


Espace de stockage et temps de génération des formats de fichiers

22 mars 2021
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Le choix d’un format de fichier approprié est essentiel, que les données soient en transit ou soient stockées. Chaque format de fichier a ses avantages et ses inconvénients. Nous les avons couverts dans un article précédent présentant et comparant les formats de fichiers les plus populaires en Big data. Dans un article complémentaire, nous comparerons leurs performances selon plusieurs scénarios. La compression utilisée pour un format donné a un impact important sur les performances de la requête. Cet article prépare les tableaux nécessaires à l’article suivant et compare les algorithmes de compression en termes d’espace de stockage et de temps de génération. Il nous aidera également à sélectionner les algorithmes de compression les plus appropriés pour chaque format.
Choix de la base de données
Apache Hive est un logiciel de stockage de données intégré sur Hadoop. Il est utilisé pour gérer de grands datasets en utilisant la syntaxe SQL. Nous l’avons choisi pour les raisons suivantes :
- Hive est conçu pour des tâches analytiques (OLAP).
- Il permet de tirer pleinement parti du traitement distribué des données.
- Il prend en charge plusieurs types de formats de fichiers.
- Dans certaines circonstances, l’utilisation d’un langage optimisé comme HiveQL présente l’avantage de minimiser les erreurs et permet d’éventuelles optimisations du moteur. HiveQL étant basé sur SQL, c’est un langage déclaratif qui rend la définition du modèle et la déclaration de requêtes de façon simple.
Note, nous aurions tout autant pu utiliser un autre moteur de traitement comme Apache Spark.
Caractéristiques du cluster et des datasets
Notre environnement utilise la distribution HDP 3.1 de Hortonwork distribuée par Cloudera. Afin de mieux évaluer la performance du format de fichier, il est pertinent de travailler sur un dataset relativement important. Au moins 10 Go sont à considérer comme le minimum, quelques centaines de Go seraient beaucoup plus pertinents.
Nous avons sélectionné 3 datasets avec des caractéristiques différentes pour évaluer les comportements des formats de fichiers sélectionnés sur différentes structures de données. Plusieurs types de requêtes ont été créés pour illustrer plusieurs cas d’utilisation tels que la sélection d’enregistrements, l’analyse de données, les jointures, etc.
-
NYC taxi est un dataset qui contient des informations sur les trajets et les tarifs de 2010 à 2013. Les données sur les trajets font environ 86,8 Go et les données sur les tarifs 49,9 Go.
-
IMDB est une donnée relationnelle. Elle fournit sept tableaux au format TSV : imdb.name.basics, imdb.title.basics, imdb.title.crew, imdb.title.akas, imdb.title.ratings, imdb.title.episode et imdb.title.principals. Leur taille totale en format non compressé est de 4,7 Go. Nous n’utiliserons pas ce dataset dans ce préent article du fait de sa taille (inférieure à 10Go). Il sera utile pour l’article suivant qui évaluera les performances des différents codecs avec HiveQL.
-
wikimedia est un dataset semi-structurée avec une structure complexe (données imbriquées). Il occupe 43,8 Go de données non compressées au format JSON.
Télécharger les données dans HDFS
Le script suivant montre comment télécharger un dataset directement en format hdfs.
# Use curl command to load data
source='http://...'
