


Le moteur Vespa de Yahoo

16 oct. 2017
- Catégories
- Tech Radar
- Tags
- Base de données
- Tools
- Elasticsearch
- Search Engine
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Vespa est le moteur de services et de traitements big data complètement autonome et autosuffisant de Yahoo. Il a pour but de servir les résultats de requêtes sur d’énorme quantité de données en temps réel. Un exemple serait de servir des résultats de recherches ou des recommandations à un utilisateur.
Yahoo - ou Oath - a récemment rendu Vespa open source sur GitHub. Actuellement, la documentation se concentre sur l’expérience utilisateur. Rendre le code open soruce va attirer de nouveaux développeurs, particulièrement concernant sa documentation, comme cela a été le cas pour Apache Hadoop il y a plus de 10 ans. D’après Jon Bratseth, Lead Architècte chez Vespa,
En lançant Vespa, nous rendons simple pour tout le monde la création d’applications permettant de traiter des requêtes utilisateur sur des datasets volumineux, en temps réel et à l’échelle d’internet.
Cet article compile certaines de mes notes prises durant mon parcours afin de mieux comprendre la nature de Vespa, ainsi que mon feedback et mon opinion après avoir lu la documentation, testé certains exemples et m’être baladé dans le code source. Je m’assure d’expliquer le vocabulaire technique spécifique à Vespa, donc si vous voyez un mot que vous ne connaissez pas, il est probable qu’un paragraphe lui soit dédié plus tard dans le document.
Que fait Vepsa ?
Vespa vous permet de :
- Sélectionner du contenu en utilisant des requêtes de type SQL et une recherche non structurée ;
- Organiser toutes les correspondances pour générer des pages pilotées par les données ;
- Classez les résultats par des modèles de pertinence manuels ou de machine learning ;
- Ecrire des données persistantes en temps réel des milliers de fois par seconde par nœud ;
- Développer, réduire et reconfigurer des clusters tout en servant et en écrivant.
Vespa repose sur un concept de base familier aux utilisateurs de Hadoop, à savoir déployer et exécuter le code le plus près possible des données. De plus, il permet d’accéder aux données traitées provenant de sources externes si nécessaire. Les applications Vespa peuvent écrire, rechercher et interroger des documents stockés dans le moteur. Elles peuvent également exécuter des dumps de données et gérer les demandes réseau sortantes, telles que l’exposition de services REST HTTP personnalisés.
Comment fait Vespa ?
Vespa divise les nœuds qui font partie de son système en trois catégories :
- Les clusters de conteneurs stateless hébergent les applications du système et la plupart de ses middleware.
- Les clusters de contenu stockent les données du système et effectuent la majeure partie de leur traitement.
- La règle du cluster d’administration et de configuration s’applique à tous les autres composants.
Les applications Vespa, construites à partir de chaînes de composants, sont développées et hébergées dans des conteneurs JDisc. Les conteneurs JDisc constituent la base du conteneur de recherche et du traitement des documents. Ces applications utilisent le système de stockage élastique de Vespa.
L’ensemble du système est géré par un système de configuration cloud complet, un outil simple qui permet aux utilisateurs de Vespa de contrôler l’allocation des ressources.
Vespa est très minimaliste en termes de sécurité, à la fois externe et interne, plus de détails ci-dessous.
Comment fonctionne Vespa ?
Bien que les capacités de Vespa soient spectaculaires, la façon dont elle accomplit une telle vitesse et extensibilité reste floue. Après avoir parcouru la documentation du projet, j’ai une bonne idée de comment utiliser Vespa et pour quoi l’utiliser, mais je ne peux pas visualiser clairement comment cela fonctionne en arrière-plan. Le plus que j’ai découvert est que le moteur Vespa effectue une indexation élaborée des données et des métadonnées afin de répondre aux requêtes avec une très faible latence.
Liens utils
Opérations disponibles
Écriture : Ajouter, remplacer, supprimer ou modifier des documents.
Recherche : recherchez un document ou un sous-ensemble de documents avec leurs identifiants.
Requête : sélectionnez les documents dont les champs correspondent à une combinaison booléenne de conditions. La sélection peut être triée ou classée à l’aide d’une expression de classement donnée (mathématiques, logique métier ou modèle de classement de Machine Learning). La sélection peut également être regroupée par valeurs de champs, qui peuvent ensuite être agrégées. Pour éviter de renvoyer inutilement les données au cluster de conteneur, toute agrégation est effectuée de manière distribuée.
Data dump : récupère toutes les données brutes correspondant à un critère donné.
