


CDP partie 6 : cas d'usage bout en bout d'un Data Lakehouse avec CDP

24 juil. 2023
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Dans cet exercice pratique, nous montrons comment construire une solution big data complète avec la Cloudera Data Platform (CDP) Public Cloud, en se basant sur l’infrastructure qui a été déployée tout au long de cette série d’articles.
Il s’agit du dernier article d’une série de six :
- CDP partie 1 : introduction à l’architecture Data Lakehouse avec CDP
- CDP partie 2 : déploiement d’un environnement CDP Public Cloud sur AWS
- CDP partie 3 : activation des Data Services en environnement CDP Public Cloud
- CDP partie 4 : gestion des utilisateurs sur CDP avec Keycloak
- CDP partie 5 : gestion des permissions utilisateurs sur CDP
- CDP partie 6 : cas d’usage bout en bout d’un Data Lakehouse avec CDP
L’objectif est de mettre en place une solution que les utilisateurs pourront solliciter à la demande et qui leur permettra d’analyser les données relatives à des cours de la bourse. De manière succinte, voici les étapes nécessaires :
- Configuration d’une ingestion de données depuis une API publique pour stockage dans notre Data Lake présent sur S3.
- Mise en place d’un ELT pour transvaser les données depuis notre Data Lake vers le Data Warehouse.
- Création d’un dashboard pour visualiser les données présentes dans l’entrepôt de données.
Préparation : récupération de la clé d’API Alpha Vantage
Avant de débuter notre processus d’ingestion, il nous faut un accès à une API. Dans notre cas, nous allons utiliser une API concernant les cours de bourse, mise à disposition gratuitement par Alpha Vantage :
-
Allez sur Alpha Vantage
-
Cliquez sur : Get Your Free Api Key Today
-
Remplir les informations suivante pour solliciter une clé :
StudentSchool/organizationname- Valid email address
-
Cliquez sur
GET FREE API KEY
-
Notez bien votre clé (
&lgt;api_alpha_key>) car il y en aura besoin plus tard.
Accéder à la console CDP Public Cloud
Pour démarrer, vous devez avoir préparé un compte utilisateur sur l’infrastructure CDP tel que décrit dans les articles précédents [CDP partie 4 : gestion des utilisateurs sur CDP avec Keycloak](CDP partie 5 : gestion des permissions utilisateurs sur CDP) et CDP partie 5 : gestion des permissions utilisateurs sur CDP.
-
Connectez-vous avec l’utilisateur créé spécialement pour cet exercice, en utilisant votre page de connexion Keycloak personnalisée.
-
Après la connexion, vous êtes redirigé vers la console CDP.
Notez que si l’instance Keycloak n’a pas été configurée avec SSL/TLS, une alerte indiquant que le site n’est pas sécurisé peut apparaître à cette étape.
Configuration du mot de passe de traitement
Après la connexion avec l’utilisateur CDP, il vous est demandé de mettre un mot de passe de traitement. Il vous permettra de lancer des tâches lors de l’utilisation de services CDP.
-
Cliquer sur votre nom dans le coin en bas à gauche et cliquer sur Profile
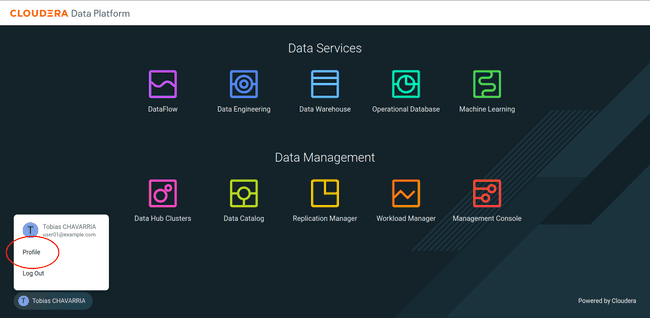
-
Cliquer sur Set Workload Password
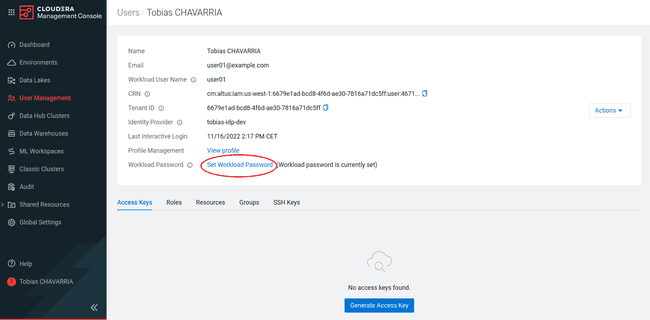
-
Si l’enregistrement du mot de passe s’est bien déroulé, vous devez voir le message
( Workload password is currently set )sur votre page de profil utilisateur.
