


Collecte de logs Databricks vers Azure Monitor à l'échelle d'un workspace

By PLAYE Claire
10 mai 2022
- Catégories
- Cloud computing
- Data Engineering
- Adaltas Summit 2021
- Tags
- Métriques
- Supervision
- Spark
- Azure
- Databricks
- Log4j [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Databricks est une plateforme optimisée d’analyse de données, basée sur Apache Spark. La surveillance de la plateforme Databricks est cruciale pour garantir la qualité des données, les performances du travail et les problèmes de sécurité en limitant l’accès aux espaces de travail de production.
Les métriques, logs et événements des applications Spark produits par un workspace Databricks peuvent être personnalisés, envoyés et centralisés vers diverses plateformes de surveillance, notamment Azure Monitor Logs. Cet outil, anciennement appelé Log Analytics par Microsoft, est un service cloud Azure intégré à Azure Monitor qui collecte et stocke les logs des environnements cloud et on-premises. Il permet d’interroger les logs à partir des données collectées à l’aide d’un langage de requête en lecture seule nommé “Kusto”, pour construire des tableaux de bord “Workbooks” et de mettre en place des alertes sur les modèles identifiés.
Cet article se concentre sur l’automatisation de l’exportation des logs de Databricks vers un workspace Log Analytics en utilisant la bibliothèque Spark-monitoring à l’échelle d’un workspace.
Aperçu de l’envoi des logs de Databricks
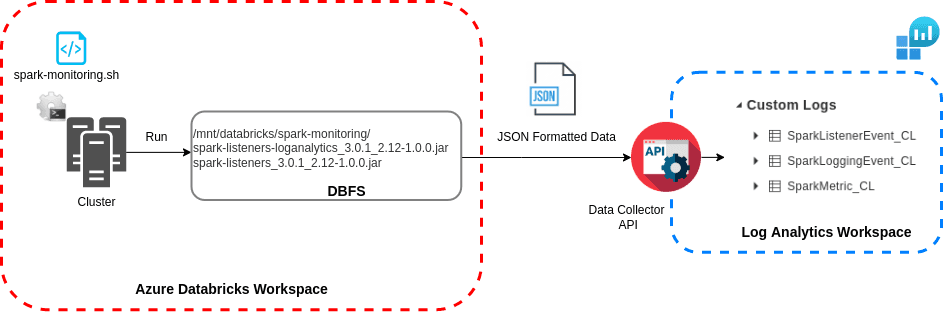
Cette section est un aperçu de l’architecture. Des informations plus détaillées et le code source associé sont fournis plus loin dans l’article.
Spark-monitoring est un projet Microsoft Open Source permettant d’exporter les logs de Databricks au niveau du cluster. Une fois téléchargée, la bibliothèque est construite localement avec Docker ou Maven en fonction de la version de Databricks Runtime du cluster à configurer (versions Spark et Scala). La construction de la bibliothèque génère deux fichiers jar :
spark-listeners_${spark-version}_${scala_version}-${version}: collecte les données d’un cluster en cours d’exécution ;spark-listeners-loganalytics_${spark-version}_${scala_version}-${version}: étendspark-listenersen collectant des données, en se connectant à un workspace Log Analytics, en analysant et en envoyant les logs via l’API Data Collector.
Dans la documentation, une fois que les jars sont construits, ils sont mis sur le DBFS. Un script init spark-monitoring.sh est édité localement avec les configurations du workspace et du cluster et ajouté manuellement via l’interface Databricks au niveau du cluster.
Au lancement du cluster, les logs sont envoyés en streaming au format JSON à l’API de Log Analytics Data Collector et stockés dans 3 tables différentes, une pour chaque type de log envoyé :
- SparkMetric_CL : Métriques d’exécution des applications Spark (utilisation de la mémoire, nombre de travaux, étapes des tâches soumises/complétées/en cours) ;
- SparkListenerEvent_CL : Tous les événements interceptés par SparkListener pendant l’exécution de l’application Spark (jobs, stages et tâches début/fin) ;
- SparkLoggingEvent_CL : Logs provenant de log4j appender.
