Synchronisation Oracle vers Hadoop avec un CDC

By WORMS David
13 juil. 2017
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Cette note résulte d’une discussion autour de la synchronisation de données écrites dans une base de données à destination d’un entrepôt stocké dans Hadoop. Merci à Claude Daub de GFI qui la rédigea et qui nous autorise à la publier.
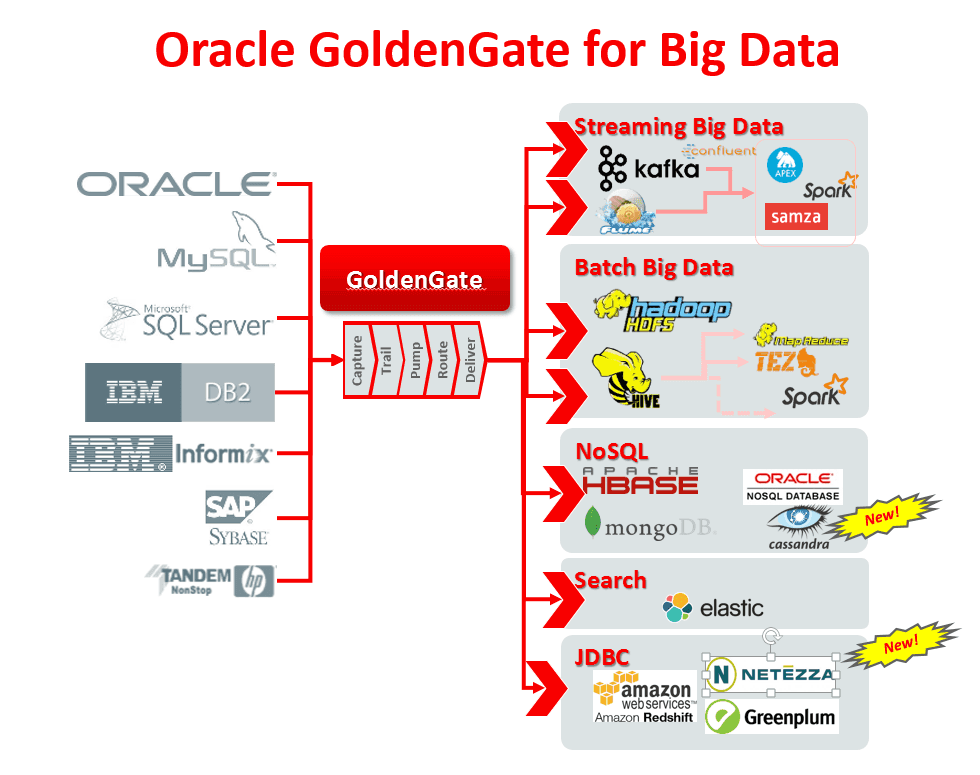
Oracle GoldenGate
- Outil de réplication des données en temps réel basé sur les logs internes
- Distribué et donc officiellement supporté par Oracle
- Pas d’impact sur les performances de la base de données source
- Large éventail de destinaires : HDFS, Kafka, HBase, Hive, Flumes, JDBC, …
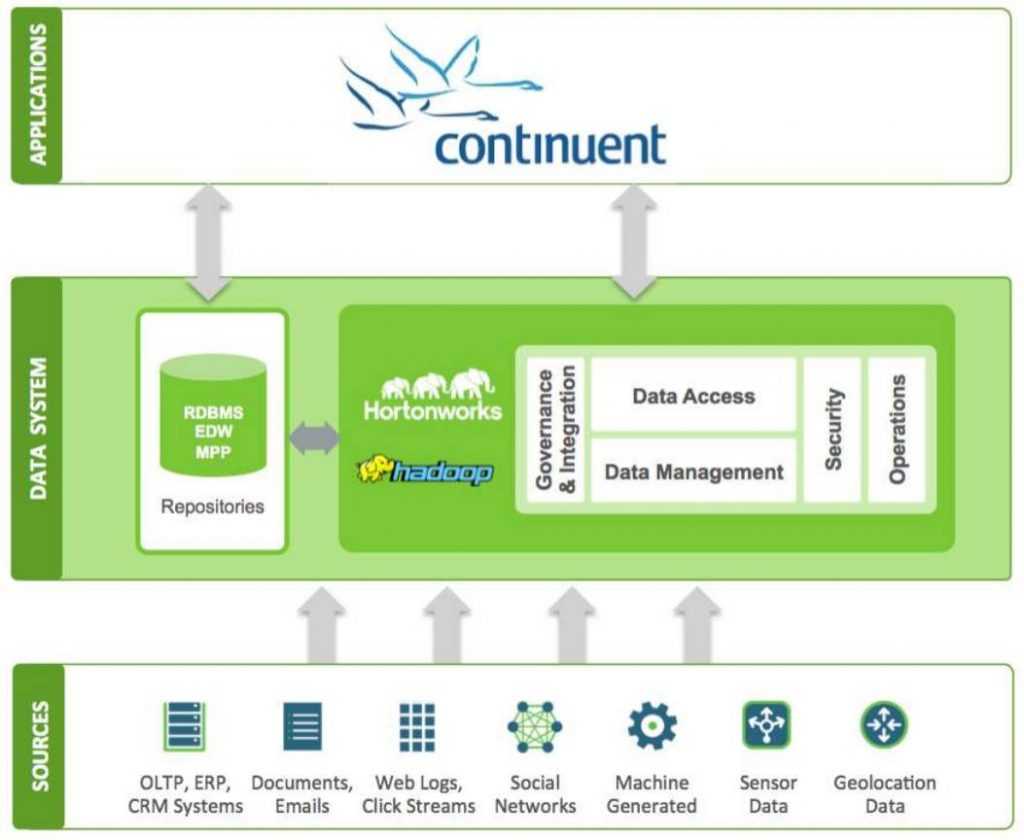
Continuent Tungsten Replicator
Tungsten consiste à activer Oracle CDC (Change Data Capture) qui récupère les changements depuis les redo logs. Il produit d’autres tables avec les changements.