hdfs dfs -put <(curl -sS -L $source) /user/${env:USER}/datasetDéclaration du schéma dans Hive
Le dataset NYC taxi est composé de deux tables :
SET hivevar:database=<DATABASE NAME>;
USE ${database};
DROP TABLE IF EXISTS trip_data;
CREATE EXTERNAL TABLE trip_data
(
medallion NUMERIC, hack_license NUMERIC, vendor_id STRING, rate_code NUMERIC,
store_and_fwd_flag NUMERIC, pickup_datetime STRING, dropoff_datetime STRING,
passenger_count NUMERIC, trip_time_in_secs NUMERIC, trip_distance NUMERIC,
pickup_longitude NUMERIC, pickup_latitude NUMERIC, dropoff_longitude NUMERIC,
dropoff_latitude NUMERIC
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ","
STORED AS TEXTFILE
LOCATION "/user/${username}/trip_data/"
TBLPROPERTIES ("skip.header.line.count"="1");
DROP TABLE IF EXISTS trip_data;
CREATE EXTERNAL TABLE fare_data
(
medallion NUMERIC, hack_license NUMERIC, vendor_id STRING, pickup_datetime STRING,
payment_type STRING, fare_amount NUMERIC, surcharge NUMERIC, mta_tax NUMERIC,
tip_amount NUMERIC, tolls_amount NUMERIC, total_amount NUMERIC
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/${username}/fare_data/'
TBLPROPERTIES ("skip.header.line.count"="1");Le dataset Wikimedia est constitué d’une seule table :
SET hivevar:database=<DATABASE NAME>;
USE ${database};
DROP TABLE IF EXISTS wiki_data_json;
CREATE EXTERNAL TABLE wiki_data_json
(
id STRING, `type` STRING,
aliases MAP<string, array<struct<language:string, value:string>>>,
descriptions MAP<string, struct<language:string, value:string>>,
labels MAP<string, struct<language:string, value:string>>,
claims MAP<string, array<struct<id:string, mainsnak:struct<snaktype:string, property:string,
datatype:string, datavalue:struct<value:string, type:string>>, type:string, `rank`:string>>>,
sitelinks MAP<string, struct<site:string, title:string, badges:string>>
)
ROW FORMAT SERDE "org.openx.data.jsonserde.JsonSerDe"
WITH SERDEPROPERTIES ("ignore.malformed.json"="true", "skip.header.line.count"="1")
STORED AS TEXTFILE
LOCATION "/user/${username}/wikidata/";Nos tables sont déclarées dans Hive comme externes. Cela nous permet de définir une table qui n’est pas gérée par Hive. Voici deux requêtes simples pour s’assurer que nos tables sont déclarées et que nos données sont lisibles :
use ${database};
show tables;
SELECT * FROM trip_data LIMIT 10;Conversion des données dans un autre format de fichier
Chaque conversion est testée avec et sans compression. Cela se fait dans les formats ORC, Parquet, CSV, JSON et AVRO. Dans Hive, le format CSV peut être déclaré de différentes manières, soit en utilisant le format CSV Serde ou le format CSV simplifié à partir des formats TEXTFILE. Le premier comprend toutes les caractéristiques liées au format CSV telles que les caractères de séparation, de “quote” et d’échappement. Cependant, il comporte une limitation en traitant chaque colonne comme un type de chaîne de caractères. Le second a été utilisé à la place. Bien que l’implémentation du format CSV soit plus naïve, elle préserve le type de données natif de chaque colonne.
Les formats de fichiers peuvent supporter algorithmes de compression appelés codecs. Par exemple, ORC et Parquet utilisent par défaut respectivement ZLIB et GZIP et tous deux supportent en plus Snappy. Les formats de fichier texte n’ont aucune restriction quant à la compression appliquée. Les codecs disponibles sont limités par ce que la base de données prend en charge. Dans notre cas, il existe de nombreux types de compression différents pris en charge dans Hive. En plus de Snappy et gzip, nous avons choisi de tester bzip2 et lz4. Pour AVRO, nous avons également choisi de tester le codec Deflate en plus de Snappy, mais d’autres codecs sont pris en charge.
Afin d’automatiser ce processus, nous avons écrit un script bash qui crée et récupère les métriques avant de supprimer la table.