Certaines configurations permettent d’automatiser la mise en place de l’envoi des logs au niveau du workspace en configurant tous les clusters d’un workspace donné. Cela implique de télécharger le projet, de le construire avec Docker ou Maven, d’éditer le script spark-monitoring.sh et les variables d’environnements des clusters. Une fois toutes les configurations effectuées, l’exécution du script PowerShell configure le workspace Databricks. Il est basé sur 3 scripts bash :
spark-monitoring-vars.sh: définit les variables d’environnement de le workspace ;spark-monitoring.sh: envoie les logs en streaming à Log Analytics ;spark-monitoring-global-init.sh: ce script à l’échelle du workspace exécutespark-monitoring-vars.shpuisspark-monitoring.sh.
Le script PowerShell dbx-monitoring-deploy.ps1 est exécuté localement et il déploie les configurations au niveau du workspace. Il remplit spark-monitoring-vars.sh avec les variables du workspace, il copie les scripts et les jars sur DBFS et envoie le script d’init global sur Databricks.
Configuration d’un workspace
1. Construction des fichiers jar
Clonez le dépôt Spark-monitoring et construisez localement les fichiers jar avec Docker ou Maven dans les versions du runtime Databricks de tous les clusters qui doivent être configurés dans le workspace conformément à la documentation.
Avec Docker :
À la racine du dossier spark-monitoring, exécutez la commande build dans les versions Spark et Scala souhaitées. Dans cet exemple, la bibliothèque est construite pour Scala 2.12 et Spark 3.0.1.
docker run -it --rm -v pwd:/spark-monitoring -v "$HOME/.m2":/root/.m2 -w /spark-monitoring/src maven:3.6.3-jdk-8 mvn install -P "scala-2.12_spark-3.0.1"Les fichiers jar sont construits dans le dossier spark-monitoring/src/target. Le script spark-monitoring.sh est situé dans le dossier spark-monitoring/src/spark-listeners/scripts.
Toutes ces étapes sont expliquées dans le chapitre Build the Azure Databricks monitoring library du dépôt GitHub de Microsoft patterns & practices.
2. Configuration des variables d’environnement de Log Analytics
L’id et la clé du workspace Log Analytics sont stockés dans les secrets d’Azure Key Vault et référencés dans les variables d’environnement de tous les clusters configurés. Azure Databricks accède à Key Vault par le biais du workspace Databricks Secret Scope.
Après avoir créé les secrets de l’identifiant et de la clé du workspace Log Analytics, configurez chaque cluster en référençant manuellement les secrets en suivant les instructions sur la façon de configurer la portée secrète soutenue par Azure Key Vault.
LOG_ANALYTICS_WORKSPACE_KEY={{secrets/secret-scope-name/pw-log-analytics}}
LOG_ANALYTICS_WORKSPACE_ID={{secrets/secret-scope-name/id-log-analytics}}3. Ajout des scripts spark-monitoring-global-init.sh et spark-monitoring-vars.sh
Créez un dossier jars, téléchargez tous les fichiers jar et configurations en respectant l’arborescence de fichiers suivante :
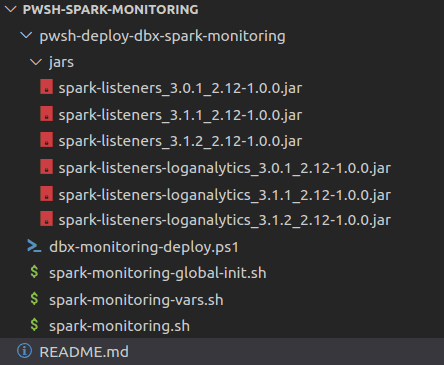
-
spark-monitoring-global-init.sh: Ce script est lancé au lancement de chaque cluster dans le workspace.#!/bin/bash # Directory of spark-monitoring STAGE_DIR=/dbfs/databricks/spark-monitoring # Script defining variables in workspace environment VARS_SCRIPT=$STAGE_DIR/spark-monitoring-vars.sh # Script sending logs to Log Analytics MONITORING_SCRIPT=$STAGE_DIR/spark-monitoring.sh # If directory exists if [ -d "$STAGE_DIR" -a -f "$VARS_SCRIPT" -a -f "$MONITORING_SCRIPT" ]; then # If scripts exists run them /bin/bash $VARS_SCRIPT; /bin/bash $MONITORING_SCRIPT; else echo "Directory $STAGE_DIR does not exist or one of the scripts needed is missing" fi -
