


CDP partie 3 : activation des Data Services en environnment CDP Public Cloud

27 juin 2023
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
L’un des principaux arguments de vente de Cloudera Data Platform (CDP) est la maturité de son offre de services. Ceux-ci sont faciles à déployer sur site, dans le cloud public ou dans le cadre d’une solution hybride.
L’architecture de bout en bout que nous avons présentée dans le premier article de notre série fait un usage intensif de certains de ces services :
- DataFlow est alimenté par Apache NiFi et nous permet de transporter des données d’une grande variété de sources vers une grande variété de destinations. Nous utilisons DataFlow pour ingérer des données depuis une API et les transporter vers notre Data Lake hébergé sur AWS S3.
- Le service Data Engineering s’appuie sur Apache Spark et offre des fonctionnalités puissantes pour rationaliser et rendre opérationnels les pipelines de données. Dans notre architecture, le service Data Engineering est utilisé pour exécuter des tâches Spark qui transforment nos données et chargent les résultats dans notre magasin de données analytiques, le Data Warehouse.
- Data Warehouse est une solution d’analyse en libre-service permettant aux utilisateurs professionnels d’accéder à de grandes quantités de données. Il prend en charge Apache Iceberg, un format de données moderne utilisé pour stocker les données ingérées et transformées. Enfin nos données sont exposées par la fonction Data Visualization intégrée au service Data Warehouse.
Cet article est le troisième d’une série de six :
- CDP partie 1 : introduction à l’architecture Data Lakehouse avec CDP
- CDP partie 2 : déploiement d’un environnement CDP Public Cloud sur AWS
- CDP partie 3 : activation des Data Services en environnement CDP Public Cloud
- CDP partie 4 : gestion des utilisateurs sur CDP avec Keycloak
- CDP partie 5 : gestion des permissions utilisateurs sur CDP
- CDP partie 6 : cas d’usage bout en bout d’un Data Lakehouse avec CDP
Cet article documente l’activation de ces services dans l’environnement CDP Public Cloud précédemment déployé dans Amazon Web Services (AWS). Après le processus de déploiement, nous fournissons une liste de ressources que CDP crée sur votre compte AWS et une estimation approximative des coûts. Assurez-vous que votre environnement et votre Data Lake sont entièrement déployés et disponibles avant de poursuivre.
Tout d’abord, deux remarques importantes :
- Ce déploiement est basé sur les recommandations de démarrage rapide (quickstart) de Cloudera pour DataFlow, Data Engineering et Data Warehouse. Il vise à vous fournir un environnement fonctionnel aussi rapidement que possible, mais n’est pas optimisé pour une utilisation en production.
- Les ressources créées sur votre compte AWS lors de ce déploiement ne sont pas gratuites. Vous allez encourir des frais. Chaque fois que vous vous entraînez avec des solutions basées sur le cloud, n’oubliez pas de supprimer vos ressources lorsque vous avez terminé afin d’éviter tout coût indésirable.
Ceci étant dit, mettons-nous en route. Les services CDP Public Cloud sont activés depuis la console Cloudera ou le CDP CLI, en supposant que vous l’ayez installé comme décrit dans la première partie de la série. Les deux approches sont couvertes : Nous commençons par déployer les services depuis la console et fournissons ensuite les commandes CLI dans la section Ajouter des services depuis votre terminal ci-dessous.
Utilisation de la console pour ajouter des services
Cette approche est recommandée si vous êtes novice en matière de plateforme CDP et/ou AWS. Elle est plus lente mais vous donne une meilleure idée des différentes étapes du processus de déploiement. Si vous n’avez pas installé et configuré la CLI CDP et la CLI AWS, c’est votre seule option.
Activation de DataFlow
Le premier service que nous ajoutons à notre infrastructure est DataFlow :
-
Pour commencer, accédez à la console Cloudera et sélectionnez DataFlow :
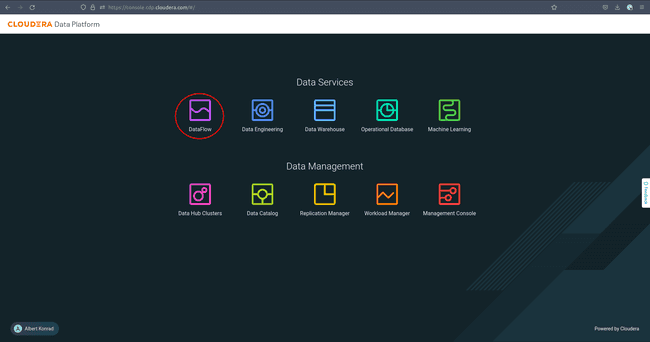
-
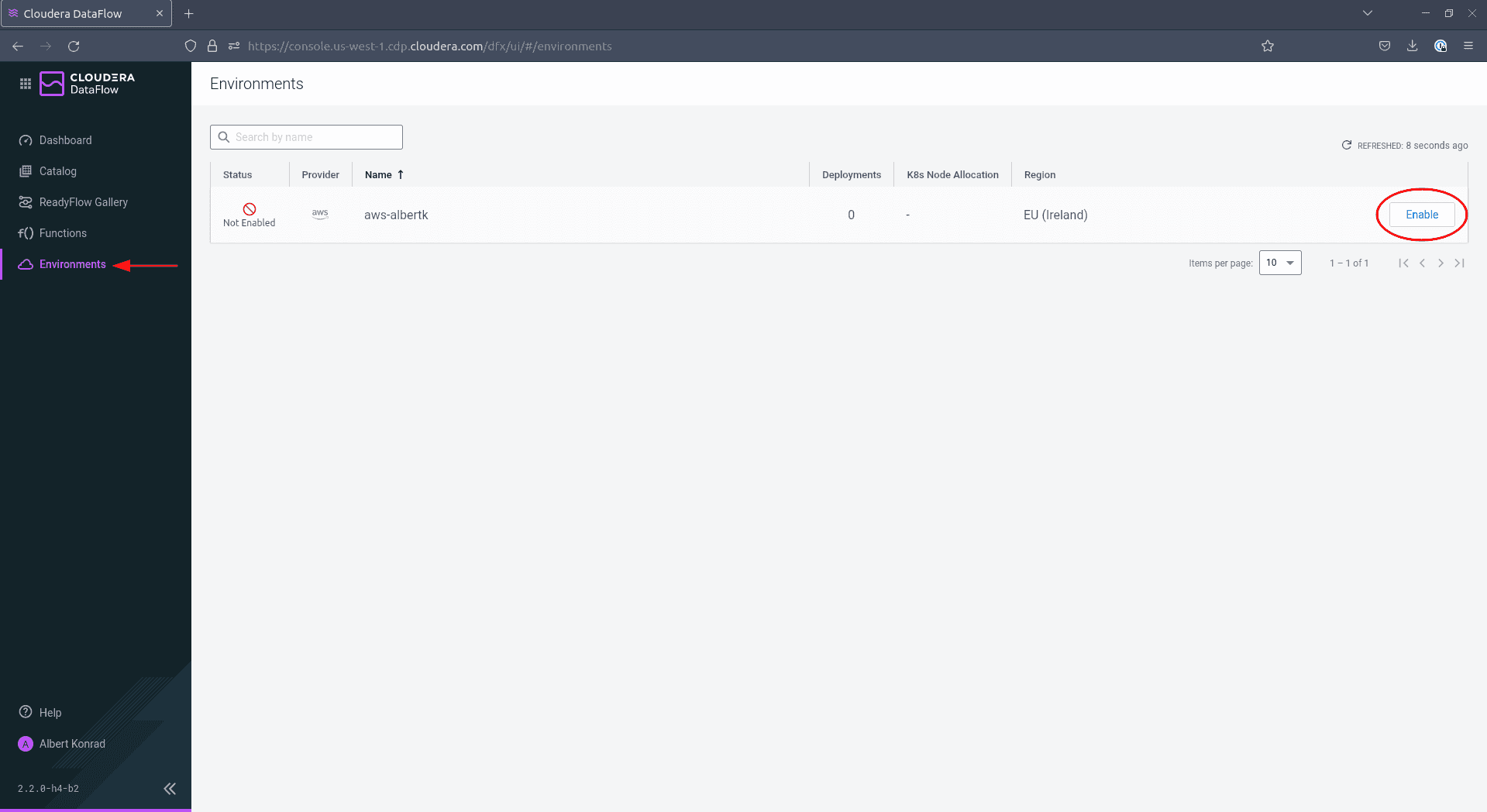
Naviguez jusqu’à Environments et cliquez sur Enable à côté de votre environnement :
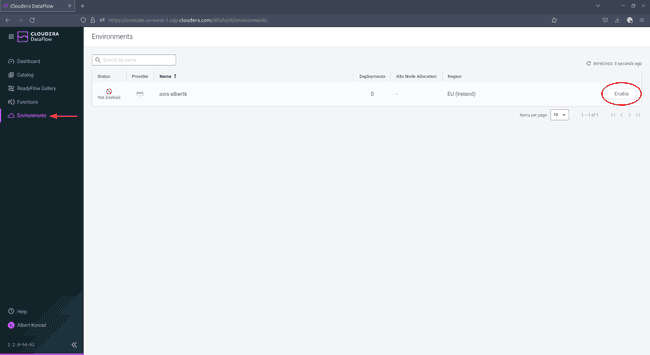
-
Sur l’écran de configuration, assurez-vous de cocher la case à côté de
Enable Public Endpoint. Cela vous permet de configurer votre DataFlow depuis l’interface web fournie sans autre configuration à faire. Laissez les autres paramètres à leurs valeurs par défaut. L’ajout de tags est facultatif mais recommandé. Lorsque vous avez terminé, cliquez sur Enable.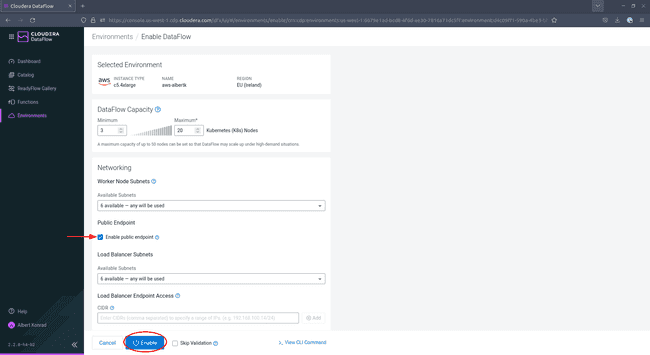
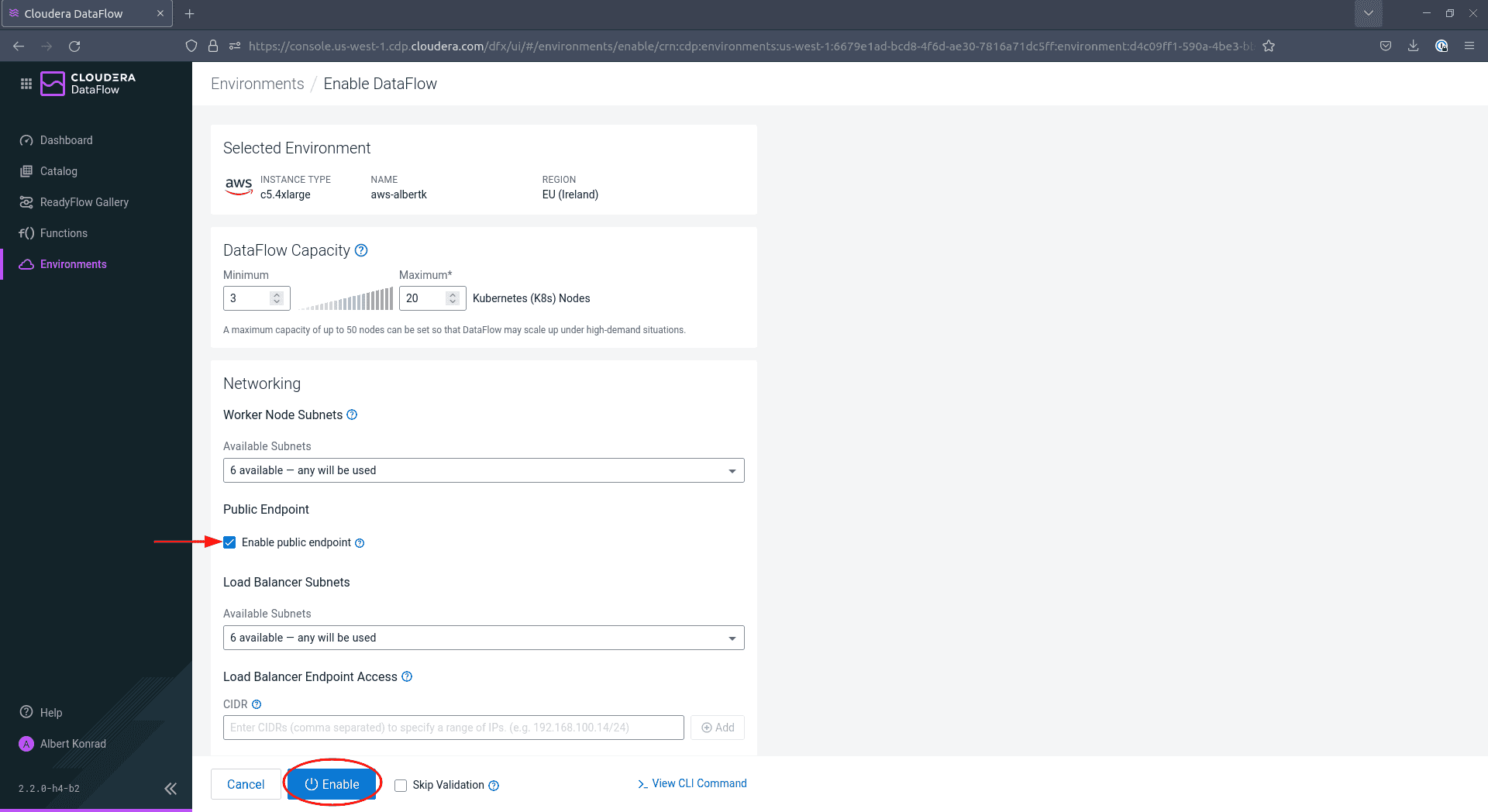
Après 45 à 60 minutes, le service DataFlow est activé.
