


Mise en production d'un modèle de Machine Learning

30 sept. 2019
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
“Le Machine Learning en entreprise nécessite une vision globale […] du point de vue de l’ingénierie et de la plateforme de données”, a expliqué Justin Norman lors de son intervention sur le déploiement de modèles d’apprentissage automatique (en anglais Machine Learning ou ML) lors du DataWorks de Barcelone de cette année. En effet, un système d’apprentissage automatique industriel fait partie d’une vaste infrastructure de données, ce qui peut rendre un flux de bout en bout particulièrement complexe. Les défis liés au développement, au déploiement et à la maintenance des systèmes de Machine Learning ne doivent pas être négligés au profit de la recherche des meilleurs algorithmes ML.
L’apprentissage automatique ne vise pas nécessairement à remplacer la prise de décision humaine, il consiste principalement à aider l’homme à prendre des décisions complexes fondées sur le jugement.
La conférence à laquelle j’ai assisté, Déploiement de modèles d’apprentissage machine : stratégie à mise en œuvre, a été donnée par les experts de Cloudera, Justin Norman et Sagar Kewalramani. Ils ont fait une présentation sur les défis rencontrés lors de la création d’une pipeline de ML de bout en bout, en se concentrant sur la mise en production.
La pyramide des besoins de l’IA
De plus en plus d’entreprises utilisent le Machine Learning et l’IA pour améliorer leurs services et devancer leurs concurrents. Malheureusement, de nombreuses entreprises se lance dans l’IA sans une plateforme de données appropriée, ni une compréhension des modèles ML utilisés. Plusieurs besoins techniques liés au Big Data et à la Data Science doivent être satisfaits en premier lieu :
- Infrastructure Big Data pour collecter, ingérer, stocker, nettoyer et déplacer des données entre différentes parties du système communément de la responsabilité des Data Engineers
- Stratégies d’analyse permettant d’explorer, de visualiser, de transformer et de prétraiter les données utiles
- Un framework pour expérimenter des algorithmes, y collaborer et les déployer, tout en gardant une trace de tous les paramètres, de la précision et des performances des modèles.
- Base établie avec les algorithmes Data Science les plus simples
En dehors de ceux-ci, vous devez garder à l’esprit certaines caractéristiques importantes de la plateforme ML :
- Une intégration profonde avec les processus métier
- Livraison continue (CI/CD) comme n’importe quel code classique
- Une boucle fermé de feedback
Dans la présentation, ces besoins étaient représentés par une pyramide, modellée selon la hiérarchie des besoins de Maslow. Les points de la liste ci-dessus sont considérés comme des niveaux d’une pyramide, en partant de la base de la pyramide pour le premier point. Ce concept, également connu sous le nom de “Hiérarchie des besoins de l’IA ”, permet de comprendre un point important :
Il n’y a pas d’intelligence artificielle (qui s’auto entretient) sans une infrastructure de base pour les calculs (nourriture, eau, chaleur). Avant de pouvoir utiliser avec succès les algorithmes d’apprentissage par la machine, vous devez être en mesure de raisonner sur le passé et de faire des analyses de base sur l’avenir. Vous ne pouvez pas vous attendre à ce qu’un réseau de neurones donne d’excellents résultats si l’ensemble de données utilisées est mal compris et préparé.
Le fait de cibler souvent les efforts sur les aspects fondamentaux du système peut améliorer davantage la précision des prévisions que l’ajustement des algorithmes de prévision actuel. Par exemple, travailler sur la représentation des données d’entrée peut donner de meilleurs résultats que le réglage du modèle ML. Lorsque tous les besoins d’ingénierie de base sont satisfaits et que la précision n’est pas suffisante, à ce moment là seulement des efforts doivent être déployés pour utiliser des algorithmes plus complexes.
Dette technique cachée dans les systèmes ML
L’importance des travaux de génie logiciel au sein d’un système d’entreprise de Machine Learning est évidente et illustrée dans le document de Google intitulé “Dette technique cachée dans les systèmes d’apprentissage automatique” (pdf). Les auteurs y font valoir que seule une petite fraction des architecture de Machine Learning sont composés du code ML. Le code ML peut même représenter moins de 10% de l’ensemble du système ML.