Note : Vous pourrez toujours remplacer votre mot de passe en cas de perte.
Ingestion de données : Mise en place d’un DataFlow
Nous allons utiliser le service DataFlow de CDP pour récupérer des données depuis l’API pour alimenter notre Data Lake. Pour appel, DataFlow se base sur Apache NiFi.
Import de la définition d’un Flow
-
Aller sur la console CDP et cliquer sur l’icône du DataFlow

-
Dans le menu de gauche, cliquer sur Catalog puis sur Import Flow Definition
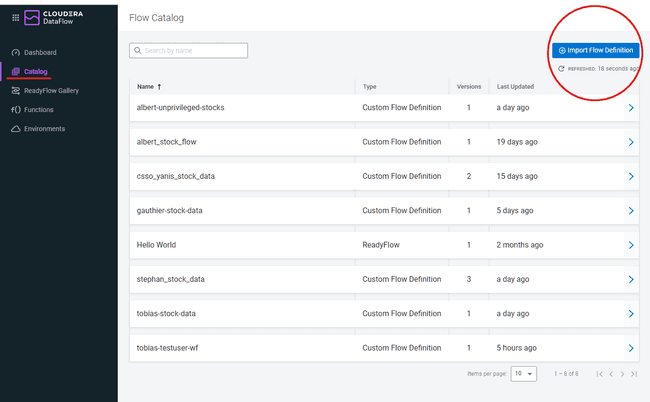
-
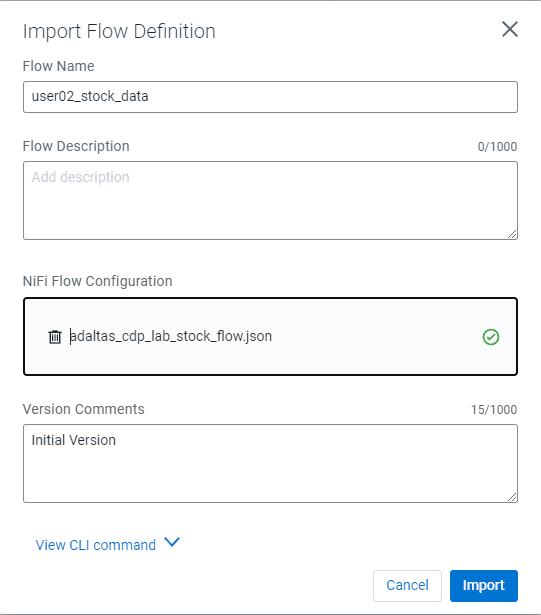
Importer le Flow NiFi et renseigner les paramètres ainsi :
- Flow name :
<username>_stock_data - Flow description :
- Import : Flow NiFi
- Cliquer sur Import
- Flow name :
Déployer un Flow Nifi
-
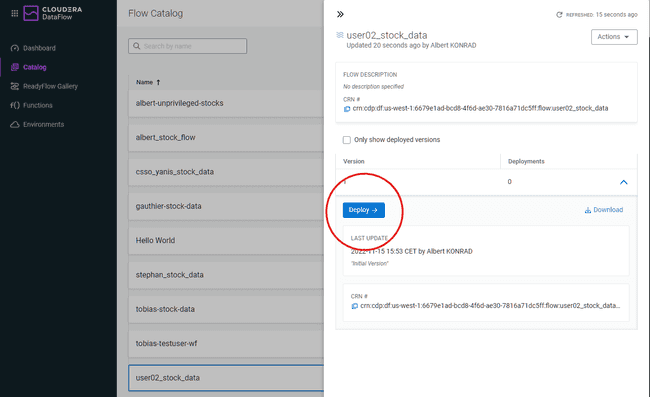
Cliquer sur la définition du flux créé à l’étape précédente.
