


Spark Streaming partie 4 : clustering avec Spark MLlib

27 juin 2019
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Spark MLlib est une bibliothèque Spark d’Apache offrant des implémentations performantes de divers algorithmes d’apprentissage automatique supervisés et non supervisés. Ainsi, le framework Spark peut servir de plateforme pour développer des systèmes d’apprentissage automatique. Un modèle de Machine Learning (ML) développé avec Spark MLlib peut être associé à un pipeline de streaming crée avec Spark Structured Streaming. Cette architecture offre un faible temps de latence. Cette article intègre l’algorithme de clusternig K-means au pipeline de données développé dans les articles précédents.
Ceci est l’ultime article d’une série en quatre parties.
- Dans la première partie, un pipeline de données est créé en Python avec Spark Structured Streaming.
- La deuxième partie concerne la migration du pipeline vers un cluster Hadoop.
- Dans la troisième partie, l’application PySpark a été portée et testée dans un environnement Scala Spark et des test unitaires ont été ajoutés.
- La quatrième et dernière partie enrichie le pipeline de données avec un algorithme du regroupement par apprentissage automatique.
Pour enrichir le pipeline existant avec un algorithme de Machine Learning nous suivrons les étapes suivantes :
- Data Engineering pour la préparation des données d’entrée
- Développement du modèle de Machine Learning
- Intégration du modèle de ML dans le pipeline de données en streaming
Le pipeline Spark MLlib est entraîné sur les données historiques en mode batch. Ensuite, le modèle résultant sera utilisé dans une autre application Spark Streaming. En production, les calculs des clusters sont supposés être périodiquement relancés pour mettre à jour le modèle ML.
Le code source du projet est accessible sur le dépôt GitHub adaltas/spark-mllib-streaming. Ce projet étend l’application Spark écrite en Scala du dépôt spark-streaming-scala avec un algorithme de Machine Learning k-means.
Cas d’usage pour le clustering
Le cas d’usage central à toute la série d’articles concerne les chauffeurs de Taxi de New York qui souhaitent optimiser leurs pourboires. La question à laquelle nous avons cherché à répondre dans les parties précédentes de la série était :
En tant que chauffeur de taxi, quel quartier de Manhattan choisir pour avoir un plus gros pourboire ?
Cette question impose une granularité spatiale déterminée par les quartiers de Manhattan. Un chauffeur de taxi ne peut être informé que d’un quartier où les pourboires sont importants, sans plus de précision. Suite à cette question, la solution développée précédemment reposait sur la division administrative de Manhattan.
Une granularité plus fine que les quartiers améliorerait l’utilité du service et répondrait mieux au cas d’usage. La question peut être généralisée ainsi :
Quelle région de Manhattan un chauffeur de taxi devrait-il choisir pour obtenir un pourboire élevé ?
Une région peut être n’importe quelle zone de taille arbitraire. Au lieu de diviser Manhattan en quartiers, nous rechercherons de petites zones avec des pourboires élevés. Un algorithme k-means de Machine Learning sera utilisé pour obtenir des domaines d’intérêt. Chacune de ces zones est un groupe de trajets en taxi avec des pourboires élevés. Un tel groupe sera appelé un cluster par la suite.
Notez qu’un cluster peut avoir deux significations. Un cluster peut être un partitionnement de données, data clustering en anglais, par exemple un groupe de trajets en taxi. Il peut aussi être associé à un ensemble d’ordinateurs dans les systèmes distribués, comme un cluster Hadoop par exemple. Les deux termes sont pertinents au context de cet article et la signification du terme cluster devrait être clairement déductible.
Le Clustering est une tâche d’apprentissage non supervisé consistant à regrouper des objets similaires dans des catégories (les clusters). De telles tâches ne sont pas évaluables facilement, car les observations directes ne sont pas disponibles et les donneés ne sont pas annotées. Les trajets en taxi n’appartiennent pas naturellement à un groupe de solutions particulier. Le partitionnement obtenu avec le clustering peut être bon ou mauvais, selon le cas d’utilisation et l’interprétation. Le choix du nombre de cluster k, qui a le plus grand impact sur les grappes obtenues, est largement subjectif.
Obtention des données des Taxis
Le dataset utilisé est une version légèrement modifiée du dataset Taxi Data de la formation Apache Flink. Il s’agit d’un petit dataset de 100 Mo obtenu à partir de données originales des voyages en Taxi de la ville de New York.
Si vous avez un cluster Hadoop et avez suivi la deuxième partie de la série, le jeu de données brut est déjà disponible dans les répertoires /tmp/datalake/RidesRaw et /tmp/datalake/FaresRaw sur HDFS. Dans ce cas, vous pouvez utiliser ces données et ignorer le reste de cette section.
Vous pouvez suivre cette partie de la série sans cluster Hadoop. L’application Scala Spark ci-dessous crée le dataset brut nécessaire en local sur un votre ordinateur. Les données sont stockées au format de fichier Parquet et suivent le même partitionnement que dans les parties précédentes de la série.
Pour commencer, téléchargez les dataset compressés de Flink : nycTaxiRides.gz et nycTaxiFares.gz.