spark-monitoring-vars.sh: Ce script est un modèle de toutes les variables d’environnement nécessaires au niveau du cluster et du workspace.#!/bin/bash # These environment variables would normally be set by Spark scripts. # However, for a Databricks init script, they have not been set yet. # We will keep the names the same here, but not export them. # These must be changed if the associated Spark environment variables # are changed. DB_HOME=/databricks SPARK_HOME=$DB_HOME/spark SPARK_CONF_DIR=$SPARK_HOME/conf tee -a "$SPARK_CONF_DIR/spark-env.sh" << EOF # Id of Azure subscription export AZ_SUBSCRIPTION_ID="$AZ_SUBSCRIPTION_ID" # Resource group name of workspace export AZ_RSRC_GRP_NAME="$AZ_RSRC_GRP_NAME" export AZ_RSRC_PROV_NAMESPACE=Microsoft.Databricks export AZ_RSRC_TYPE=workspaces # Name of Databricks workspace export AZ_RSRC_NAME="$AZ_RSRC_NAME" EOF
4. Edition et ajout de spark-monitoring.sh
Copiez spark-monitoring.sh du projet cloné, ajoutez-le à l’arborescence des fichiers et modifiez les variables d’environnement comme suit :
DB_HOME=/databricks
SPARK_HOME=$DB_HOME/spark
SPARK_CONF_DIR=$SPARK_HOME/conf
tee -a "$SPARK_CONF_DIR/spark-env.sh" << EOF
# Export cluster id and name from environment variables
export DB_CLUSTER_ID=$DB_CLUSTER_ID
export DB_CLUSTER_NAME=$DB_CLUSTER_NAME
EOFCompte tenu des coûts de stockage importants associés à un workspace Log Analytics, dans le contexte des métriques Spark, appliquez des filtres basés sur des expressions REGEX pour ne conserver que les informations les plus pertinentes des logs. Cette documentation sur le filtrage des événements vous donne les différentes variables à définir.
5. Édition, ajout et lancement du script PowerShell
Le script dbx-monitoring-deploy.ps1 est utilisé pour configurer l’exportation des logs de cluster d’un workspace Databricks vers Log Analytics.
Il effectue les actions suivantes :
- Remplit
spark-monitoring-vars.shavec les valeurs correctes pour le workspace. - Télécharge
spark-monitoring-vars.sh,spark-monitoring.shet tous les fichiers jar sur le workspace DBFS. - Affiche via l’API Databricks le contenu du script init global.
On suppose qu’il y a 3 abonnements Azure différents (DEV/ PREPROD/ PROD) pour séparer les phases de développement, de test et de production d’une intégration continue. Un abonnement de pré-production est utilisé pour les tests d’intégration et les tests fonctionnels d’acceptation avant de passer en production.
Modifiez cette section en fonction de vos abonnements.
param(
[Parameter(Mandatory=$true,ValueFromPipeline=$true)]$p,
[Parameter(Mandatory=$true,ValueFromPipeline=$true)]$e,
[Parameter(Mandatory=$true,ValueFromPipeline=$true)]$n,
[Parameter(Mandatory=$true,ValueFromPipeline=$true)]$rg,
[Parameter(Mandatory=$true,ValueFromPipeline=$true)]$w
)
$armFolder = $p.TrimEnd("/","\")
$deploymentName = $n.ToLower()
$varsTemplatePath = "$armFolder/spark-monitoring-vars.sh"
if ($e -like "dev")
{
$AZ_SUBSCRIPTION_ID = ""
}
elseif ($e -like 'prod') {
$AZ_SUBSCRIPTION_ID = ""
}
elseif ($e -like 'preprod') {
$AZ_SUBSCRIPTION_ID = ""
}
else{
Write-Output "no environment provided - exiting"
Exit-PSSession
}
# Fill spark-monitoring-vars.sh with correct values for workspace
$AZ_RSRC_GRP_NAME = $rg
$AZ_RSRC_NAME = $w
$environment = $e.ToLower()
$parametersPath = "$armFolder/$environment/$deploymentName/spark-monitoring-vars-$environment-$deploymentName.sh"
$template = Get-Content "$varsTemplatePath" -Raw
$filledTemplate = Invoke-Expression "@`"`r`n$template`r`n`"@"
mkdir -p $armFolder/$environment/$deploymentName
Out-File -FilePath $parametersPath -InputObject $filledTemplate
# Set Azure Context to Databricks workspace subscription
try {
$context = get-azContext
if(!$context)
{
Write-Output "No context, please connect !"
