


Installation de Kubernetes sur CentOS 7

29 janv. 2019
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Cet article présente la démarche à suivre afin d’installer un cluster Kubernetes. Chaque étape sera détaillée afin que ayez une compréhension approfondie de chacune d’elle.
Cet article s’appuie sur ma présentation lors du Summit Adaltas 2018. Au cours de cette conférence, j’ai présenté le procédé par lequel installer un cluster Kubernetes en partant de zéro. Pour mettre en évidence la puissance de Kubernetes, j’ai installé un cluster Ceph utilisant Rook. Cela permet à la donnée d’être persistée tout au long du cycle de vie de l’application.
Ce dont nous allons parler
- Containers : bref récapitulatif
- Qu’est ce que Kubernetes ?
- Qu’est ce que Ceph ?
- Comment allons-nous les installer ?
- Guide étape par étape
Containers, un bref récapitulatif
Qu’est ce qu’un container exactement ? J’ai souvent entendu les gens comparer les containers aux machines virtuelles (VMs). Bien qu’ils aient des choses en commun, un container n’est pas une VM.
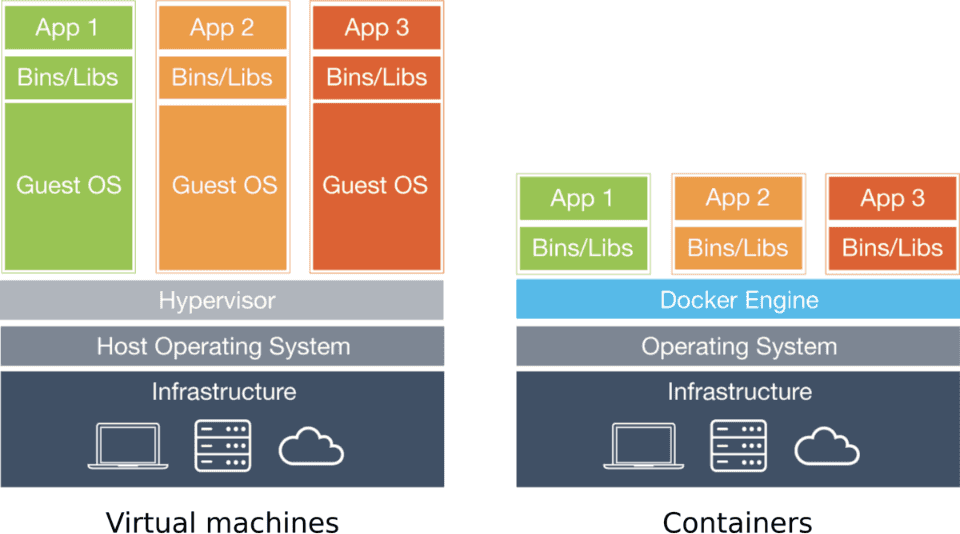
Les machines virtuelles sont nommées ainsi car elles émulent une machine physique sur laquelle peut s’exécuter n’importe quel système d’exploitation : Linux, BSD, Windows, ou tout autre OS. Les VMs sont parfaites pour partager les ressources d’un serveur puissant lorsque des applications nécessitent d’être isolées, par exemple.
L’inconvénient des machines virtuelles est qu’elles exécutent chacune leur propre système d’exploitation. Supposons que vous disposez d’un serveur faisant fonctionner 20 VM. Ce serveur exécute simultanément 21 systèmes d’exploitation au total : le sien et un pour chaque machine virtuelle. Et si tous les 21 de ceux-ci sont Linux ? Il semble inutile de faire fonctionner le même système d’exploitation autant de fois.
C’est là que les containers entrent en jeu. Contrairement aux machines virtuelles, les containers n’exécutent pas leur propre système d’exploitation. Cela leur permet de consommer beaucoup moins de ressources, tout en isolant les différentes applications qui tournent sur le serveur.Vous pouvez packager à peu près n’importe quelle application à l’intérieur d’un container. S’il y a des dépendances, vous pouvez aussi les ajouter. Une fois cette opération effectuée, vous pourrez exécuter votre application à l’aide d’un moteur d’exécution de containers.
Jusqu’ici, les containers semblent vraiment utiles, mais que sont-ils exactement ?