Requête réseau personnalisée : gérée par les composants d’application déployés sur les clusters de contenu.
Architecture à trois clusters
Vespa divise son système en trois types de cluster : les clusters de conteneur, les clusters de contenu ainsi qu’un cluster d’administration et de configuration.
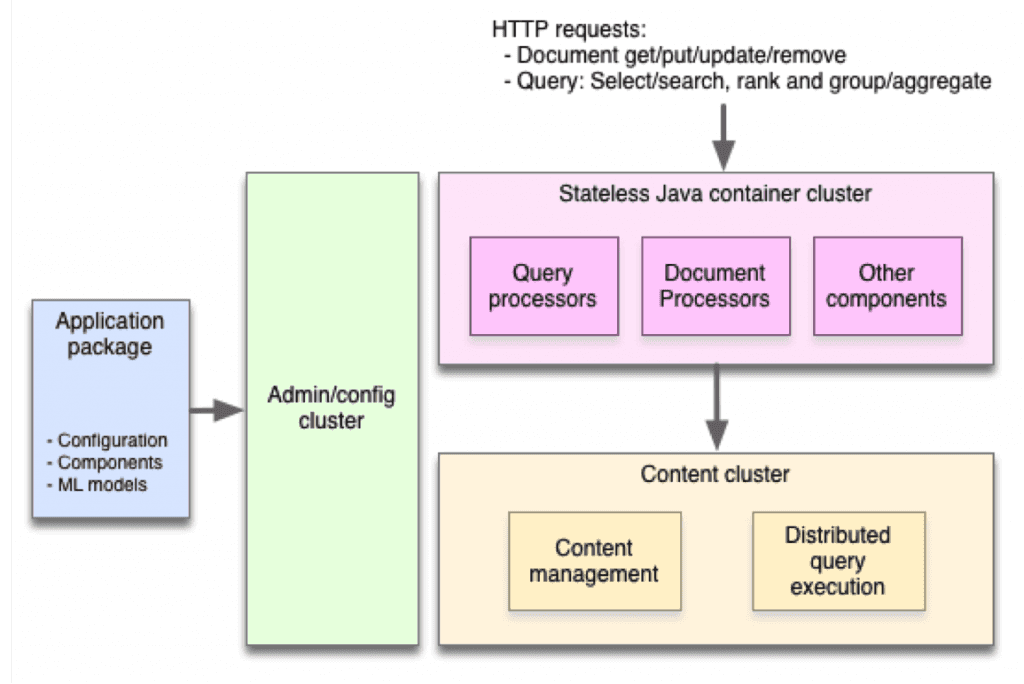
Clusers stateless de conteneurs
Les clusters de conteneurs sont stateless. Ils hébergent les composants applicatifs du système et fournissent une couche réseau pour la gestion et l’émission de requêtes distantes, pour lesquelles HTTP est facilement disponible mais d’autres protocoles peuvent être connectés.
Clusters de contenu
Les clusters de contenu stockent de manière fiable les données en les répliquant sur plusieurs nœuds ; le nombre de copies est spécifié par l’application. Les clusters maintiennent des indices de données distribués pour les recherches et les sélections. Ces clusters peuvent être développés ou réduits en ligne en modifiant le package d’application.
Les recherches sont routées directement vers le nœud correct, cependant, les requêtes sont réparties sur le sous-ensemble de nœuds contenant les documents pertinents. Ces requêtes utilisent des algorithmes distribués avec des étapes de va-et-vient entre les conteneurs et les nœuds de contenu, ce qui permet une faible latence.
Cluster d’administration et de configuration
Il n’y a qu’un seul groupe de ce type car il contrôle les autres groupes. Il dérive de la configuration de bas niveau requis par chaque nœud de chaque autre cluster, en fonction de la configuration de haut niveau par le développeur de l’application.
Les packages peuvent être modifiés, redéployés ou inspectés via une API HTTP REST ou via les commandes CLI. Le processus s’exécute sur Zookeeper, pour s’assurer que les modifications de la configuration sont uniques et cohérentes, tout en évitant tout.
JDisc containers
Sur les clusters de conteneurs, les composants d’application et les plug-ins sont stockés dans des conteneurs JDisc (conteneur de service Java intensif pour les données), également appelés conteneurs middleware (MWC). Ceux-ci constituent la base du conteneur de recherche et du conteneur de traitement de documents : les conteneurs de recherche traitent les requêtes et renvoient les résultats, tandis que les conteneurs docproc renvoient les documents qui leur ont été envoyés, après les avoir traités. Cette structure permet aux composants de traiter ou de modifier toutes les requêtes, les résultats et les documents.
