


Lando : résumé de conversation en Deep Learning

By HATI Yliess
18 sept. 2018
- Catégories
- Data Science
- Formation
- Tags
- Micro Services
- Open API
- Deep Learning
- Internship
- Kubernetes
- Réseau de neurones
- Node.js [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Lando : Les derniers maîtres des mots
Lando est une application de résumé de réunion qui utilise les technologies de Speech To Text pour transcrire de l’audio en écrit et les technologies de Deep Learning pour synthétiser le contenu. Lando permet à ses utilisateurs de comprendre rapidement le contexte de la conversation.
En tant que stagiaires chez Adaltas, nous avons travaillé sur ce projet afin d’explorer la mise en production et l’exploitation d’un projet de Data Science tout en mettant à profit nos connaissances fraîchement acquises dans le domaine du Deep Learning. Dans cet article, nous allons discuter du processus de développement et de l’architecture de Lando.

Microservices
En définissant les tâches, nous avons décidé d’adopter une architecture Microservice : le projet a été divisé en plusieurs applications plus petites appelées Microservices, chacune ne traitant qu’une partie du produit global. Les Microservices offrent une certaine flexibilité : lorsqu’un Microservice est surchargé vous pouvez faire face à une montée de charge en provisionnant de nouvelles instances de ce même service. En d’autres mots, il est possible d’ajuster le nombre de processus et de ressources aux besoins de l’application.
Microservices
Les services constituant le projet sont regroupés en deux catégories. Les points d’entrée API sont accessibles depuis le monde extérieur et fournissent une interface aux utilisateurs finaux. Le core applicatif, inaccessible des utilisateurs finaux, opère les traitements de Deep Learning.
Points d’entrée API
Nous avons plusieurs points d’entrée API :
- Un pour la connexion des utilisateurs
- Un pour la gestion des utilisateurs (infos, inscription etc …)
- Un pour l’entrée de l’utilisateur (recevoir le texte à résumer)
- Un pour permettre à l’utilisateur de recevoir les résultats lorsqu’ils sont prêts
Chaque API a été écrite selon la norme OpenAPI en utilisant l’outil Swagger. Les API sont des serveurs web générés par Swagger en utilisant le framework Express. Ces API utilisent une dépendance commune qui regroupe l’ensemble des messages utilisés comme réponses, les utilitaires utilisés par les autres APIs ou encore les connecteurs aux bases de données.
Core
Le service au cœur de Lando est le traitement Deep Learning qui prend les données fournies par l’utilisateur et produit un résumé du texte avec quelques informations supplémentaires. Cette partie a été écrite en Python pour profiter de nos connaissances avec le framework Tensorflow. Compte tenu de la taille du modèle et des bibliothèques, nous avons décidé de déplacer le dossier contenant le modèle hors de l’environnement Deep Learning. Pour nos tests nous avons utilisé un NFS local, faisant du modèle un point de montage en lecture seule dans le Microservice, mais une solution cloud peut être implémentée rapidement grâce à l’abstraction Persistent Volume de Kubernetes.
Voici la configuration Kubernetes du Microservice Lando Deep Learning :
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
namespace: lando
name: landodp-summarizer
spec:
serviceName: "landodp-summarizer"
replicas: 1
template:
metadata:
labels:
namespace: lando
component: summarizer
spec:
containers:
- name: landodp-summarizer
image: landohub/landodp_summarizer
imagePullPolicy: Always
volumeMounts:
- name: weights-dir
mountPath: /lando_deep_learning/lando/nlp/data
env:
- name: NATS_ENDPOINT
value: nats
resources:
requests:
memory: "1Gi"
cpu: "500m"
terminationGracePeriodSeconds: 7
volumes:
- name: weights-dir
persistentVolumeClaim:
claimName: summarizer-weights-dir
updateStrategy:
type: RollingUpdateVous pouvez observer ci-dessous la définition du point de montage pour le dossier des poids du modèle dans la liste des volumes, le volume étant dénommé summarizer-weights-dir :
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
datadir-cockroachdb-0 Bound pvc-952578cb-850f-11e8-8214-0800271cfb2c 1Gi RWO standard 11d
datadir-cockroachdb-1 Bound pvc-10735233-85b4-11e8-af67-0800271cfb2c 1Gi RWO standard 11d
summarizer-weights-dir Bound summarizer-weights-dir 10Gi ROX 11dIl est lui-même provisionné par le serveur NFS.