-
Cliquer sur Deploy
-
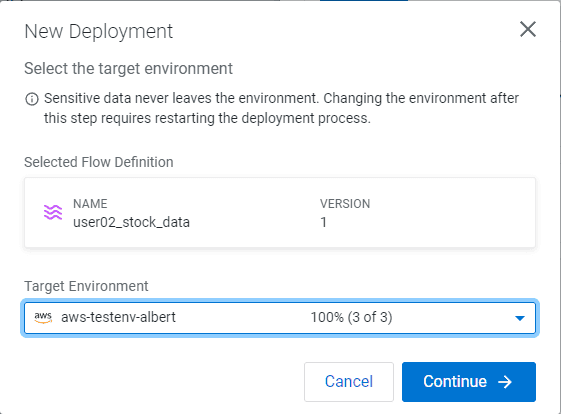
Sélectionner votre environnement CDP Public Cloud comme Target Environment
-
Cliquer sur Continue
-
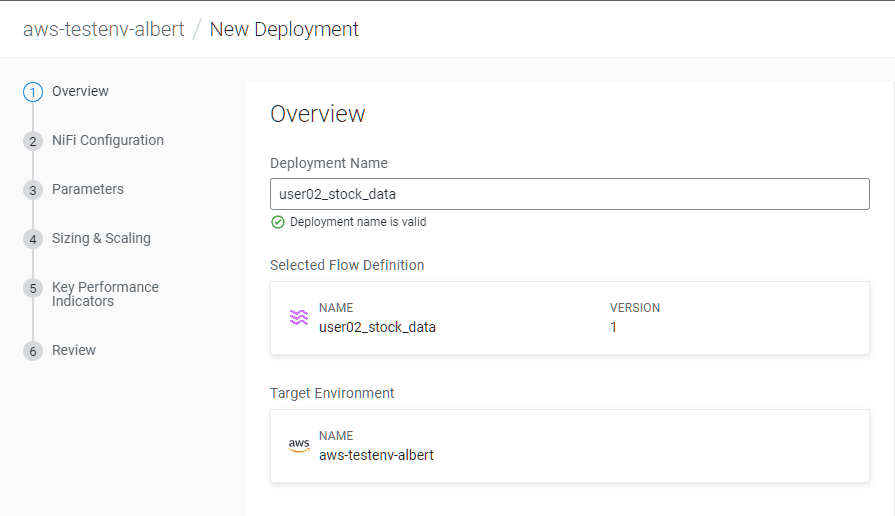
Indiquer un nom de déploiement :