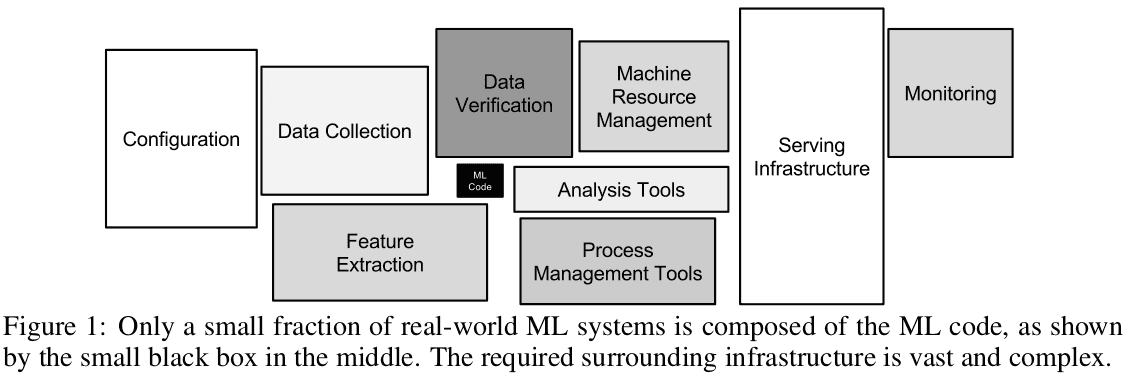
Bien que le code de Machine Learning commande toutes les décisions, il n’est presque pas pertinent du point de vue du système logiciel dans son ensemble, qui doit être développé pour résoudre un problème pour un utilisateur final. La minuscule fraction de ML fournissant des décisions est importante, mais il existe de nombreux autres composants importants dans le système. Consacrer du temps à la conception de l’architecture d’un système, au durcissement de modèle, au déploiement, à la surveillance, etc. est au moins aussi important que de passer du temps à l’amélioration de l’algoritme.
L’importance d’un workflow ML bout en bout
Un workflow ML doit traiter de tous les niveaux de la pyramide afin de ne pas engager une dette technique cachée. Pour tenter de résumer la première moitié de l’exposé, trois défis principaux sont identifiable dans un workflow de bout en bout : la complexité, l’échelle et l’expérimentation. Les défis ne sont pas exclusifs, ils sont tous liés les uns aux autres.
Complexité
Le workflow d’enterprise de Machine Learning nécessite :
- Infrastructure de données et de nombreux traitements pour fournir des données préparées et consommables par les modèles ML
- Construire des modèles ML à travers de nombreuses expériences
- Beaucoup d’efforts à fournir pour déployer des modèles ML et les surveiller.
Trois compétences distinctes peuvent être associés aux points de la liste ci-dessus : Data Engineer, Data Scientist et DevOps Engineer, respectivement. Ils ont des points de vue distincts sur le projet, des attentes différentes sur les résultats et utilisent différents outils. Des exemples de technologies présentes dans les systèmes ML sont Hadoop, Kafka, Spark, Tensorflow, xgboost, Docker, et Kubernetes. Ces outils doivent être intégrés et les mécanismes permettant de déplacer en toute sécurité des données entre eux doivent être mis en œuvre.
Les différences dans le raisonnement des personnes et le comportement des outils peuvent conduire à des problèmes qui peuvent saper le projet dans son ensemble. Par exemple, les Data Scientists ont tendance à produire du code à l’aide de notebooks et de packages qui ne peuvent pas être mis en parallèle et ne sont pas prêts pour la production, car ils ne peuvent pas être déployés sur des systèmes distribués. Un notebook est comme une spécification (recette) pour le modèle de sortie souhaité (gâteau). Comme les data ingénieurs et DevOps ne sont pas des experts en datascience, ils pourraient mal comprendre la recette et un gâteau différent est cuit. Un modèle ML en production risque de ne pas correspondre au produit attendu et de ne pas satisfaire le cas d’utilisation, simplement en raison d’interprétations erronées entre les équipes. La complexité supplémentaire découle du fait que chaque cas d’utilisation nécessite un modèle ML spécifique, une préparation des données différente et des considérations spéciales pour le déploiement.
Échelle
Le passage à l’échelle est une caractéristique importante de l’apprentissage industriel. Une solution ML peut devoir évoluer pour servir des millions de clients, ce qui implique de grands ensembles de données. Il faut beaucoup de puissance de calcul pour prétraiter ces grands ensembles de données et les utiliser pour l’entrainement de modèles ML. Les technologies et techniques Big Data sont généralement utilisées pour fournir cette capacité informatique par le biais du calcul parallèle dans un environnement de cluster sécurisé. Le déploiement de modèles ML entrainés en production à grande échelle implique également le besoin de stratégies et d’outils DevOps.
