


Insérer des lignes dans une table BigQuery avec des colonnes complexes

22 nov. 2019
- Catégories
- Cloud computing
- Data Engineering
- Tags
- GCP
- BigQuery
- Schéma
- SQL [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Le service BigQuery de Google Cloud est une solution data warehouse conçue pour traiter d’énormes volumes de données avec un certain nombre de fonctionnalités disponibles. Parmi toutes celles-ci, nous allons nous focaliser sur le support du type Struct et des colonnes répétées.
Les colonnes complexes
Les colonnes de type Struct - que nous appellerons colonnes complexes - permettent de définir le contenu d’une colonne comme une structure ayant plusieurs propriétés typées (STRUCT).
Par exemple, disons que nous voulons stocker les informations suivantes concernant une personne :
- Nom
- Date de naissance
- Addresse
- Rue
- Ville
- Code postal
- Pays
Dans un système SQL traditionnel, nous pourrions faire une deuxième table pour conserver les adresses et avoir une clé étrangère sur la ligne de votre personne ou bien aplatir l’objet adresse dans la ligne de la personne. Un certain nombre d’autres possibilités feraient l’affaire.
Grâce à l’utilisation des colonnes complexes dans BigQuery, il est possible de garder l’adresse en tant qu’objet. Nous ajoutons seulement une colonne à notre schéma sans avoir à utiliser de jointure pour obtenir l’information.
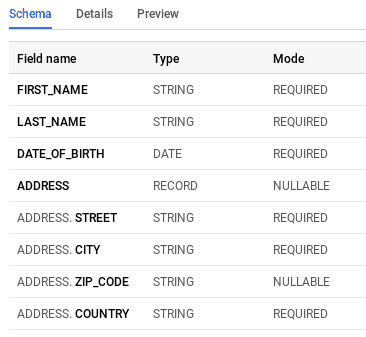
Pour définir le schéma d’une colonne complexe, il faut paramétrer le type sur RECORD et ajouter la propriété fields qui est un ensemble de champs. Voici à quoi ressemblerait le schéma de notre table au format JSON :
[
{
"name": "FIRST_NAME",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "LAST_NAME",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "DATE_OF_BIRTH",
"type": "DATE",
"mode": "REQUIRED"
},
{
"name": "ADDRESS",
"type": "RECORD",
"mode": "NULLABLE",
"fields": [
{
"name": "STREET",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "CITY",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "ZIP_CODE",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "COUNTRY",
"type": "STRING",
"mode": "REQUIRED"
}
]
}
]Lors de la lecture du schéma dans l’UI de BigQuery, la colonne complexe apparaît d’abord avec son type et son mode défini (record, nullable) et sera ensuite répétée pour chaque champ sous la forme colonne.champ avec le type et mode du champ.
Passons à l’insertion des données. On retrouve beaucoup de documentation de Google sur la façon d’insérer des lignes mais pas via la méthode SQL INSERT INTO (a la date d’écriture de cet article). Le principe est simple, vous définissez les valeurs complexes entres parenthèses (comme un tuple). Cependant, afin de ne pas avoir de problèmes avec le type des champs, vous devriez spécifier les colonnes ciblées et vous pourriez avoir à caster les valeurs si vous insérez NULL. Par exemple :
INSERT INTO `project.dataset.person_table` (FIRST_NAME, LAST_NAME, DATE_OF_BIRTH, ADDRESS)
VALUES
("Jeff", "Smith", "1980-10-10", ("#1 7th Avenue", "New York", "100011", "United States")),
("Charlotte", "Lalande", "1990-01-01", ("3Bis Avenue des Champs Élysées", "Paris", STRING(NULL), "France"))Pour afficher les colonnes complexes, l’UI de BigQuery appliquera la même logique que pour le schéma : chaque champ de la colonne complexe apparaît sous la forme colonne.champ.

Les colonnes répétées
BigQuery permet également de définir des colonnes répétées, ce qui revient à définir le type sur ARRAY.
Mettons à jour notre tableau précédent pour appliquer les changements suivants :
- Une personne peut avoir des seconds prénoms.
- Une personne peut avoir des adresses secondaires, ce sera une colonne répétée d’addresses.
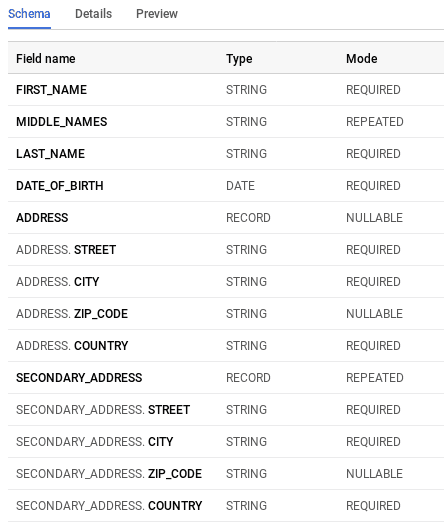
Voici notre nouveau schéma :
[
{
"name": "FIRST_NAME",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "MIDDLE_NAMES",
"type": "STRING",
"mode": "REPEATED"
},
{
"name": "LAST_NAME",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "DATE_OF_BIRTH",
"type": "DATE",
"mode": "REQUIRED"
},
{
"name": "ADDRESS",
"type": "RECORD",
"mode": "NULLABLE",
"fields": [
{
"name": "STREET",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "CITY",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "ZIP_CODE",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "COUNTRY",
"type": "STRING",
"mode": "REQUIRED"
}
]
},
{
"name": "SECONDARY_ADDRESS",
"type": "RECORD",
"mode": "REPEATED",
"fields": [
{
"name": "STREET",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "CITY",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "ZIP_CODE",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "COUNTRY",
"type": "STRING",
"mode": "REQUIRED"
}
]
}
]L’interface BigQuery les affichera dans le schéma comme n’importe quelle autre colonne sauf que son mode est REPEATED.
Pour insérer dans un champ répété, vous devez définir la valeur sous la forme [VALUE1, VALUE2, ....] :
INSERT INTO `project.dataset.person_table` (FIRST_NAME, MIDDLE_NAMES, LAST_NAME, DATE_OF_BIRTH, ADDRESS, SECONDARY_ADDRESS)
VALUES
("Jeff", ["Pierre", "Jack"], "Smith", "1980-10-10", ("#1 7th Avenue", "New York", "100011", "United States"), [("3Bis Avenue des Champs Élysées", "Paris", "75008", "France")]),
("Charlotte", ["Marie"], "Lalande", "1990-01-01", ("3Bis Avenue des Champs Élysées", "Paris", STRING(NULL), "France"), NULL)Pour afficher les champs répétés, l’interface utilisateur ajoutera de nouvelles lignes (visuelles) à la même ligne (SQL), chaque nouvelle cellule contenant une valeur du champ répété. Les cellules supplémentaires des champs non répétés sont grisés.

Notez que les champs répétés ne sont pas optimisés pour être requêtées. Si vous cherchez à filter une donnée d’un champ répété dans votre table, il est préférable de dupliquer cette donnée sur une colonne spécifique ou simplement ne pas la mettre dans le champ répété.
Félicitations, vous savez désormais comment insérer manuellement des données dans des colonnes complexes et répétées !