Les conteneurs JDisc fournissent un environnement de développement et d’hébergement pour le traitement des composants, via un modèle de composant basé sur OSGi qui permet le déploiement et le re-déploiement de composants sur un cluster d’instances en cours d’exécution. Ils fournissent également un modèle général de documents, requêtes, résultats et des composants qui les traitent. Enfin, ils fournissent un mécanisme de composition - des chaînes - permettant de créer des applications à partir de composants et de gérer les dépendances de l’ordre d’exécution. Cela permet aux composants d’être développés par différentes équipes.
Liens utiles
Chaînes de composants
Vespa utilise les composants d’application suivants : chercheurs, processeurs de document, gestionnaires et convertisseurs. Les composants chaînés sont exécutés en série et chacun fournit un service ou une transformation.
Chaque composant fournit une liste de services devant figurer dans la chaîne (ses dépendants), ainsi qu’une liste de services devant figurer dans la chaîne (ses dépendances). Ces contraintes d’ordre définissent l’ordre d’exécution.
Fondamentalement, une chaîne est simplement un ensemble de composants d’application avec des dépendances.
Liens utiles
- http://docs.vespa.ai/documentation/chained-components.html
- http://docs.vespa.ai/documentation/searcher-development.html
- https://docs.vespa.ai/documentation/reference/services-docproc.html
- http://docs.vespa.ai/documentation/result-rendering.html
Stockage des données
Elasticité
Vespa stocke les données d’application dans ses clusters de contenu. Les nœuds à utiliser pour le stockage sont spécifiés dans la configuration de chaque application. Les applications peuvent agrandir ou réduire leur matériel tout en répondant aux requêtes et en acceptant les écritures normalement.
Lorsqu’un tel changement se produit, les données sont automatiquement redistribuées en arrière-plan. Vespa applique un minimum de mouvements de données requis pour une distribution uniforme des données. Aucun redémarrage n’est nécessaire : il suffit d’éditer la liste du matériel dans la configuration de l’application et de redéployer celle-ci.
Le même mécanisme est utilisé pour s’adapter aux nœuds ou disques défectueux des clusters de contenu.
À ce jour, Vespa n’est pas optimisé pour fonctionner sur plusieurs datacenters, car son algorithme de distribution n’est pas adapté à la distribution mondiale car il ne cherche pas à minimiser l’utilisation de la bande passante entre les datacenters, ni à tolérer de manière transparente les pannes à l’échelle du datacenter. Actuellement, une solution consiste à exécuter une instance de Vespa dans chaque datacenter et à laisser des applications écrire dans toutes les instances. L’équipe de développement de Vespa se rend compte que ce n’est pas idéal et travaille sur une solution.
Nœuds de stockage
Les nœuds de stockage effectuent le stockage réel. Ils fournissent une interface SPI (Service Provider Interface) qui résume la manière dont les documents sont stockés dans le système élastique. Cette interface est implémentée par les nœuds protons, qui constituent le noyau de recherche de Vespa.
Distributeurs
Lorsqu’un document est écrit ou lu dans le système, il passe par un distributeur. Le rôle principal d’un distributeur est de décider dans quel compartiment un document est stocké.
Buckets
Afin de gérer un grand nombre de documents, Vespa les regroupe dans des compartiments. Ces buckets sont scindés et fusionnés à mesure qu’ils grandissent et diminuent avec le temps. Le SPI relie le système à compartiments élastiques et le stockage de documents proprement dit. Les compartiments contiennent les éléments de base des documents récemment supprimés, qui sont supprimés après un laps de temps configurable.
Liens utiles
Cloud configuration
À première vue, le système CCS (Cloud Configuration System) de Vespa ne semble pas compliqué.
Nous pouvons diviser la configuration en trois catégories :
- Configuration au niveau du système du noeud : définir l’heure système, les privilèges de l’utilisateur,…
- Gestion des packages : assurez-vous que le logiciel approprié est installé sur tous les nœuds.
- Configuration Cloud : démarrez l’ensemble de processus configuré sur chaque nœud avec leurs paramètres de démarrage configurés et fournissez une configuration dynamique aux modules exécutés par ces services. Par configuration, toutes les données qui ne peuvent pas être corrigées au moment de la compilation sont statiques la plupart du temps.
Vespa repose presque exclusivement sur la configuration Cloud. Par conséquent, les utilisateurs de Vespa peuvent autoriser les nœuds du Cloud à utiliser les mêmes logiciels, car les différences de comportement sont gérées entièrement par le biais du CCS. La complexité des variations de nœud est donc gérée via la configuration Cloud plutôt que sur plusieurs systèmes.
