


Kubernetes : déboguer avec les conteneurs éphémères

7 févr. 2023
- Catégories
- Orchestration de conteneurs
- Tech Radar
- Tags
- Debug
- Kubernetes [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Tout individu ayant eu un jour à manipuler Kubernetes s’est retrouvé confronter à la résolution d’erreurs de pods. Les méthodes prévues à cet effet sont performantes, et permettent de venir à bout des erreurs les plus fréquentes. Malgré tout, dans certaines situations, celles-ci se retrouvent limitées : déboguer devient alors délicat. Lors de la Kubecon 2022 à Valence, présenté par la Cloud Native Computing Foundation, j’ai pu assister à la présentation d’Aaron Alpar à propos d’une nouvelle manière de déboguer ses pods dans Kubernetes disponible en beta dans sa version 1.23 : kubectl debug.
Tout d’abord, nous allons voir les méthodes classiques pour le debug de pods, ensuite nous développerons la notion de namespace, puis nous définirons ce que sont les conteneurs éphémères.
Comment déboguer un pod ?
Jusqu’à maintenant, après avoir consulté les logs d’un pod avec kubectl log <pod>, deux solutions s’offraient à nous pour déboguer plus en profondeur : exec et copy.
La première se présente sous la forme suivantes :
kubectl exec \
-it \ # Ouvre une invite de commande
-n <namespace_pod> \
<pod> \
-c <conteneur> \ # Permet de spécifier un conteneur en particulier
-- /bin/sh # Lance un shell dans l'inviteCette commande permet d’ouvrir une invite de commande dans le conteneur cible. L’étendue des droits de l’utilisateur à lancer des commandes dépendra alors du rôle Kubernetes avec lequel l’invite à été démarrée. Si vos privilèges sont élevés, vous pourrez faire à peu près tout dans votre conteneur… tant qu’il sait le faire. En effet, les conteneurs sont pensés pour être légers : ils ne contiennent chacun que leur application et ses dépendances. Les outils essentiels à une résolution d’erreur efficace seront inutilisables car absents. Lister les fichiers d’un répertoire avec ls, rechercher un fichier en particulier avec find ou modifier les droits d’accès sur un fichier avec chmod : toutes ces actions seront le plus souvent réalisables car natives au système d’exécution du conteneur. En revanche, une analyse plus poussée des ports réseaux actifs avec netstat, ou des tests de connexion avec curl ne seront la plupart du temps pas faisable.
La seconde commande se présente sous la forme suivante :
kubectl debug \
-it \ # Ouvre une invite de commande
-n <namespace_pod> \
<pod> \
--copy-to=<nom_pod> \ # Nom du nouveau pod
--container <nom_conteneur> \ # Pour choisir un nom de conteneur autre que debugger-xxxxx
--image=busybox \ # Image contenant de nombreux outils de debug
--share-processes \ # Autorise ce nouveau conteneur à voir les processus des autres conteneurs du même pod
-- /bin/sh # Lance un shell dans l'inviteCette commande crée un nouveau pod et redémarre notre application dans un nouveau conteneur lui appartenant. Une invite de commande vers notre nouveau conteneur s’ouvre alors. Ici, le fait de pouvoir sélectionner l’image de notre choix offre à notre nouveau conteneur des outils pertinents pour la résolution d’erreur. Cependant, cette méthode possède deux inconvénients majeurs :
- la création d’un nouveau pod implique le redémarrage de l’application
- s’il s’agit d’un pod avec réplicat (pour les deployments et *statefulset), cette méthode peut s’avérer dangereuse car de nouveaux réplicats peuvent être créés involontairement.
Les namespaces Linux
Qu’est-ce qu’un conteneur ? En effet, l’idée que l’on se fait d’un conteneur n’est parfois pas tout à fait alignée avec la réalité. Un conteneur est une sorte de bac à sable dont l’isolation dépend d’une caractéristique clé du noyau Linux : les namespaces.
Un namespace regroupe tous les processus ayant une vision commune d’une ressource partagée (par exemple, tous les processus d’un conteneur). Les namespaces contrôlent l’isolation du conteneur et de ses processus, et délimitent ses ressources : ce sont eux qui lui interdisent de voir en-dehors de lui-même vers le reste du système. Il existe un namespace pour chaque caractéristique d’un environnement :
mnt: isole les points de montagepid: isole les ID de processusnet: isole l’interface réseauipc: isole les communications inter-processusuts: isole les noms d’hôte et de domaineuser: isole l’identification des utilisateurs et les privilègescgroup: isole l’appartenance d’un processus à un groupe de contrôle
Le namespace pid, par exemple, permet au conteneur d’avoir ses propres ID de processus, car il n’a pas connaissance des PID de la machine hôte. De même, le namespace uts autorise le conteneur à posséder son propre nom d’hôte, indépendamment de celui de la machine hôte. Un conteneur peut appartenir à plusieurs types de namespaces : il peut par exemple avoir ses propres points de montage ainsi que sa propre interface réseau. De plus, ces namespaces peuvent être copiés d’un conteneur à l’autre.
