


Hadoop Ozone partie 3: Stratégie de réplication avancée avec les Copyset

3 déc. 2019
- Catégories
- Infrastructure
- Tags
- HDFS
- Ozone
- Cluster
- Kubernetes
- Noeud [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Hadoop Ozone propose de configurer le type de réplication à chaque écriture effectué sur le cluster. Actuellement seules HDFS et Ratis sont disponibles mais des stratégies plus avancées sont réalisables. Dans cette dernière partie nous discuterons des défauts des stratégies de réplications classiques et présenterons la replication Copyset.
Cette article est la troisième et dernière partie d’une série de trois articles présentant Ozone, démontrant son usage et proposant une stratégie de réplication avancée basée sur les Copyset.
Réplication aléatoire dans HDFS
Dans HDFS chaque fichier est découpé en bloc. Chaque bloc est répliqué aléatoirement sur trois Datanodes. La seule règle appliquée est que ces trois datanodes ne doivent pas être dans le même rack. Il s’agit de la “réplication aléatoire”.
Les avantages de cette réplication sont que :
- Elle est facile à comprendre à développer.
- Simple à maintenir (ajouter ou retirer des Datanodes est extrêmement simple)
- La charge est distribuée équitablement entre les noeuds
A présent parlons de perte de données. Sachant que les blocs sont répartis équitablement entre les noeuds, perdre 3 noeuds de différents racks va obligatoirement entraîner de la perte de données, si le cluster contient au moins 3 fois plus de blocks que de datanodes.
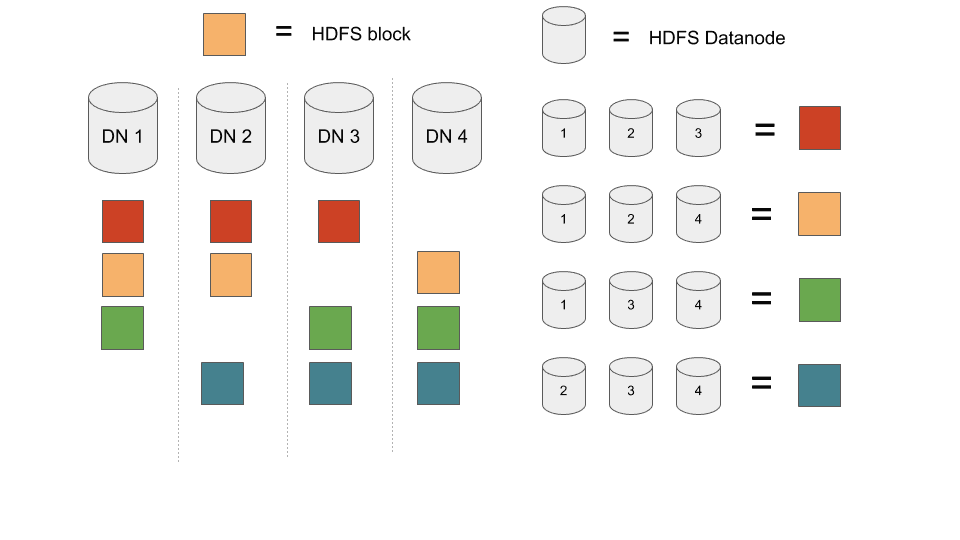
Avec cette distribution, le charge est parfaitement équilibrée avec 3 blocs de données par noeud. Dans le cas où 3 noeuds font défaut, il y aura de la perte de données puisque chaque combinaison de trois noeuds contient un ensemble de bloc.
Il est très peu probable que 3 noeuds ou trois disques fassent défaut sur un petit cluster, mais la probabilité croît avec la croissance du cluster. Facebook ou Yahoo ont déjà rencontré des pertes d’alimentation complète d’un datacenter. Au redémarrage du cluster il est tout à fait possible qu’un pourcent du parc ne redémarre pas. Il est facile de calculer que sur un cluster de 300 noeuds où 1% est égal à 3 noeuds : il y aura de la perte de données.
La récupération n’est vraiment pas bon marché avec des frais fixes très élevés :
- Recalculer toutes les données perdues
- Recupérer les données depuis d’autre sources ou en lisant les disques endommagés
Ces opérations sont très chères et ne sont pas proportionnels à la quantité de données perdues dans l’incident.
C’est le principal problème que tente de résoudre la réplication CopySet : réduire la fréquence des pertes de données, au prix de plus de données perdues par incident.
Replication Copyset
Le principe de le réplication CopySet peut être facilement compris avec un cluster de 6 noeuds et un facteur de réplication à 3.
Avec la réplication HDFS classique, un ensemble de blocs peut se trouver sur 3 noeuds parmi 6 : 20 ensembles. Une fois que le cluster contient 21 blocs ou plus, des donnés seront obligatoirement perdues si 3 de ces noeuds défaillent.
Avec copyset : nous fixons 2 ensembles uniquement (1,2,3) et (4,5,6)
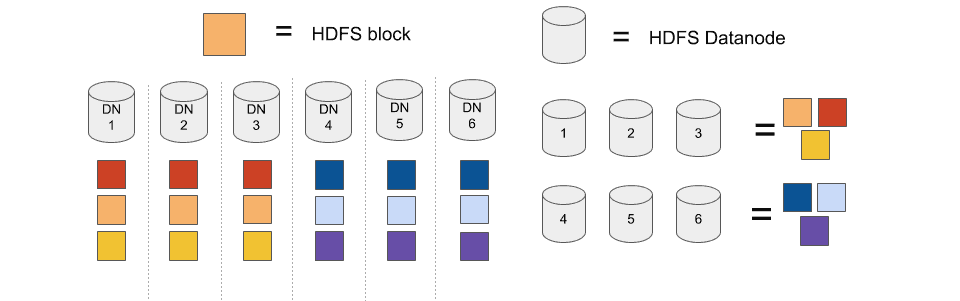
Dans cette configuration, les blocs ne peuvent être répliquées que sur deux ensembles. Des données seront perdues si et seulement si nous perdons tous les noeuds d’un de ces ensemble.
Un peu de maths : sur un cluster de 300 noeuds nous perdons 1% du parc (soit 3 noeuds), cela signifie que nous perdons un ensemble.
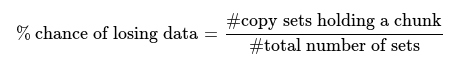
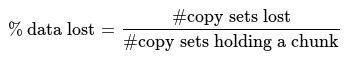
Avec la réplication aléatoire, chaque ensemble contient au moins un fragment, la probabilité de pertes de données est donc de 100%. Si on prend 3 noeuds parmi 300, on dispose de 4455100 ensembles. Nous perdrons ainsi en moyenne 1/4455100=0.00002% de données.
Sur le cluster utilisant copyset, nous n’écrirons que sur 100 différents ensembles. Perdre un de ces ensembles signifie perdre 1% de données. Mais perdre un de ces ensembles est très peu probable car la probabilité est de 100/4455100=0.002%
| % chance de perdre des données | % de données perdues | |
|---|---|---|
| Replication aléatoire | 100 | 0.00002 |
| Rréplication Copyset | 0.002 | 1 |
Conclusion
La réplication copyset est une affaire de compromis. Êtes-vous prêt à perdre des données moins souvent, au prix de plus de données perdues à chaque incident ?
Ces interrogations doivent être répondues sur une infrastructure très large stockant des donnés critiques. Connaître les défauts de la stratégie de réplication choisie est fondamental.
Ozone offrant la possibilité de définir des stratégies de réplications avancées est très prometteur.