Activer Data Engineering
Le prochain service à activer pour notre environnement est Data Engineering :
-
Accédez à la console Cloudera et sélectionnez Data Engineering :
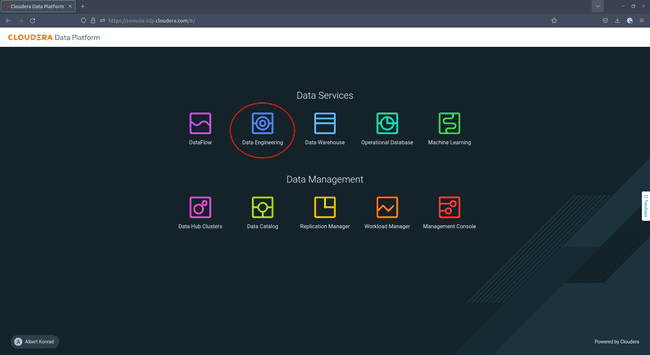
-
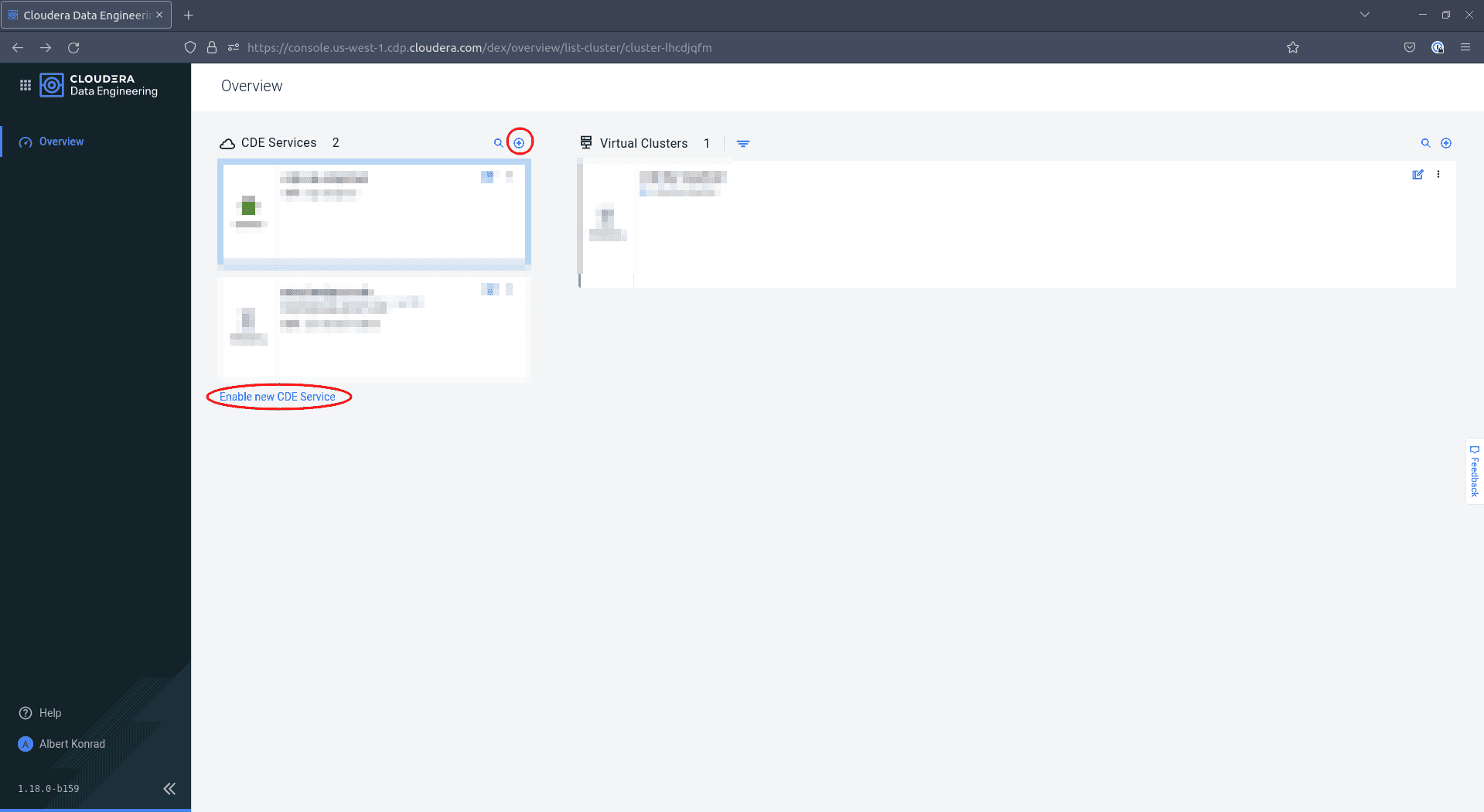
Cliquez soit sur la petite icône ’+’, soit sur Enable new CDE Service :
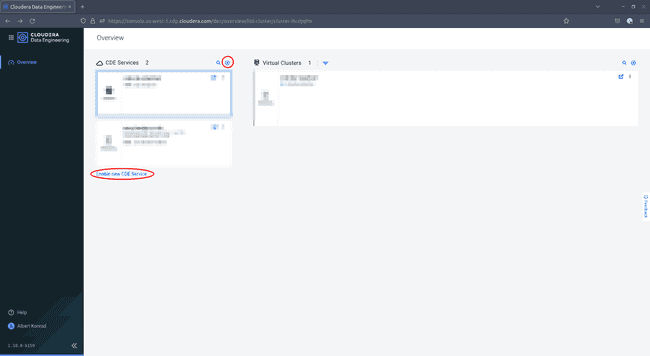
-
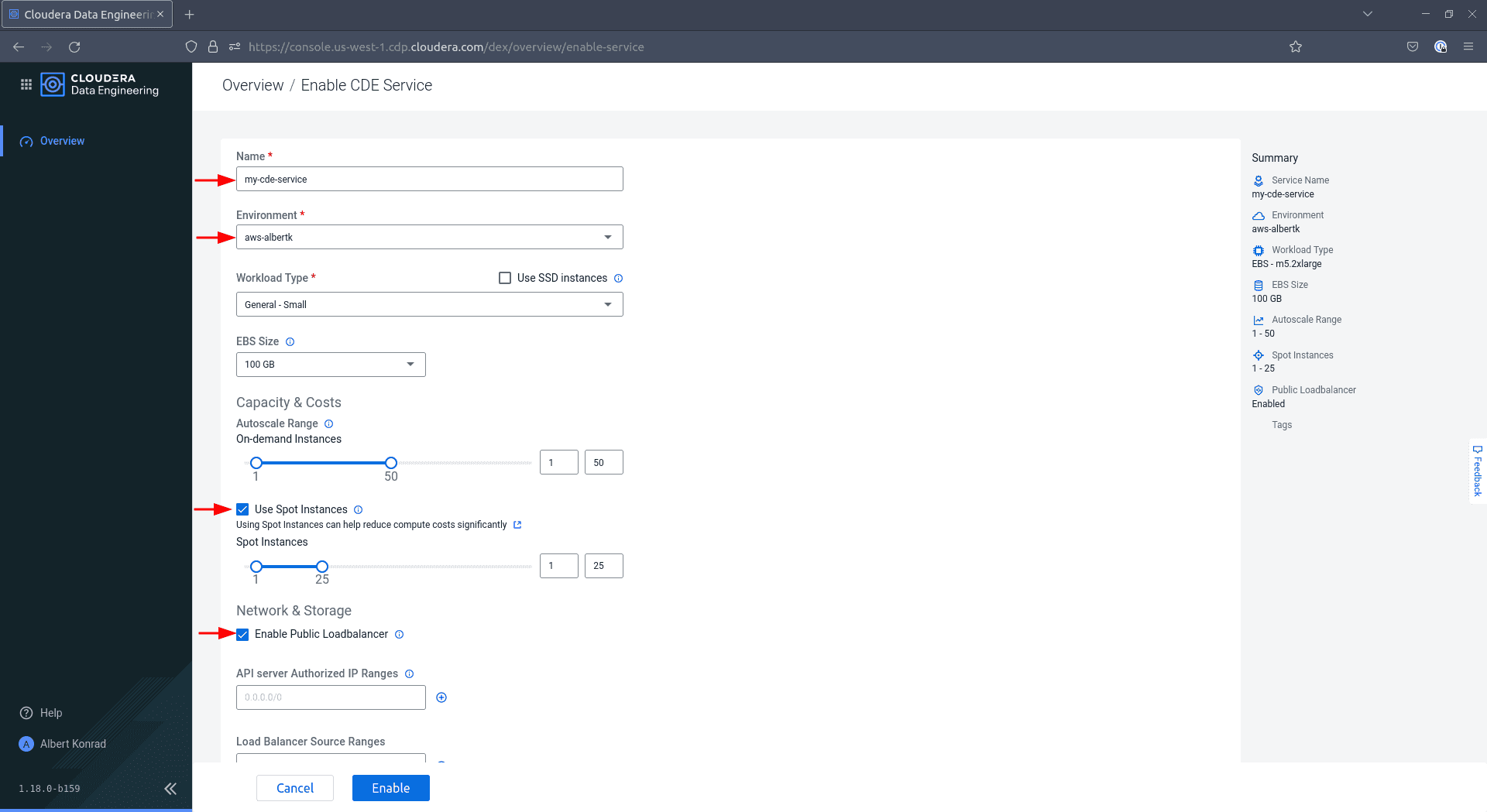
Dans la boîte de dialogue Enable CDP Service, donnez un nom à votre service et choisissez votre environnement CDP dans la liste déroulante. Sélectionnez un type de charge de travail et une taille de stockage. Pour les besoins de cette démo, la sélection par défaut
General - Smallet100 GBest suffisante. CochezUse Spot InstancesetEnable Public Load Balancer.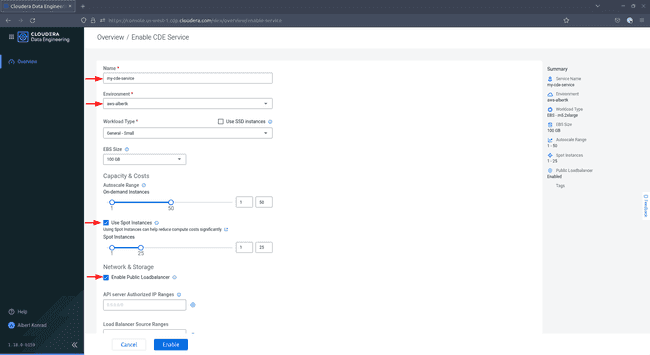
-
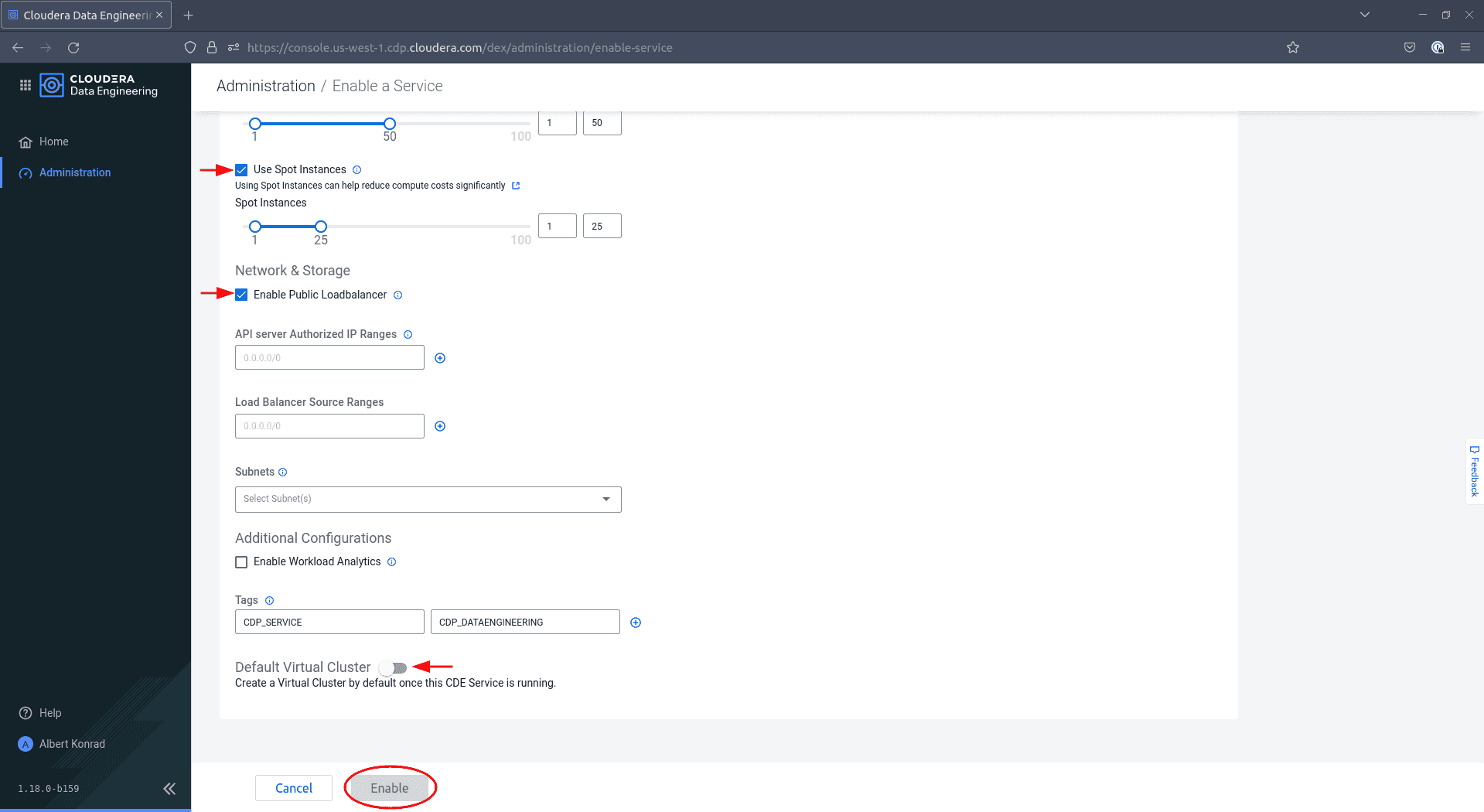
Faites défiler vers le bas, ajoutez éventuellement des tags et désactivez l’option
Default VirtualCluster, puis cliquez sur Enable.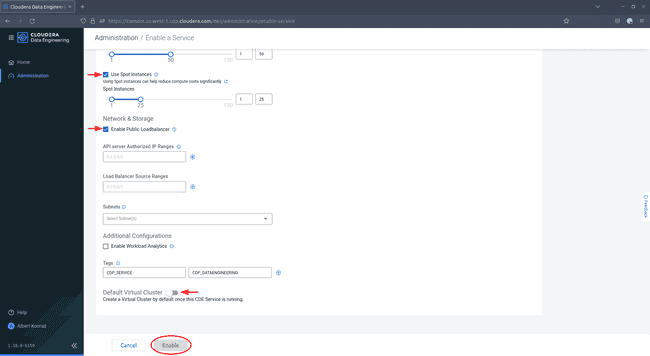
Après 60 à 90 minutes, le service Data Engineering est activé. L’étape suivante est la création d’un cluster virtuel pour soumettre des charges de travail.