<username>_stock_data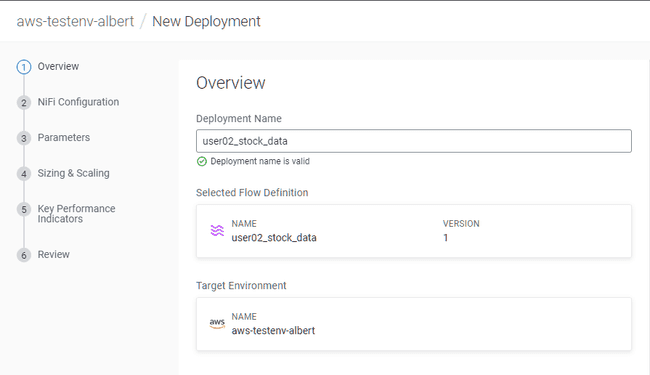
-
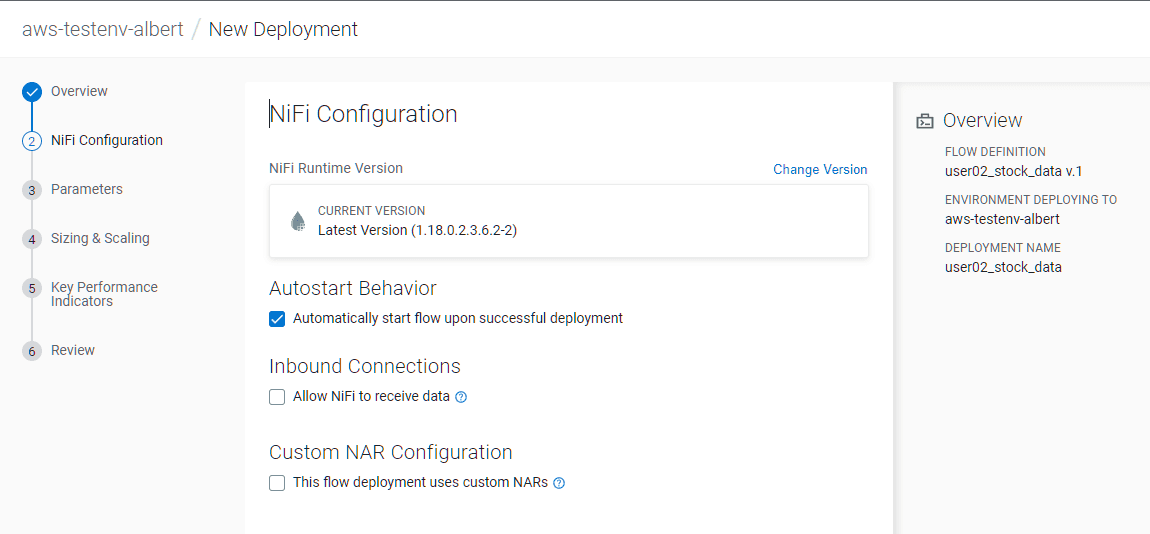
Ne rien changer à l’écran NiFi Configuration, cliquer sur Next
-
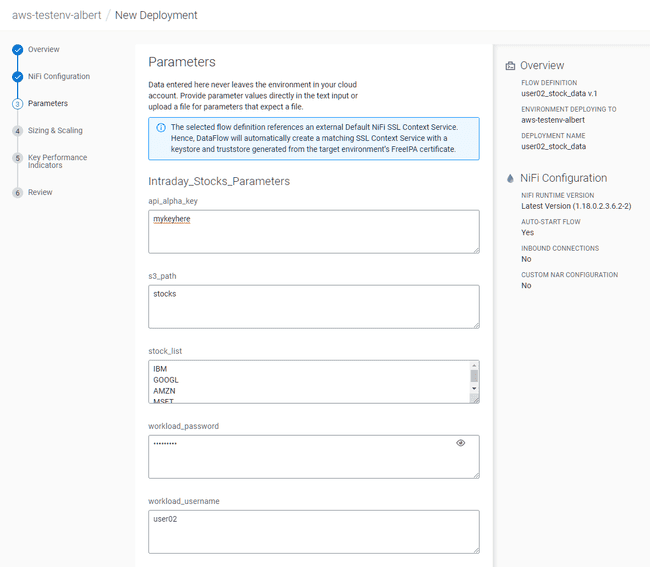
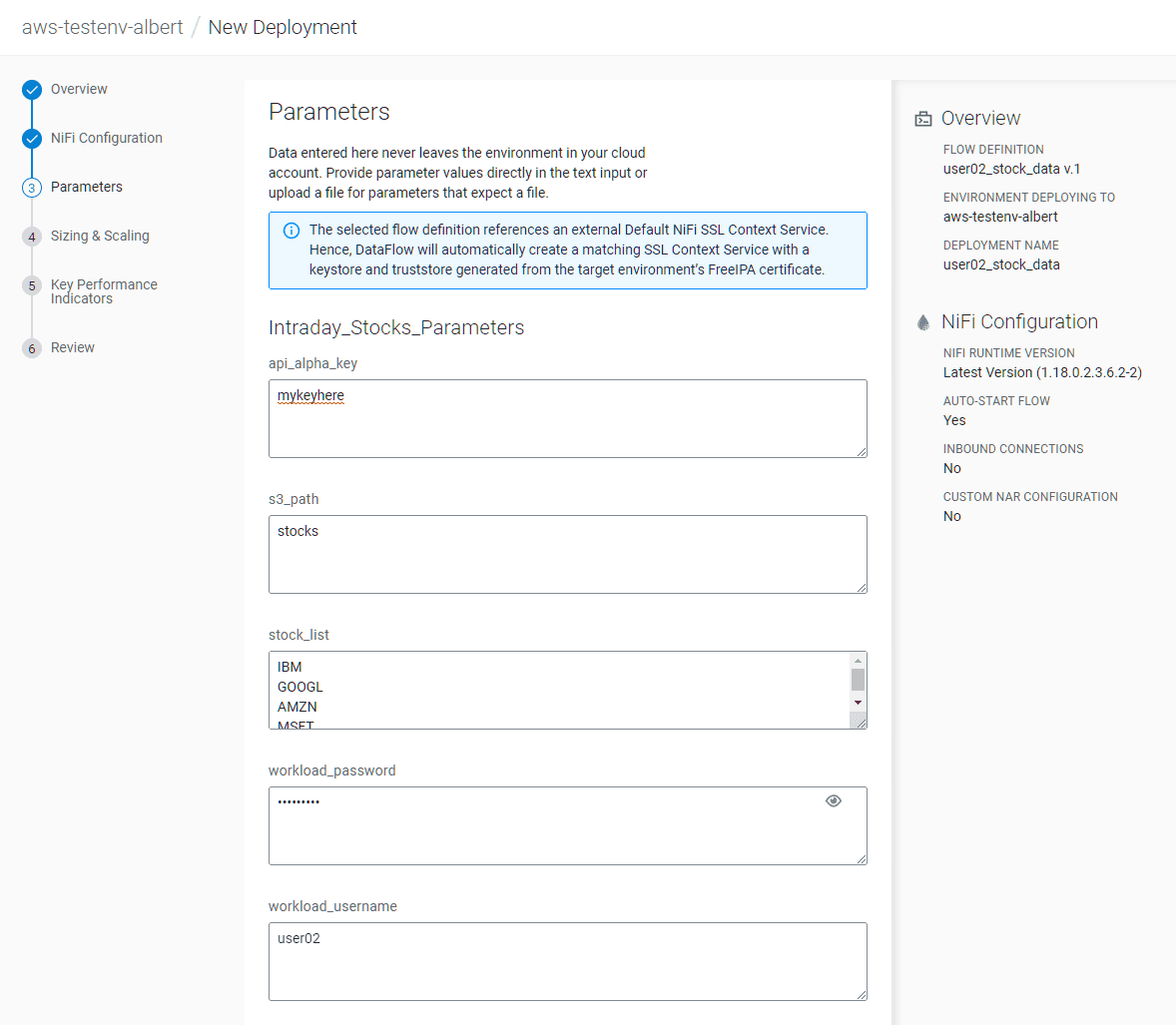