Service Frontend
Le service Frontend est simplement un serveur Web avec un site Web statique. Le JavaScript exécuté sur le navigateur de l’utilisateur final se connectera aux APIs mentionnés précédemment. Le service Frontend étant stateless, c’est-à-dire ne stockant aucun état, il peut facilement être mis à l’échelle pour équilibrer la charge.
Bases de données
Comme nous avons adopté une approche en Microservices, nous étions obligés de sélectionner des bases de données distribuées afin qu’elles puissent facilement être mises à l’échelle. Nous avons choisi une base de données relationnelle, distribuée et hautement disponible pour stocker nos données : CockroachDB. Initialement, nous disposions également d’une autre base de données clé-valeur : FoundationDB récemment rendue Open Source par Apple pour stocker les données binaires vocales pour un traitement de la voix permettant l’obtention d’un transcript. Nous l’avons par la suite abandonné tout en laissant la possibilité de la remettre en service pour pouvoir se concentrer sur les parties cruciales du projet.
Le choix de CockroachDB était d’autant plus intéressant que son déploiement sur un cluster Kubernetes était bien documenté.
La décision d’utiliser CockroachDB fut largement influencée par les garanties qu’elle apporte, la richesse des fonctionnalités disponible ainsi que la qualité de sa documentation une fois déployé à l’intérieur d’un environnement Kubernetes.
En plus des bases de données, nous avions besoin d’un moyen de faire passer nos données d’un Microservice à un autre. Nous avons d’abord pensé à Apache Kafka, mais nous avons finalement choisi NATS car il n’a pas de dépendances, il est léger et débuggable avec une simple connexion telnet.
Conteneurs
L’utilisation de conteneurs a été induite par l’approche Microservice. Les conteneurs sont utilisés pour déployer rapidement et efficacement une solution. Leur capacité à démarrer rapidement répond parfaitement aux besoins d’une architecture Microservice : le temps est essentiel lors de la mise à l’échelle d’une application, nous voulons réagir rapidement à une charge soudaine.
Le système est entièrement orchestré par Kubernetes, (Minikube pour nos tests), l’orchestrateur permettant de démarrer et d’arrêter les conteneurs pour s’adapter à la charge. Il est également livré avec un gestionnaire de réseau sans configuration manuelle nécessaire. Il distribue la charge de lui-même et il est facile de changer la version des programmes qu’il exécute. Il demande un léger temps d’apprentissage, mais c’est un outil puissant.
Par exemple, voici tous les pods de Lando lorsque l’application est en cours d’exécution :
NAME READY STATUS RESTARTS AGE
cockroachdb-0 1/1 Running 8 11d
cockroachdb-1 1/1 Running 8 11d
default-http-backend-648cfc585b-zgqvp 1/1 Running 5 6d
foundationdb-0 1/1 Running 15 11d
frontend-httpd-6c9f6db5cd-hpq8q 1/1 Running 2 3d
landodp-summarizer-0 1/1 Running 7 10d
loginmanager-api-5fc996574b-n7t62 1/1 Running 6 6d
nats-0 1/1 Running 8 11d
nginx-ingress-controller-846f5b5c5c-gntw4 1/1 Running 5 6d
realtimeupdate-api-86b5986465-tv55p 1/1 Running 0 2d
sessionmanager-api-66c54df75c-lh757 1/1 Running 6 6d
usermanager-api-76885d8b74-7krqn 1/1 Running 7 6dSécurité
En ce qui concerne la sécurité, notre principale préoccupation était de pouvoir identifier un utilisateur faisant une demande aux API. Nous avons d’abord pensé à un système de jetons, une fois connecté, l’utilisateur reçoit un jeton unique, stocké dans une base de données et transmis avec toutes les demandes que l’utilisateur fait. Le souci principal était la charge imposée à la base de données. Nous avons donc opté pour le JWT (JSON Web Token) :
- Une entête est générée :
{
"type":"JWT",
"alg":"HS256"
}- Les informations de connexions et autre sont placées dans un objet JSON :
{
"userid":"364763392789544962",
"username":"toto",
"userstatus":"0",
"issuedTime":1532078309046,
"expirationTime":1532164709046,
"duration":86400000
}- Une signature est également générée :
Les deux premières parties sont ensuite encodées en base64 et concaténées à la signature séparée par un point et stocké dans le navigateur. Ici le JWT complet est :
eyJ0eXBlIjoiSldUIiwiYWxnIjoiSFMyNTYifQ.eyJ1c2VyaWQiOiIzNjQ3NjMzOTI3ODk1NDQ5NjIiLCJ1c2VybmFtZSI6InRvdG8iLCJ1c2Vyc3RhdHVzIjoiMCIsImlzc3VlZFRpbWUiOjE1MzIwNzgzMDkwNDYsImV4cGlyYXRpb25UaW1lIjoxNTMyMTY0NzA5MDQ2LCJkdXJhdGlvbiI6ODY0MDAwMDB9.N4VqqSFOXeRqLSp16sJFOma+DRIZr/kf5EnY9qiY0CY=Sur le serveur, grâce à la gestion des secrets de Kubernetes, il y a un jeton secret, partagé entre les Microservices nécessitant l’identification de l’utilisateur, la signature étant le hash de l’entête, des informations utilisateur et du secret partagé. Le JWT ne peut donc être altéré sans devenir invalide et donc rejeté par le serveur.