-
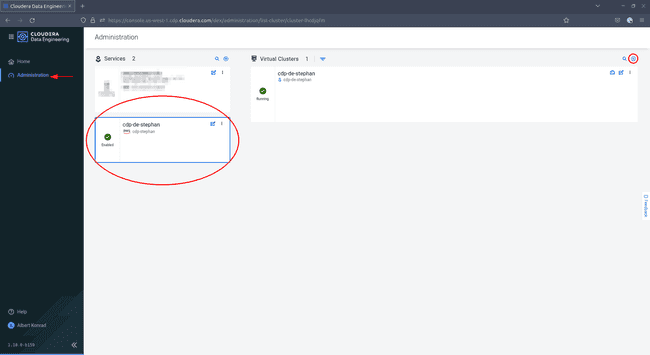
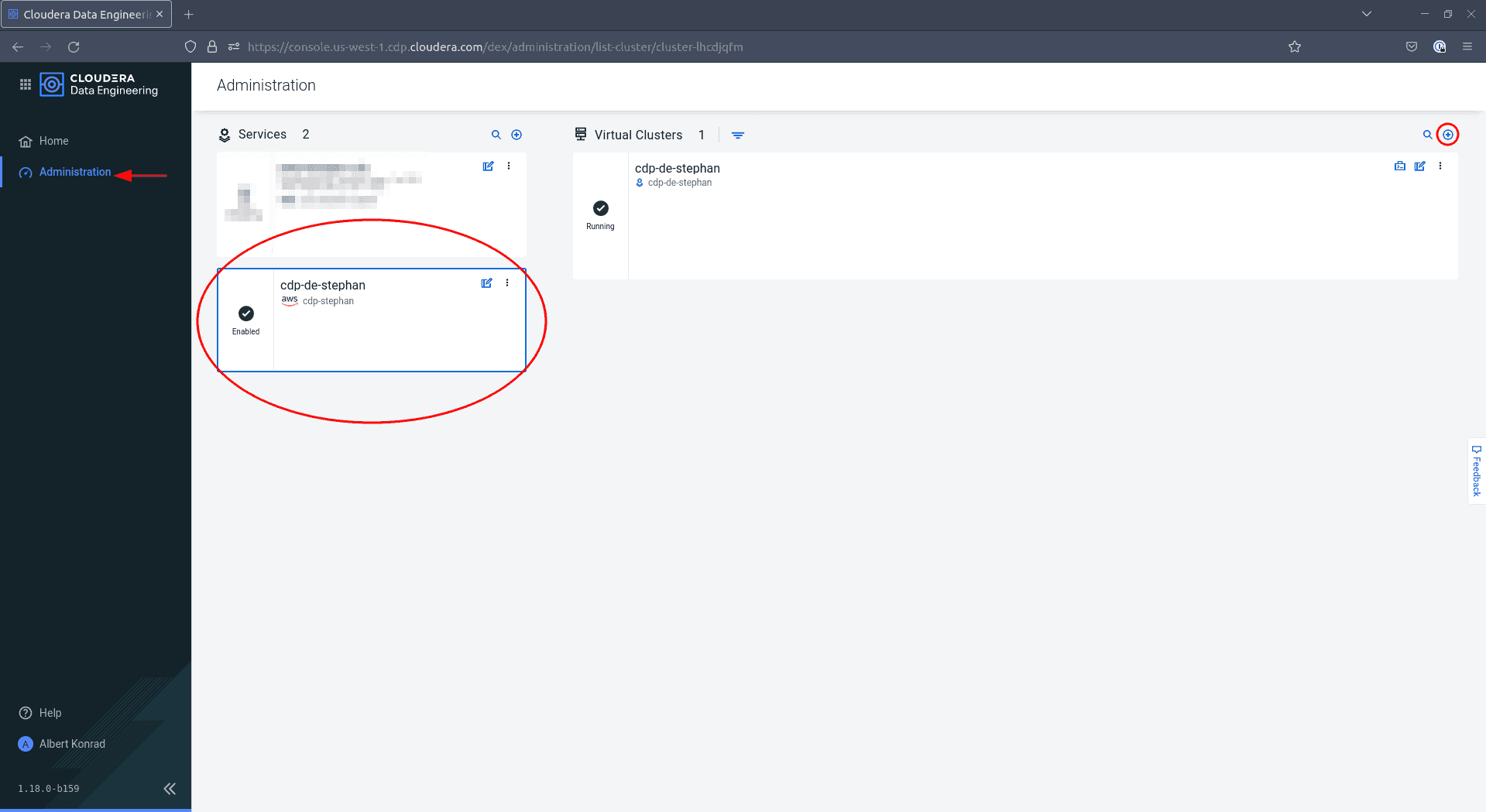
Naviguez à nouveau vers le service Data Engineering. Vous pouvez remarquer que le menu de navigation sur la gauche a changé. Sélectionnez Administration, puis sélectionnez votre environnement et cliquez sur l’icône ’+’ en haut à droite pour ajouter un nouveau cluster virtuel :
-
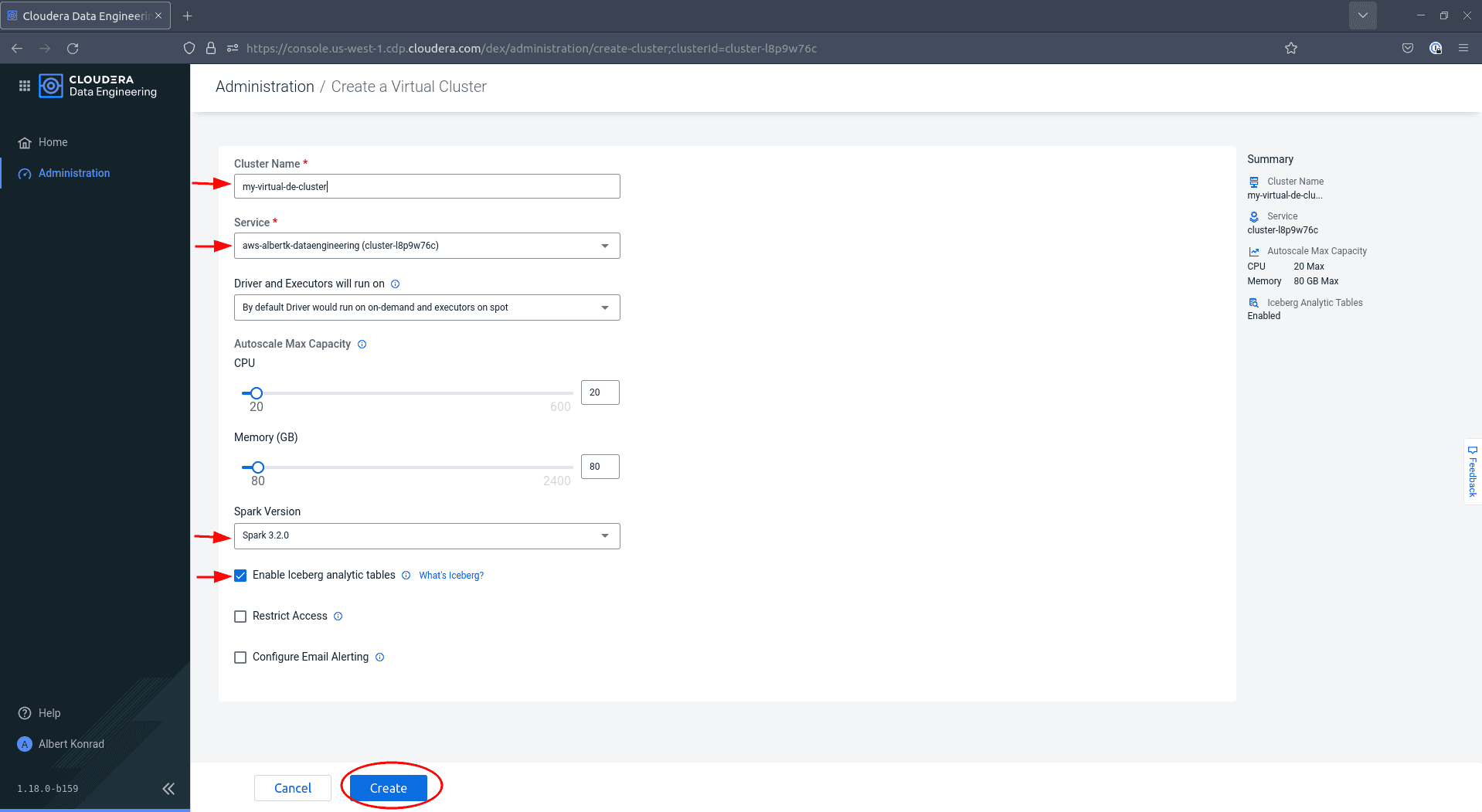
Dans la boîte de dialogue Create a Virtual Cluster, donnez un nom à votre cluster et assurez-vous que le bon service est sélectionné. Choisissez la version de Spark
3.x.xet cochez la case à côté deEnable Iceberg analytics tables, puis cliquez sur Create :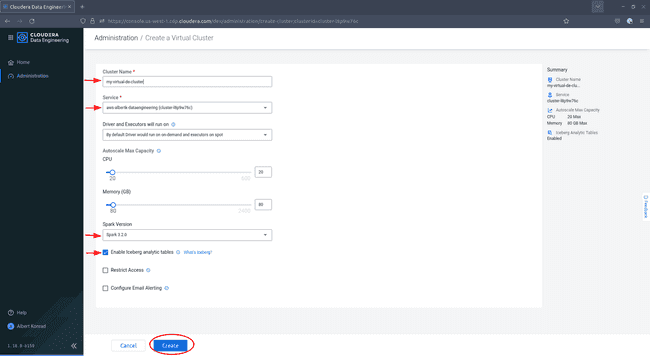
Votre service Data Engineering sera entièrement disponible une fois que votre cluster virtuel aura été lancé.
Activer Data Warehouse
Le dernier service que nous activons pour notre environnement est le Data Warehouse, l’outil d’analyse dans lequel les données traitées sont stockées et exposées à l’utilisateur.
-
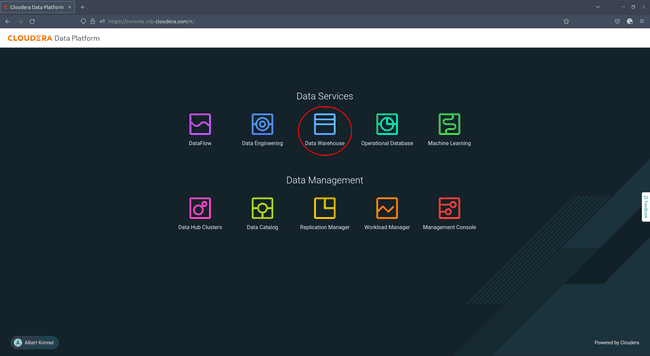
Pour commencer, accédez à votre console Cloudera et naviguez jusqu’à Data Warehouse :
-
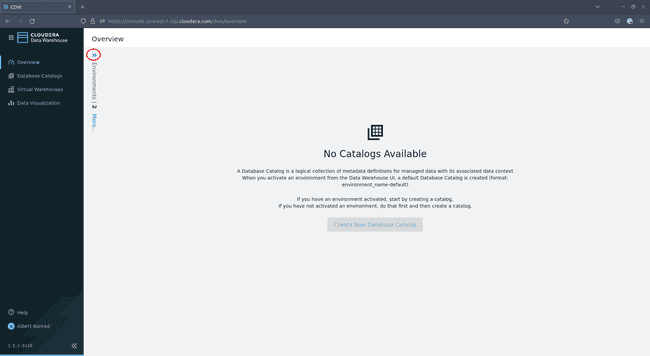
Dans l’écran de présentation de Data Warehouse, cliquez sur les petites flèches bleus en haut à gauche :
-
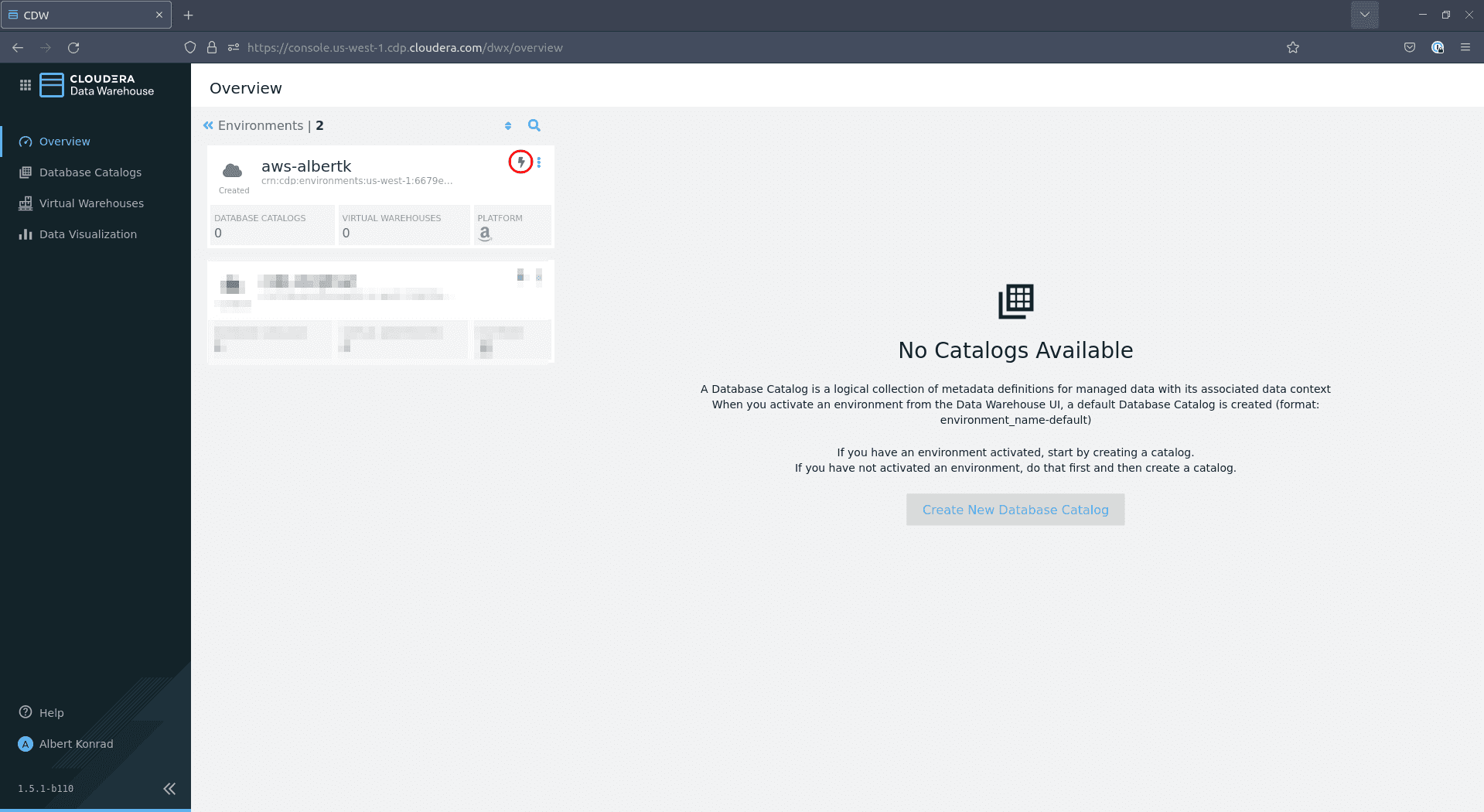
Dans le menu qui s’ouvre, sélectionnez votre environnement et cliquez sur la petite icône verte en forme d’éclair :