Les namespaces sont utilisés par tout processus tournant sur une machine. Le dossier /proc/ contient tous les fichiers relatifs aux namespaces d’un processus et les namespaces actuellement utilisés par celui-ci. Les namespaces utilisés par les conteneurs ont une relation parent-enfant avec ceux de la machine : un namespace parent est conscient de ses enfants, alors que l’inverse est faux. Cela peut se vérifier grâce à la commande nsenter, qui permet de lancer une commande dans un namespace (se lance donc depuis un shell d’un namespace parent) :
nsenter \
--target <pid> \ # Permet de sélectionner un namespace par le biais d'un processus l'utilisant
--all \ # Permet d'englober tous les namespaces utilisés par le processus spécifié
/bin/ps -ef # Affiche tous les processus de manière détailléeCette commande permet donc d’afficher tous les processus appartenant aux namespaces qu’utilise le processus mentionné. En spécifiant le PID d’un conteneur (donc un processus utilisant un namespace enfant), on obtient la liste des processus tournant dans ce conteneur, du point de vue de la machine hôte. Ci-dessous un exemple de cette commande vers un pod possédant un conteneur PostgreSQL, lancé depuis son nœud hôte :
nsenter --target $(pgrep -o postgres) --all /bin/ps -ef
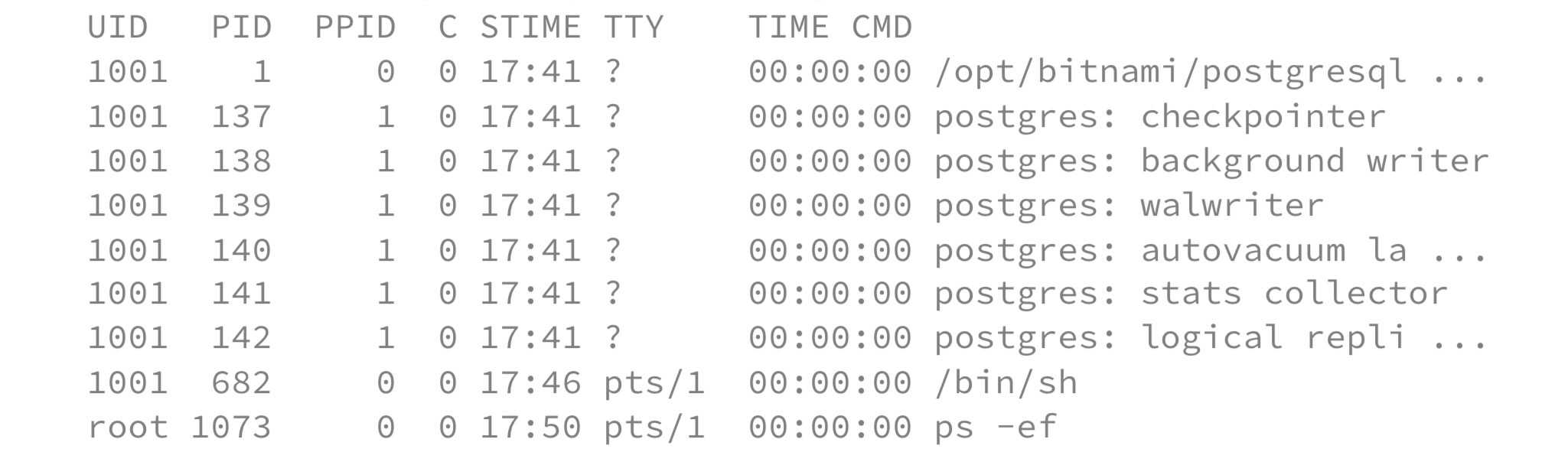
Si, ensuite, on effectue la même action mais cette fois-ci avec kubectl exec, on obtient la liste des processus tournant dans ce conteneur, du point de vue cette fois-ci du conteneur lui-même. Ci-dessous un exemple depuis l’intérieur du même pod PostgreSQL :
kubectl exec -it -n pg pg-postgresql -- ps -ef
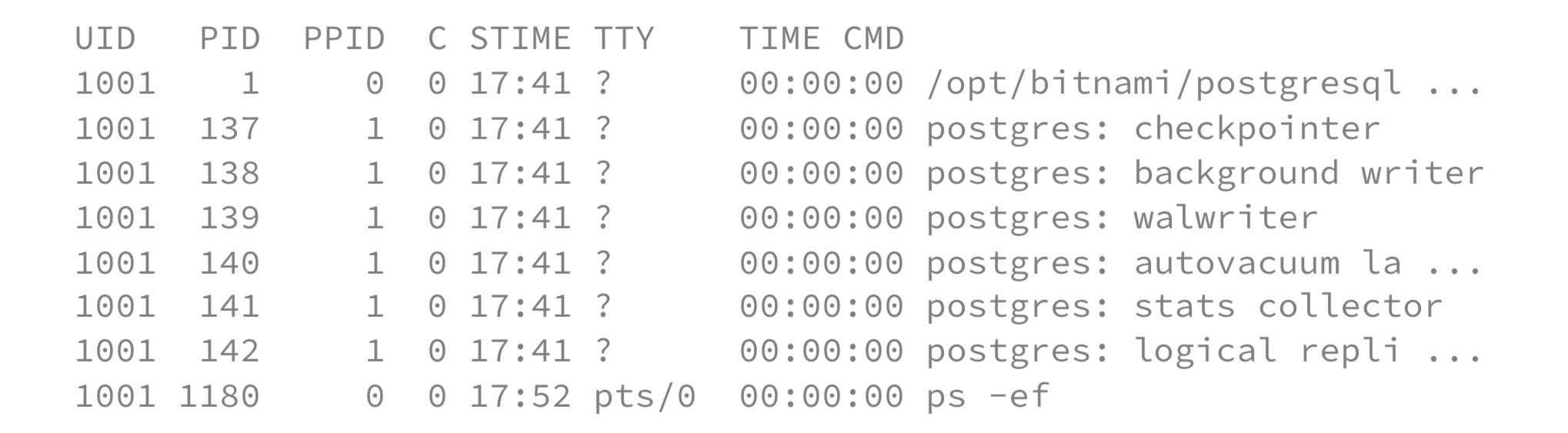
On remarque que les deux listes sont identiques : la machine hôte est donc bien en connaissance de ses namespaces enfant, on dit alors que les namespaces sont partagés.
Les conteneurs éphémères
Un conteneur éphémère est un nouveau conteneur situé au sein du même pod que le conteneur cible. Puisqu’ils sont dans le même pod, ils partagent des ressources, ce qui est idéal pour les situations délicates telles que le debug de conteneur tombant instantanément.