# Create table and retrieve the generation time of conversion
username=`whoami`
for i in /home/${username}/requests_file/*;
do
metrics_file="$(echo "$i" | awk -F"/" '{print $NF}')"."csv"
sh <<EOF
beeline -u "jdbc:hive2://zoo-1.au.adaltas.cloud:2181,zoo-2.au.adaltas.cloud:2181,zoo-3.au.adaltas.cloud:2181/dsti;serviceDiscoveryMode=zooKeeper;zooKeeper$"
-f "$i" 2>&1 | awk '/^[INFO].*VERTICES.*$/||/^[INFO].*Map .*$/||/^[INFO].*Reducer .*$/' >> "$metrics_file"
EOF
# Retrieve the storage space
hdfs dfs -du -s -h /user/${username}/tables/* >>"$metrics_file"
# Delete table
hdfs dfs -rm -r -skipTrash /user/${username}/tables/*
doneUn exemple de la variable $i pourrait être :
--Convert trip data to ORC
CREATE EXTERNAL TABLE trip_data_orc
(
-- all fields described above
)
STORED AS ORC
LOCATION '/user/${env:USER}/trip_data/trip_data_orc'
TBLPROPERTIES ("orc.compress"="ZLIB");
SET hive.exec.compress.output=true;
insert into trip_data_orc
select * from trip_data;NOTE :
- Assurez-vous que le fichier
/home/${username}/requests_file/contient les requêtes comme l’exemple ci-dessus. - La commande de récupération de l’espace de stockage génère deux colonnes. La première colonne fournit la taille brute des fichiers dans les répertoires HDFS. La deuxième colonne indique l’espace réellement consommé par ces fichiers dans HDFS. La deuxième colonne fournit une valeur beaucoup plus élevée que la première en raison du facteur de réplication configuré dans HDFS.
- Nous avons délibérément choisi de ne pas convertir le dataset Wikimédia en CSV en raison de sa structure qui ne correspond pas parfaitement aux contraintes du CSV.
- Pour plus de fiabilité, ces tests ont été effectués sur trois répétitions. Le résultat final décrit dans la section suivante est représenté par la valeur moyenne.
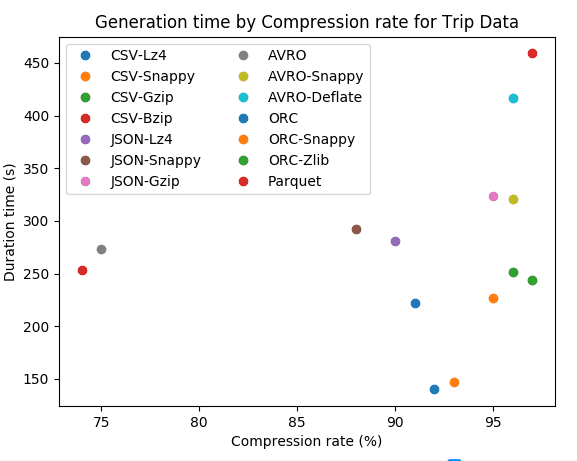
