


Apache Apex : l'analytique Big Data nouvelle génération

17 juil. 2016
- Catégories
- Data Science
- Évènements
- Tech Radar
- Tags
- Apex
- Storm
- Tools
- Flink
- Hadoop
- Kafka
- Data Science
- Machine Learning [plus][moins]
Vous appréciez notre travail......nous recrutons !
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Ci-dessous une compilation de mes notes prises lors de la présentation d’Apache Apex par Thomas Weise de DataTorrent, l’entreprise derrière Apex.
Introduction
Apache Apex est un moteur de traitements parallélisés en mémoire, comme Flink ou Storm. Cependant, il est développé avec une intégration native d’Hadoop :
- Yarn est utilisé pour la gestion des ressources
- HDFS est utilisé pour le stockage d’état
Modèle de développement applicatif
- Un stream est une séquence de couplets
- Un opérateur :
- prend un ou plusieurs flux en entrée
- applique un traitement aux couplets (logique en Java)
- émet un ou plusieurs flux en sortie
- est lancé plusieurs fois en instance monothread parallélisée
- utilise le modèle DAG pour optimiser le traitement des données
- Une application est composée d’une suite d’opérateurs
Logique de développement
Un exemple typique de WordCount avec Apex prend la forme suivante :
- Les données sont acheminées via Kafka
- La logique Apex utilise les opérateurs suivants :
- Input Kafka
- Parseur
- Filtre
- Compteur de mots
- Output JDBC
- La donnée finale est écrite en base
La logique de développement prend la forme suivante :
- Utilisation d’un opérateur existant depuis les librairies Apex ou implémentation d’une logique spécifique
- Connexion des opérateurs pour former l’application
- Configuration des propriétés d’opérateurs
- Configuration de la mise à l’échelle et des attributs de plateforme
- Test des fonctionnalités et performance, début d’une nouvelle itération
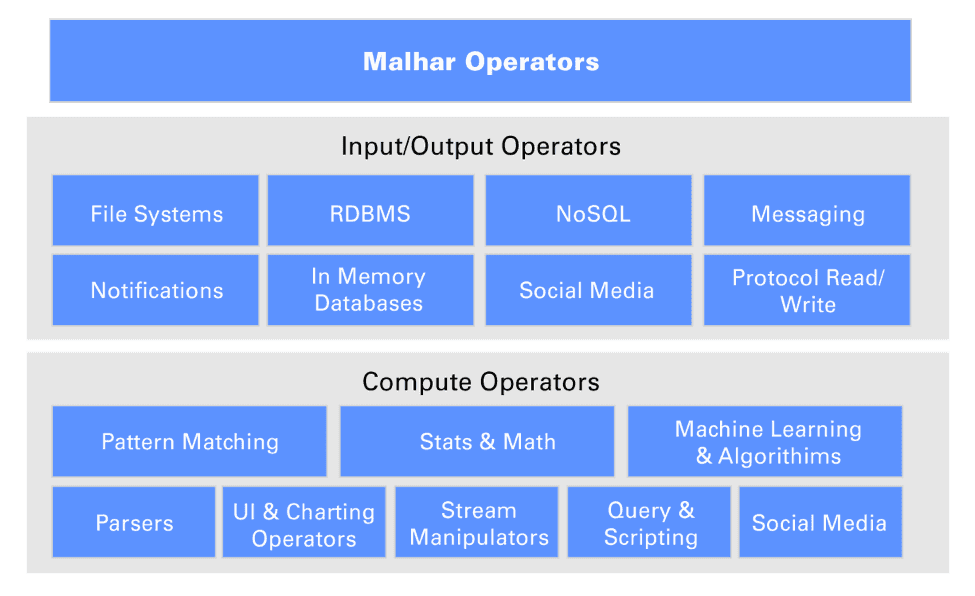
Librairies d’opérateurs
Apex fournit une librairie d’opérateurs très complète via le projet Apache Apex Malhar :
- Messaging (Kafka, ActiveMQ, …)
- NoSQL (HBase, Cassandra, MongoDB, Redis, CouchDB, …)
- RDBMS (JDBC, MySQL, …)
- Système de fichier (HDFS / Hive, …)
Notes
- Apex se base sur Apache BEAM pour le développement des jobs, il profite donc des multiples avantages :
- partitionnement dynamique à l’exécution
- répartition de la charge entre les opérateurs parallélisés
- gestion du fenêtrage
- …
- La tolérance à la panne est couverte par la sauvegarde d’état des opérateurs
- Apex assure les modes de traitement
- au moins une fois
- au plus une fois
- exactement une fois