Sur le plan technique, un container est un processus, ou un ensemble de processus, isolé du reste du système par le noyau. Si vous souhaitez en savoir plus sur ces sujets, vous pouvez vous renseigner sur les groups et namespaces.Sur le plan fonctionnel, les containers sont un nouveau moyen de packager et déployer les applications avec un minimum de frais.
Dans le cas où notre infrastructure travaillerait déjà avec des VMs, pourquoi utiliserions nous des containers ?
Pour commencer, les containers sont plus rapides, plus légers et plus efficaces que les machines virtuelles, tout simplement en raison de leur façon de fonctionner. Cela vient du fait que les processus s’exécutant dans un container s’exécutent sur le serveur actuel sans qu’il n’y ait aucune virtualisation. Ensuite, (et je crois que c’est là que réside vraiment leur valeur) les containers sont mobiles d’un environnement à l’autre. Ils fonctionneront exactement de la même manière sur un ordinateur portable de développeur, dans votre pipeline CI/CD ou en production.
Après avoir vu à quel point les containers étaient incroyables, comment pouvons-nous les utiliser ? Aujourd’hui, la réponse la plus populaire à cette question est Docker. Si vous voulez en savoir plus sur les alternatives, regardez rkt ou LXD (vous trouverez ici un très bon article sur LXD rédigé par mon collègue).

Docker offre un moyen simple de construire et d’exécuter des containers. Le contenu de notre container est spécifié dans un Dockerfile. Dans l’exemple ci-dessous, je me base sur une image de container existante, golang:alpine, installe mon application et ses dépendances, et indique à Docker où il peut trouver mon application principale exécutable.
FROM golang:alpine
RUN apk add --no-cache git
RUN go get -u -v github.com/busser/nmon2influxdb
ENTRYPOINT ["/go/bin/nmon2influxdb"]Je peux alors utiliser la CLI Docker pour construire et exécuter mon container.
docker build myapp --tag myapp:v1.0
docker run myapp:v1.0 --name myappSi les choses sont simples dans un environnement de développement, qu’en est-il des containers en production ? Comment pouvons-nous gérer le cycle de vie des containers ? Quand faut-il démarrer le container ? Devrait-il être redémarré s’il crashe ? Combien d’instances de notre container devons-nous exécuter ? Comment maintenons-nous cette cardinalité ? Comment pouvons-nous démarrer de nouveaux containers lorsque la charge de notre application devient trop importante ? Lorsque plusieurs instances de notre application sont en cours d’exécution, comment pouvons-nous équilibrer la charge de ces services ?
Docker ne parvient pas à résoudre tous ces problèmes à grande échelle. Au cours des dernières années, la communauté Open Source a travaillé à la résolution de ces problèmes et a construit plusieurs orchestrateurs de containers différents. Celui qui s’en démarque aujourd’hui est sans aucun doute Kubernetes.

Kubernetes a d’abord été réalisé par Google sur la base de son expérience avec Borg, son système de gestion de containers interne et open-sourcé en 2014. Il est maintenant géré par la Cloud Native Computing Foundation (CNCF), qui fait partie de la Linux Foundation.
De nombreuses entreprises ont contribué à Kubernetes, incluant Google, RedHat, CoreOS, IBM, Microsoft, Mesosphere, VMWare, HP, et la liste continue.
On peut se demander, avec le soutien d’une si grande communauté, que peut faire Kubernetes ?
Il peut déployer des applications containerisées sans effort, automatiser le déploiement et la réplication de containers et regrouper des containers pour fournir un équilibrage de charge. Il permet de déclarer une architecture cible, de déployer des mises à jour progressives, de séparer l’application de l’architecture sous-jacente et de détecter les incidents et l’auto-assistance.
Avant de continuer, un peu de vocabulaire :
- Les pods sont un petit groupe de containers qui sont déployés ensemble. C’est l’unité de base de tous les déploiements de Kubernetes. Si un pod contient plusieurs containers, ceux-ci seront toujours déployés sur le même serveur Kubernetes et auront toujours la même cardinalité.
- Les services sont une abstraction de réseau de réplicas de pod. Lorsque vous avez plusieurs instances de votre application, et donc plusieurs pods, la connexion au service correspondant vous redirigera vers n’importe lequel de ces pods. Voilà comment fonctionne l’équilibrage de charge dans Kubernetes.
- Les namespaces sont une séparation logique des composants Kubernetes. Par exemple, vous pouvez avoir un namespace pour chaque développeur ou différents namespaces pour les applications exécutées en production.