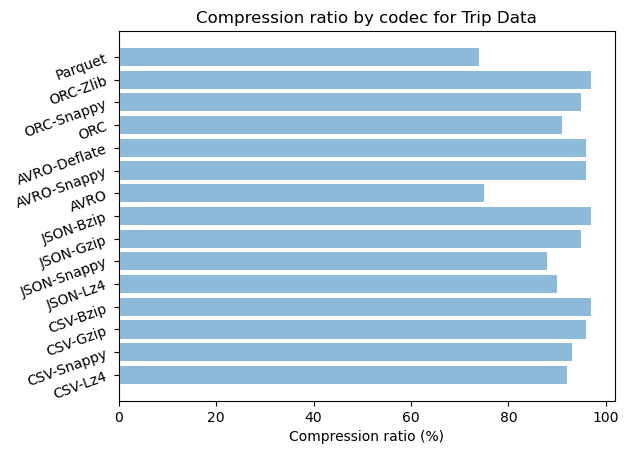
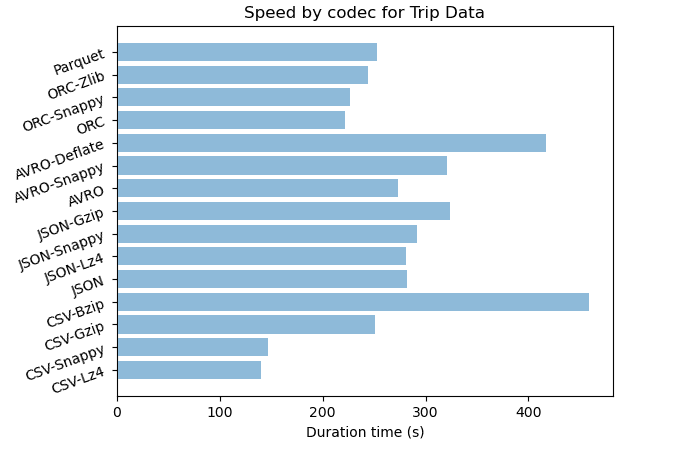
Resultats
| Dataset | Format-codec | Compressé | Taille (Go) | Ratio de stockage | Durée (s) | Durée CPU (s) |
|---|---|---|---|---|---|---|
| Trip data | CSV | no | 86.8 | 39% | ||
| Trip data | CSV-Lz4 | yes | 17.2 | 8% | 140 | 4002 |
| Trip data | CSV-Snappy | yes | 16.5 | 7% | 147 | 4007 |
| Trip data | CSV-Gzip | yes | 9.9 | 4% | 251 | 7134 |
| Trip data | CSV-Bzip | yes | 6.0 | 3% | 459 | 13730 |
| Trip data | JSON | no | 222.0 | 100% | 282 | 6848 |
| Trip data | JSON-Lz4 | yes | 22.3 | 10% | 281 | 6402 |
| Trip data | JSON-Snappy | yes | 26.7 | 12% | 292 | 7222 |
| Trip data | JSON-Gzip | yes | 11.5 | 5% | 324 | 9196 |
| Trip data | JSON-Bzip | yes | 6.5 | 3% | 2020 | 60201 |
| Trip data | AVRO | no | 55.2 | 25% | 273 | 7459 |
| Trip data | AVRO-Snappy | yes | 9.2 | 4% | 321 | 9613 |
| Trip data | AVRO-Deflate | yes | 9.2 | 4% | 417 | 9808 |
| Trip data | ORC | no | 19.8 | 9% | 222 | 6481 |
| Trip data | ORC-Snappy | yes | 10.0 | 5% | 227 | 6746 |
| Trip data | ORC-Zlib | yes | 6.7 | 3% | 244 | 7046 |
| Trip data | Parquet | no | 58.1 | 26% | 253 | 7073 |
| Trip data | Parquet-Gzip | yes | 58.1 | 26% | 262 | 7337 |
| Trip data | Parquet-Snappy | yes | 58.1 | 26% | 299 | 8014 |
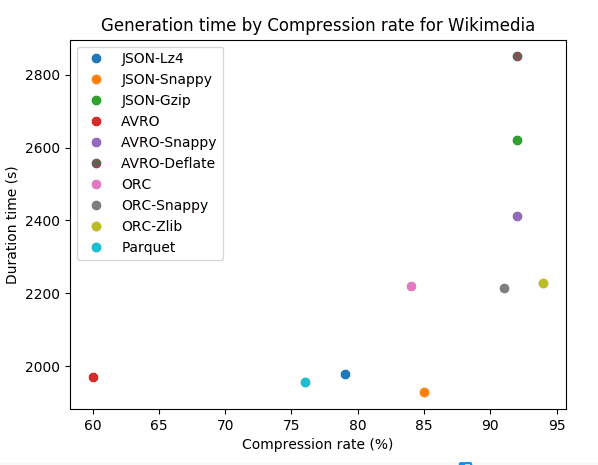
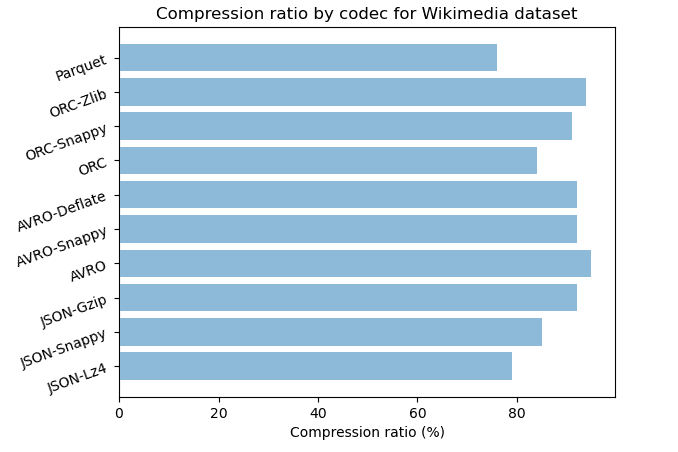
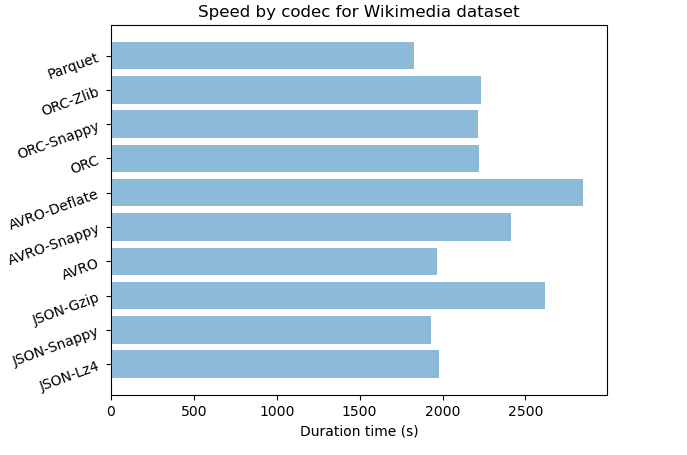
| Dataset | Format-codec | Compressé | Taille (Go) | Ratio de stockage | Durée (s) | Durée CPU (s) |
|---|---|---|---|---|---|---|
| Wikimedia | JSON | no | 43.8 | 100% | ||
| Wikimedia | JSON-Lz4 | yes | 5.9 | 21% | 1978 | 2743 |
| Wikimedia | JSON-Snappy | yes | 6.5 | 15% | 1928 | 2567 |
| Wikimedia | JSON-Gzip | yes | 3.6 | 8% | 2620 | 2824 |
| Wikimedia | JSON-Bzip | yes | 2.4 | 5% | 7610 | 8007 |
| Wikimedia | AVRO | no | 17.4 | 40% | 1969 | 2341 |
