ease of deployment.
More and more Spark developers favor Python over Scala to develop their various jobs for speed of development.
In this article, we will see together how to connect a Jupyter server to a Spark cluster running on Hadoop Yarn secured with Kerberos.
How to install Jupyter?
We cover two methods to connect Jupyter to a Spark cluster:
- Set up a script to launch a Jupyter instance that will have a Python Spark interpreter.
- Connect Jupyter notebook to a Spark cluster via the Sparkmagic extension.
Method 1: Create a startup script
Prerequisites:
- Have access to a Spark cluster machine, usually a master node or a edge node;
- Having an environment (Conda, Mamba, virtualenv, ..) with the ‘jupyter’ package. Example with Conda:
conda create -n pysparktest python=3.7 jupyter.
Create a script in /home directory and insert the following code by modifying the paths so that they correspond to your environment:
#! /bin/bash
# Define env Python to use
export PYSPARK_PYTHON=/home/adaltas/.conda/envs/pysparktest/bin/python
# Define IPython driver
export PYSPARK_DRIVER_PYTHON=/home/adaltas/.conda/envs/pysparktest/bin/ipython3
# Define Spark conf to use
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --no-browser --ip=10.10.20.11--port=8888"
pyspark \
--master yarn \
--conf spark.shuffle.service.enabled=true \
--conf spark.dynamicAllocation.enabled=false \
--driver-cores 2 --driver-memory 11136m \
--executor-cores 3 --executor-memory 7424m --num-executors 10Running this script creates a Jupyter server that can be used to develop your Spark jobs.
Main advantages of this solution:
- Quick execution;
- No need to edit cluster conf;
- Customization of the Spark environment by customer;
- Local environment of the edge from which the server was launched;
- Dedicated environment per user which avoids problems related to server overload.
Main drawbacks of this solution:
- Customization drifts (using too many resources, bad configuration, etc…);
- Need to have access to a cluster edge node;
- The user only have a Python interpreter (which is PySpark);
- Only one environment (Conda or other) available per server.
Method 2: Connect a Jupyter cluster via Sparkmagic
What is Sparkmagic?
Sparkmagic is a Jupyter extension that allows you to launch Spark processes through Livy.
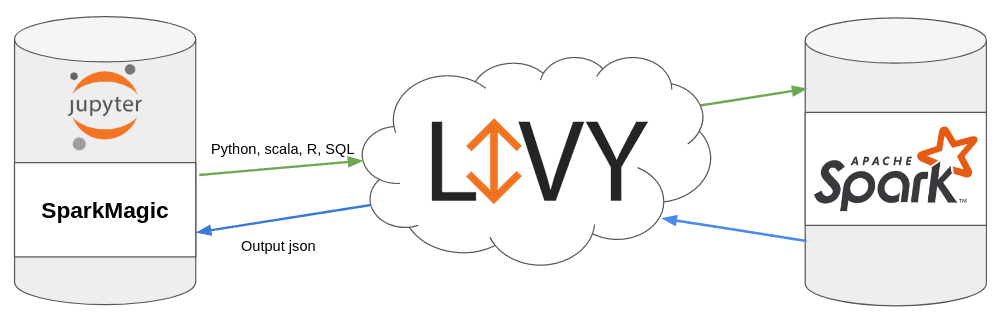
Prerequisites:
- Have a Spark cluster with Livy and Spark available (for reference: HDP, CDP ou TDP);
- Have a Jupyter server. JupyterHub is used for this demonstration;
- Have configured impersonation on the cluster.
Creating the jupyter user within the cluster
In this test, users are managed via FreeIPA on a Kerberized HDP cluster.
Creation of the jupyter user:
ipa user-add
Creation of the password:
ipa passwd jupyter
Verification that the user has a keytab on one of the cluster edge nodes and that user impersonation works accordlingly:
kinit jupyter
curl --negotiate -u : -i -X PUT
"http://edge01.local:9870/webhdfs/v1/user/vagrant/test?doas=vagrant&op=MKDIRS"Note, the above command creates a
/user/vagrantdirectory in HDFS. It requires administrator-type permissions via the impersonation described in the next section.
Finally, check that the jupyter user is indeed part of the sudo group on the server where Jupyter will be installed.
User impersonation for the jupyter user
Since we are in the case of a Kerberized HDP cluster, we must activate impersonation for the jupyter user.
To do this, modify the core-site.xml file:
<property>
<name>hadoop.proxyuser.jupyter.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.jupyter.groups</name>
<value>*</value>
</property>Installing and activating the Sparkmagic extension
As stated in the documentation, you can use the following commands to install the extension:
pip install sparkmagic
jupyter nbextension enable --py --sys-prefix widgetsnbextension
pip3 show sparkmagic
cd /usr/local/lib/python3.6/site-packages
jupyter-kernelspec install sparkmagic/kernels/sparkkernel
jupyter-kernelspec install sparkmagic/kernels/pysparkkernel
jupyter-kernelspec install sparkmagic/kernels/sparkrkernelThis example uses pip but it also works with other Python package managers.
Sparkmagic configuration
Sparkmagic needs each user to have the following:
- A
.sparkmagicdirectory at the root of each user in the/home/directory; - A custom
config.jsonfile in the users.sparkmagicdirectory.
