


Prise de contrôle d'un cluster Hadoop avec Apache Ambari

15 nov. 2018
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Nous avons récemment migré un large cluster Hadoop de production installé “manuellement” vers Apache Ambari. Nous avons nommé cette opération “Ambari Takeover”. C’est un processus à risque et nous allons détailler pourquoi nous avions besoin de réaliser cette opération et comment nous l’avons fait.
Contexte
En 2012, un des clients d’Adaltas nous a exprimé le besoin de déployer un cluster Hadoop fonctionnel de production sur son infrastructure on-premise. Le cahier des charges était orienté sécurité et multi-tenant. Le cluster devait disposer de services en hautes disponibilités, l’authentification via Kerberos, SSL activé etc. Le choix de la distribution déployée serait Hortonworks HDP. Début 2013, le projet Ambari venait de rejoindre définitivement la fondation Apache. L’outil n’était pas le même qu’aujourd’hui. Nous avons donc choisi de déployer le cluster sans Ambari. Nous avons ainsi créé le projet Ryba, que je vais présenter.
Depuis 2013 le cluster a évolué : des nœuds ont été ajoutés, la stack HDP a été upgradée plusieurs fois. Lorsque le client a décidé de déléguer l’infogérance du cluster, nous avons conclu que Ryba n’était plus l’outil le plus adapté. Il nous fallait désormais un outil plus simple d’utilisation. Les services et leurs configurations associées devraient être gérés par Ambari.
Le projet ’Ambari Takeover’ a ainsi commencé.
Ryba
![]()
Ryba est un projet Open Source. Son rôle est de bootstraper des clusters Hadoop sécurisés et fonctionnels en une seule commande ryba install. Ryba sert également de gestionnaire de configuration pour tous ses services. Il peut déployer HDFS, Kerberos, Hive, HBase, etc. Le projet est exécuté en Node.js et est essentiellement écrit en CoffeeScript pour son expressivité.
Ryba est basé sur deux autres projets, également développés par Adaltas : Masson et Nikita.
La couche la plus basse est Nikita : il s’agit d’une collection de fonctions orientées système. Elles permettent de réaliser les actions voulues sur sa machine ou sur un serveur distant via SSH. Les actions Nikita sont variées : créer un dossier, générer un fichier, initier un service systemd, ajouter une règle de pare-feu iptable, etc.
Ces actions sont utilisées par Ryba qui est en quelque sorte une collection d’instructions Nikita spécifique au déploiement de composants Big Data.
Enfin nous avons Masson : un moteur d’exécution de modules. Masson sera utilisé pour ordonnancer le plan d’exécution des composants ainsi que l’enrichissement et le partage des configurations. Par exemple, si vous déployez le HDFS Namenode avec Ryba, Masson vous rappellera qu’il faut également avoir le service HDFS JournalNode (en lisant les dépendances du module HDFS NameNode). Il pourra également lire la configuration du serveur KDC pour créer les keytabs nécessaires.

Voici un exemple simplifié de module Ryba :
# HBase Master Install
module.exports = header: 'HBase Master Install', handler: ({options}) ->
# Créer les règles IPTables sur le noeud où le service HBase Master sera déployé
@tools.iptables
header: 'IPTables'
if: options.iptables
rules: [
{ chain: 'INPUT', jump: 'ACCEPT', dport: options.hbase_site['hbase.master.port'], protocol: 'tcp', state: 'NEW', comment: "HBase Master" }
{ chain: 'INPUT', jump: 'ACCEPT', dport: options.hbase_site['hbase.master.info.port'], protocol: 'tcp', state: 'NEW', comment: "HMaster Info Web UI" }
]
# Créer le user et le groupe 'hbase'
@system.group header: 'Group', options.group
@system.user header: 'User', options.user
# Créer les dossier nécéssaires sur le noeud
@call header: 'Layout', ->
@system.mkdir
target: options.pid_dir
uid: options.user.name
gid: options.group.name
mode: 0o0755
@system.mkdir
target: options.log_dir
uid: options.user.name
gid: options.group.name
mode: 0o0755
@system.mkdir
target: options.conf_dir
uid: options.user.name
gid: options.group.name
mode: 0o0755
# Installe le package HBase Master
@call header: 'Service', ->
@service
name: 'hbase-master'
# Initie le script systemd pour manipuler le service
@service.init
header: 'Systemd Script'
target: '/usr/lib/systemd/system/hbase-master.service'
source: "#{__dirname}/../resources/hbase-master-systemd.j2"
local: true
context: options: options
mode: 0o0640Celui-ci déploie le service HBase Master sur un nœud donné, le code source complet peut être trouvé ici. À instruction commençant par @ correspond une action Nikita. Par exemple : ajouter une règle iptable, créer un dossier, initier un service systemd, etc.
Ambari takeover
La difficulté principale a été de transmettre à Ambari la connaissance de la topologie des clusters (quels services sont déployés où) ainsi que nos configurations (nombre de containers maximum dans YARN, heapsize des HBase Regionservers, etc.). Pour les besoins de cette migration, nous avons créé un fork de Ryba. De cette manière, nous pouvions nous assurer que les configurations personnalisées du cluster serait conservées puisque générées de la même façon qu’elles l’étaient dans Ryba.
Avant de commencer à la migration des services Hadoop, il faut installer Ambari Server et les Ambari Agents ainsi que créer un cluster vide avec aucun service activé. Nous avons fait cela via l’API natif d’Ambari, la WebUI ne le permettant pas. Pour cette étape nous avons automatisé la création du cluster, l’enregistrement des noeuds, etc.
La procédure, appliquable à chaque service déployé sur le cluster (HDFS, HBase, Hive, etc.), est la suivante :
- Positionner le service comme installé.
- Déclarer le composant sur un noeud donné.
- Uploader les configurations pour le composant donné.
- Arrêter le service sur le noeud.
- Supprimer le script systemd ou initd sur le noeud pour être sûr qu’il soit géré par Ambari.
- Démarrer le service via Ambari.
Toutes ces actions sont réalisées via l’API d’Ambari.
Voici un exemple étape par étape avec le service responsable de la coordination du cluster : Apache Zookeeper.
Dans notre cluster de test, le quorum Zookeeper est constitué de trois nœuds. Nous allons les “takeover” un par un pour assurer la continuité du service.
Comme on peut le voir ici, le service est déjà installé et tourne bien sur le nœud master01 :