# from project's directory
curl -s https://training.ververica.com/trainingData/nycTaxiRides.gz -o nycTaxiRides.gz
curl -s https://training.ververica.com/trainingData/nycTaxiFares.gz -o nycTaxiFares.gzEnsuite, créez un fichier Scala : src/main/scala/com/adaltas/taxistreaming/DataLoader.scala dans le package com.adaltas.taxistreaming.
package com.adaltas.taxistreaming
import org.apache.spark.sql.functions.{col, dayofmonth, month, year}
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, SparkSession}
object DataLoader {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.appName("Local fs data writer")
.master("local")
.getOrCreate()
val taxiRidesSchema = StructType(Array(
StructField("rideId", LongType), StructField("isStart", StringType),
StructField("endTime", TimestampType), StructField("startTime", TimestampType),
StructField("startLon", FloatType), StructField("startLat", FloatType),
StructField("endLon", FloatType), StructField("endLat", FloatType),
StructField("passengerCnt", ShortType), StructField("taxiId", LongType),
StructField("driverId", LongType)))
val taxiFaresSchema = StructType(Seq(
StructField("rideId", LongType), StructField("taxiId", LongType),
StructField("driverId", LongType), StructField("startTime", TimestampType),
StructField("paymentType", StringType), StructField("tip", FloatType),
StructField("tolls", FloatType), StructField("totalFare", FloatType)))
var dfRides = spark.read
.option("header", false)
.option("inferSchema", false)
.schema(taxiRidesSchema)
.csv("nycTaxiRides.gz")
var dfFares = spark.read
.option("header", false)
.option("inferSchema", false)
.schema(taxiFaresSchema)
.csv("nycTaxiFares.gz")
dfRides
.withColumn("year", year(col("startTime")))
.withColumn("month", month(col("startTime")))
.withColumn("day", dayofmonth(col("startTime")))
.write
.format("parquet")
.partitionBy("year", "month", "day")
.save("datalake/RidesRaw")
dfFares
.withColumn("year", year(col("startTime")))
.withColumn("month", month(col("startTime")))
.withColumn("day", dayofmonth(col("startTime")))
.write
.format("parquet")
.partitionBy("year", "month", "day")
.save("datalake/FaresRaw")
spark.stop()
}
}Compilez votre application en .jar et soumettez-le à l’exécution :
spark-submit \
--class com.adaltas.taxistreaming.DataLoader \
target/scala-2.11/spark-streaming-scala_2.11-0.1.0-SNAPSHOT.jarÀ la racine du projet, créez deux nouveaux répertoires : datalake/FaresRaw et datalake/RidesRaw. Ils contiennent les mêmes datasets comme ceux stockés sur HDFS dans les parties précédentes.
Features
Les features sont les variables d’entrées. Elles sont équivalents aux variables indépendantes en statistiques. En Machine Learning elles sont formellement définies de cette manière :
Une feature est une propriété ou une caractéristique individuelle mesurable d’un phénomène observé.
Dans notre cas, les featues sont des colonnes du dataset qui seront utilisées pour le calcul des clusters. Trois variables seront utilisées pour le regroupement : startLon, startLat et tip. Avant de pouvoir partitionner les données en fonction de ces caractéristiques, le jeu de données doit être prétraité.
Préparation des données d’entrée
Pour commencer, créez un package com.adaltas.taxistreaming.clustering contenant un fichier MainKmeans.scala. Les modèles K-means s’en serviront pour leur entraînement. Chargez les fichiers Parquet du dataset des Taxis et convertissez les en DataFrame Spark :
package com.adaltas.taxistreaming.clustering
import org.apache.spark.sql.DataFrame
object MainKmeans {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.appName("Part 4")
.getOrCreate()
val dfRides: DataFrame = spark.read.parquet("datalake/RidesRaw")
.selectExpr("rideId","endTime","startLon",
"startLat","endLon", "endLat")
val dfFares: DataFrame = spark.read.parquet("datalake/FaresRaw")
.selectExpr("rideId AS rideId_fares", "startTime", "tip")
}Ajustez les chemins de fichiers Parquet si nécessaire. Spark prend en charge les fichiers Parquet en tant que sources de données, déduit automatiquement les clés de partitionnement des fichiers Parquet et charge le schéma préservé.
Dans le fichier build.sbt, ajoutez la dépendance Spark MLlib (correspondant à votre version de Spark) :
libraryDependencies += "org.apache.spark" %% "spark-mllib" % "2.3.0"Créez maintenant un fichier “TaxiProcessingBatch.scala” dans le package com.adaltas.taxistreaming.processing. Le code ci-dessous prend les trajets de taxi terminés dans notre région d’intérêt, Manhattan, et effectue une jointure entre les DataFrames dfRides et dfFares. Les trajets sans aucun pourboire sont filtrés. Nous créons aussi une nouvelle colonne avec l’heure de début du trajet obtenue à partir de la date de départ.
package com.adaltas.taxistreaming.processing
import org.apache.spark.sql.functions.{col, expr, hour, udf}
import org.apache.spark.ml.linalg.Vectors
object TaxiProcessingBatch {
def prepareTaxiData(dfRides: DataFrame, dfFares: DataFrame): DataFrame = {
// Manhattan bbox
val lonEast = -73.887
val lonWest = -74.037
val latNorth = 40.899
val latSouth = 40.695
var dfRidesManhattan = dfRides.filter(
col("startLon") >= lonWest && col("startLon") <= lonEast &&
col("startLat") >= latSouth && col("startLat") <= latNorth &&
col("endLon") >= lonWest && col("endLon") <= lonEast &&
col("endLat") >= latSouth && col("endLat") <= latNorth).
filter(col("isStart") === "END").
join(dfFares, expr ("""
rideId_fares = rideId AND
endTime > startTime AND
endTime <= startTime + interval 2 hours
""")).
filter(col("tip") > 0).
withColumn("startHour", hour(col("startTime"))).
drop(col("rideId_fares"))
val vectCol = udf((tip: Double) => Vectors.dense(tip))
dfRidesManhattan.withColumn("tipVect", vectCol(dfRidesManhattan("tip")))
}
}Notez qu’une nouvelle colonne tipVect est créée avec la fonction UDF vectCol (User Defined Function). Le pourboire a été inséré un vecteur MLlib de Spark. Cette conversion est nécessaire pour un traitement ultérieur avec les algorithmes de transformation de Spark MLlib.