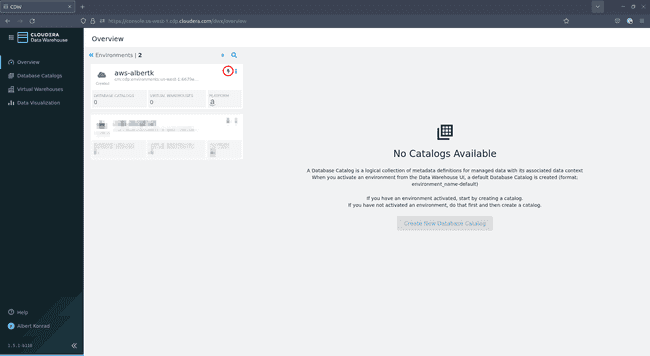
-
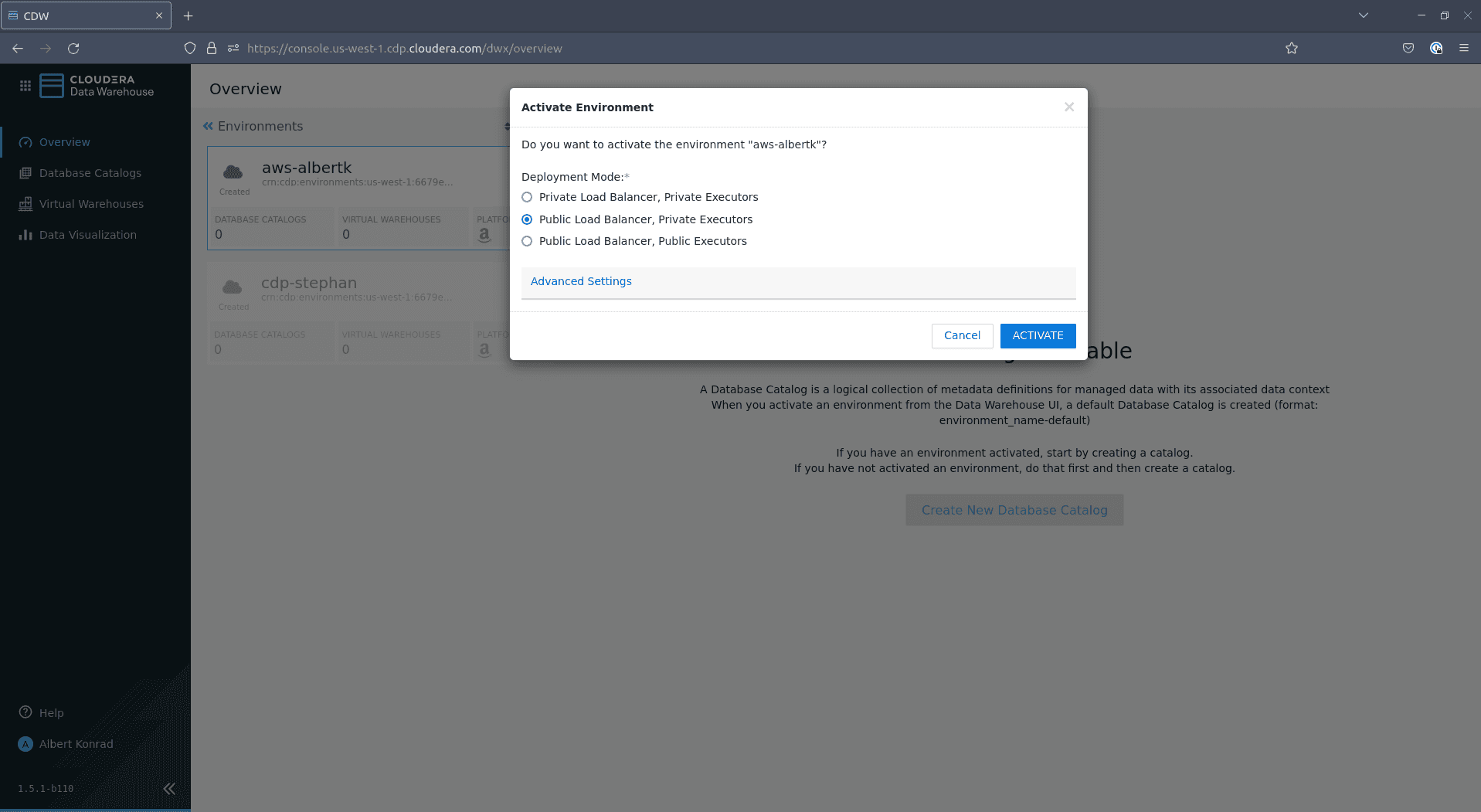
Dans la boîte de dialogue d’activation, sélectionnez
Public Load Balancer, Private Executorset cliquez sur ACTIVATE :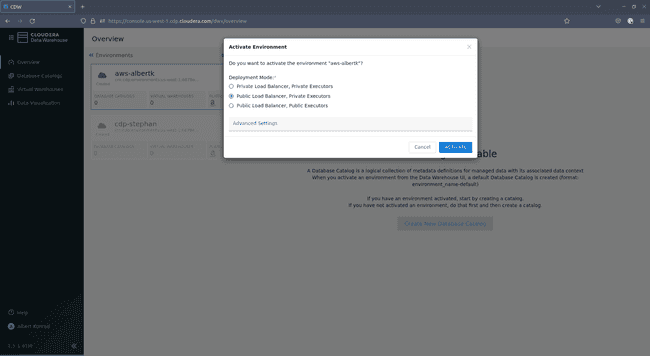
Vous lancez maintenant votre service Data Warehouse. Cela devrait prendre environ 20 minutes. Une fois lancé, activez un virtual warehouse pour héberger les charges de travail :
-
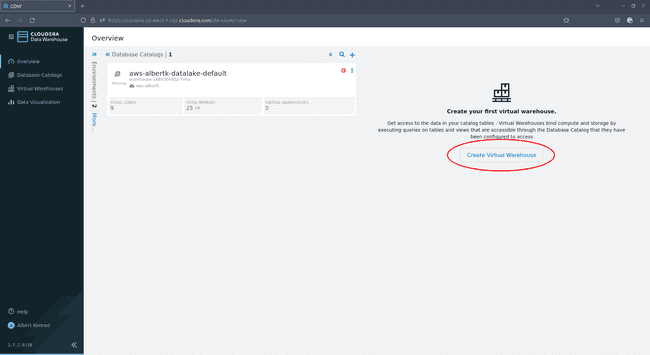
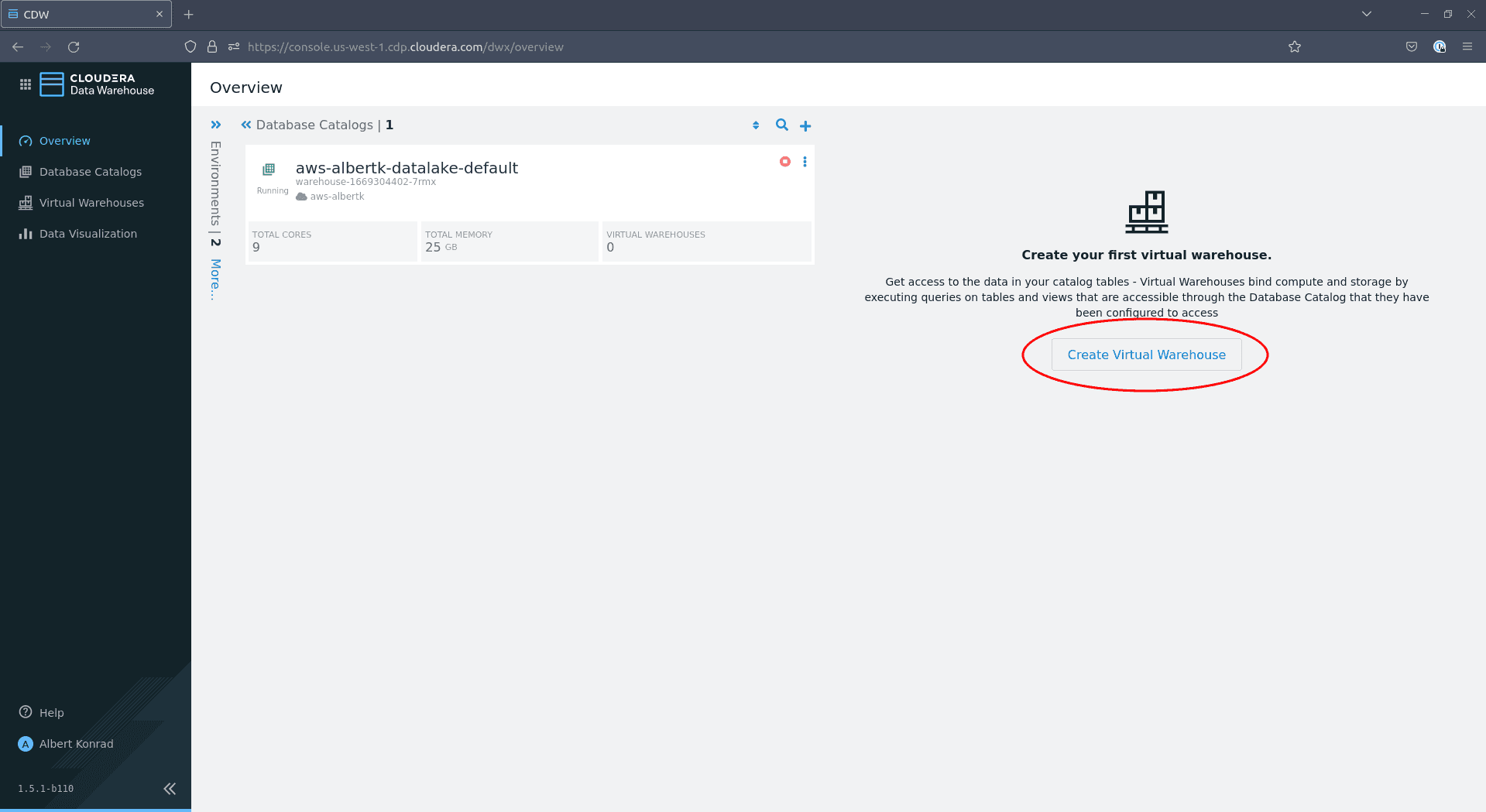
Revenez à l’écran d’aperçu du Data Warehouse et cliquez sur Create Virtual Warehouse :
-
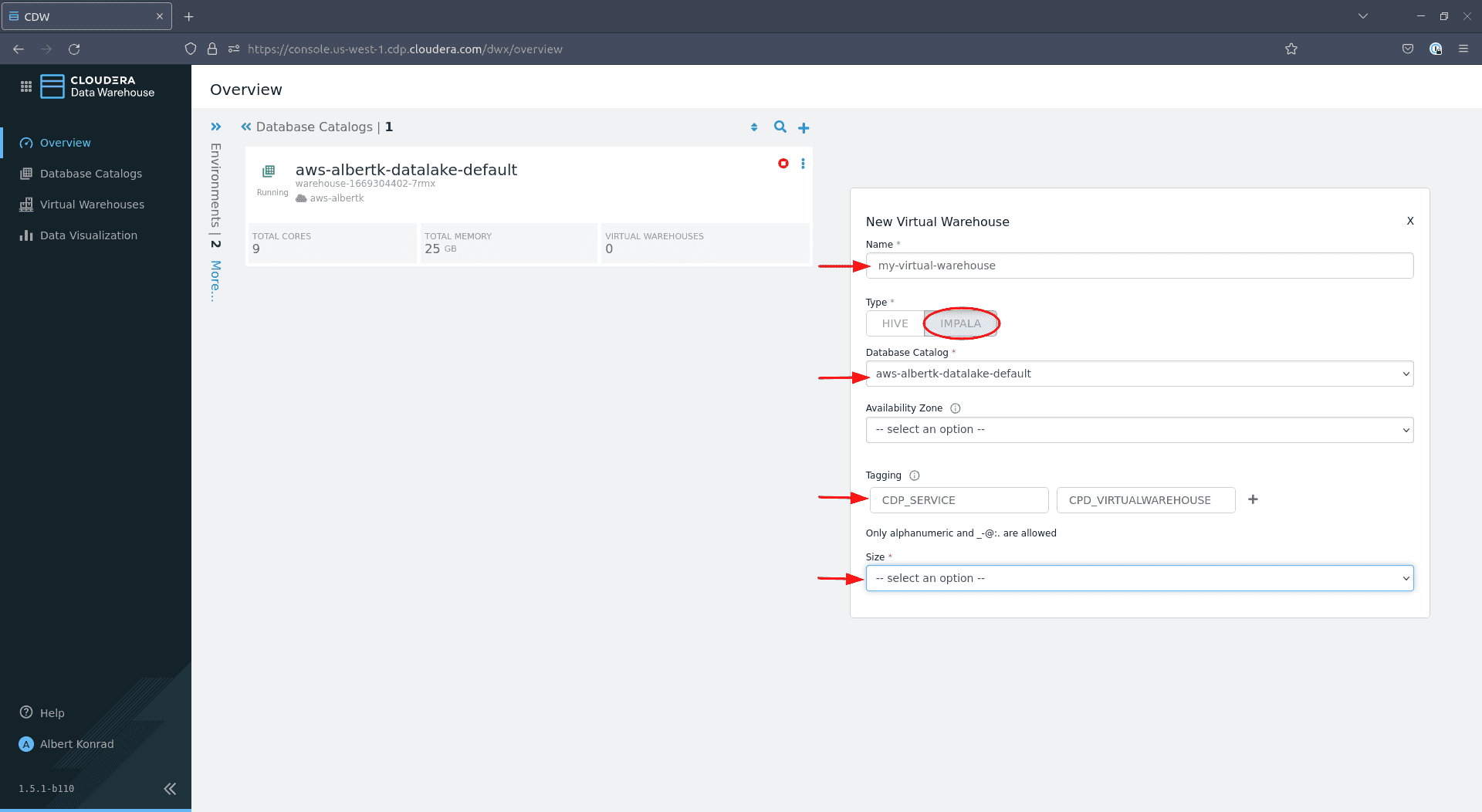
Dans la boîte de dialogue qui s’ouvre, donnez un nom au virtual warehouse. Sélectionnez
Impala, laissez le choix par défault pour Database Catalog, les tags sont facultatifs et dans Size choisissez la taille :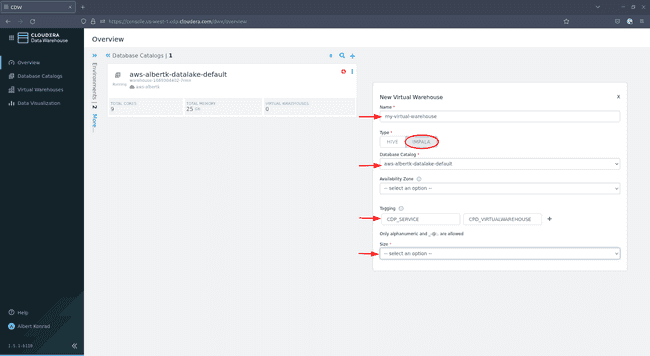
-
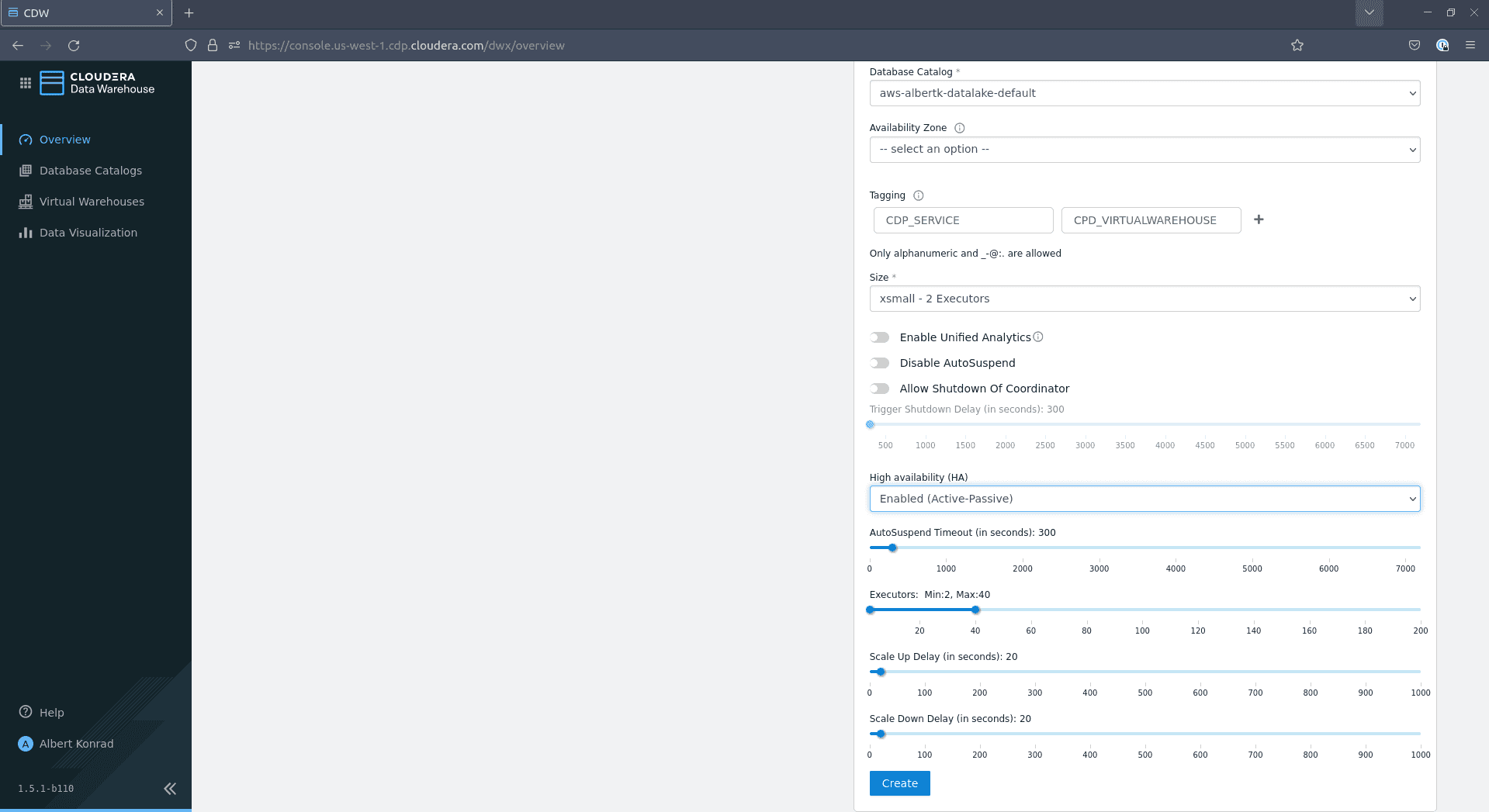
Si vous souhaitez juste tester l’infrastructure,
xsmall - 2 executorssera suffisant. La taille de votre data warehouse peut nécessiter quelques ajustements si vous prévoyez de prendre en charge plusieurs utilisateurs simultanés. Laissez les paramètres par défaut pour les autres options et cliquez sur Create :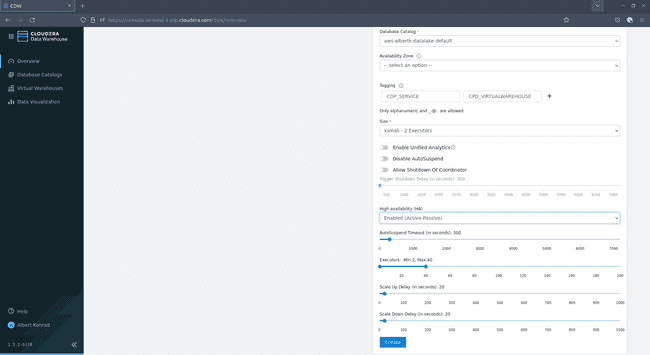
La dernière fonctionnalité que nous activons pour notre data warehouse est Data Visualization. Pour ce faire, nous devons d’abord créer un groupe d’utilisateurs Administrateur :