La configuration du système Vespa est divisée en assemblage et livraison (assembly and delivery).
L’assemblage de configuration est basé sur le package d’application, qui est envoyé au serveur de configuration. Un modèle de configuration du système distribué est assemblé, acceptant les abstractions de niveau supérieur en tant qu’entrée et dérivant automatiquement des configurations détaillées avec les interdépendances correctes. Une fois validée, cette configuration peut être activée, ce qui mettra à jour toutes les configurations d’application pertinentes.
La livraison de la configuration interroge le modèle de configuration précédemment assemblé pour obtenir les configurations concrètes des composants du système. Les composants s’abonnent à certaines configurations et interrogent l’API du serveur de configuration avant la mise à jour. Les abonnements sont des longs délais d’attente consécutifs, qui fonctionnent d’une manière comparable aux notifications push.
Chaque nœud a un proxy de configuration afin que les composants d’application n’interagissent pas directement et de manière redondante avec le cluster de configuration.
CCS émet plusieurs hypothèses sur les nœuds qui l’utilisent :
- Tous les nœuds disposent des packages logiciels nécessaires à l’exécution du système de configuration et des services qui seront configurés pour s’exécuter sur le nœud. Cela signifie généralement que tous les nœuds ont le même logiciel, bien que cela ne soit pas obligatoire.
- Tous les nœuds ont défini VESPA_CONFIGSERVERS, qui définit les serveurs de configuration à interroger.
- Tous les nœuds connaissent son nom de domaine complet.
La documentation de ce dernier ne précise pas comment Vespa gère les ressources des nœuds lorsque plusieurs applications tentent de l’utiliser. Il semble qu’un système «prioritaire» est en place, mais je n’ai pas pu trouver de détails sur son fonctionnement ni sur la façon de l’utiliser efficacement.
Useful links
- http://docs.vespa.ai/documentation/cloudconfig/config-introduction.html
- http://docs.vespa.ai/documentation/cloudconfig/application-packages.html
Security
Content clusters
La sécurité des clusters de contenu inclus dans Vespa est encore légère.
Les hôtes Vespa doivent être isolés du réseau interne et du réseau interne, ce qui permet de restreindre l’accès aux acteurs du réseau de confiance. Tous les hôtes Vespa doivent pouvoir communiquer entre eux. N’oubliez pas que tous les protocoles internes sont authentifiés. Il incombe à l’utilisateur d’imposer l’isolation du réseau. Cela peut être accompli avec VLan, iptables ou AWS Security Groups, serveurs proxy, etc.
La communication entre nœuds n’est pas chiffrée, ce qui est une pratique courante mettant l’accent sur les performances.
Container clusters
Par défaut, les conteneurs d’applications permettent les écritures et les lectures non authentifiées vers et depuis l’installation de Vespa. L’authentification personnalisée peut être mise en place en utilisant des filtres de requête. mais il n’est pas clair si certains mécanismes tels que les authentifications Kerberos ou LDAP sont disponibles. Les communications doivent être chiffrées à l’aide de SSL/TLS pour sécuriser l’interface HTTP du conteneur JDisc.
Additionnal notes
Tous les processus Vespa sont exécutés sous l’utilisateur Linux donné par $VESPA_USER et stockent leurs données sous $VESPA_USER. Vous devez vous assurer que les fichiers et les répertoires sous $VESPA_HOME ne sont pas accessibles aux autres utilisateurs si vous stockez des données sensibles dans votre application.
Vespa ne prend pas en charge le chiffrement des magasins de documents ou des index sur disque. L’ouverture du moteur sur la communauté opensource peut fournir des fonctionnalités de sécurité supplémentaires.
Liens utiles
http://docs.vespa.ai/documentation/securing-your-vespa-installation.html
Personal opinion
Dans son état actuel, la documentation est de qualité incohérente. Elle décrit en détail l’expérience de l’utilisateur final sur son utilisation mais ne couvre pas assez l’infrastructure du système pour expliquer son fonctionnement.
À mon humble avis, Vespa est énorme. Il semble faire beaucoup et bien le faire. Cela dit, il n’est pas encore prêt à concurrencer des systèmes multi-utilisateurs / multi-tenants bien établis, tels que Hadoop pour le traitement de données volumineuses ou Kubernetes pour l’orchestration des conteneurs. Vespa dégage une ambiance plug-n-play. C’est tentant et j’aimerais avoir plus de temps à ma disposition pour le peaufiner pour des objectifs spécifiques et voir à quel point il est puissant, facile et complex.