Les problèmes de sécurité incluent également la question des droits et permissions des utilisateurs. Nous avons opté pour des fonctionnalités minimales : l’utilisateur donnant le texte à résumer est le seul à y avoir accès. Les mots de passe de l’utilisateur sont stockés hachés et salés, suivant les pratiques standards de sécurité.
Enfin, nous avons pensé que même avec un bon système d’identification, cela n’aurait aucun sens sans protocole de connexion sécurisé, le jeton pourrait être intercepté et tout le système deviendrait vulnérable aux attaques par rejeu. Nous avons donc tout passé sous https.
Méthodes de travail
Deep Learning
Lors de notre cursus scolaire, il nous fut enseigné la méthodologie suivante pour travailler avec des projets de Deep Learning. Voici les étapes clés à suivre :
- Lire des articles, les plus récents mais aussi quelques-uns des précédents afin de comprendre ce qui fonctionne et ce qui ne fonctionne pas ou moins bien.
- Trouver un bon jeu de données adapté à votre problème ou en créer un grâce aux ressources disponibles en ligne ou ailleurs.
- Essayer de faire marcher le modèle dernier cri, essayer son implémentation officielle si elle existe.
- Commencer par entraîner le modèle d’abord sur sa propre machine et essayer d’affiner les hyperparamètres.
- La plupart du temps, il vaut mieux entraîner le modèle final sur plusieurs GPU. Pour ce faire, il est possible d’utiliser la flexibilité offerte par les offres Cloud. Moins de temps sera requis à l’entraînement et le modèle convergera plus rapidement.
- Enregistrer son modèle et coder quelque chose capable de le charger pour une inférence. Faire ces deux parties dans deux fonctions distinctes.
- Transformer son code pour être utilisé dans une API.
Cette méthode fonctionne mieux avec des projets de Deep Learning qui ne sont pas destinés à devenir des projets de recherche.
Gestion des versions
Chaque API était un projet Node.js à part entière comportant ses propres tests, sa pipeline de déploiement avec NPM et docker-compose pour l’environnement de test. Les tests ont été exécutés dans un conteneur, avec un réseau et un environnement aussi proche que possible de l’environnement cible, Minikube en local. Les dépôts pour le code étaient sur une instance privée de Gitlab mais nous avons utilisé un compte Docker public pour les images. Tous les services étant indépendants, c’était beaucoup plus facile à gérer.
Nous avons également un projet contenant les scripts Kubernetes et la documentation du projet, de sorte que le projet puisse facilement être déployé sur un cluster. Les scripts Kubernetes de déploiement sont écrits à l’aide de Nikita.
Deep Learning
Le Deep Learning est extrêmement populaire de nos jours. Il est présent dans notre navigateur, dans nos voitures, téléphones, etc. La technologie elle-même existe depuis plusieurs années déjà. Mais la majorité des personnes en a entendu parler que récemment grâce au Big Data. En fait, ces algorithmes fonctionnent mieux lorsqu’on leur fournit un volume important de données pour les entraîner. Grâce à la quantité de données recueillies via Internet, les techniques de Deep Learning ont grandi et mûri au point de surpasser les algorithmes dits traditionnels dans de nombreux domaines. C’est l’une des communautés et un des domaines les plus actifs en informatique actuellement.