Nous sommes désormais prêt à migrer le service Zookeeper pour le mettre dans Ambari. Avec l’API, nous allons activer le composant Zookeeper sur le cluster, l’installer sur un nœud (cela sera rapide puisque les packages sont déjà présents sur la machine) et uploader ses configurations. Avant de redémarrer le service avec Ambari, nous allons l’éteindre et supprimer le script systemd pour être sûr qu’il sera ensuite correctement géré par Ambari.

Nous pouvons après cela utiliser l’API Ambari pour démarrer le service :
Enfin, il faut s’assurer que le processus Zookeeper tourne effectivement sur le nœud :

Une fois fini avec le premier nœud, nous pouvons continuer avec les deux autres. Voici le résultat une fois que les trois Zookeepers sont migrés :
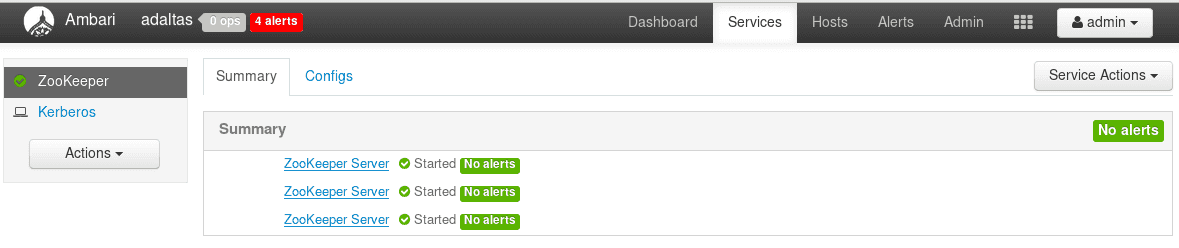
Chaque service Hadoop qui dispose de la haute disponibilité peut être “takeover” de cette manière sans interruption de service pour l’utilisateur. Il s’agissait d’un besoin primordial puisque de nombreux cas d’usages de production tournent sur le cluster en 24/7 fortement solicités.
Dès le début du projet Ryba, l’idée était d’automatiser le plus de choses possibles : générer les truststores, keytabs, etc. Comme notre cluster de production était déjà déployé avec Ryba, il était pertinent de continuer à s’occuper de ces cas. Ambari a la main pour gérer les topologies et configurations, et nous nous chargeons encore de la partie SSL/Kerberos avec Ryba.
En faisant cela, notre projet peut également être utilisé pour bootstrapper un cluster Ambari et déployer ses services sur n’importe quel serveur. Toutes les actions nécessaires à l’implémentation de configurations complexes (SSL, Kerberos, etc.) sont toujours faites telles qu’elles l’étaient dans Ryba. La seule différence étant que les services sont gérés par Ambari et non systemd.
Difficultés
La plus grosse difficulté que nous avons rencontré en migrant nos clusters vers Ambari a été le manque de documentation de l’API d’Ambari. La plupart des API que l’on a utilisé ont été disséquées avec l’outil d’appels réseaux de Firefox. Un travail sur la documentation est un des chantiers d’Hortonworks dans le cadre d’Ambari 2.7/HDP 3.X.
Une autre difficulté notable a été l’absence de visibilité concernant certaines normailisation de la configuration dans Ambari. Lorsque vous changez des propriétés via la WebUI, une popup vous informe du problème si elles rentrent en conflits avec d’autres propriétés. Via l’API, certaines propriétés auront des valeurs par défaut générées par du code, si elles ne sont pas explicitement transmises.
Par exemple, la propriété MapReduce mapreduce.job.queuename, si elle n’est pas spécifiée, sera générée par Ambari, dans l’appel return leaf_queues.pop(). En installant un nouveau cluster, cela renverrait default étant donné qu’il s’agit de l’unique queue (mais dans notre cas nous avions déjà des queues définies). Nous avons passé beaucoup de temps à comprendre pourquoi les jobs de certains utilisateurs étaient envoyés vers la dernière queue du cluster.
Conclusion
Quoique très compliquée, la migration d’un cluster Hadoop vers Ambari est faisable. La principale notion à garder en tête est la disponibilité des services et la consistance des configurations pré et post takeover. Il y a des milliers de configurations parmi les nombreux services d’un cluster. Assurez vous donc de ne pas en oublier !
Note
Le projet ryba-ambari-takeover a été entièrement écrit par Lucas Bakalian.
