


Apache Thrift vs REST

28 oct. 2017
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Adaltas a récemment assisté à l’Open Source Summit Europe 2017 à Prague. J’ai eu l’occasion de suivre une présentation faite par Randy Abernethy et Jens Geyer de RM-X, une société de conseil en cloud native, sur l’utilisation d’Apache Thrift dans la construction de microservices haute performance. L’objectif de la présentation était de montrer que Thrift est très rapide et tout désigné pour des microservices. Une bonne partie de la présentation traitait sur la comparaison de vitesse entre Apache Thrift, REST et gRPC.
Historique de REST
REST, pour Representational State Transfer, a été défini en 2000 par Roy Fielding. Il permet la communication entre des ressources web (ordinateurs, navigateurs web, …) en respectant un ensemble de contraintes :
- Architecture client-serveur
- Cache-friendly
- Stateless
- Interface standard
- Transport HTTP
Avec de telles caractéristiques, les systèmes REST visent des performances rapides, la fiabilité et la possibilité d’être modifiés sans affecter le système dans son ensemble. La majeure partie du Web repose sur HTTP et REST pour la communication et ils ont tous deux prouvé leur valeur, leur fiabilité et leur scalabité au fil des ans.
Dans l’ensemble, REST est idéal pour le web. Cependant, la pile composée de REST, HTTP et JSON n’est pas optimale pour les hautes performances requises pour le transfert de données internes. En effet, la sérialisation et la désérialisation de ces protocoles et formats peuvent être préjudiciables à la vitesse globale.
C’est là que Thrift entre en jeu.
Apache Thrift
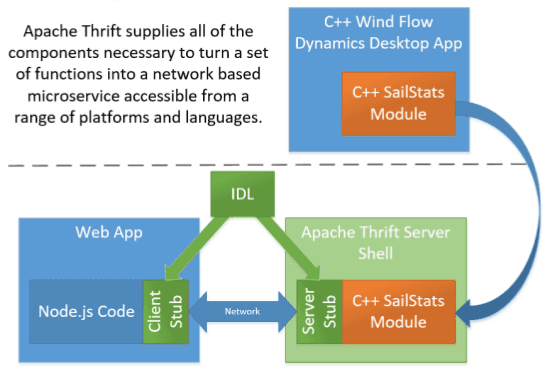
Apache Thrift a été développé à l’origine par Facebook, rendu Open Source en 2007, puis intègre le programme d’incubation Apache en 2008 et avant de devenir un projet Apache top level en 2009. Il est presque impossible de déployer une infrastructure Big Data sans rencontrer Thrift. Par exemple, HiveServer2 est construit en utilisant Thrift. Nous pouvons également citer l’interface Thrift de HBase.
L’infrastructure de Thrift permet de créer des services multi-langages, il supporte actuellement presque 20 langages (C ++, Java, JavaScript, etc.).
Le workflow pour créer un service est le suivant :
- Définissez-le en utilisant l’IDL de Thrift
- Générez des stubs de clients dans touts les langages souhaités
- Générez un stub de serveur et implémentez-le
- Utilisez un serveur Thrift pour implémenter le service
Voici un exemple d’un service Thrift qui serait utilisé pour surveiller les projets GitHub :
struct Date {
1: i16 year
2: i16 month
3: i16 day
}
struct Project {
1: string name
2: string host
3: Date inception
4: i16 commits
}
struct CreateResult {
1: i16 code
2: string message
}
service Projects {
Project get(1: string name)
CreateResult create(1: Project proj)
}Un avantage supplémentaire de Thrift est le support de plusieurs protocoles. Par exemple, le même service peut communiquer en utilisant un protocole binaire, XML ou même JSON. Le codage binaire facilite l’envoi de grandes quantités de données sur des réseaux internes.
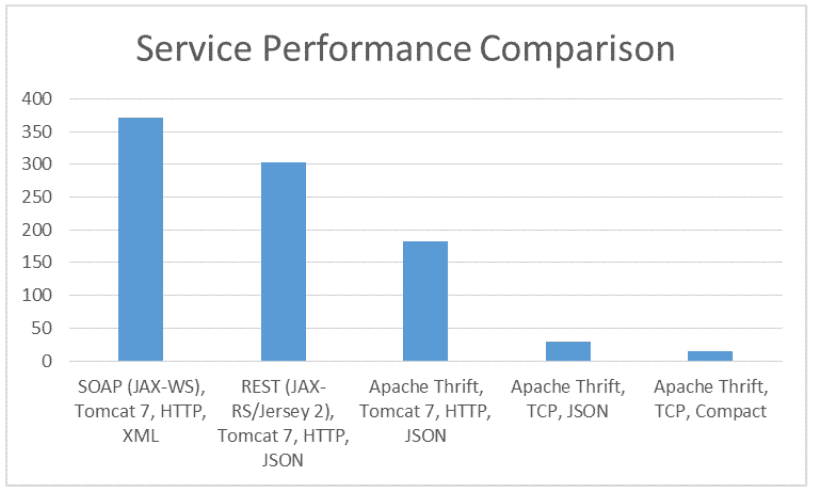
Le graphique ci-dessus montre les performances du même service implémenté en utilisant différents protocoles incluant Apache Thrift et REST. L’axe des verticales est la durée en secondes pour appeler le service 1 million de fois. On constate que Thrift est l’option la plus performante.
Conclusion
Thrift et REST ont tous deux leurs avantages et leurs inconvénients. REST est adapté pour les API Web simples et s’appuie sur le JSON, compréhensible par tous. Toutefois, les coûts de sérialisation le rendent inapproprié à des services internes à l’échelle de l’entreprise. Quand il s’agit de micro-services, la sérialisation binaire rapide qu’offre Apache Thrift en fait un format privilégié orienté performance.