| Wikimedia | AVRO-Snappy | yes | 3.7 | 8% | 2412 | 2891 |
| Wikimedia | AVRO-Deflate | yes | 3.7 | 8% | 2850 | 3121 |
| Wikimedia | ORC | no | 7.0 | 16% | 2221 | 2475 |
| Wikimedia | ORC-Snappy | yes | 4.1 | 9% | 2215 | 2398 |
| Wikimedia | ORC-Zlib | yes | 2.8 | 6% | 2229 | 2487 |
| Wikimedia | Parquet | no | 10.3 | 24% | 1827 | 2222 |
| Wikimedia | Parquet-Snappy | yes | 10.3 | 24% | 1778 | 2190 |
| Wikimedia | Parquet-Gzip | yes | 10.3 | 24% | 1957 | 2365 |
Interprétation
Analysons les résultats sous différents angles. Les ratios de stockage sont relatifs au format de fichier JSON non compressé utilisé comme référence.
Valeurs abérantes de Parquet
On remarque que l’algorithme de compression de Parquet ne fonctionne pas. Cela peut être dû à l’absences de certains fichiers jar de compression snappy dans la plateforme HDP.
Analyse par format de fichier
Analysons les formats de manière indépendante et tentons de mettre en évidence les avantages d’utiliser un format en fonction de cas d’utilisation spécifiques.
JSON
Pour le format JSON, on remarque que la compression a un fort impact entre 90% et 97% pour les données Trip Data et entre 79% et 95% pour Wikimedia. Nous pouvons remarquer que les algorithmes de compression avec JSON sont moins performants avec les données semi-structurées. En termes de vitesse, les algorithmes de compression avec JSON sont rapides mais nous pouvons observer que plus le taux de compression est élevé, plus l’algorithme est lent.
AVRO
Avec AVRO, nous avons un fort taux de compression de 92% pour Wikimedia et 96% pour les données Trip Data. Il a également une vitesse acceptable en ce qui concerne ses performances de compression. Les algorithmes de compression avec AVRO sont plus efficaces avec les séries de données temporelles qui ont beaucoup de flottants.