- Les revendications de volume persistant (persistent volume claims, ou PVC) indiquent comment un pod peut continuer à utiliser le même espace de stockage persistant tout au long de son cycle de vie. Si un pod est supprimé puis recréé, en raison d’une mise à niveau de version par exemple, il peut utiliser ses anciennes données tant qu’il utilise la même revendication de volume persistant. Nous utiliserons les PVC une fois que Ceph sera installé dans notre cluster Kubernetes ultérieurement.
Qu’est ce que Ceph ?
Ceph est un logiciel Open Source conçu pour fournir un stockage hautement évolutif des objets, des blocs et des fichiers dans un système unifié.

La raison pour laquelle nous allons utiliser Ceph est qu’il nous permet de créer un système de fichiers distribués sur nos workers Kubernetes. Les pods déployés peuvent utiliser ce système de fichiers pour stocker de la donnée qui sera conservée et répliquée sur le cluster.
Comment installer tout cela ?
Maintenant que nous avons expliqué ce que sont Docker, Kubernetes et Ceph, et quelle est leur utilité, nous pouvons commencer à installer un cluster Kubernetes. Pour cela, nous allons utiliser des outils réalisés par la communauté.
Le premier est kubeadm, une interface de ligne de commande pour initialiser le master et les workers Kubernetes. Cela nous fournira un cluster de base déjà sécurisé.
kubeadm init --apiserver-advertise-address 12.34.56.78
kubeadm join 12.34.56.78:6443 --token abcdef.0123456789abcdefUne fois notre cluster installé, nous utiliserons kubectl, une interface de ligne de commande pour intéragir avec l’API Kubernetes. Cela nous permettra de contrôler notre cluster, de déployer des pods, etc.
kubectl get pods
kubectl apply --filename myapp.yamlPour installer Ceph sur notre cluster, nous allons utiliser Rook. Il exécute un service de stockage cloud natif construit sur des technologies de stockage Open Source comme Ceph.

kubectl apply --filename rook-operator.yaml
kubectl apply --filename rook-cluster.yamlNous pouvons maintenant commencer.
Guide étape par étape
Toutes les commandes que nous allons exécuter ci-dessous doivent être exécutées en tant que super-utilisateur, comme le compte root.
Etape 1 : Préparer vos serveurs
Nous allons utiliser cinq serveurs pour cette installation : un master node, trois workers nodes, et un serveur qui aura le rôle de client. La raison pour laquelle nous utiliserons un serveur séparé comme client est de montrer qu’une fois le cluster Kubernetes installé, il peut être administré via son API à partir de n’importe quel serveur distant.
Personnellement, j’ai utilisé 5 machines virtuelles pour cela. J’ai installé KVM sur mon ordinateur portable Arch Linux. J’ai utilisé Vagrant pour construire et installer ces cinq VMs. Vous trouverez ici mon fichier Vagrant, si vous souhaitez l’utiliser (vous devrez peut-être le modifier pour que cela fonctionne sur votre système) :
# -*- mode: ruby *-*
# vi: set ft=ruby
if Vagrant::VERSION == '1.8.5'
ui = Vagrant::UI::Colored.new
ui.error 'Unsupported Vagrant Version: 1.8.5'
ui.error 'Version 1.8.5 introduced an SSH key permissions bug, please upgrade to version 1.8.6+'
ui.error ''
end
Vagrant.configure("2") do |config|
config.vm.synced_folder ".", "/vagrant", disabled: true
config.ssh.insert_key = false
config.vm.box_check_update = false
config.vm.box = "centos/7"
config.vm.box_version = "=1708.01" # RedHat 7.4
config.vm.provider :libvirt do |libvirt|
libvirt.driver = "kvm"
libvirt.uri = "qemu:///system"
end
cluster = {
"master-1" => { :ip => "10.10.10.11", :cpus => 2, :memory => 2048 },
"worker-1" => { :ip => "10.10.10.21", :cpus => 1, :memory => 4096, :disk => "50G" },
"worker-2" => { :ip => "10.10.10.22", :cpus => 1, :memory => 4096, :disk => "50G" },
"worker-3" => { :ip => "10.10.10.23", :cpus => 1, :memory => 4096, :disk => "50G" },
"client-1" => { :ip => "10.10.10.31", :cpus => 1, :memory => 2048 },
}
cluster.each do | hostname, specs |
config.vm.define hostname do |node|
node.vm.hostname = hostname
node.vm.network :private_network, ip: specs[:ip]
node.vm.provider :libvirt do |libvirt|
libvirt.cpus = specs[:cpus]
libvirt.memory = specs[:memory]
if specs.key?(:disk)
libvirt.storage :file, :size => specs[:disk]
end
end
end
end
endQu’est-ce que le fichier Vagrant dit exactement à Vagrant de construire ? Il n’y a que deux sections qui sont importantes.