La fonction prepareTaxiData que nous venons de définir peut être utilisée pour obtenir un DataFrame contenant un trajet en Taxi qui a débuté dans Manhattan et s’est conclu avec un pourboire. Ajoutez le à la fonction main de MainKmeans :
import com.adaltas.taxistreaming.processing.TaxiProcessingBatch
val dfRidesManhattan = TaxiProcessingBatch.prepareTaxiData(dfRides, dfFares)Mise à l’échelle des features
Dans cet article, deux types de caractéristiques sont utilisées pour le clustering : une géographique et une financière. Ces caractéristiques ont des unités incomparables et des magnitudes différentes. Par exemple, une différence de latitude de 0,05 degré est importante mais serait pratiquement négligeable par rapport au pourboire de 5 dollars. En d’autres termes, les variables géographiques seraient complètement écrasées si l’algorithme de clustering était appliqué sur le dataset en l’état.
A partir du code, nous pouvons trouver la latitude et longitude minimale de Manhattan dans les champs startLon et startLat. Chacune ne varie que de 0.1 ou 0.01 degrés.
Nous pouvons trouver le minimum et le maximum du champ tip avec la commande dfRidesManhattan.select("tip").describe().show(). Le pourboire va jusqu’à 153,35$, il varie donc bien plus que la latitude et la longitude. Cette différence poserait un problème pour l’algorithme k-means qui est sensible à la variance et les clusters seraint calculés uniquement à partir du pourboire. La mise à l’échelle permet de résoudre ce problème.
Nous ne pouvons pas simplement centrer et réduire les variables. Cela introduirait des distortions dans les coordonnées géographiques. Nous allons plutôt mettre la variable tip à la même échelle que la latitude et la longitude. Cela implique que pour avoir la véritable valeur du pourboire il faudra plus tard remettre le champ à l’échelle.
Nous pouvons utiliser le MinMaxScaler de Spark pour mettre le pourboire à l’échelle. Sa borne supérieure peut être spécifiée par le paramètre setMax. Pour utiliser le MinMaxScaler, la colonne tip doit être du type Vector. Cette conversion a déjà été faite dans la fonction prepareTaxiData où la colonne tipVect a été préparée. Le tipScaler peut être créé avec le code ci-dessous :
import org.apache.spark.ml.feature.MinMaxScaler
val tipScaler = new MinMaxScaler()
.setInputCol("tipVect")
.setOutputCol("tipScaled")
.setMin(0)
.setMax(1)Les bornes des latitudes et des longitudes ont moins de 0.5 degrés d’écart, alors que les extrèmes du pourboire ont un écart de 153.35$. Pour rendre le pourboire comparable avec les caractéristiques géographiques, la valeur de setMax pour la mise à l’échelle était de 1. Cette mise à l’échelle rend intentionnelement plus important le pourboire que les informations géographiques mais aucune caractéristique ne domine désormais. Le tipScaler n’a pas encore été appliqué.
Assemblage des features
Pour utiliser l’algorithme k-means de Spark, une seule colonne de “features” de type Vector est acceptée. Actuellement, les features sont dans des colonnes différentes. Il faut les fusionner en une seule colonne de type Vector. Nous utilisons le VectorAssembler de Spark.
import org.apache.spark.ml.feature.VectorAssembler
val featuresAssembler = new VectorAssembler().
setInputCols(Array("startLon", "startLat", "tipScaled")).
setOutputCol("features")Ni le tipScaler ni le featureAssembler n’ont été utilisés pour le moment. Ils ont uniquement été préparés et seront incorporés dans un Pipeline MP de Spark plus tard.
K-means
L’algorithme K-means est probablement l’algorithme de classification le plus populaire. Son nom indique le nombre de k clusters à spécifier avant l’utilisation de l’algorithme. En pratique, k-means optimise le partitionnement des données pour trouver un minimum de variance intra-cluster dans tous les k clusters. Nous choisirons k = 12 comme point de départ.
Le clustering est généralement effectué sur des données statiques, mais le jeu de données taxi est une série temporelle. Ignorer l’aspect temporel de l’ensemble de données retirerait probablement tout leur sens aux clusters. La solution la plus simple consiste à diviser les trajets en segments d’une heure. Chaque segment aura un modèle de clustering distinct. Ainsi, 24 modèles k-means indépendants seront calculés, un pour chaque heure de la journée.
Vous vous demandez peut-être pourquoi le vecteur de featues ne peut pas être étendu avec une caractéristique contenant l’heure. Cela semble raisonnable, car plus la différence de temps entre les trajets est grande, plus différents il faut les considérer. Cependant, cela crée un risque d’affecter différents trajets au même cluster, uniquement parce qu’elles se sont déroulées à la même heure. Par exemple, si un groupe de trajets avait des pourboires aléatoires et une grande dispersion géographique, ils ne devraient pas être considérés comme similaires uniquement parce qu’ils se produisaient au même moment.
Un autre aspect est la mesure de similarité. Les trajets vont être jugés similaires ou différents les unes des autres. Les caractéristiques utilisées pour cette comparaison sont la longitude, la latitude et le pourboire. Cependant, diverses mesures de distance pourraient être utilisées pour comparer ces caractéristiques. Bien qu’il existe des métriques spéciales pour les séries temporelles et les données géographiques, la mesure la plus populaire est choisie : la distance euclidienne.