ORC
Avec ORC, nous avons un taux de compression très élevé, jusqu’à 97% pour les données Trip Data et 94% pour Wikimedia. Le temps de génération est plus court que pour les autres formats et il est moins gourmand en CPU. Pour les ensembles de données comportant beaucoup de valeurs flottantes ainsi que des colonnes avec beaucoup de valeurs nulles tel que le dataset Trip Data, les algorithmes de compression d’ORC sont très efficaces.
PARQUET
Dans sa forme non comprimée, Parquet a un taux de stockage de 74% pour les données Trip Data et de 76% pour Wikimedia par rapport à JSON. Parquet semble être plus efficace avec les données qui contiennent beaucoup de texte.
Analyse des formats de type ligne
Pour les données Trip Data, qui sont des séries temporelles composées de valeurs flottantes, nous pouvons voir que les différents codecs nous donnent un taux de compression presque identique : entre 92 % et 97 % pour CSV, entre 88 % et 97 % pour JSON et 96 % pour AVRO. Le codec Bzip est légèrement plus puissant que Gzip mais ce dernier est deux fois plus rapide quand il est appliqué à CSV et six fois plus rapide avec JSON. Les codecs AVRO-Snappy et AVRO-Deflate ont le même taux de compression mais le premier est légèrement plus rapide.
Le jeu de données Wikimedia est semi-structuré avec beaucoup de texte, JSON-Bzip est très efficace avec 95% de taux de compression. JSON-Gzip et JSON-Snappy sont très proches avec respectivement 92% et 85%. AVRO avec les codecs Snappy et Deflate a une forte compression de 92%. Même si JSON-Bzip est légèrement plus puissant, JSON-Gzip et AVRO avec Snappy sont trois fois plus rapides.
Pour les données semi-structurées, si vous recherchez une forte compression, un algorithme puissant comme Bzip avec JSON ou CSV serait recommandé. Mais des algorithmes modérément puissants comme Gzip avec JSON ou Snappy avec AVRO sont plus rapides et donnent presque le même ratio de stockage. Exemple : pour l’archivage, gzip pourrait être un choix pertinent car il traite plus rapidement la compression et fournit un espace de stockage pas trop éloigné de bzip2.
AVRO lui-même a comme format de codec par défaut deflate et pourrait être compressé en plus par bzip2, snappy, xz et zstandard. Il prend en charge les formats deflate et Snappy dans Hive où les deux ont été testés. D’après nos résultats, nous avons un bon taux de compression dans les deux ensembles de données et nous pouvons noter que snappy a une vitesse de compression plus rapide que deflate.
JSON vs AVRO
Comparons JSON et AVRO qui sont des formats de fichiers largement utilisés pour l’échange de données entre systèmes, en langages de programmation et cadres de traitement. Leur forme non compressée, JSON, qui est un format texte, est plus volumineuse qu’AVRO, qui est un format binaire. AVRO n’occupe qu’un quart de JSON pour les données Trip data qui sont des séries chronologiques et seulement 40% de JSON pour Wikimedia qui est un ensemble de données semi-structurées.
AVRO est très compact et rapide. Pour les données de flux, il a l’avantage d’avoir un schéma défini en JSON qui spécifie clairement la structure. Avec un schéma, les données peuvent également être encodées plus efficacement. Ainsi, il est pertinent de l’utiliser pour les données de flux. JSON ne fournit pas de schéma, ce qui entraîne une certaine verbosité et rend difficile la compréhension entre producteurs et consommateurs.
Analyse des formats de type colonne
Avec le format en colonnes, nous avons un taux de compression élevé pour tous les codecs avec jusqu’à 97% de compression pour ORC. Le format ORC-zlib donne dans les deux ensembles de données un taux de compression efficace de 97% et 94% et avec le format ORC-Snappy de 95% et 91%. Le temps de génération pour les deux codecs est presque le même avec un léger avantage pour ORC avec Snappy.
On peut remarquer que la compression est plus efficace pour les séries chronologiques. Le codec ORC-Zlib est plus puissant, mais le codec ORC-Snappy est plus rapide pour les données semi-structurées et les séries temporelles.
Comparaison des algorithmes de compression
Dans cette section, nous allons comparer les formats de fichiers en leur appliquant le même algorithme.