Ce bloc demande à Vagrant de construire cinq VMs avec la version CentOS correspondant à RHEL 7.4
config.vm.box = "centos/7"
config.vm.box_version = "=1708.01" # RedHat 7.4Ce bloc spécifie les specs de chaque VM :
cluster = {
"master-1" => { :ip => "10.10.10.11", :cpus => 2, :memory => 2048 },
"worker-1" => { :ip => "10.10.10.21", :cpus => 1, :memory => 4096, :disk => "50G" },
"worker-2" => { :ip => "10.10.10.22", :cpus => 1, :memory => 4096, :disk => "50G" },
"worker-3" => { :ip => "10.10.10.23", :cpus => 1, :memory => 4096, :disk => "50G" },
"client-1" => { :ip => "10.10.10.31", :cpus => 1, :memory => 2048 },
}Le master node a besoin d’au moins deux coeurs de CPU. Les workers ont plus de mémoire et une partition de disque supplémentaire sera utilisée pour Ceph.
Etape 2 : Installation de Docker
Chaque noeud de notre cluster Kubernetes aura besoin de Docker pour travailler.
A cette étape, toutes les commandes seront exécutées sur master-1, worker-1, worker-2, and worker-3.
Pour installer la Community Edition de Docker, nous devons configurer yum afin qu’il utilise le dépôt officiel de Docker.
# Add Docker's yum repository
yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repoNous installons volontairement la version 17.09 de Docker, car il s’agit de la dernière version pour laquelle Kubernetes a été entièrement testée (pour le moment).
# Install Docker CE
yum install --assumeyes docker-ce-17.09.*
# Start and enable the Docker daemon service
systemctl daemon-reload
systemctl start docker
systemctl enable dockerEtape 3 : Installation de kubeadm and kubelet
Chaque noeud de notre cluster Kubernetes aura besoin de kubeadm pour l’initialiser, qu’il s’agisse d’un master ou d’un worker. Le processus d’agent Kubernetes, kubelet, a aussi besoin d’être installé : c’est lui qui va démarrer les containers Docker sur nos serveurs.
Une fois kubeadm installé, kubectl est aussi installé comme une dépendance, mais nous ne l’utiliserons ni sur nos masters ni sur nos workers.
A cette étape, toutes les commandes seront exécutées sur master-1, worker-1, worker-2, and worker-3.
La première chose à faire est de désactiver l’échange de mémoire sur nos nœuds. Ceci est important car nous préférerions que nos containers plantent plutôt que de ralentir faute de RAM suffisante.
# Disable swap
swapoff -a
sed -i '/swap/d' /etc/fstab # remove swap linePour que Kubernetes fonctionne correctement, il est nécessaire de rendre permissif SELinux et de configurer iptables pour permettre le trafic entre containers.
# Make SELinux permissive
setenforce 0
# Pass IPv4/6 traffic to iptables' chains
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --systemComme pour l’installation de Docker, l’installation de kubeadm et de kubelet nécessitent la configuration de yum pour utiliser le dépôt officiel de Kubernetes. Notez la ligne exclude=kube* dans le fichier kubernetes.repo. La raison en est que nous voulons éviter les mises à jour accidentelles de kubelet, qui pourraient conduire à un comportement indéfini.
# Add Kubernetes' yum repository
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
exclude=kube*
EOFPour les besoins de cette démonstration, j’ai choisi d’installer Kubernetes v1.11. La raison pour laquelle je n’ai pas opté pour la v1.12 (la dernière version au moment de la rédaction) est qu’il y a eu des problèmes entre Kubernetes v1.12 et Flannel v0.10.0. Si vous ne savez pas ce qu’est Flannel, ça n’est pas un problème, nous y arriverons bientôt.