Spark MLlib a une implementation de KMeans, elle est initialisée comme suit :
import org.apache.spark.ml.clustering.KMeans
val k = 12
val kmeansEstimator = new KMeans().setK(k).setSeed(1L)Le pipeline Spark MLlib
La pipeline ML de Spark permet de combiner facilement plusieurs processus dans un workflow ML. Un pipeline est construit à partir des objets Transformer et Estimator. Un Transformer converts DataFrame dans un autre DataFrame. Les MinMaxScaler et VectorAssembler créés précédemment sont des exemples de Transformer. Un estimateur crée un Model, qui est un type particulier de Transformer. Dans le cas de KMeans, l’estimateur est un KMeansModel. Créez la fonction prepareKmeansPipeline dans MainKmeans à partir du package com.adaltas.taxistreaming.clustering :
def prepareKmeansPipeline(k: Int): Pipeline = {
val tipScaler = new MinMaxScaler()
.setInputCol("tipVect")
.setOutputCol("tipScaled")
.setMin(0)
.setMax(1)
val featuresAssembler = new VectorAssembler()
.setInputCols(Array("startLon", "startLat", "tipScaled"))
.setOutputCol("features")
val kmeansEstimator = new KMeans().setK(k).setSeed(1L)
new Pipeline().setStages(Array(tipScaler, featuresAssembler, kmeansEstimator))
}Avec cette fonction, le pipeline ML souhaité est créé en une ligne de code. Testons la sur un exemple entre 10 et 11 heures du matin :
import org.apache.spark.ml.clustering.KMeansModel
import com.adaltas.taxistreaming.processing.TaxiProcessingBatch
/* prepareKmeansPipeline(...) defintion */
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.appName("Part 4")
.getOrCreate()
val dfRides: DataFrame = spark.read.parquet("datalake/RidesRaw")
.selectExpr("rideId","endTime","startLon",
"startLat","endLon", "endLat")
val dfFares: DataFrame = spark.read.parquet("datalake/FaresRaw")
.selectExpr("rideId AS rideId_fares", "startTime", "tip")
val dfRidesManhattan = TaxiProcessingBatch.prepareTaxiData(dfRides, dfFares)
//keep original max tip for rescaling later on
val originalTipMax = dfRidesManhattan
.agg(org.apache.spark.sql.functions.max("tip")).collect()(0).getFloat(0)
val k = 12
// Example for 10am
val datasetHour = dfRidesManhattan.filter(col("startHour") === 10)
val pipeline = prepareKmeansPipeline(k)
val kmeansPipe = pipeline.fit(datasetHour) // obtain a PipelineModel
val centers = kmeansPipe.stages(2).asInstanceOf[KMeansModel].clusterCenters
centers.foreach(println)
}Chaque centre de cluster est un Vector Spark dont les valeurs correspondent à la longitude, latitude et le pourboire mis à l’échelle.
Evaluation des clusters
L’évaluation interne des clusters mesure la qualité des clusters. L’une des mesures pour l’évaluation interne est le score de Silhouette qui prend une valeur entre -1 et 1 dépendant de la “compacité” du cluster. Ce score est calculé ci-dessous :
val predictions = kmeansPipe.transform(datasetHour) //appends prediction column to df
val evaluatorSilhouette = new ClusteringEvaluator()
val silhouette = evaluatorSilhouette.evaluate(predictions)
println(s"Silhouette with squared euclidean distance = $silhouette at k=$k")Par exemple à 10h du matin, le score de Silhouette est de 0.407 pour k=12. Ce score indique une forte variance des clusters, ce qui n’est pas une bonne chose. Le score de Silhouette n’est qu’une partie de l’évaluation des clusters, un bon score ne garanti pas que les clusters soient pertinents pour notre cas d’usage. Remarquez que même des clusters de haute qualité peuvent être inutile pour le cas d’usage. Une évaluation humaine est requise. Nous allons à présent calculer la variance des clusters et visualiser nos clusters pour confirmer l’évaluation du score de Silhouette.
Calcul de la variance des clusters
La variance d’un cluster décrit la dispersion autour de la moyenne. Cela donne une idée de la taille du cluster. Créons une fonction qui prend le DataFrame predictions avec chaque course de Taxi assigne à un des k clusters dans la colonne prediction et retourne un DataFrame avec les variances intra-cluster. Ajoutons cette fonction à MainKmeans :
def computeVariances(predictions: DataFrame): DataFrame = {
/* Calculate variance for each cluster */
import org.apache.spark.ml.stat.Summarizer
val variances = predictions
.groupBy(col("prediction"))
.agg(Summarizer.variance(col("features")).alias("clustersVar"))
val vecToSeq = udf((v: org.apache.spark.ml.linalg.Vector) => v.toArray)
val assemblerVarianceVect = new VectorAssembler()
.setInputCols(Array("prediction", "clustersVar"))
.setOutputCol("vect")
val variancesMerged = assemblerVarianceVect
.transform(variances)
.select("vect")
// Prepare a list of columns to create from the Vector
val cols: Seq[String] = Seq(
"prediction", "startLonVar", "startLatVar", "tipScaledVar")
val exprs = cols
.zipWithIndex.map{ case (c, i) => col("_tmp").getItem(i).alias(c) }
variancesMerged.select(vecToSeq(col("vect")).alias("_tmp")).select(exprs:_*)
}La fonction computeVariances utilise le Summarizer de Spark MLlib pour calculer les variances des variables startLon, startLat et de tip qui sont dans un Vecteur dans la colonne feature. Le reste du code permet de dépaquetter les Vecteurs vers des colonnes de DataFrame de haut niveau pour faciliter l’accès à la variance.
Au lieu d’utiliser les variances directement, nous allons utiliser une mesure calculée à partir de la variance : l’écart type. L’écart type est la racine carrée de la variance. L’écart type donne autant d’information que la variance mais on la préfère à cette dernière car les unités correspondent aux variables originales. Ici la variance donne des degrés au carré, l’écart type des degrés. Remarquez que les variances ont du être calculées pour obtenir l’écart type, car le Summarizer ne donne pas directement l’écart type.