-
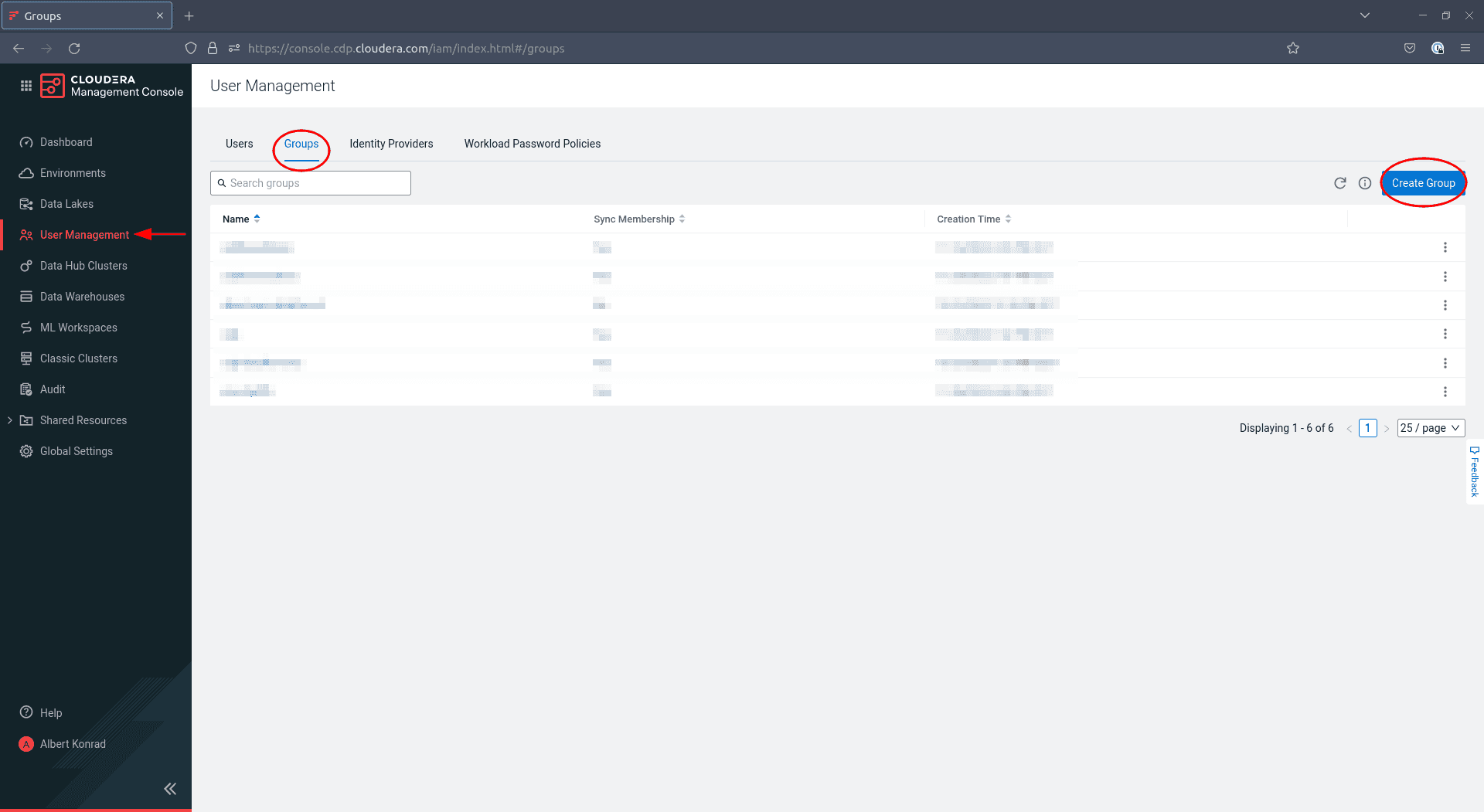
Naviguez vers Management Console > User Management et cliquez sur Create Group :
-
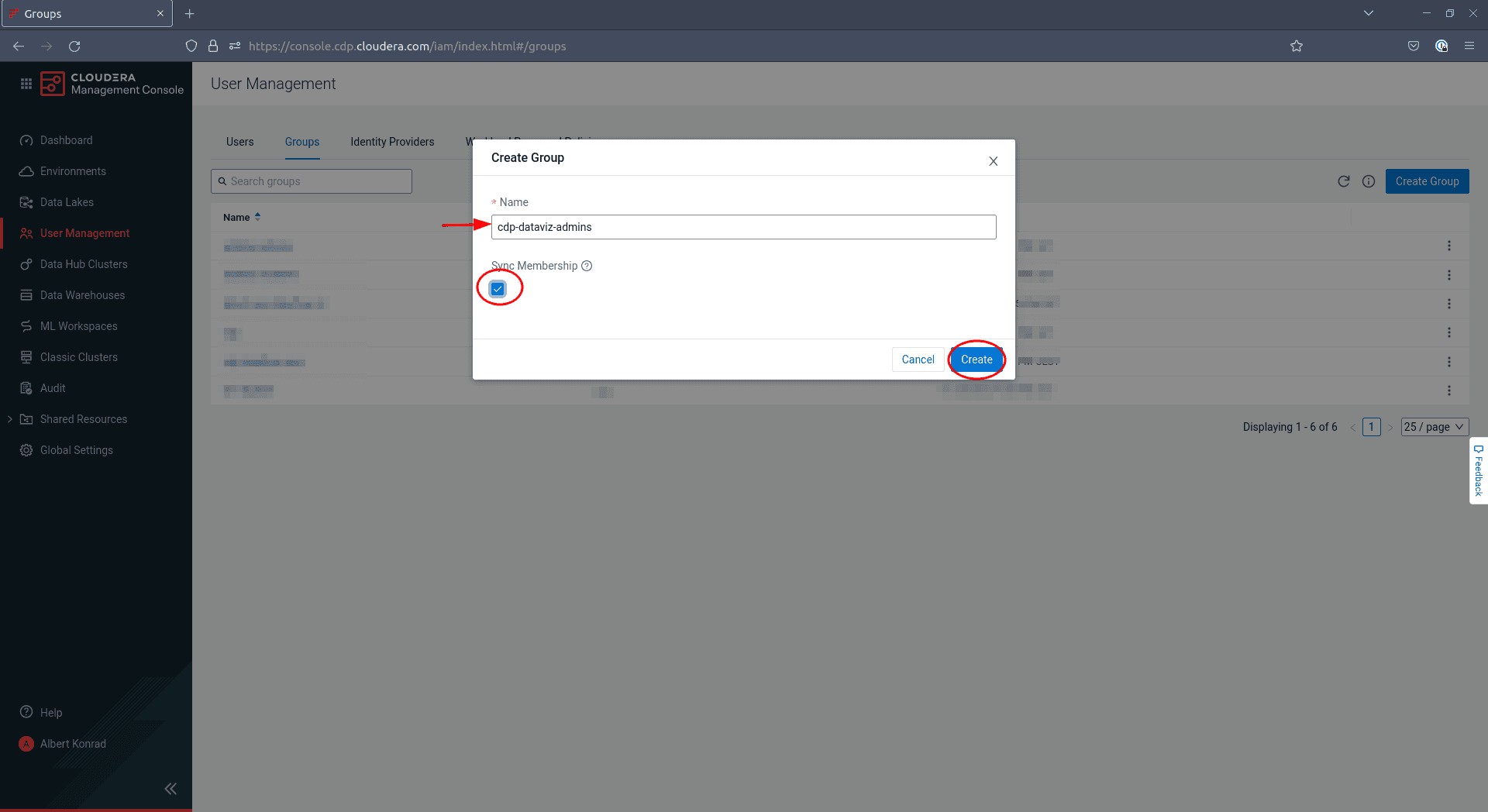
Dans la boîte de dialogue qui s’ouvre, saisissez un nom pour votre groupe et cochez la case
Sync Membership:
-
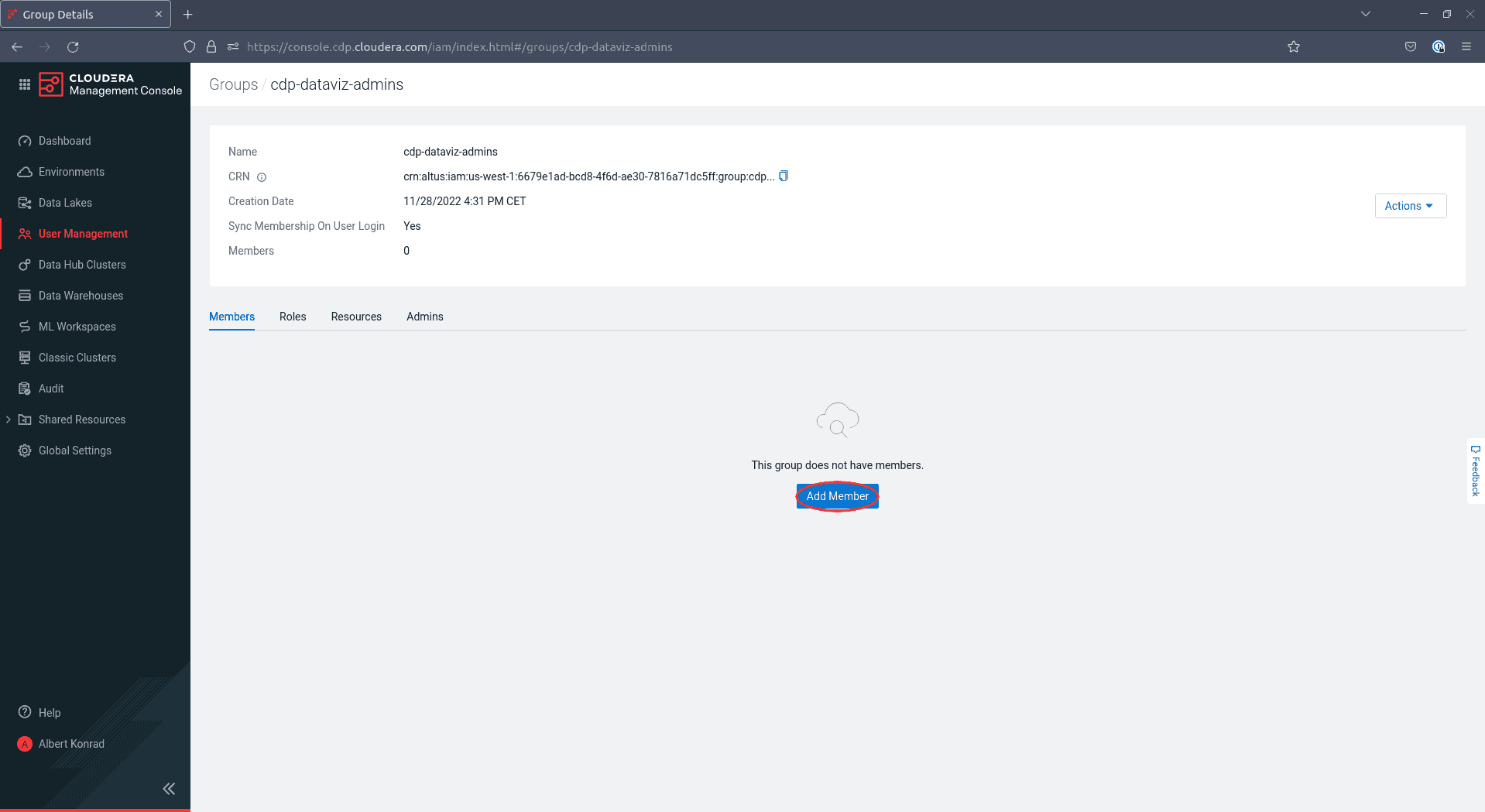
Sur l’écran suivant, cliquez sur Add Member :
-
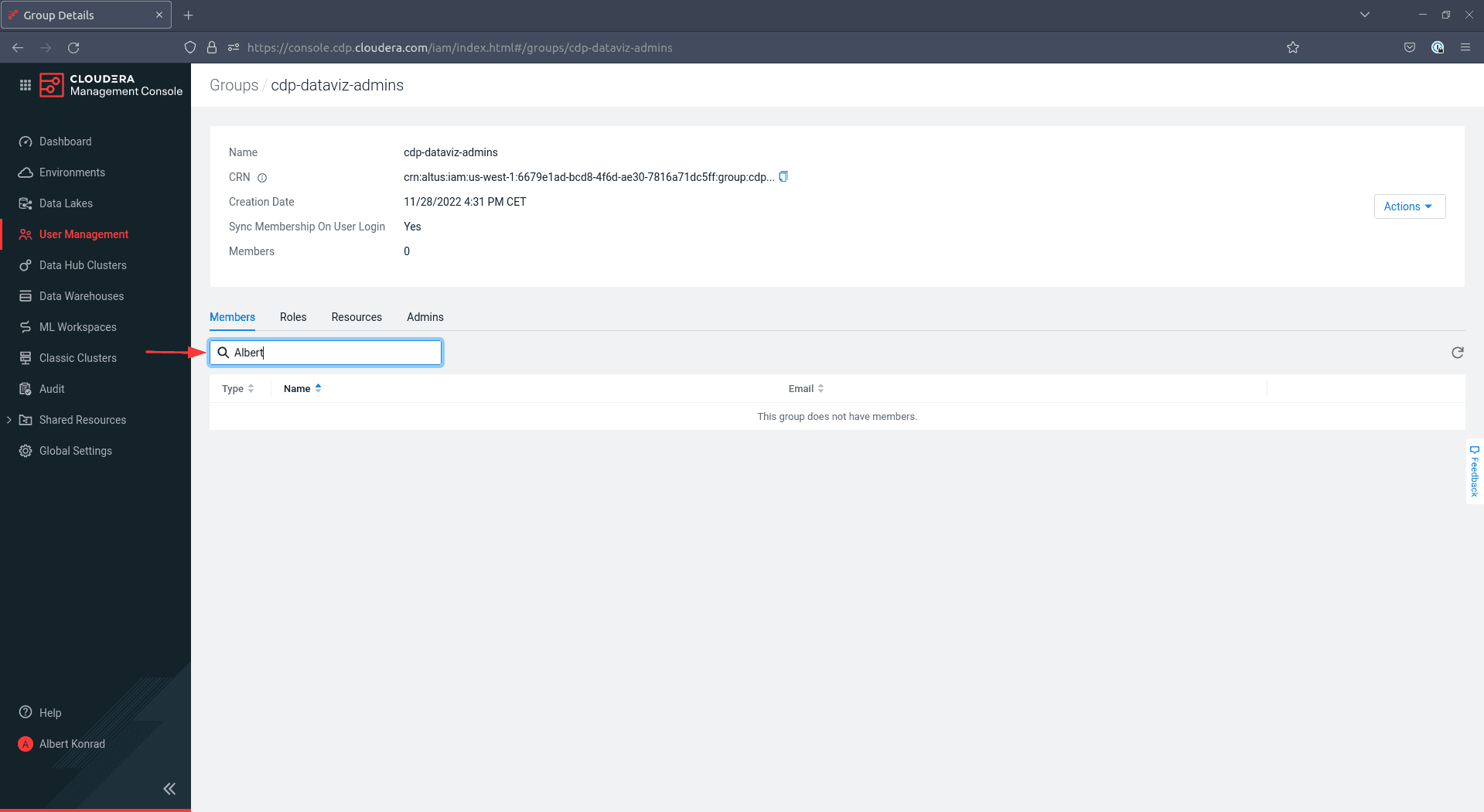
Sur l’écran suivant, entrez les noms des utilisateurs existants que vous voulez ajouter dans le champ de texte sur le côté gauche. Ajoutez au moins vous-même à ce groupe :
-
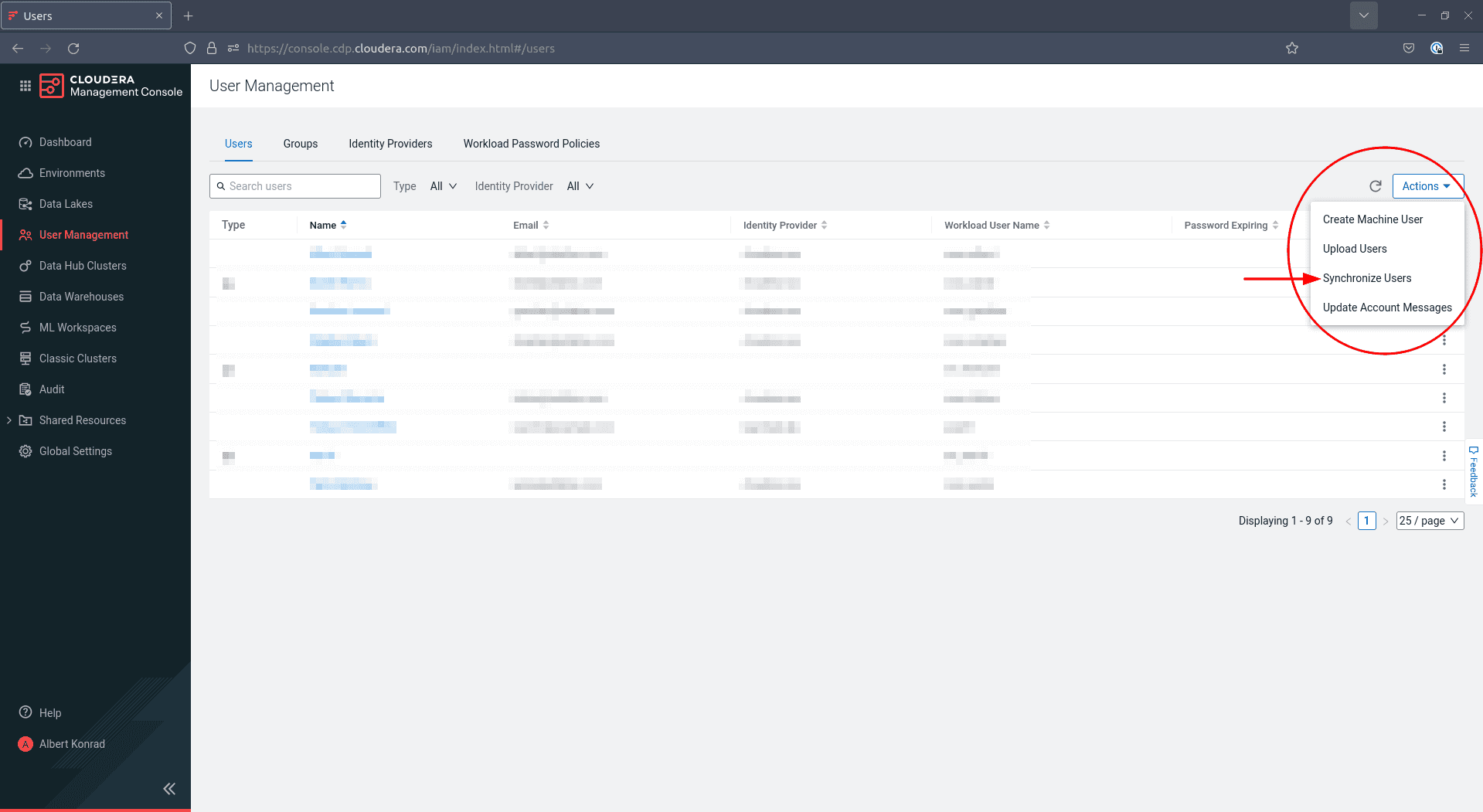
Pour terminer la création de votre groupe d’administrateurs, retournez dans User Management et cliquez sur Actions sur la droite, puis sélectionnez Synchronize Users :
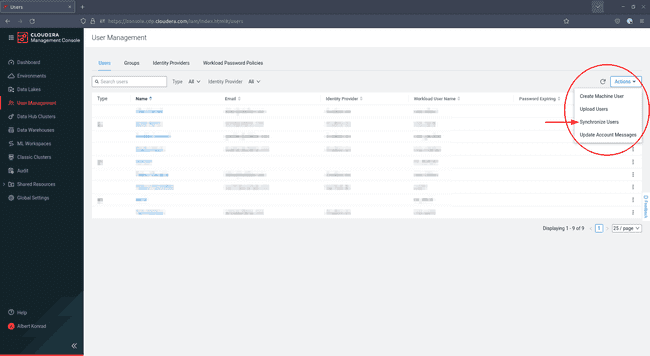
-
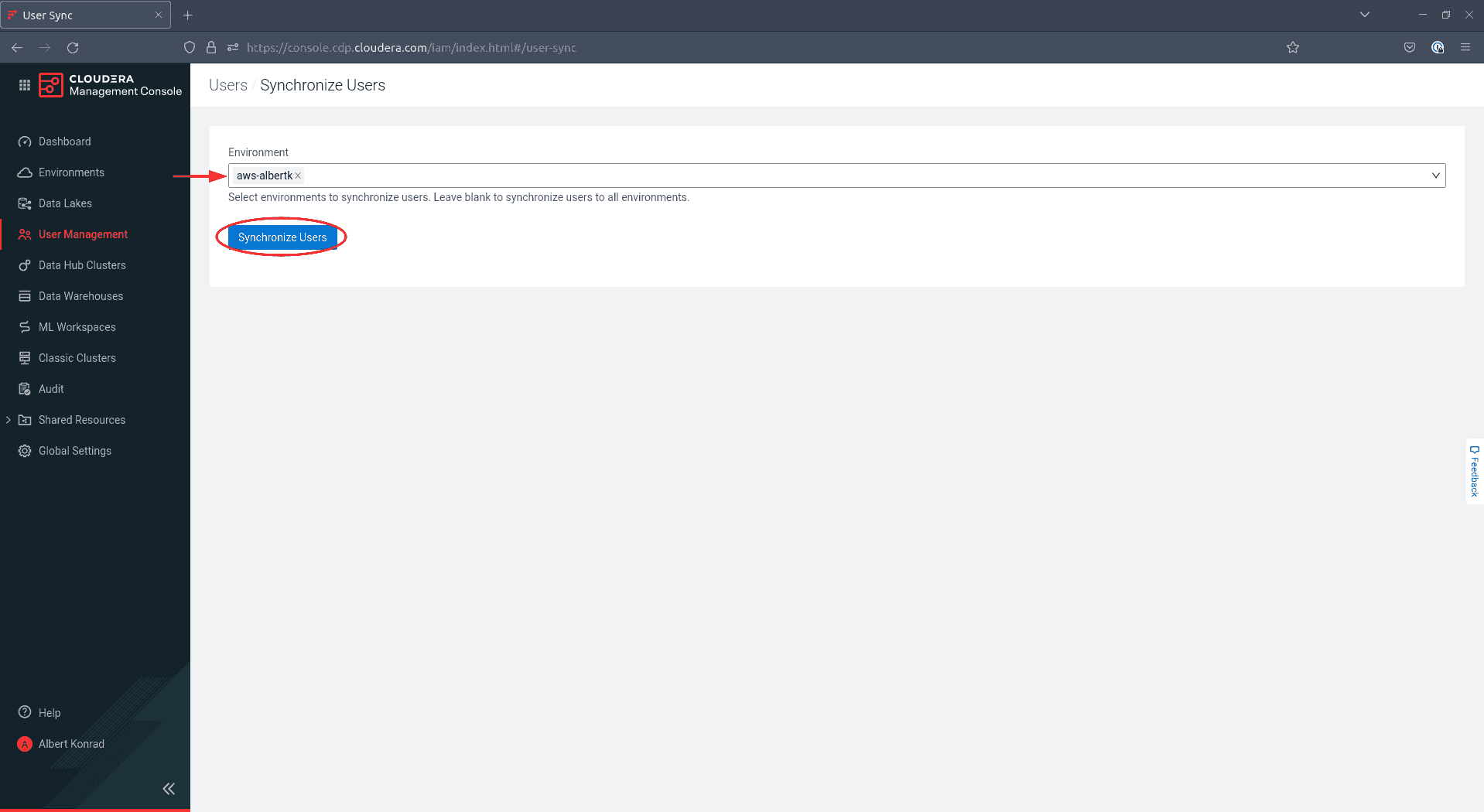
Sur l’écran suivant, sélectionnez votre environnement et cliquez sur Synchronize Users :
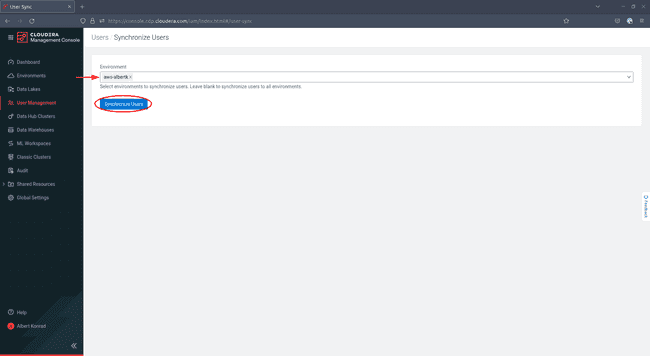
-
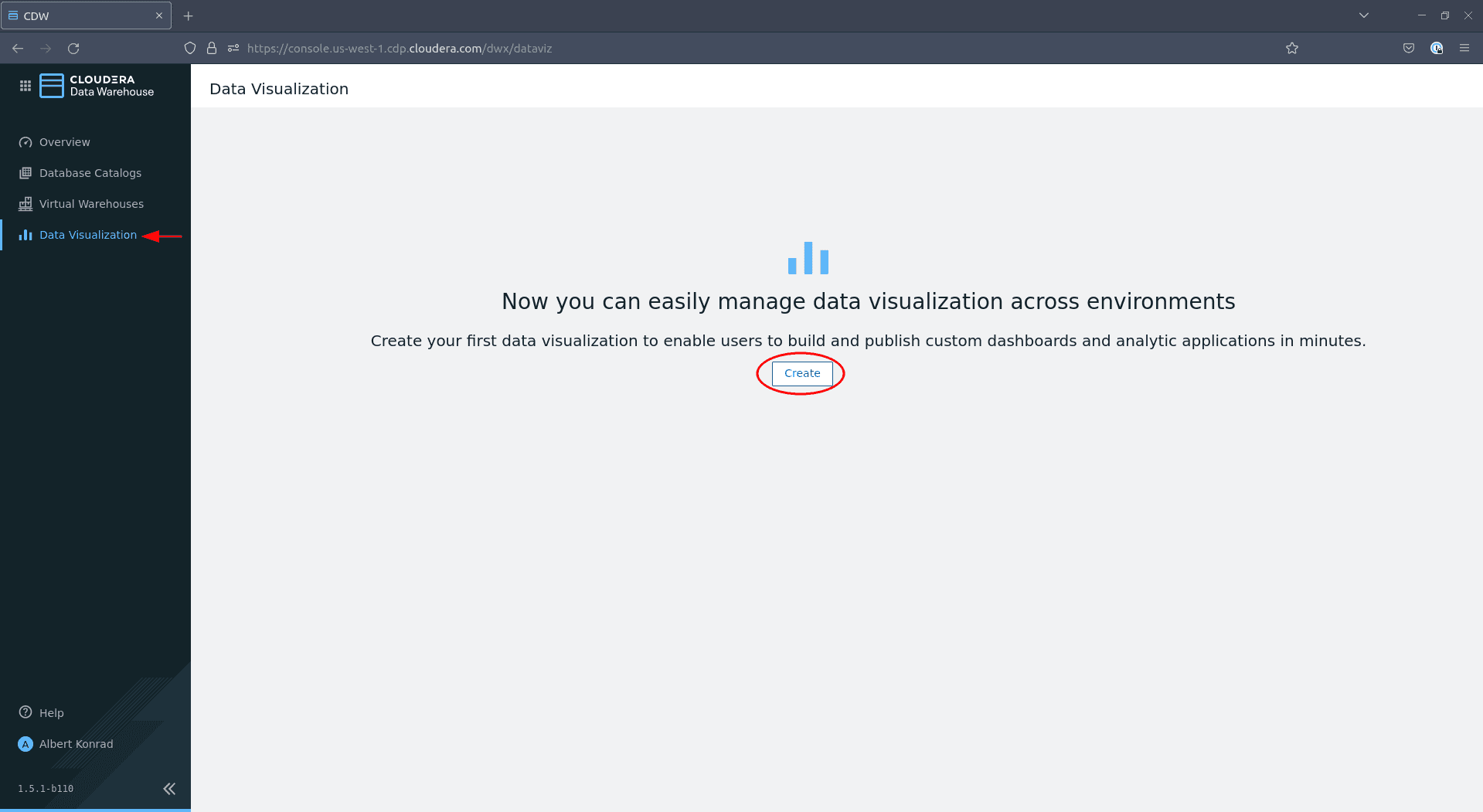
Lorsque le groupe d’administrateurs est créé et synchronisé, accédez à Data Warehouse > Data Visualization et cliquez sur Create :
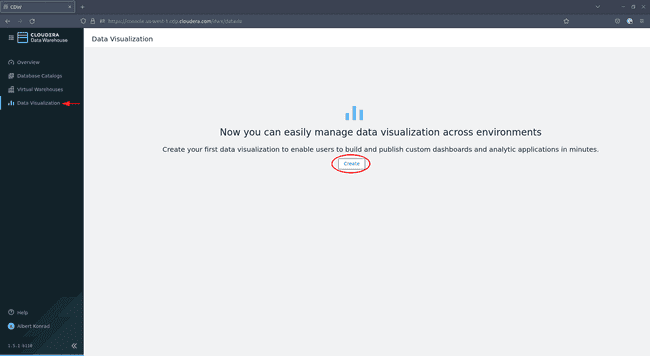
-
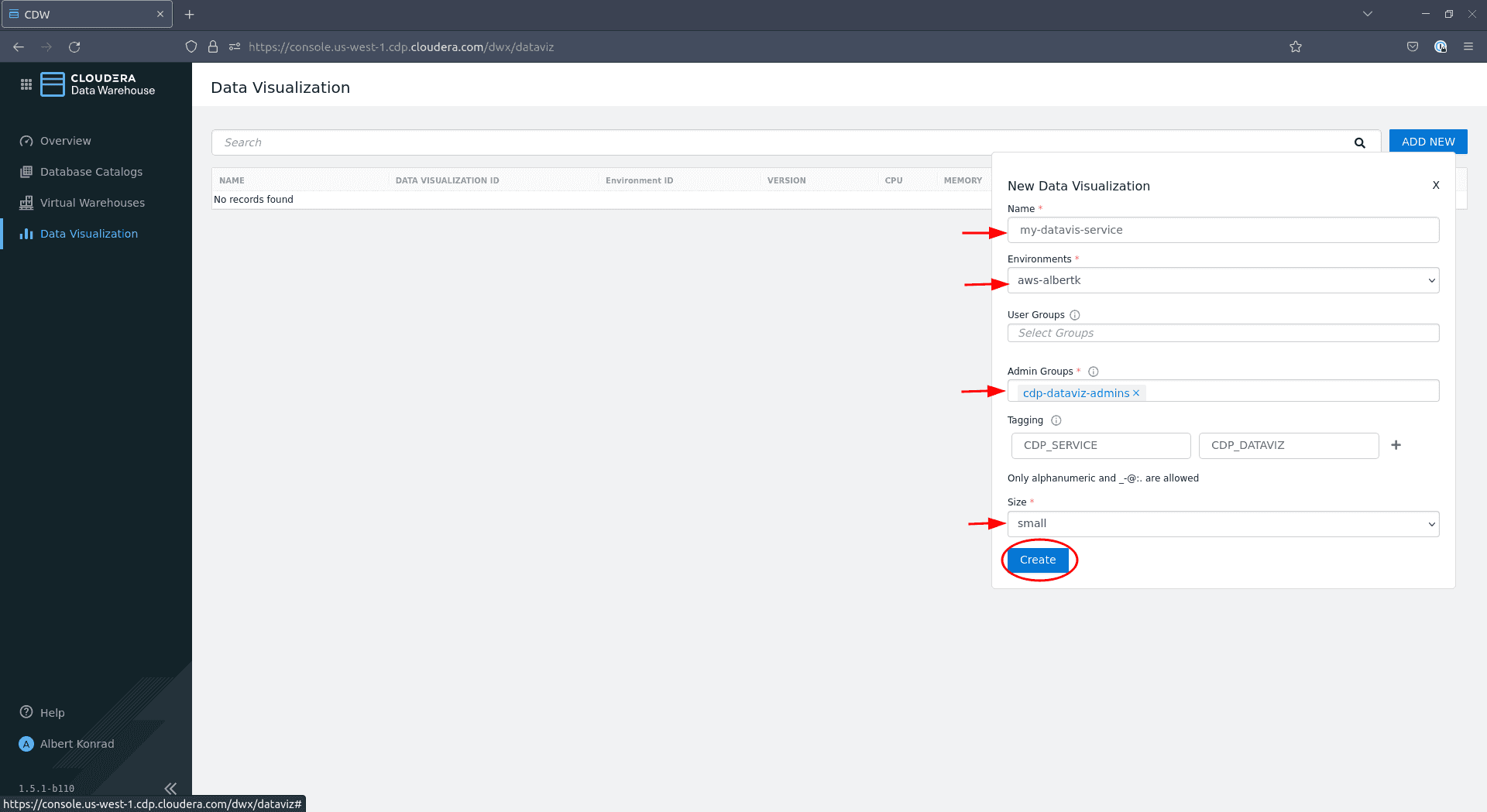