$Credential = Get-Credential
Connect-AzAccount -Credential $Credential -ErrorAction Stop
}
if ($environment -like "dev")
{
set-azcontext "AD-DEV01" -ErrorAction Stop
}
elseif ($environment -like 'prod') {
set-azcontext "AD-PROD01" -ErrorAction Stop
}
elseif ($environment -like 'preprod') {
set-azcontext "AD-PREPROD01" -ErrorAction Stop
}
else{
Write-Output "no context found for provided environment- exiting"
Exit
}
}
catch{
Write-Output "error setting context - exiting"
Exit
}
# Upload spark-monitoring-vars.sh, spark-monitoring-vars.sh and all jar files on DBFS workspace
$mydbx=Get-AzDatabricksWorkspace -ResourceGroupName $AZ_RSRC_GRP_NAME
$hostVar = "https://" + $mydbx.Url
$myToken = Get-AzAccessToken -Resource "2ff814a6-3304-4ab8-85cb-cd0e6f879c1d"
$env:DATABRICKS_AAD_TOKEN=$myToken.Token
databricks configure --aad-token --host $hostVar
databricks fs mkdirs dbfs:/databricks/spark-monitoring
databricks fs cp --overwrite $armFolder/spark-monitoring.sh dbfs:/databricks/spark-monitoring
databricks fs cp --overwrite $armFolder/$environment/$deploymentName/spark-monitoring-vars-$environment-$deploymentName.sh dbfs:/databricks/spark-monitoring/spark-monitoring-vars.sh
databricks fs cp --recursive --overwrite $armFolder/jars dbfs:/databricks/spark-monitoring
# Post through Databricks API content of global init script
$inputfile = "$armFolder/spark-monitoring-global-init.sh"
$fc = get-content $inputfile -Encoding UTF8 -Raw
$By = [System.Text.Encoding]::UTF8.GetBytes($fc)
$etext = [System.Convert]::ToBase64String($By, 'InsertLineBreaks')
$Body = @{
name = "monitoring"
script = "$etext"
position = 1
enabled = "true"
}
$JsonBody = $Body | ConvertTo-Json
$Uri = "https://" + $mydbx.Url + "/api/2.0/global-init-scripts"
$Header = @{Authorization = "Bearer $env:DATABRICKS_AAD_TOKEN"}
Invoke-RestMethod -Method Post -Uri $Uri -Headers $Header -Body $JsonBodyEnrichissez et lancez le script avec ces paramètres :
| Paramètre | Description |
|---|---|
| p | Chemin du script |
| e | Environnement (DEV, PREPROD, PROD) |
| n | Nom du déploiement |
| rg | Groupe de ressources du workspace |
| w | Nom du workspace |
Appelez le script comme suit :
pwsh dbx-monitoring-deploy.ps1 -p /home/Documents/pwsh-spark-monitoring/pwsh-deploy-dbx-spark-monitoring -e DEV -n deploy_log_analytics_wksp_sales -rg rg-dev-datalake -w dbx-dev-datalake-salesGrâce à ce script, vous pouvez facilement déployer la bibliothèque Spark-monitoring sur tous vos espaces de travail Databricks.
Les logs envoyés nativement permettent de surveiller la santé du cluster, l’exécution des tâches et de signaler les erreurs de notebooks. Une autre façon de surveiller le traitement quotidien des données consiste à effectuer une journalisation personnalisée à l’aide de log4j appender. Ainsi, vous pouvez ajouter des étapes pour mettre en œuvre la validation de la qualité des données sur les données ingérées et nettoyées et des tests personnalisés avec une liste prédéfinie d’attentes pour valider les données.
Nous pouvons imaginer utiliser des logs personnalisés pour enregistrer les mauvais enregistrements, appliquer des contrôles et des contraintes sur les données, puis envoyer des mesures de qualité à Log Analytics pour la création de rapports et d’alertes. Pour ce faire, vous pouvez créer votre propre bibliothèque de qualité des données ou utiliser des outils existants comme Apache Griffin ou Amazon Deeque.
