


Deployez vos aplications IA conteneurisées avec nvidia-docker

24 mars 2022
- Catégories
- Orchestration de conteneurs
- Data Science
- Tags
- containerd
- DevOps
- Enseignement et tutorial
- NVIDIA
- Docker
- Keras
- TensorFlow [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
De plus en plus de produits et services prennent avantage des capacités de modélisation et prédiction des IA. Cet article présente l’outil nvidia-docker permettant d’intégrer des briques logiciels IA (Intelligence Artificielle) au sein d’une architecture micro-service. L’avantage principal exploré ici est l’utilisation des ressources GPU (Graphical Processing Unit) du système hôte pour accélérer de multiples applications IA conteneurisées.
Pour comprendre l’utilité de nvidia-docker, nous allons commencer par décrire quel type d’IA peut tirer profit de l’accélération GPU. Dans un second temps nous allons présenter comment mettre en place l’outil nvidia-docker. Finalement, nous décrirons quels sont les outils disponibles pour utiliser l’accélération GPU dans vos applications et comment les utiliser.
Pourquoi utiliser les GPUs dans les applications IA ?
Dans le domaine de l’intelligence artificielle, nous avons deux principaux sous-domaines qui sont utilisés : Le machine learning et le deep learning. Ce dernier fait partie d’une famille plus large de méthodes de machine learning basées sur les réseaux de neurones artificiels.
Dans le contexte du deep learning où les opérations sont essentiellement des multiplications de matrices, les GPUs s’avèrent plus efficaces par rapport aux CPUs (Central Processing Unit). C’est pourquoi l’utilisation des GPUs s’est développée ces dernières années. En effet, les GPUs sont considérés comme le coeur du deep learning en raison de leur architecture massivement parallèle.
Cependant, les GPUs ne peuvent pas exécuter n’importe quel programme. En effet, ils utilisent un langage spécifique (CUDA pour NVIDIA) permettant de tirer profit de leur architecture. Donc, comment utiliser et communiquer avec GPUs depuis vos applications ?
La technologie NVIDIA CUDA
NVIDIA CUDA (Compute Unified Device Architecture) est une architecture de calcul parallèle combinée avec une API permettant de programmer les GPUs. CUDA traduit le code des applications en un jeu d’instruction que les GPUs puissent executer.
Un SDK CUDA et des bibliothèques comme cuBLAS (Basic Linear Algebra Subroutines) et cuDNN (Deep Neural Network) ont été développées pour communiquer facilement et efficacement avec un GPU. CUDA est disponible en C, C++ et Fortran. Il existe des wrappers pour les autres langages dont Java, Python et R. Par exemple, les bibliothèques de deep learning comme TensorFlow et Keras reposent sur ces technologies.
Pourquoi utiliser nvidia-docker ?
Nvidia-docker répond au besoin des développeurs voulant ajouter des fonctionnalités IA à leurs applications, les conteneuriser et les déployer sur des serveurs disposant de GPUs NVIDIA.
L’objectif est de mettre en place une architecture permettant de développer et de déployer des modèles de deep learning dans des services disponibles via une API. Ainsi, le taux d’utilisation des ressources GPUs est optimisé en les rendant disponibles à multiples instances d’applications.
De plus, on bénéficie des avantages des environnements conteneurisés :
- Isolation des instances de chaque modèle IA.
- Colocalisation de plusieurs modèles avec chacun leurs dépendances spécifiques.
- Colocalisation d’un même modèle sous plusieurs versions.
- Déploiement cohérent des modèles.
- Surveillance des performances des modèles.
Nativement, l’utilisation d’un GPU dans un conteneur nécessite d’installer CUDA dans le conteneur et de donner les privilèges pour accéder au périphérique. C’est dans ce sens que l’outil nvidia-docker a été développé, permettant d’exposer les périphériques GPU NVIDIA dans les conteneurs de manière isolée et sécurisée.
À la date d’écriture de cet article, la dernière version de nvidia-docker est la v2. Cette version diffère grandement de la v1 par les points suivants :
- Version 1 : Nvidia-docker est implémenté comme une surcouche à Docker. C’est-à-dire que pour créer le conteneur il fallait utiliser nvidia-docker (Ex :
nvidia-docker run ...) qui effectue les actions (entre autres la création de volumes) permettant de voir les périphériques GPU dans le conteneur. - Version 2 : Le déploiement est simplifié avec le remplacement des volumes Docker par l’utilisation des runtimes Docker. Effectivement, pour lancer un conteneur, il faut à présent utiliser le runtime NVIDIA via Docker (Ex :
docker run --runtime nvidia ...)
Notez qu’en raison de leur architecture différente, les deux versions ne sont pas compatibles. Une application écrite en v1 doit être réécrite pour la v2.
Mise en place de nvidia-docker
Les éléments requis pour utiliser nvidia-docker sont :
- Un runtime pour conteneur.
- Un GPU disponible.