Dans la boîte de dialogue de configuration, donnez un nom à votre service Data Visualization et assurez-vous que l’environnement adéquat est sélectionné. Laissez User Groups vide pour le moment. Sous Admin Groups, sélectionnez le groupe d’administrateurs que nous venons de créer. Ajoutez éventuellement des tags et sélectionnez une taille (
smallest suffisant pour les besoins de cette démo), puis cliquez sur Create :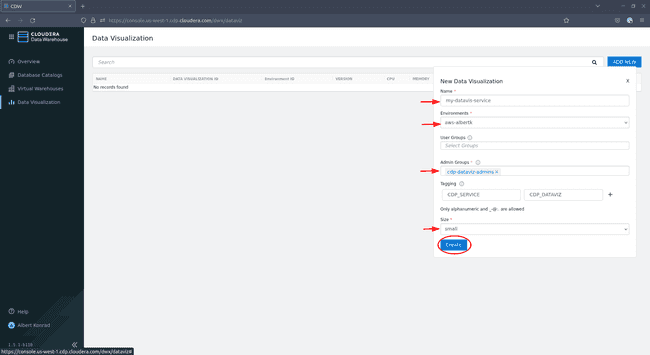
Et c’est tout ! Vous avez maintenant activé le service Data Warehouse sur votre environnement avec toutes les fonctionnalités requises pour déployer notre architecture. Notez que nous devons encore ajouter quelques utilisateurs à notre service Data Visualization, ce que nous allons couvrir dans un autre article.
Ajouter des services depuis votre terminal
Vous pouvez activer tous les services (cependant avec une certaine limitation décrite ci-dessous) depuis votre terminal en utilisant le CDP CLI. Cette approche est préférable pour les utilisateurs expérimentés qui veulent être en mesure de créer rapidement un environnement.
Avant de commencer à déployer les services, assurez-vous que les variables suivantes sont déclarées dans votre session shell :
# Définissez le nom de votre environnement CDP. S'il n'est pas défini, les commandes ci-dessous prennent par défaut la valeur aws-${USER}.
export CDP_ENV_NAME=aws-${USER}# Récupérer le CRN de l'environnement
export CDP_ENV_CRN=$(cdp environments describe-environment \
--environment-name ${CDP_ENV_NAME:-aws-${USER}} \
| jq -r '.environment.crn')# Gestion des tags AWS