Cette solution permet un traitement différé, mais passe – comme pour les triggers – par des tables intermédiaires. Après la méthode de synchro avec Hadoop est adaptable (sqoop peut suffire) ou un export CSV / import via fichier.
Intègre un service de réplication des données :
- Compatible avec plusieurs bases (Oracle, MySQL…)
- On peut avoir des time series
- Solution certifiée Hortonworks
- Pas d’information sur l’impact en performance sur la source
DBVisit
Solution commerciale incluant :
- Temps réel
- Support de plusieurs SGBDR (Oracle, MySQL)
- Réplication bidirectionnelle possible.
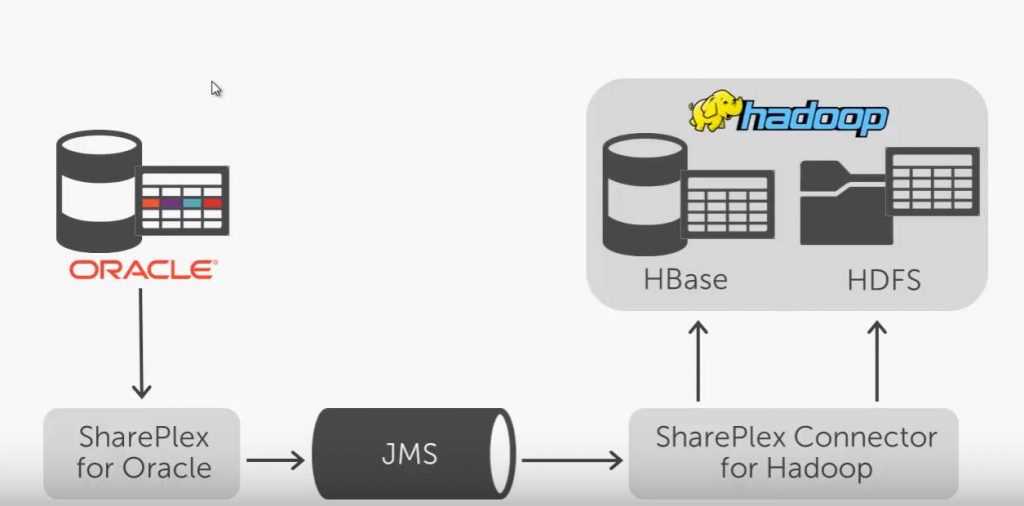
Share Plex de Quest Software
- Se base sur les redo logs => Concerne Oracle
- Les changements identifiés sont bufférisés dans une queue JMS puis stockés dans HDFS / Hbase.
- Voir https://www.youtube.com/watch?v=JuWB5HfYjJY