- Le NVIDIA Container Toolkit (partie principale de nvidia-docker).
Prérequis
Docker
Un runtime de conteneur est nécessaire pour l’exécution du NVIDIA Container Toolkit. Docker est le runtime recommandé, mais Podman et containerd sont également supportés.
La documentation officielle donne la procédure d’installation de Docker.
Driver NVIDIA
Des pilotes sont nécessaires pour l’utilisation d’un périphérique GPU. Dans le cas de GPUs NVIDIA, les pilotes correspondant à un OS donné s’obtiennent à partir de la page de téléchargement de pilote de NVIDIA, ceci en renseignant les informations sur le modèle du GPU.
L’installation des pilotes se fait via l’exécutable. Pour Linux, utiliser les commandes suivantes en remplaçant le nom du fichier téléchargé :
chmod +x NVIDIA-Linux-x86_64-470.94.run
./NVIDIA-Linux-x86_64-470.94.runRedémarrer la machine hôte à la fin de l’installation pour la prise en compte des pilotes installés.
Installer nvidia-docker
Nvidia-docker est disponible sur la page GitHub du projet. Pour l’installer, suivez le manuel d’installation en fonction des spécificités de votre serveur et architecture.
Outils nvidia-docker
Nous avons à présent une infrastructure qui permet d’avoir des environnements isolés donnant accès aux ressources GPU. Pour utiliser l’accélération GPU dans les applications, plusieurs outils ont été développés par NVIDIA (liste non exhaustive) :
- CUDA Toolkit : un ensemble d’outils permettant de développer des logiciels/programmes pouvant effectuer des calculs en utilisant à la fois CPU, RAM, et GPU. Ce dernier est utilisable sur les plateformes x86, Arm et POWER.
- NVIDIA cuDNN : une bibliothèque de primitives permettant d’accélérer les réseaux de deep learning et d’optimiser les performances GPU pour les principaux frameworks comme Tensorflow et Keras.
- NVIDIA cuBLAS : une bibliothèque de sous-programmes d’algèbre linéaire accélérés par GPU.
En utilisant ces outils dans le code des applications, les tâches d’IA et d’algèbre linéaires sont accélérées. Les GPU étant maintenant visibles, l’application est capable d’envoyer les données et les opérations à traiter sur le GPU.
Le CUDA Toolkit est l’option de plus bas niveaux. Il offre le plus de contrôle (mémoire et instructions) permettant de réaliser des applications sur mesure. Les bibliothèques offrent une abstraction des fonctionnalités CUDA. Elles permettent de se concentrer sur le développement de l’application plutôt que l’implémentation CUDA.
Une fois tous ces éléments implémentés, l’architecture utilisant le service nvidia-docker est prête à l’emploi.
Voici un schéma pour résumer tout ce que l’on a vu :
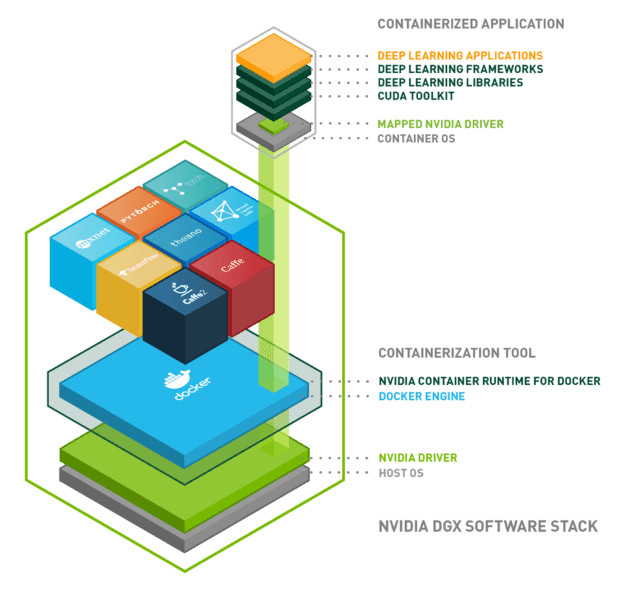
Conclusion
Nous avons mis en place une architecture permettant l’utilisation des ressources GPU depuis nos applications dans des environnements isolés. Pour résumer, l’architecture est composée des briques suivantes :
- Système d’exploitation : Linux, Windows …
- Docker : isolation de l’environnement utilisant les conteneurs Linux
- Pilote NVIDIA : installation du pilote pour le hardware en question
- Runtime conteneur NVIDIA : orchestration des trois précédents
- Applications sur conteneur Docker :
- CUDA
- cuDNN
- cuBLAS
- Tensorflow/Keras
NVIDIA continue de développer des outils et des bibliothèques autour des technologies IA, avec pour objectif de s’imposer en tant que leader. D’autres technologies peuvent complémenter nvidia-docker ou peuvent être plus adaptés que nvidia-docker en fonction des cas d’usage.