AWS_TAG_GENERAL_KEY=ENVIRONMENT_PROVIDER
AWS_TAG_GENERAL_VALUE=CLOUDERA
AWS_TAG_SERVICE_KEY=CDP_SERVICE
AWS_TAG_SERVICE_DATAFLOW=CDP_DATAFLOW
AWS_TAG_SERVICE_DATAENGINEERING=CDP_DATAENGINEERING
AWS_TAG_SERVICE_DATAWAREHOUSE=CDP_DATAWAREHOUSE
AWS_TAG_SERVICE_VIRTUALWAREHOUSE=CDP_VIRTUALWAREHOUSEActivation de DataFlow
Pour activer DataFlow à partir du terminal, utilisez les commandes suivantes.
# Activer DataFlow
cdp df enable-service \
--environnement-crn ${CDP_ENV_CRN} \
--min-k8s-node-count ${CDP_DF_NODE_COUNT_MIN:-3} \
--max-k8s-node-count ${CDP_DF_NODE_COUNT_MIN:-20} \
--use-public-load-balancer \
--no-private-cluster \
--tags "{\"${AWS_TAG_GENERAL_KEY}\":\"${AWS_TAG_GENERAL_VALUE}\",\"${AWS_TAG_SERVICE_KEY}\":\"${AWS_TAG_SERVICE_DATAFLOW}\"}"Pour surveiller l’état de votre service DataFlow :
# État du service DataFlow
cdp df list-services \
--search-term ${CDP_ENV_NAME} (terme de recherche) \
| jq -r '.services[].status.detailedState'Activation de Data Engineering
L’activation complète du service Data Engineering depuis votre terminal nécessite deux étapes :
- Activez le service Data Engineering
- Activer un cluster virtuel
Dans notre cas d’utilisation spécifique, nous devons activer le cluster virtuel Data Engineering à partir de la console CDP. En effet, au moment de la rédaction de l’article, l’interface CLI de CDP ne fournit aucune option permettant de lancer un cluster virtuel prenant en charge les tables Apache Iceberg.