Génération de GeoJSON
Pour finir l’exemple de 10h du matin, nous allons visualiser les clusters sur une carte. Nous formatterons le centre des clusters et l’écart type en GeoJSON et les visualiserons sur la carte geojson.io. Nous utiliserons circe, une librairie Scala populaire pour encoder des objets en JSON avec le format GeoJSON. Ajoutez la dépendance circe dans build.sbt :
val circeVersion = "0.9.0"
libraryDependencies ++= Seq(
"io.circe" %% "circe-core",
"io.circe" %% "circe-generic",
"io.circe" %% "circe-parser"
).map(_ % circeVersion)Créez le fichier “src/main/scala/com/adaltas/taxistreaming/utils/ClustersGeoJSON.scala” dans le package com.adaltas.taxistreaming.utils. La fonction generateGeoJSON ci-dessous nous donne une sortie formatée en JSON à partir des clusters calculés précedemment.
package com.adaltas.taxistreaming.utils
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.functions.col
import io.circe._, io.circe.generic.auto._, io.circe.parser._, io.circe.syntax._
object ClustersGeoJSON {
def generateGeoJSON(centers: Array[org.apache.spark.ml.linalg.Vector],
variancesDF: DataFrame, originalTipMax: Double,
k: Int, silhouette: Double): io.circe.Json = {
//scan Cluster Centers to get max tip
var maxTip: Double = 0
for (vect <- centers) {
val tip = vect(2) //Array[Double]
if (tip > maxTip) maxTip = tip
}
//calc coeff to scale maxTip to max val of 255 for marker color coding
// maxTip*alfa = 255
val alfa = 255/maxTip
//calc coeff to rescalled maxTip back to originalTipMax
// maxTip*beta = originalTipMax
val beta = originalTipMax/maxTip
//GeoJSON structure
case class ClusterCenter(`type`: String, coordinates: Array[Double])
case class Properties(`marker-color`: String, title: String,
stddev: Double, fill: String,
`stroke-opacity`: Double, `fill-opacity`: Double)
case class Feature(`type`: String, properties: Properties,
geometry: ClusterCenter)
case class GjsonClusters(k: Int, silhouette: Double, `type`: String,
features: Array[Feature])
var clustersArray: Array[Feature] = Array()
// iterate clusters and build GeoJSON
for ((vect, group) <- centers.zipWithIndex) {
val lonLatVar = variancesDF
.select(col("startLonVar"),
col("startLatVar")).where(col("prediction") === group)
val radiusStdDev: Double = math.sqrt((
lonLatVar.first.getAs[Double](0) + lonLatVar.first.getAs[Double](1))/2)
val coordinates: Array[Double] = Array(vect(0), vect(1))
val tip = vect(2)
val colorTip: Int = 255-(tip*alfa).toInt // substracted to switch red and white
val colorTipString: String = f"$colorTip%02x" // Hex String
val color = "ff" + colorTipString + colorTipString // construct a full color
val dollarTip = beta*tip // rescaling
clustersArray = clustersArray :+ Feature(
`type`="Feature", properties=Properties(
`marker-color`=color, s"Tip of $dollarTip", radiusStdDev, fill=("#"+color), `stroke-opacity`=0.2,`fill-opacity`=0.2
), geometry=ClusterCenter(`type`="Point", coordinates))
}
val gclusters = GjsonClusters(k, silhouette, `type`="FeatureCollection", features=clustersArray)
gclusters.asJson
}
}Le centre géographique des clusters est encodé en tant que Point de geometry en format GeoJSON. L’écart type est utilisé comme rayon des cercles autour du centre des clusters. Les cercles sont plus difficiles à encoder car ils ne sont pas supportés par GeoJSON. Pour l’instant l’écart type est inclus dans les objets Properties de JSON. Plus tard, nous nous en servirons pour créer des polygones autour des clusters. La valeur tip du pourboire est aussi incluse dans les proriétés GeoJSON, elle controle l’intensité de la couleur.
La méthode generateGeoJSON produit un objet du type io.circe.Json. Utilisez cette méthode pour obtenir un fichier GeoJSON “clusters-mean.geojson” :
// add to main() in MainKmeans
import java.io.{File, PrintWriter}
val writer = new PrintWriter(new File("clusters-mean.geojson"))
writer.write(generateGeoJSON(centers, variancesDF,
originalTipMax, k, silhouette).toString())
writer.close()Dans Intellij IDEA, le projet est compilé et peut être exécuté sur Spark local pour créer le fichier “clusters-mean.geojson”. Sans IDEA, le fichier jar créé avec sbt-console échouera s’il est soumis avec spark-submit. Spark et circe dépendent tous deux de Shapeless. Malheureusement, il existe des différences entre Shapeless utilisé par Spark et Shapeless dépendant de circe. Pour résoudre ce problème, vous pouvez utiliser sbt-assembly et compiler un “gros jar” avec une dépendance masquée pour Spark ou circe. Cette tâche n’est pas simple. Si vous utilisez Intellij IDEA, vous pouvez compiler et exécuter le programme. La sortie GeoJSON n’est nécessaire que pour vérifier la validité des clusters obtenus. Il est donc acceptable d’utiliser IDEA ici et de ne pas utiliser la fonction generateGeoJSON pour la compilation du jar final.
Voici un apercu d’un fichier “clusters-mean.geojson” pour un seul cluster (les 11 autres ne sont pas montrés) :
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"properties": {
"marker-color": "ffdcdc",
"title": "Tip of 21.64375957666014",
"stddev": 0.009536803090126285,
"fill": "#ffdcdc",
"stroke-opacity": 0.2,
"fill-opacity": 0.2
},
"geometry": {
"type": "Point",
"coordinates": [
-74.00270215083792,
40.721537286182766
]
}
},
...more features...