Compte tenu des exigences du projet, il était évident que nous devions utiliser le Deep Learning pour le traitement de nos données. Les composants principaux de Deep Learning de Lando sont divisés en deux parties : la partie Speech To Text et la partie de synthèse de texte.
Synthèse
Il existe deux types d’algorithmes de synthèse :
- Extractive : Les méthodes d’extraction ne nécessitent pas de Deep Learning elles utilisent du Machine Learning et les statistiques pour résumer un texte en extrayant les échantillons les plus significatifs.
- Abstractive : Les techniques abstractives ont tendance à sembler plus humaines puisqu’elles peuvent résumer en utilisant d’autres termes que ceux présents dans le texte d’origine et ils semblent comprendre le contexte du texte.
Pour simplifier, nous pouvons voir des méthodes d’extraction comme des surligneurs et les méthodes abstractives comme des stylos.
Seulement, les techniques de résumé ne sont pas encore arrivées à maturité, elles ne fonctionnent pas très bien avec des textes de longueur conséquente. Actuellement, la plupart des algorithmes les plus performants sont fondés à la fois sur des techniques statistiques, abstractives. Et c’est ce que nous avons décidé d’utiliser pour Lando.
Pour ce faire, nous avons d’abord parcouru le Web à la recherche des documents sur les dernières techniques en la matière. Un document a attiré notre attention : ’Get To The Point : Summarization with Pointer-Generator Networks’, un résumé abstractif qui peut générer des mots de vocabulaire n’étant pas présents dans son vocabulaire d’origine et peut éviter la redondance.
Le Pointer Generator Network ou PGN est un modèle Sequence to Sequence comme ceux utilisés dans le domaine de la traduction. Au lieu de traduire des phrases, il les résume. Plus précisément, il s’agit d’un type de réseau neuronal récurrent (RNN) possédant un mécanisme d’attention.
- Nous l’alimentons avec des phrases, il les marque ensuite et les traite à travers un Embedding.
- Le mécanisme d’attention calcule une distribution d’attention sur les cellules RNN.
- Nous obtenons un vecteur de contexte qui est combiné avec la sortie précédente du modèle.
- Finalement, cela nous donne une distribution de vocabulaire pour obtenir la sortie suivante jusqu’à ce que nous arrivions à la fin du texte.

Il s’agit là du mécanisme d’un simple modèle Seq2Seq avec attention. Mais cela pose quelques problèmes :
- Certains détails résumés sont faux
- Il se répète souvent
Donc, comme indiqué dans l’article de recherche, le premier problème est résolu en calculant, avant le vecteur de contexte, la probabilité de prendre un mot directement à partir des phrases d’origine au lieu de le calculer. En plus de résoudre le premier problème, il permet au modèle de générer et d’utiliser d’autres mots que ceux présents dans le texte. Pour le deuxième problème, on introduit une erreur de couverture qui représente les idées déjà résumées afin d’éviter de les répéter.