La commande pour créer un conteneur éphémère est la suivante :
kubectl debug \
-it \ #ouvre une invite de commande
-n <namespace_pod> \
<pod> \
--image busybox \ #image contenant de nombreux outils de debug
--target <conteneur> \ #permet de partager les PID d'un conteneur spécifique du même pod
-- /bin/sh \ #lance un shell dans l'inviteUne fois créé, le conteneur éphémère apparaît dans les specs : deux nouvelles entrées sont alors présentes dans « containers » et dans « status ».

Il est ensuite possible de lister les conteneurs éphémères actifs avec la commande suivante :
kubectl get pod -n <namespace> <pod> -o json
| jq '{"ephemeralContainers": [(.spec.ephemeralContainers[].name)], "ephemeralContainersStatuses": [(.status.ephemeralContainersStatuses[].name]}'En créant un conteneur éphémère de cette manière, on remarque que deux namespaces sont différents par rapport au conteneur original : cgroup et mnt. Cela signifie que les ressources liées à tous les autres namespaces sont partagées par le conteneur original et sa version éphémère. Ces nouveaux conteneurs permettent donc d’allier l’intégrité des ressources manipulées avec une commande exec et les outils à disposition de l’utilisateur avec une commande copy. En effet, le conteneur généré à l’aide de cette dernière commande n’aurait que des namespaces différents de ceux du conteneur original.
Le namespace mnt ne peut être partagé car certains points de montage critiques ne doivent pas être partagés. Néanmoins, si certains points de montages identiques au conteneur original sont nécessaires dans votre conteneur éphémère, il est toujours possible de les monter à la main.
Conclusion
Cette nouvelle fonctionnalité apportée à Kubernetes standardise une méthode de résolution d’erreurs de pods performante et complète, tout en répondant à de nouveaux cas de figure délicats. De plus, celle-ci facilite la démocratisation des conteneurs dits « distroless », des conteneurs plus légers ne proposant aucun outil de debug, et donc plus rapides à déployer. Les outils deviendraient alors totalement indépendants de la production, s’inscrivant dans la pensée cloud native.