]
}Dans le fichier “clusters-mean.geojson”, l’écart type d’un cluster est stddev dans l’objet properties de l’objet JSON dans le tableau features (voir l’exemple ci-dessus). Nous souhaitons utiliser cette valeur pour créer un polygone de points à partir de la circonférence du cluster. Pour cela, nous utiliserons un court script Python utilisant shapely.
#!/usr/bin/python3
import json
import geojson
import shapely
from shapely.geometry import shape, GeometryCollection
with open("clusters-mean.geojson") as f:
data = json.load(f)
features = data["features"]
for clusterInd in range(len(features)-1):
stddev = features[clusterInd]["properties"]["stddev"]
lon, lat = features[clusterInd]["geometry"]["coordinates"][0], features[clusterInd]["geometry"]["coordinates"][1]
center = shapely.geometry.point.Point(lon,lat)
circle = center.buffer(stddev) # Degrees Radius
poly = shapely.geometry.mapping(circle)
data["features"][clusterInd]["geometry"] = {"type": "GeometryCollection", "geometries": [features[clusterInd]["geometry"],poly]}
with open('clusters-mean-stddev.geojson', 'w') as f:
geojson.dump(data, f)Le script utilise le fichier “clusters-mean.geojson” et produit un fichier “clusters-mean-stddev.geojson”. Dans le nouveau fichier GeoJSON, les rayons sont utilisés pour créer des polygones en forme de cercles autour du centre des clusters. Voici un exemple de fichier “clusters-mean-stddev.geojson” :
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"properties": {
"marker-color": "ffdcdc",
"title": "Tip of 21.64375957666014",
"stddev": 0.009536803090126285,
"fill": "#ffdcdc",
"stroke-opacity": 0.2,
"fill-opacity": 0.2
},
"geometry": {
"type": "GeometryCollection",
"geometries": [
{
"type": "Point",
"coordinates": [
-74.00270215083792,
40.721537286182766
]
},
{
"type": "Polygon",
"coordinates": [
[
[
-73.99316534774779,
40.721537286182766
],
[
-73.99321127006135,
40.72060251601599
],
[
-73.99334859474502,
40.71967674819691
],
[
-73.99357599928705,
40.71876889837571
],
...more points...
]]
}
]
}
},
...more features...
]
}L’image ci-dessous montre les clusters pour l’intervalle 10h-11h. La visualisation a été obtenue en chargeant le fichier “clusters-mean-stddev.geojson” sur le site geojson.io.
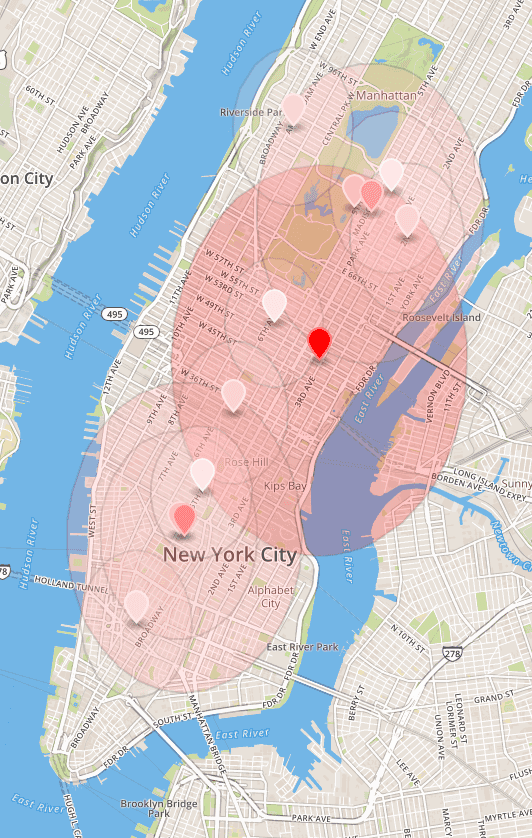
L’inclinaison verticale des cercles viens du fait que nous traitons la longitude et la latitude de la même manière que le rayon. Malheureusement, l’écart type est élevé. De grandes zones autour des marqueurs indiquent que les tours à pourboire élevé commencent souvent loin du centre du cluster à laquelle ils appartiennent. Néanmoins, les résultats du regroupement semblent satisfaisants car ils abordent la question de la recherche de zones à fort pourboire.
Certains ajustements pourraient être faits pour obtenir différents clusters et de meilleurs scores de Silhouette. Plus particulièrement, le nombre de clusters pourrait être modifié. De plus, l’impact du pourboire pourrait être contrôlé avec la méthode setMax() de MinMaxScaler. Diminuer la valeur maximale du purboire donnerait plus de poids à la latitude et à la longitude, diminuant ainsi la variance géographique (au prix d’une variance supérieure du pourboire dans un cluster).
Sauvegade des modèles K-means pour chaque heure
Calculons 24 modèles k-means indépendants, un pour chaque heure de la journée. A la place de 10h, nous faisons simplement une boucle et sauvons les modèles dans un répertoire “kmeans-models” :
val k = 12
val startingHour = 0
val endingHour = 24
for (h <- startingHour until endingHour) {
val pipeline = prepareKmeansPipeline(k)
val datasetHour = dfRidesManhattan.filter(col("startHour") === h)
val kmeansPipe = pipeline.fit(datasetHour) // obtain a PipelineModel
//save with MLWriter
kmeansPipe.write.overwrite.save(s"kmeans-models/clusters-at-$h")
}Remarquez que le code pour entraîner les modèles k-means n’appelle pas les fonctions computeVariances ou generateGeoJSON
Intégration du modèle ML dans le pipeline de streaming
Le pipeline de streaming développée dans les parties précédentes se décompose ainsi :
- La donnée est envoyée vers Kafka
- L’application Spark consomme les messages Kafka
- Les messages Kafka sont lus et convertis en DataFrame Spark
- Le jeu de données est sauvegardé sur HDFS
- Un processus Spark Structures Streaming nettoie, joint, augmente et aggrège la donnée
- Les résultats obtenus sont écrits sur HDFS et gardés en mémoire
- Les résultats sont exposés sur JDBC pour des requêtes de faible latences
Le pipeline existant va être modifié pour prendre en compte l’ajout de l’algorithme de Machine Learning. Nous allons principalement modifier le processus de streaming de Spark Structures Streaming.