# Install kubeadm, kubelet and kubectl
yum install \
--assumeyes \
--disableexcludes kubernetes \
kubeadm-1.11.* \
kubectl-1.11.* \
kubelet-1.11.*
# Start and enable kubelet service
systemctl daemon-reload
systemctl start kubelet
systemctl enable kubeletVous pouvez exécuter la commande ci-dessous pour voir que le démon kubelet est dans un crashloop. C’est parfaitement normal et il n’y a pas de quoi s’inquiéter. Comme les nœuds n’ont pas encore été initialisés par kubeadm, le démarrage de kubelet échoue et systemd essaie de le redémarrer toutes les dix secondes.
# Notice that kubelet is in a crashloop, which is OK
watch -n0 systemctl status kubelet # Ctrl+C to exit watchEtape 4 : Initialiser le master
Nous sommes maintenant prêts à initialiser notre master node Kubernetes .
Toutes les commandes à cette étape seront exécutées sur master-1.
Commencez par télécharger toutes les images de Docker votre master node en aura besoin pour être initialisé. Cela peut prendre du temps, en fonction de votre connexion Internet.
# Pull required Docker images
kubeadm config images pullMaintenant, nous pouvons utiliser kubeadm pour initialiser notre master node. Dans la commande ci-dessous, nous devons spécifier l’adresse IP du master, car il s’agit de l’adresse qui sera annoncée par l’API serveur de Kubernetes. Nous spécifions également la plage que Kubernetes utilisera pour attribuer des adresses IP à des pods individuels.
La commande générera, entre autres choses, une commande kubeadm join. Nous pourrions utiliser cette commande pour ajouter des workers à notre cluster ultérieurement, mais dans un souci d’apprentissage, nous allons générer notre propre commande similaire.
# Initiate master node
kubeadm init \
--pod-network-cidr 10.244.0.0/16 \
--apiserver-advertise-address 10.10.10.11
# 10.244.0.0/16 is required by Flannel's default settings
# 10.10.10.11 is the master node's IP address
# Save kubeadm join command somewhereCette commande a fait pas mal de choses. Les principales sont la génération de certificats SSL pour les différents composants de Kubernetes, la génération d’un fichier de configuration pour kubectl et le démarrage du plan de contrôle de Kubernetes (serveur d’API, etc.).
A ce niveau, le démon kubelet démarre plusieurs pods sur le master node. Vous pouvez voir sa progression avec cette commande :
watch -n0 \
kubectl \
--kubeconfig /etc/kubernetes/admin.conf \
--namespace kube-system \
get pods \
--output wideVous pouvez utiliser Ctrl+C pour quitter la commande watch
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
coredns-78fcdf6894-blnjn 0/1 Pending 0 35m <none> <none> <none>
coredns-78fcdf6894-k5726 0/1 Pending 0 35m <none> <none> <none>
etcd-master-1 1/1 Running 0 35m 192.168.121.213 master-1 <none>
kube-apiserver-master-1 1/1 Running 0 35m 192.168.121.213 master-1 <none>
kube-controller-manager-master-1 1/1 Running 0 35m 192.168.121.213 master-1 <none>
kube-proxy-2wvvp 1/1 Running 0 35m 192.168.121.213 master-1 <none>
kube-scheduler-master-1 1/1 Running 0 35m 192.168.121.213 master-1 <none>Ces pods sont :
- Une instance de etcd, dans laquelle Kubernetes stocke ses métadonnées ;
- L’API server de Kubernets, avec lequel nous allons intéragir à travers kubectl ;
- Le gestionnaire de contrôle Kubernetes , qui s’assurera que le bon nombre de pods s’exécute lorsque nous déployons notre application ;
- Le planificateur Kubernetes , qui décidera sur quel noeud chacun de nos pods devra être exécuté ;
- Le proxy Kubernetes , qui s’exécutera sur chaque nœud du cluster et gérera l’équilibrage de la charge entre nos différents services.
Les pods coredns sont bloqués avec le statut “En attente”, car nous n’avons pas encore installé de plug-in de réseau dans notre cluster. Nous ferons cela une fois que nous aurons ajouté nos workers à notre cluster.
Etape 5 : Préparation de l’ajout de workers
La commande kubeadm init que nous avons exécutée plus tôt a fourni une commande kubeadm join que nous pourrions utiliser pour ajouter des workers à notre cluster. Cette commande contient un token prouvant à Kubernetes que ce nouveau noeud est autorisé à devenir un worker.
L’ensemble des commandes de cette étape sera exécuté sur master-1.