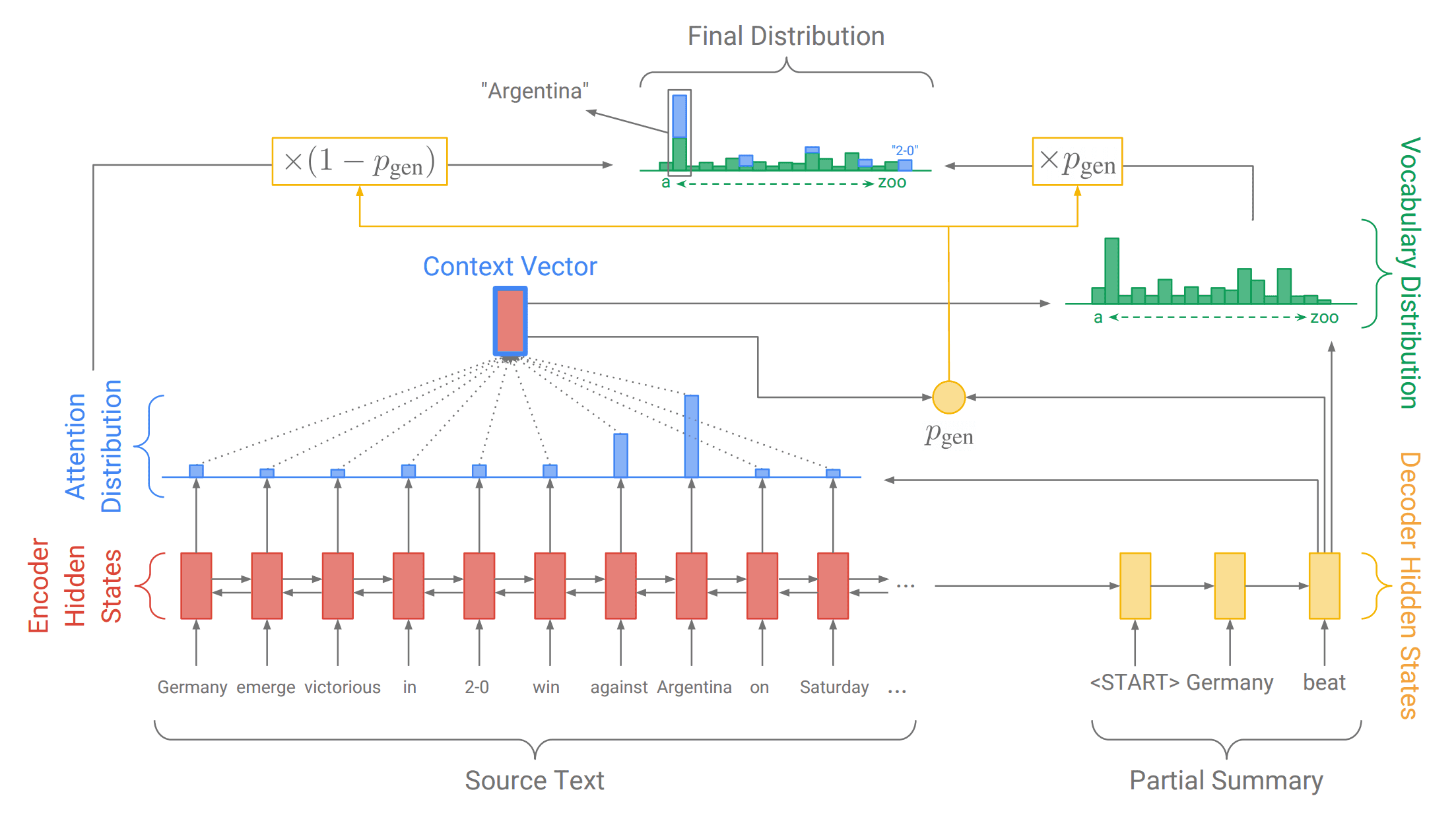
Comme nous n’avons pas assez de temps pour entraîner le modèle, nous avons pris le modèle officiel pré-entraîné. Nous avions commencé à le ré-implémenter à partir de zéro, mais pendant l’entraînement, nous avons réalisé que nos machines ne nous permettraient pas d’avoir des résultats à temps. Nous avons finalement modifié le code officiel pour simplifier son utilisation dans notre projet.
Seulement, comme nous l’avons vu auparavant, cela ne suffit pas, nous devons trouver un moyen d’effectuer un résumé extractif et de regrouper les phrases par sujet. En ce qui concerne la synthèse extractive, nous avons utilisé la bibliothèque Gensim pour pré-résumer les phrases portant sur les mêmes sujets afin d’en alimenter le modèle PGN. La partie la plus difficile était de regrouper les phrases par sujet.
Après quelques recherches, nous avons trouvé des modèles capables d’un telle tâche. Nous devons transformer les phrases en une sorte de représentation vectorielle pour les regrouper selon leur distance. Nous avons donc décidé de former un modèle de sujet : c’est un modèle Encoder-Decoder qui construit une représentation (Embedding) des phrases en regroupant des phrases ayant des thèmes similaires. Les thèmes sont détectés grâce à la Similarité Cosinus. Le modèle que nous avons utilisé s’appelle Doc2Vec et il est inspiré du célèbre modèle Word2Vec utilisé pour les mots dans la plupart des modèles de Natural Language Processing.