Créez un fichier “MainConsoleClustering.scala” dans le package com.adaltas.taxistreaming. L’application Spark streaming doit avoir tout les modèles k-means chargés :
import org.apache.spark.ml.PipelineModel
import org.apache.spark.ml.clustering.KMeansModel
//read clusters in MainConsoleClustering
var hourlyClusters: Array[Array[org.apache.spark.ml.linalg.Vector]] = Array()
val startingHour = 0
val endingHour = 24
for (h <- startingHour until endingHour) {
val reloadedKmeansPipe: PipelineModel = PipelineModel
.load(s"kmeans-models/clusters-at-$h")
val centers: Array[org.apache.spark.ml.linalg.Vector] = reloadedKmeansPipe
.stages(2)
.asInstanceOf[KMeansModel]
.clusterCenters
hourlyClusters = hourlyClusters :+ centers
}Lorsqu’une course de Taxi arrive depuis le stream, l’heure de fin va servir à déterminer quel modèle de clustering utilise via la variable hourlyClusters. Cependant, hourlyClusters est un tableau de clusters (Vectors) - quel cluster est la meilleure recommendation pour un taxi libre ?
Pour déterminer le meilleur cluster pour un taxi, nous comparons les distances entre les centres des clusters et les coordonnées géographiques de la course qui s’est terminée. Définissons une fonction pour avoir la distance entre deux coordonnées :
def distBetween(lon1: Double, lat1: Double, lon2: Double, lat2: Double): Double = {
// Distance between (lon1, lat1) and (lon2, lat2) in meters
val earthRadius = 6371000 //meters
val dLon = Math.toRadians(lon2 - lon1)
val dLat = Math.toRadians(lat2 - lat1)
val a = Math.sin(dLat / 2) * Math.sin(dLat / 2) +
Math.cos(Math.toRadians(lat1)) * Math.cos(Math.toRadians(lat2)) *
Math.sin(dLon / 2) * Math.sin(dLon / 2)
val c = 2 * Math.atan2(Math.sqrt(a), Math.sqrt(1 - a))
val dist = (earthRadius * c).toFloat
dist
}Next, let’s put the distBetween function to use inside a UDF function picking up an attractive cluster for the Taxi driver :
val RecommendedLonLat = udf { (h: Int, lon: Double, lat: Double) => {
val clustersArray = hourlyClusters(h)
var closestCluster = clustersArray(0) // Init to 1st cluster
clustersArray foreach { case (vect) =>
val clusterLon = vect(0)
val clusterLat = vect(1)
val clusterTip = vect(2)
val dist = distBetween(clusterLon, clusterLat, lon, lat)
val currentBestDist = distBetween(closestCluster(0),closestCluster(1),lon,lat)
if ((dist < currentBestDist && (clusterTip > closestCluster(2))) {
closestCluster = vect
}
}
Seq(closestCluster(0), closestCluster(1))
}: Seq[Double] }Dans la fonction RecommendedLonLat, tous les clusters d’un segment horaire d’une heure sont analysés afin de faire correspondre le point d’entrée du cluster le plus proche. Pour établir qu’un cluster donné est meilleur, non seulement il doit être plus proche que le meilleur cluster actuel, mais il doit également donner un pourboire plus élevé. Enfin, les coordonnées géographiques des clusters les plus appropriés sont indiquées en tant que longitude et latitude recommandées.
Le code restant correspond au pipeline existant développé dans les parties précédentes de la série. Il copie principalement le contenu du fichier “MainConsole.scala”.
import com.adaltas.taxistreaming.processing.TaxiProcessing
import com.adaltas.taxistreaming.utils.{ParseKafkaMessage, StreamingDataFrameWriter}
val taxiRidesSchema = StructType(Array(
StructField("rideId", LongType), StructField("isStart", StringType),
StructField("endTime", TimestampType), StructField("startTime", TimestampType),
StructField("startLon", FloatType), StructField("startLat", FloatType),
StructField("endLon", FloatType), StructField("endLat", FloatType),
StructField("passengerCnt", ShortType), StructField("taxiId", LongType),
StructField("driverId", LongType)))
val taxiFaresSchema = StructType(Seq(
StructField("rideId", LongType), StructField("taxiId", LongType),
StructField("driverId", LongType), StructField("startTime", TimestampType),
StructField("paymentType", StringType), StructField("tip", FloatType),
StructField("tolls", FloatType), StructField("totalFare", FloatType)))
// Adjust kafka "master02.cluster:6667" <-> "localhost:9997" (hadoop setup vs local)
var sdfRides = spark.readStream.
format("kafka").
option("kafka.bootstrap.servers", "master02.cluster:6667").
option("subscribe", "taxirides").
option("startingOffsets", "latest").
load().
selectExpr("CAST(value AS STRING)")
var sdfFares= spark.readStream.
format("kafka").
option("kafka.bootstrap.servers", "master02.cluster:6667").
option("subscribe", "taxifares").
option("startingOffsets", "latest").
load().