Il est possible d’obtenir une liste des tokens d’authentification existants en exécutant cette commande :
kubeadm token listVous verrez que la commande kubeadm init d’auparavant a déjà créé un jeton. Créons-en un nouveau. Pour cela, exécutez cette commande :
kubeadm token create --description "Demo token" --ttl 1hCette commande va créer un jeton ressemblant à ceci : cwf92w.i46lw7mk4cq8vy48. Sauvegardez le vôtre quelque part.
Il y a encore une chose dont nous avons besoin pour construire notre commande kubeadm join : un hachage du certificat SSL utilisé par le serveur de l’API. Cela permet aux workers node que nous allons ajouter de s’assurer qu’ils communiquent avec le bon serveur d’API. Exécutez cette commande compliquée pour obtenir votre hachage :
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'Cela devrait produire un long hash comme celui-ci :
12920e76e48212ff292e45d716bba76da5d3230f1e1ef4055a586206b5e69138Nous sommes maintenant prêts pour construire notre commande kubeadm join, en utilisant notre token et notre hash. C’est simplement ceci (il ne faut pas encore l’exécuter) :
kubeadm join \
--token cwf92w.i46lw7mk4cq8vy48 \
--discovery-token-ca-cert-hash sha256:12920e76e48212ff292e45d716bba76da5d3230f1e1ef4055a586206b5e69138 \
10.10.10.11:6443N’oubliez pas le sha256 avant le hash.
L’IP et le port à la fin de la commande correspondent au serveur d’API.
Nous sommes maintenant prêts à ajouter nos trois workers à notre cluster. Pour voir comment cela se passe en temps réel, vous pouvez exécuter cette commande dans un autre shell sur master-1 :
watch -n0 kubectl --kubeconfig /etc/kubernetes/admin.conf get nodesEtape 6 : Ajouter des workers
Tout ce que nous avons à faire pour ajouter des workers à notre cluster Kubernetes est d’exécuter notre commande kubeadm join sur chaque worker.
Lors de cette étape, l’ensemble des commandes sera exécuté sur worker-1, worker-2, and worker-3.
kubeadm join \
--token cwf92w.i46lw7mk4cq8vy48 \
--discovery-token-ca-cert-hash sha256:12920e76e48212ff292e45d716bba76da5d3230f1e1ef4055a586206b5e69138 \
10.10.10.11:6443Si vous êtes toujours en train d’exécuter la dernière commande de l’étape 5, vous verrez que les workers node sont ajoutés une fois que vous avez exécuté la commande kubeadm join.
Maintenant que les workers sont ajoutés, vous n’avez plus besoin de kubeadm. Chaque étape qui va suivre utilisera kubectl. Autrement dit, à partir de maintenant, nous pouvons travailler en utilisant seulement l’API de Kubernetes.
Vous remarquerez que les workers sont affichés comme étant NotReady. Cela est normal et nous allons bientôt le réparer en ajoutant un pluging réseau à notre cluster.
Etape 7 : Configurer le client
C’est ici que notre machine client-1 entre en jeu. Nous allons configurer kubectl sur ce serveur.
La raison pour laquelle nous utilisons un serveur séparé est simple : il s’agit de montrer que nous n’avons pas besoin d’accéder aux noeuds actuels du cluster Kubernetes pour l’utiliser.
Tout d’abord, nous devons obtenir la configuration de kubectl, également appelée kubeconfig, du master-1 :
cat /etc/kubernetes/admin.confCe fichier contient toutes les informations dont kubectl a besoin pour se connecter à l’API Kubernetes en tant que cluster-admin, un rôle que vous pourriez comparer à root sur un serveur. Assurez vous que le fichier est sécurisé.
Comme quand vous installez kubeadm et kubelet sur les noeuds du cluster, nous avons besoin de configurer yum sur le client-1 pour utiliser le dépôt officiel Kubernetes.
# Add Kubernetes' yum repository
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
exclude=kube*
EOFMaintenant nous pouvons installer kubectl.
# Install kubectl
yum install \
--assumeyes \
--disableexcludes kubernetes \
kubectl-1.11.*Nous sauvegarderons le fichier de configuration de kubectl en tant que $HOME/.kube/config.
# Configure kubectl
mkdir --parents ~/.kube
vi ~/.kube/config # paste kubectl configuration from master nodeUne fois le contenu de /etc/kubernetes/admin.conf sur master-1 sauvegardé dans $HOME/.kube/config sur client-1, vous pouvez exécuter la commande kubectl depuis client-1. Par exemple :
kubectl get nodesVous remarquerez que nous n’avons plus besoin de l’option --kubeconfig. Cela est dû au fait que $HOME/.kube/config est l’emplacement par défaut de la configuration de kubectl.