La pipeline finale de Deep Learnig est donc :
pour chaque phrase dans le texte:
nettoyer la phrase
calculer sa représentation vectorielle
k = nombre de sujets
faire k clusters à partir des phrases du texte avec k-mean
pour chaque cluster:
faire une synthèse extractive
faire une synthèse abstractive
résumé du texte = concaténer les synthèsesEnfin, avec cette Pipeline, nous pouvons résumer de longs textes. Le seul problème que nous avons maintenant est que les modèles ont été entraînés pour la synthèse d’articles de presse. Nous devons donc les entraîner à nouveau avec les bonnes données.
C’est en fait le problème majeur avec Lando tel qu’il est actuellement. Tous les modèles ont été formés avec des jeux de données conçus pour la synthèse d’articles de journaux. La première véritable amélioration de notre système serait donc de ré-entraîner tous nos modèles avec les données appropriées. Cela soulève une question : existe-t-il un ensemble de données pour la synthèse de réunions ? Le seul que nous ayons trouvé qui pourrait faire l’affaire est un ensemble de données sur la synthèse d’e-mails. Les e-mails s’apparentent à une réunion écrite, mais ce n’est pas exactement ce dont nous avons besoin car il n’y a pas d’interférence, pas de vocabulaire informel. Nous devrions donc commencer à créer notre propre ensemble de données. Avec cette amélioration majeure, nous pensons que notre prototype améliorerait considérablement ses performances.
Speech To Text
Comme le Speech To Text est un problème résolu, nous avons décidé de nous concentrer d’abord sur la tâche de résumé. Mais nous avons tout de même fait quelques recherches sur le sujet et lu quelques articles. En tout, nous avons trois solutions possibles :
- Utiliser l’API de Google qui est actuellement la solution avec les meilleurs performances
- Utiliser une solution intégrée au navigateur
- Faire notre propre modèle
| Pros | Contre | |
|---|---|---|
| API Google | Précis + Rapide | Coût |
| Dans le navigateur | Côté client | Pas assez précis |
| Fait maison | Gratuit + Précis | Long + Entraînement |
Toutes ces solutions sont bonnes, mais il y a des avantages et des inconvénients. Si nous voulons avoir un prototype, nous choisirons la solution In-Browser ou Google, car elle est rapide, facile à utiliser et fonctionne très bien. Mais si nous voulons faire de Lando un service commercial, il vaudrait mieux faire notre propre solution. Grâce à Google, aux articles de Baidu et à toutes les ressources disponibles sur Github, nous pouvons y parvenir avec du temps et de bons jeux de données.
Côté client
Côté client, nous avons réalisé un site JavaScript d’une page pour tester nos appels API. C’est la dernière chose sur laquelle nous allons nous concentrer, alors nous avons décidé de faire quelque chose qui puisse nous donner un aperçu du Lando final. Mais nous avons aussi pensé aux technologies que nous utiliserions pour réaliser cette version et certaines d’entre eux se démarqueraient :

Le site Web doit simplement permettre aux clients de se connecter à leur compte pour accéder aux services Lando. Ils pourront alors résumer de nouveaux textes ou voir les textes précédemment résumés.
Conclusion
Dans l’ensemble, ce projet était intéressant et couvrait un large éventail de technologies et de compétences. C’était une excellente occasion d’apprendre, non seulement des techniques de Deep Learning ou d’infrastructure, mais aussi la gestion de projet. Il y a encore beaucoup de choses à améliorer et à ajouter avant de pouvoir avoir une application entièrement prête à la production, mais le projet se dirige dans la bonne direction.
Liens utilisés dans l’article
- OpenAPI
- Swagger
- Express
- Kubernetes volumes abstraction
- CockroachDB
- FoundationDB
- Kubernetes
- Apache Kafka
- NATS
- Minikube
- JWT
- Kubernetes Secrets Management
- replay attacks
- Gitlab
- NFS
- Deep Learning
- Machine Learning
- Doc2Vec
- Word2Vec
- Pointer Generator Network
- React.js
- Vue.js
- Material Design
- Googles API
- Github
- GPU
- Seq2Seq
- Encoder-Decoder
- Big Data
- Speech To Text
- Gensim
- Natural Language Processing
- Embedding
- Cosine Distance
- Tensorflow