selectExpr("CAST(value AS STRING)")
sdfRides = ParseKafkaMessage.parseDataFromKafkaMessage(sdfRides, taxiRidesSchema)
sdfFares= ParseKafkaMessage.parseDataFromKafkaMessage(sdfFares, taxiFaresSchema)
sdfRides = TaxiProcessing.cleanRidesOutsideNYC(sdfRides)
sdfRides = TaxiProcessing.removeUnfinishedRides(sdfRides)
val sdf = sdfRides.withColumn("hour", hour(col("endTime")))Finallement, nous pouvons intégrer un pipeline de straming avec les modèles k-means via la fonction UDF RecommendedLonLat et afficher les résultats.
val sdfRes = sdf
.withColumn("RecommendedLonLat", RecommendedLonLat(
col("hour"), col("endLon"), col("endLat")))
.drop(col("passengerCnt"))
// Write streaming results in console
StreamingDataFrameWriter.StreamingDataFrameConsoleWriter(sdfRes, "TipsInConsole").awaitTermination()Le fichier jar de l’application Scala Spark peut être compilé avec sbt-console et soumis avec spark-submit. En cas d’exécution sur le cluster Hadoop de la partie 2 de la série, soumettez-le avec :
spark-submit \
--master yarn --deploy-mode client \
--class com.adaltas.taxistreaming.MainConsoleClustering \
--num-executors 2 --executor-cores 1 \
--executor-memory 5g --driver-memory 4g \
--packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.3.0 \
/vagrant/taxi-streaming-scala_2.11-0.1.0-SNAPSHOT.jarSinon, remplacez master par local et faites correspondre les ressources de votre machine.
Après le lancement des flux Kafka (comme expliqué dans les parties 1 et 2 de la série), les résultats finaux sont écrits sur la console :
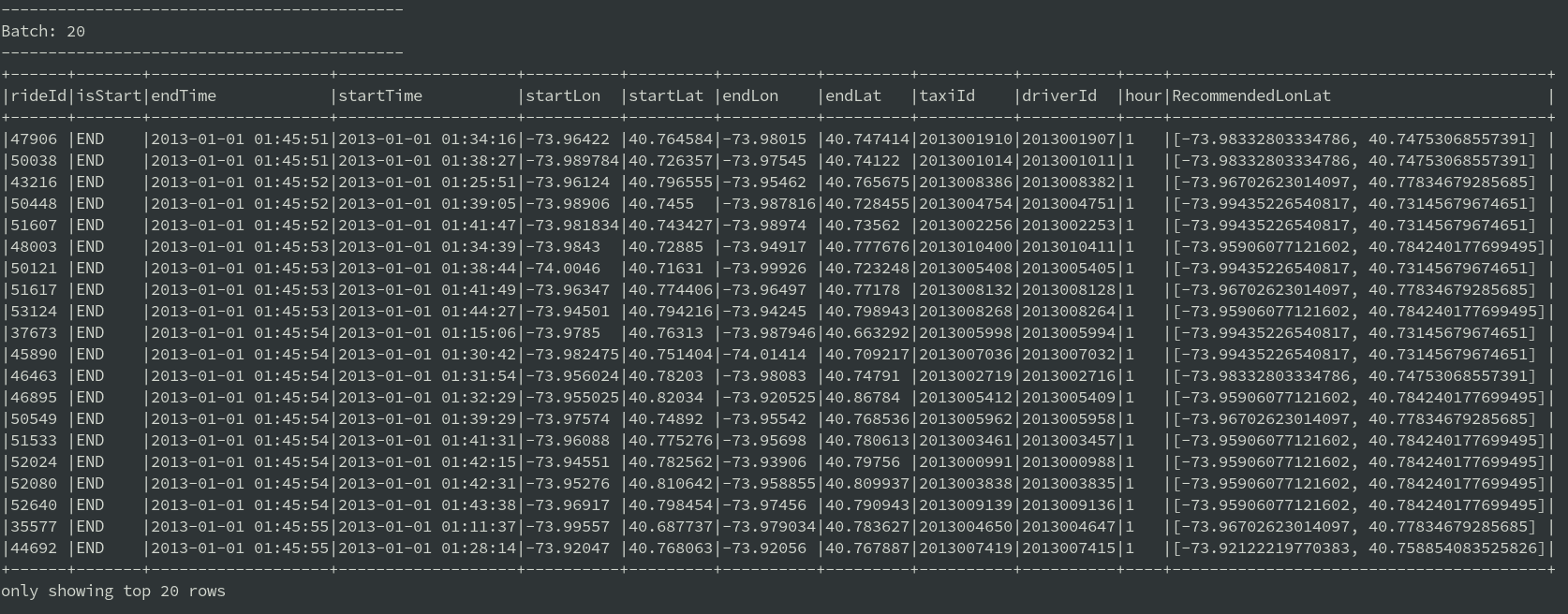
Notez que les mises à jour périodiques des modèles k-means devraient être effectuées sur un cluster Hadoop. Cela pourrait être réalisé e.g. avec Apache Airflow en soumettant une tâche Spark avec l’application MainKmeans. Par exemple, chaque nuit, les clusters peuvent être recalculés en fonction des données de la semaine précedente.
Conclusions
La majeure partie du travail d’un projet ML concerne la préparation des données, le prétraitement, la compréhension de l’algorithme et l’évaluation. Cet article reflète cela, car beaucoup de travail a du être fait en plus d’adapter simplement l’algorithme k-means de Spark aux données du jeu de données.
Le déploiement d’un modèle ML dans un scénario temps réel est généralement difficile, mais comme le montre cet article, cela peut être simplifié. L’algorithme k-means, bien qu’entraîné sur des données statiques, a été intégré avec succès dans un pipeline de streaming Spark.