Expérimentation
La création de modèles ML est un processus progressif impliquant de nombreuses expériences. Il faut donner à un Data Scientist le moyen de conserver les informations de chaque entrainement du modèle : paramètres, bibliothèques utilisées, versions, etc.
Les outils et le système de CI doivent être suffisamment robustes pour permettre une flexibilité entre différents modèles de ML (chacun ayant des dépendances spécifiques) et une compatibilité pour mettre rapidement à l’échelle, promouvoir et rétrograder les modèles de ML en production. Ensuite, de nombreux modèles ML doivent être surveillés et gérés.
Stratégies et cycle de vie des workflows ML de bout en bout
Un produit doté de fonctionnalités ML doit traiter la pipeline ML comme faisant partie de l’infrastructure de données. De même, la sortie ML doit être considérée comme un sous-ensemble des résultats obtenus dans le système plus large. Sans intégration, la mise en production des modèles ML prendrait trop de temps pour rester compétitive.
Trois parties d’un workflow ML seront abordées :
- Entrainement versionnés et reproductibles des modèles ML
- Déploiement des modèles ML
- Gestion des modèles ML en production
Remarque importante, quel que soit l’outil utilisé pour développer des modèles ML, il est préférable de limiter au maximum le déplacement des données. Travaillez sur les données là où elles se trouvent. Au lieu d’envoyer des données sur plusieurs plates-formes, sélectionnez une solution distribuée évolutive unique, telle que celle située dans l’environnement on-premise ou dans l’environnement cloud.
il est préférable d’éviter de déplacer des données, comme dans l’environnement on premise ou dans le cloud où les données résident.
Formation sur modèle ML reproduite et reproductible
Les modèles d’apprentissage sont créés dans un processus itératif. Un modèle final de ML mis en production est obtenu après de nombreuses essaies, dans lesquelles les paramètres et les hyperparamètres des modèles sont progressivement ajustés de manière empirique.
Malheureusement, suivre ces essaies n’est pas une pratique courante et les versions intermédiaires menant au modèle final ont tendance à s’égarer. Un workflow ML devrait fournir un moyen de suivre et de gérer facilement les modèles ML émergents.
Un modèle final doit être précédé d’une série d’instantanés des méta-informations des modèles précédents, telles que qui et quand créer le modèle, le code du modèle, les configurations de dépendances, les paramètres, les commentaires, etc.
Two examples of projects specifically addressing versioned, reproducible ML model training are :
Voici deux exemples de projets traitant spécifiquement du versionnement et du caratère reproductive des entrainement de modèles :
- DVC - Système de contrôle de version en source libre pour projets d’apprentissage machine
- Comet - Solution propriétaire
Déploiement de modèle ML
Le déploiement doit être rapide et adapté aux besoins de l’entreprise. Les modèles déployés doivent être surveillés et faciles à gérer. Trois modèles de déploiement principaux peuvent être utilisés, en fonction du cas d’utilisation de l’entreprise :
- Déploiement par lots - Le modèle ML est utilisé hors ligne. Par exemple, des rapports quotidiens avec des prévisions sont générés pour assister l’équipe managériale à la prise de décisions
- Déploiement en temps réel - Le modèle ML est utilisé pour automatiser les décisions urgentes. Par exemple dans les systèmes de recommandation et dans les systèmes de détection de fraude
- Déploiement Edge : le modèle ML est utilisé dans des systèmes à délai critique où la décision doit être prise instantanément. Les deux types de déploiement précédents ont une unité centrale exécutant le modèle ML, tandis que les déploiements périphériques ont le modèle exécuté directement sur le système externe. Par exemple, dans un drone autonome
Le modèle ML peut être déployé sous plusieurs formats, par exemple en tant qu’application Java / C ++ / Python, Spark, ou en tant qu’application API REST. Le déploiement du modèle en tant qu’application est plus coûteux et plus lent que le déploiement du modèle basé sur une API, mais offre plus de fiabilité, une vitesse supérieure et une sécurité accrue. Le format de déploiement reste une décision largement dépendante du cas d’utilisation.