CSV-Bzip vs JSON-Bzip
Bzip donne les mêmes performances de compression à 97% avec le format CSV et JSON, mais l’algorithme est quatre fois plus rapide avec le format CSV. Par exemple, pour l’archivage, nous pouvons envisager de stocker l’ensemble des données en CSV et d’appliquer le codec Bzip, car le traitement sera plus rapide et les performances de stockage seront les mêmes.
CSV-Lz4 vs JSON-Lz4
Lz4 avec CSV et JSON donne respectivement 92% et 90% de taux de compression. Lz4 avec CSV est deux fois plus rapide que JSON.
CSV-Snappy vs JSON-Snappy vs AVRO-Snappy vs ORC-Snappy vs Parquet-Snappy
Les taux de compression sont très proches pour tous les formats, mais nous le taux le plus élevé est atteint avec AVRO autour de 96%. En termes de vitesse, il est plus rapide avec CSV et ORC. Le premier est deux fois plus rapide que JSON et AVRO. Si nous recherchons une forte compression, choisissez AVRO avec Snappy et pour la vitesse, ORC avec Snappy est préférable.
CSV-Gzip vs JSON-Gzip vs Parquet-Gzip
Gzip a un taux de compression élevé d’environ 95% avec CSV et JSON. Leur vitesse est proche avec un léger avantage pour CSV.
Critères de sélection pour format de fichier et codec
Comment choisir un algorithme de compression pour notre ensemble de données ? En fonction de notre objectif et de nos contraintes, nous pouvons avoir différentes options.
Format ligne vs format colonne : avec compression
Pour le format en ligne, le codec bzip offre le taux de compression le plus élevé, 97% pour le CSV et le JSON, tandis que gzip suit de près avec respectivement 96% et 92% pour CSV et JSON.
Pour le format en colonnes ORC avec zlib, les deux ensembles de données offrent un taux de compression efficace de 97% et 94% et, avec snappy, de 95% et 91%.
Les formats texte et colonne ont tous deux des algorithmes puissants qui produisent des résultats presque similaires en termes de stockage.
Lorsque vous avez besoin d’une forte compression
ORC-Zlib, JSON-Bzip et CSV-Bzip donnent le même taux de compression de 97%. ORC-Zlib est deux fois plus rapide que CSV-Bzip et huit fois plus rapide que JSON-Bzip. Pour l’archivage, ORC avec Zlib est le meilleur choix pour le format en colonnes et CSV avec Bzip est préférable pour les formats texte.
Lorsque vous avez besoin d’un traitement rapide
Lz4, Snappy, Gzip, et Zlib sont les algorithmes les plus rapides. On peut voir que plus l’algorithme est rapide, moins il est efficace en compression. Ces algorithmes sont plus efficaces lorsqu’ils sont appliqués à des formats en lignes.
Pour le format en colonnes, ORC avec snappy est l’algorithme le plus rapide et pour le format texte, vous pouvez considérer Lz4 ou Snappy.
Conclusion
Grâce à cette étude, nous avons eu un aperçu de la façon dont chaque format de fichier se comporte en termes de compression et de vitesse de génération. D’autres aspects, tels que la façon dont ils effectuent les requêtes, seront examinés dans notre prochain article.
Nous pouvons conclure en disant que les formats en colonnes optimisent mieux les ressources de stockage que les formats de fichiers en lignes ou en texte. Pour l’archivage, il est préférable de choisir le format en colonnes et ORC. Si vous devez utiliser des formats texte, les codecs Bzip et Gzip optimisent mieux le stockage, et pour le format en colonnes, le format Zlib avec ORC est recommandé. ORC offre une compression efficace ainsi qu’un stockage en colonnes qui permet de réduire les lectures sur le disque. En termes de vitesse, nous avons un comportement différent selon le format. Par exemple, pour le format texte, la vitesse semble être corrélée à l’espace de stockage. Plus le gain de stockage est élevé, plus il faut de temps pour effectuer la tâche de compression. Mais pour le format basé sur des colonnes, le temps de génération reste faible pour les algorithmes de compression puissants.