Here is an example config.json file:
{
"kernel_python_credentials":{
"username":"{{ username }}",
"url":"http://master02.cdp.local:8998",
"auth":"Kerberos"
},
"kernel_scala_credentials":{
"username":"{{ username }}",
"url":"http://master02.cdp.local:8998",
"auth":"Kerberos"
},
"kernel_r_credentials":{
"username":"{{ username }}",
"url":"http://master02.cdp.local:8998",
"auth":"Kerberos"
},
"logging_config":{
"version":1,
"formatters":{
"magicsFormatter":{
"format":"%(asctime)s\t%(levelname)s\t%(message)s",
"datefmt":""
}
},
"handlers":{
"magicsHandler":{
"class":"hdijupyterutils.filehandler.MagicsFileHandler",
"formatter":"magicsFormatter",
"home_path":"~/.sparkmagic"
}
},
"loggers":{
"magicsLogger":{
"handlers":[
"magicsHandler"
],
"level":"DEBUG",
"propagate":0
}
}
},
"authenticators":{
"Kerberos":"sparkmagic.auth.kerberos.Kerberos",
"None":"sparkmagic.auth.customauth.Authenticator",
"Basic_Access":"sparkmagic.auth.basic.Basic"
},
"wait_for_idle_timeout_seconds":15,
"livy_session_startup_timeout_seconds":60,
"fatal_error_suggestion":"The code failed because of a fatal error:\n\t{}.\n\nSome things to try:\na) Make sure Spark has enough available resources for Jupyter to create a Spark context.\nb) Contact your Jupyter administrator to make sure the Sparkmagic library is configured correctly.\nc) Restart the kernel.",
"ignore_ssl_errors":false,
"session_configs":{
"driverMemory":"1000M",
"executorCores":2,
"conf":{
"spark.master":"yarn-cluster"
},
"proxyUser":"jupyter"
},
"use_auto_viz":true,
"coerce_dataframe":true,
"max_results_sql":2500,
"pyspark_dataframe_encoding":"utf-8",
"heartbeat_refresh_seconds":30,
"livy_server_heartbeat_timeout_seconds":0,
"heartbeat_retry_seconds":10,
"server_extension_default_kernel_name":"pysparkkernel",
"custom_headers":{
},
"retry_policy":"configurable",
"retry_seconds_to_sleep_list":[
0.2,
0.5,
1,
3,
5
],
}Edit /etc/jupyterhub/jupyterhub_config.py - SparkMagic
In my case, I decided to modify the /etc/jupyterhub/jupyterhub_config.py file in order to automate some processes related to SparkMagic:
- Creation of the
.sparkmagicfolder is the/home/directory of each new user; - Generating the
config.jsonfile.
c.LDAPAuthenticator.create_user_home_dir = True
import os
import jinja2
import sys, getopt
from pathlib import Path
from subprocess import check_call
def config_spark_magic(spawner):
username = spawner.user.name
templateLoader = jinja2.FileSystemLoader(searchpath="/etc/jupyterhub/")
templateEnv = jinja2.Environment(loader=templateLoader)
TEMPLATE_FILE = "config.json.template"
tm = templateEnv.get_template(TEMPLATE_FILE)
msg = tm.render(username=username)
path = "/home/" + username + "/.sparkmagic/"
Path(path).mkdir(mode=0o777, parents=True, exist_ok=True)
outfile = open(path + "config.json", "w")
outfile.write(msg)
outfile.close()
os.popen('sh /etc/jupyterhub/install_jupyterhub.sh ' + username)
c.Spawner.pre_spawn_hook = config_spark_magic
c.JupyterHub.authenticator_class = 'ldapauthenticator.LDAPAuthenticator'
c.LDAPAuthenticator.server_hosts = ['ipa.cdp.local']
c.LDAPAuthenticator.server_port = 636
c.LDAPAuthenticator.server_use_ssl = True
c.LDAPAuthenticator.server_pool_strategy = 'FIRST'
c.LDAPAuthenticator.bind_user_dn = 'uid=admin,cn=users,cn=accounts,dc=cdp,dc=local'
c.LDAPAuthenticator.bind_user_password = 'passWord1'
c.LDAPAuthenticator.user_search_base = 'cn=users,cn=accounts,dc=cdp,dc=local'
c.LDAPAuthenticator.user_search_filter = '(&(objectClass=person)(uid={username}))'
c.LDAPAuthenticator.user_membership_attribute = 'memberOf'
c.LDAPAuthenticator.group_search_base = 'cn=groups,cn=accounts,dc=cdp,dc=local'
c.LDAPAuthenticator.group_search_filter = '(&(objectClass=ipausergroup)(memberOf={group}))'Main advantages of this solution:
- Has three interpreters via Sparkmagic (Python, Scala and R);
- Customizing Spark resources via
config.jsonfile; - No need to have physical access to the cluster for users;
- Ability to have multiple Python environments available;
- Connecting JupyterHub with an LDAP.
Main drawbacks of this solution:
- Customization drifts (using too many resources, bad configuration, etc…);
- Modification of the HDP/CDP configuration;
- More complex deployment;
- A notebook has only one interpreter.
Conclusion
If you are developing Spark jobs and historical solutions such as Zeppelin no longer suit you or you are limited by its version, you can now set up a Jupyter server inexpensively to develop your jobs while taking advantage of the resources of your clusters.