Les conditions de cas d’utilisation déterminent le type de déploiement applicable, ce qui conditionne à son tour le format de déploiement et les outils utilisés. Par exemple, dans le scénario de déploiement par lots, une tâche Scala Spark exécuté sur un cluster Hadoop peut être choisi. Dans un scénario en temps réel, un moteur de traitement de flux tel que Flink ou Kafka Stream est nécessaire. Enfin, le déploiement à la périphérie peut nécessiter des réécritures vers C / C ++ et des architectures de processeur spécifiques.
Gestion de modèles ML en production
De même que pour garder une trace des expériences dans la phase de formation, les modèles de ML doivent être suivis en production.
- Lors du déploiement, toutes les métadonnées doivent être collectées : qui et quand le modèle est déployé, quel est le modèle, quelle version, quels paramètres, etc.
- Les performances des modèles déployés doivent être surveillées et diverses mesures collectées telles que la précision, le score F1 (qui mesure la précision d’un test), les indicateurs de performance clé d’activité (KPIs), l’utilisation des ressources, le temps de réponse, etc. Un modèle dégradant doit être identifié et ses mesures de performance analysées. Quelle métrique a dérivé, combien, quand, etc.
Le suivi des modèles ML en production permet de réévaluer les modèles et de réexaminer l’algorithme d’apprentissage sélectionné. En outre, on pourrait déployer quelques variantes d’un modèle et les comparer. La comparaison doit être faite sur la base des performances, de la signification statistique et de la signification pratique pour le cas d’utilisation.
Il existe des outils qui ciblent spécifiquement la gestion de modèles ML (par exemple, Datmo), mais il s’agit généralement d’une fonctionnalité de l’ensemble de la plateforme Machine Learning.
Containerization
Comme indiqué précédemment, chaque format de déploiement de modèles correspond à un cas d’utilisation spécifique et comporte de nombreuses exigences spécifiques : langage, infrastructure, bibliothèques, packages. Souvent, ces dépendances doivent avoir une version spécifique. Cela crée une multitude de logiciels prérequis, souvent contradictoires. L’installation de logiciels différents sur les nœuds du cluster peut constituer un obstacle en raison des différences de version entre les dépendances et d’autres conflits logiciels. La containerization peut être une solution. Des technologies comme Docker permettent d’héberger des modèles ML dans un environnement isolé contenant déjà tous les logiciels nécessaires. Différentes versions du code du projet peuvent être regroupées dans plusieurs conteneurs Docker avec différentes images Docker.
Kubernetes est un excellent outil pour déployer et gérer des applications conteneurisées évolutives. Il est couramment utilisé pour l’orchestration des conteneurs Docker. Alternativement, Hadoop 3 peut orchestrer les conteneurs Docker.
Plateformes d’apprentissage automatique
Il y a quelques années à peine, il n’existait aucun outil pour construire des systèmes de Machine Learning à grande échelle. Les grandes entreprises ont dû créer leurs plates-formes, telles que Michelangelo, la plateforme d’apprentissage automatique d’Uber. D’une certaine manière, ces plates-formes propriétaires ont créé des normes pour les workflows ML, qui ont ensuite été adoptées dans l’écosystème open source.
De nos jours, deux plates-formes / kits d’apprentissage automatique sont disponibles pour faciliter les workflow ML. L’option la plus notable qui a été présentée au cours de la conférence est Cloudera Data Science Workbench (CDSW), qui s’intègre aux populaires plateformes Big Data CDH et HDP.
Une option intéressante pour les projets ML sur un cluster Hadoop est le projet Apache Hadoop Submarine que j’ai découverte au cours d’une autre conférence, Projet Hadoop {Submarine} : Exécuter des charges d’apprentissage approfondies sur YARN, donnée par Sunil Govindan et Zhankun Tang. Submarine permet de calculer des applications Tensorflow non modifiées sur un cluster Hadoop. Submarine exploite Hadoop YARN pour l’orchestration des charges de travail ML et Hadoop HDFS pour collecter et stocker des données dans le système. Cette solution est possible car Hadoop 3 prend en charge la planification et l’isolation de GPU sur YARN, ainsi que en tant que conteneurs Docker.
MLflow semble être un choix prometteur. Deux autres alternatives sont Polyaxon et Kubeflow qui conviennent à une utilisation avec Kubernetes.
Conclusions
L’intelligence artificielle et l’apprentissage automatique traversent la phase d’industrialisation. Le passage à l’échelle, la complexité et le caractère expérimental de la création de modèles ML constituent les principaux défis d’un workflow ML en entreprise. De nouveaux outils et plates-formes sont en cours de développement pour développer, former et déployer des modèles ML dans l’industrie.