Etape 8 : Installer un network plugin
J’ai parlé plus tôt dans cet article et à plusieurs reprises des network plugins en expliquant que c’était la raison pour laquelle nous ne devrions pas nous inquiéter du fait que nos nœuds soient dans un état NotReady, par exemple. Maintenant que nos masters et workers nodes sont tous ajoutés à notre cluster Kubernetes, nous sommes prêts à installer notre network plugin.
Lors de cette étape, toutes les commandes seront exécutées sur client-1.
Dans son état actuel, Kubernetes ne sait pas comment gérer des connexions entre différents pods. Cela est particulièrement vrai quand des pods s’exécutent sur différents workers nodes. La mise en réseau n’est pas très bien traitée par les environnements d’exécution de containers tels que Kubernetes, la communauté a démarré le projet d’interface réseau de conteneur (CNI), désormais géré par la CNCF. Un plug-in réseau est une implémentation du CNI qui permet à Kubernetes de fournir des fonctionnalités de réseau à ses pods. Il existe de nombreux plug-ins réseau tiers différents. Par exemple, le moteur Google Kubernetes (GKE) utilise Calico.
Pour l’exemple d’aujourd’hui, nous opterons pour Flannel, une extension de réseau de pod développée par CoreOS. L’équipe Flannel fournit un fichier YAML qui indique à Kubernetes comment déployer leurs logiciels sur votre cluster. Nous pouvons fournir ce fichier YAML à kubectl et il fera les appels nécessaires à l’API Kubernetes pour nous.
# Install Flannel network plugin
kubectl apply \
--filename https://raw.githubusercontent.com/coreos/flannel/v0.10.0/Documentation/kube-flannel.ymlKubernetes déploiera rapidement une instance de Flannel sur chacun de nos nœuds, masters et workers. Vous pouvez voir les pods correspondants avec cette commande :
kubectl get pods --namespace kube-system --output wideVous devriez obtenir quelque chose comme cela :
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
coredns-78fcdf6894-l6dw8 1/1 Running 0 4h 10.244.2.2 worker-2 <none>
coredns-78fcdf6894-zzqrf 1/1 Running 0 4h 10.244.2.3 worker-2 <none>
etcd-master-1 1/1 Running 0 4h 192.168.121.143 master-1 <none>
kube-apiserver-master-1 1/1 Running 0 4h 192.168.121.143 master-1 <none>
kube-controller-manager-master-1 1/1 Running 0 4h 192.168.121.143 master-1 <none>
kube-flannel-ds-45h7l 1/1 Running 0 18m 192.168.121.154 worker-1 <none>
kube-flannel-ds-bw7z4 1/1 Running 0 18m 192.168.121.143 master-1 <none>
kube-flannel-ds-jzcfd 1/1 Running 0 18m 192.168.121.83 worker-2 <none>
kube-flannel-ds-vmqdh 1/1 Running 0 18m 192.168.121.204 worker-3 <none>
kube-proxy-4mfnl 1/1 Running 0 4h 192.168.121.154 worker-1 <none>
kube-proxy-59l9j 1/1 Running 0 4h 192.168.121.143 master-1 <none>
kube-proxy-qwfkc 1/1 Running 0 4h 192.168.121.83 worker-2 <none>
kube-proxy-rrk5v 1/1 Running 0 4h 192.168.121.204 worker-3 <none>
kube-scheduler-master-1 1/1 Running 0 4h 192.168.121.143 master-1 <none>Vous remarquerez peut-être aussi que nos pods coredns fonctionnent enfin. C’est parce qu’ils attendaient qu’un plugin réseau soit installé.
Vous pouvez vérifier le statut de nos quatre différents noeuds :
kubectl get nodesVous devriez voir quelque chose comme cela :
NAME STATUS ROLES AGE VERSION
master-1 Ready master 4h v1.11.4
worker-1 Ready <none> 4h v1.11.4
worker-2 Ready <none> 4h v1.11.4
worker-3 Ready <none> 4h v1.11.4Nos nœuds sont maintenant également prêts, puisque Flannel fournit désormais des fonctionnalités réseau essentielles.
Nous avons maintenant un cluster Kubernetes qui fonctionne !