Pour activer Data Engineering à partir du terminal, utilisez la commande suivante :
cdp de enable-service \
--name ${CDP_DE_NAME:-aws-${USER}-dataengineering} \
--env ${CDP_ENV_NAME:-aws-${USER}} \
--instance-type ${CDP_DE_INSTANCE_TYPE:-m5.2xlarge} \
--minimum-instances ${CDP_DE_INSTANCES_MIN:-1} \
--maximum-instances ${CDP_DE_INSTANCES_MAX:-50} \
--minimum-spot-instances ${CDP_DE_SPOT_INSTANCES_MIN:-1} \
--maximum-spot-instances ${CDP_DE_SPOT_INSTANCES_MAX:-25} \
--enable-public-endpoint \
--tags "{\"${AWS_TAG_GENERAL_KEY}\":\"${AWS_TAG_GENERAL_VALUE}\",\"${AWS_TAG_SERVICE_KEY}\":\"${AWS_TAG_SERVICE_DATAENGINEERING}\"}"Pour surveiller l’état de votre service Data Engineering :
# Obtenez l'ID de cluster de notre service Data Engineering
export CDP_DE_CLUSTER_ID=$(cdp de list-services \
| jq -r --arg SERVICE_NAME "${CDP_DE_NAME:-aws-${USER}-dataengineering}" \
'.services[] | select(.name==$SERVICE_NAME).clusterId')
# Voir l'état de notre service Data Engineering
cdp de describe-service \
--cluster-id ${CDP_DE_CLUSTER_ID} \
| jq -r '.service.status' (en anglais)Le service devient disponible après 60 à 90 minutes. Une fois prêt, vous devez activer un cluster virtuel prenant en charge les tables Apache Iceberg Analytical. Cette opération s’effectue depuis la console Cloudera comme décrit dans la section Utilisation de la console pour ajouter des services.
Activation du service Data Warehouse
Afin de lancer le service Data Warehouse depuis votre terminal, vous devez fournir les sous-réseaux publics et privés de votre environnement CDP :
-
Tout d’abord, récupérez votre ID VPC afin de trouver vos sous-réseaux :
# Obtenez l'ID VPC de base AWS_VPC_ID=$(cdp environments describe-environment \ --environnement-name $CDP_ENV_NAME \ | jq '.environment.network.aws.vpcId') -
Ensuite, récupérez vos sous-réseaux publics et privés avec la commande suivante :
# Obtenir les sous-réseaux privés AWS_PRIVATE_SUBNETS=$(aws ec2 describe-subnets \ --filtres Name=vpc-id,Values=${AWS_VPC_ID} \ | jq -r '.Subnets[] | select(.MapPublicIpOnLaunch==false).SubnetId') # Obtenir les sous-réseaux publics AWS_PUBLIC_SUBNETS=$(aws ec2 describe-subnets \ --filtres Name=vpc-id,Values=${AWS_VPC_ID} \ | jq -r '.Subnets[] | select(.MapPublicIpOnLaunch==true).SubnetId') -
Les groupes de sous-réseaux doivent être fournis dans un format spécifique, qui exige qu’ils soient joints avec une virgule comme séparateur. Une petite fonction bash permet de générer ce format :
# Concaténation de chaînes de caractères avec délimiteur function join_by { local IFS="$1" ; shift ; echo "$*" ; } -
Appelez cette fonction pour concaténer les deux tableaux en chaînes de la forme
subnet1,subnet2,subnet3:# Concaténation au format requis export AWS_PRIVATE_SUBNETS=$(join_by "," ${AWS_PRIVATE_SUBNETS}) export AWS_PUBLIC_SUBNETS=$(join_by "," ${AWS_PUBLIC_SUBNETS})
Maintenant que nous avons nos sous-réseaux, nous sommes prêts à créer le cluster Data Warehouse :
# Créez un cluster Data Warehouse
cdp dw create-cluster \
--environment-crn $CDP_ENV_CRN \
--no-use-overlay-network \
--database-backup-retention-period 7 \
--no-use-private-load-balancer \
--aws-options privateSubnetIds=$AWS_PRIVATE_SUBNETS,publicSubnetIds=$AWS_PUBLIC_SUBNETSPour surveiller l’état du data warehouse, utilisez les commandes suivantes :
# Obtenez l'ID de notre cluster Data Warehouse
export CDP_DW_CLUSTER_ID=$(cdp dw list-clusters --environment-crn $CDP_ENV_CRN | jq -r '.clusters[].id')
# Obtenez le statut de notre cluster Data Warehouse
cdp dw describe-cluster \
--cluster-id ${CDP_DW_CLUSTER_ID} \
| jq -r '.cluster.status' (en anglais)Une fois que votre Data Warehouse est disponible, lancez un virtual warehouse comme suit :
# Obtenez l'identifiant de notre Data Warehouse cluster
export CDP_DW_CLUSTER_ID=$(cdp dw list-clusters --environment-crn $CDP_ENV_CRN | jq -r '.clusters[].id')# Obtenez l'identifiant de notre catalogue de base de données par défaut
export CDP_DW_CLUSTER_DBC=$(cdp dw list-dbcs --cluster-id $CDP_DW_CLUSTER_ID | jq -r '.dbcs[].id')# Définissez un nom pour votre virtual warehouse
export CDP_VWH_NAME=aws-${USER}-virtual-warehouse# Lancez le virtual warehouse
cdp dw create-vw \
--cluster-id ${CDP_DW_CLUSTER_ID} \
--dbc-id ${CDP_DW_CLUSTER_DBC} \
--vw-type impala \
--name ${CDP_VWH_NAME} \
--template xsmall \
--tags key=${AWS_TAG_GENERAL_KEY},value=${AWS_TAG_GENERAL_VALUE} key=${AWS_TAG_SERVICE_KEY},value=${AWS_TAG_SERVICE_VIRTUALWAREHOUSE}Pour surveiller l’état du virtual warehouse :
# Obtenez l'ID de votre virtual warehouse
export CDP_VWH_ID=$(cdp dw list-vws \
--cluster-id ${CDP_DW_CLUSTER_ID} \
| jq -r --arg VW_NAME "${CDP_VWH_NAME}" \
'.vws[] | select(.name==$VW_NAME).id')
# Afficher l'état de votre virtual warehouse
cdp dw describe-vw \
--cluster-id ${CDP_DW_CLUSTER_ID} \
--vw-id ${CDP_VWH_ID} \
| jq -r '.vw.status'La dernière fonctionnalité à activer est la Visualisation des données. La première étape consiste à préparer un Groupe d’utilisateurs Administrateur :
# Définissez un nom pour votre nouveau groupe d'utilisateurs
export CDP_DW_DATAVIZ_ADMIN_GROUP_NAME=cdp-dw-dataviz-admins
export CDP_DW_DATAVIZ_SERVICE_NAME=cdp-${USER}-dataviz
# Créez le groupe dans votre compte CDP
cdp iam create-group \
--group-name ${CDP_DW_DATAVIZ_ADMIN_GROUP_NAME} \
--sync-membership-on-user-loginPar la suite, vous devrez vous connecter au service de visualisation des données avec des privilèges d’administrateur. Par conséquent, vous devez vous ajouter au groupe d’administrateurs :
# Obtenez votre propre identifiant d'utilisateur
export CDP_MY_USER_ID=$(cdp iam get-user \
| jq -r '.user.userId')
# Ajoutez vous au groupe
cdp iam add-user-to-group \
--user-id ${CDP_MY_USER_ID} \
--group-name ${CDP_DW_DATAVIZ_ADMIN_GROUP_NAME}Une fois le groupe administrateur créé, le lancement du service Data Visualization est rapide. Notez que nous allons ajouter un groupe utilisateur dans le futur, mais cela sera couvert dans un prochain article :
# Lancez le service Data Visualization
cdp dw create-data-visualization \
--cluster-id ${CDP_DW_CLUSTER_ID} \
--name ${CDP_DW_DATAVIZ_SERVICE_NAME} \
--config adminGroups=${CDP_DW_DATAVIZ_ADMIN_GROUP_NAME}Pour surveiller l’état de votre service Data Visualization :
# Obtenez l'ID du service Data Visualization
export CDP_DW_DATAVIZ_SERVICE_ID=$(cdp dw list-data-visualizations \
--cluster-id ${CDP_DW_CLUSTER_ID} \
| jq -r --arg VIZ_NAME "${CDP_DW_DATAVIZ_SERVICE_NAME}" \
'.dataVisualizations[] | select(.name==$VIZ_NAME).id')
# Voir l'état du service Data Visualization
cdp dw describe-data-visualization \
--cluster-id ${CDP_DW_CLUSTER_ID} \
--data-visualization-id ${CDP_DW_DATAVIZ_SERVICE_ID} \
| jq -r '.dataVisualization.status'Et voilà, c’est fait ! Vous avez maintenant activé le service Data Warehouse avec toutes les fonctionnalités requises par notre architecture.
Aperçu des ressources AWS
Bien que Cloudera fournisse une documentation exhaustive sur le CDP Public Cloud, comprendre quelles ressources sont déployées sur AWS lorsqu’un service spécifique est activé n’est pas une tâche évidente. D’après nos observations, les ressources suivantes sont créées lorsque vous lancez les services DataFlow, Data Engineering et/ou Data Warehouse.
Les coûts horaires et autres sont pour la région Europe Irlande, tels qu’observés en juin 2023. La tarification des ressources AWS varie selon la région et peut évoluer dans le temps. Consultez AWS Pricing pour connaître les tarifs en vigueur dans votre région.
| Composant CDP | Ressource AWS créée | Quantité | coût de la resource par heure | Autre coût de la ressource |
|---|---|---|---|---|
| DataFlow | EC2 Instance: c5.4xlarge | 3* | $0.768 | Tarification de tranfert de données |
| DataFlow | EC2 Instance: m5.large | 2 | $0.107 | Tarification de tranfert de données |
| DataFlow | EBS: GP2 65gb | 3* | n/a | $0.11 par GB par mois (voir Tarification Amazon EBS) |
| DataFlow | EBS: GP2 40gb | 2 | n/a | $0.11 par GB par mois (voir Tarification Amazon EBS) |
| DataFlow | RDS Postgre DB Instance: db.r5.large | 1 | $0.28 | Ressources de tarification supplémentaires |
| DataFlow | RDS: DB Subnet Group | 1 | Pas de charges | Pas de charges |
| DataFlow | RDS: DB Snapshot | 1 | n/a | Ressources de tarification supplémentaires |
| DataFlow | RDS: DB Parameter Group | 1 | n/a | n/a |
| DataFlow | EKS Cluster | 1 | $0.10 | Tarification d’Amazon EKS |
| DataFlow | VPC Classic Load Balancer | 1 | $0.028 | $0.008 par GB de données traitées (voir Tarification d'Elastic Load Balancing) |
| DataFlow | KMS: Customer-Managed Key | 1 | n/a | $1.00 par mois et coûts d'usage costs : Tarification AWS KMS |
| DataFlow | CloudFormation: Stack | 6 | Pas de charges | Tarification AWS CloudFormation |
| Data Engineering | EC2 Instance: m5.xlarge | 2 | $0.214 | Tarification transfert de données |
| Data Engineering | EC2 Instance: m5.2xlarge | 3* | $0.428 | Tarification transfert de données |
| Data Engineering | EC2 Security Group | 4 | Pas de charges | Pas de charges |
| Data Engineering | EBS: GP2 40gb | 2 | n/a | $0.11 par GB par mois (voir Tarification Amazon EBS) |
| Data Engineering | EBS: GP2 60gb | 1 | n/a | $0.11 par GB par mois (voir Tarification Amazon EBS) |
| Data Engineering | EBS: GP2 100gb | 1 | n/a | $0.11 par GB par mois (voir Tarification Amazon EBS) |
| Data Engineering | EFS: Standard | 1 | n/a | $0.09 par GB par mois (voir Tarification Amazon EFS) |
| Data Engineering | EKS Cluster | 1 | $0.10 | Tarification d’Amazon EKS |
| Data Engineering | RDS MySQL DB Instance: db.m5.large | 1 | $0.189 | Tarification Amazon RDS pour MySQL |
| Data Engineering | RDS: DB Subnet Group | 1 | Pas de charges | Pas de charges |
| Data Engineering | VPC Classic Load Balancer | 2 | $0.028 | $0.008 par GB de données traitées (voir Tarification d'Elastic Load Balancing) |
| Data Engineering | CloudFormation: Stack | 8 | Pas de chargess | Tarification AWS CloudFormation |
| Data Warehouse | EC2 Instance: m5.2xlarge | 4 | $0.428 | Tarification de tranfert de données |
| Data Warehouse | EC2 Instance: r5d.4xlarge | 1 | $1.28 | Tarification de tranfert de données |
| Data Warehouse | EC2 Security Group | 5 | Pas de chargess | Pas de chargess |
| Data Warehouse | S3 Bucket | 2 | n/a | Tarification AWS S3 |
| Data Warehouse | EBS: GP2 40gb | 4 | n/a | $0.11 par GB par mois (voir Tarification Amazon EBS) |
| Data Warehouse | EBS: GP2 5gb | 3 | n/a | $0.11 par GB par mois (voir Tarification Amazon EBS) |
| Data Warehouse | EFS: Standard | 1 | n/a | $0.09 par GB par mois (voir Tarification Amazon EFS) |
| Data Warehouse | RDS Postgre DB Instance: db.r5.large | 1 | $0.28 | Ressources de tarification supplémentaires |
| Data Warehouse | RDS: DB Subnet Group | 1 | Pas de chargess | Pas de chargess |
| Data Warehouse | RDS: DB Snapshot | 1 | n/a | Ressources de tarification supplémentaires |
| Data Warehouse | EKS: Cluster | 1 | $0.10 | Tarification d’Amazon EKS |
| Data Warehouse | VPC Classic Load Balancer | 1 | $0.028 | $0.008 par GB de données traitées (voir Load Balancer Pricing) |
| Data Warehouse | CloudFormation: Stack | 1 | Pas de chargess | Tarification AWS CloudFormation |
| Data Warehouse | Certificate via Certificate Manager | 1 | Pas de chargess | Pas de chargess |
| Data Warehouse | KMS: Customer-Managed Key | 1 | n/a | $1.00 par mois et coûts d'usage : Tarification AWS KMS |
| Virtual Warehouse | EC2 Instance: r5d.4xlarge | 31,152* | $1.28 | Tarification de tranfert de données |
| Virtual Warehouse | EBS: GP2 40gb | 3* | n/a | $0.11 par GB par mois (voir Tarification Amazon EBS) |
Remarque : certaines ressources évoluent en fonction de la charge et du nombre minimum et maximum de nœuds que vous définissez lorsque vous activez le service.
Avec notre configuration (et sans tenir compte des coûts basés sur l’utilisation tels que les frais de transfert de données ou de traitement de l’équilibreur de charge, ou des coûts au prorata tels que le prix des volumes de stockage EBS provisionnés) nous envisageons le coût de base horaire approximatif suivant par service activé :
- DataFlow : ~2,36 $ par heure
- Data Engineering : ~1,20 $ par heure
- Data Warehouse : ~3,40 $ par heure
- Virtual Warehouse : ~3,84 $ par heure
Comme toujours, nous devons insister sur le fait que vous devez toujours supprimer les ressources dans le cloud qui ne sont plus utilisées afin d’éviter des coûts indésirables.
Prochaines étapes
Maintenant que votre environnement de CDP Public Cloud est entièrement déployé avec une série de services puissants, vous êtes presque prêt à l’utiliser. Avant de le faire, vous devez intégrer les utilisateurs dans votre plateforme et configurer leurs droits d’accès. Nous couvrons ce processus dans les deux prochains chapitres, en commençant par Gestion des utilisateurs sur le CDP Public Cloud avec Keycloak.