Dans l’écran Parameters, mettre :
- api_alpha_key :
<Your Alpha Vantage API key> - s3_path :
stocks - stock_list :
default - workload_password :
<Your workload password> - workload_username :
<Your user name>
- api_alpha_key :
-
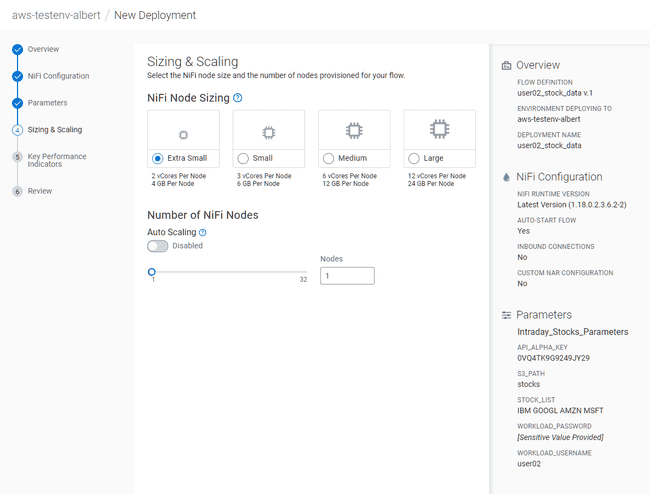
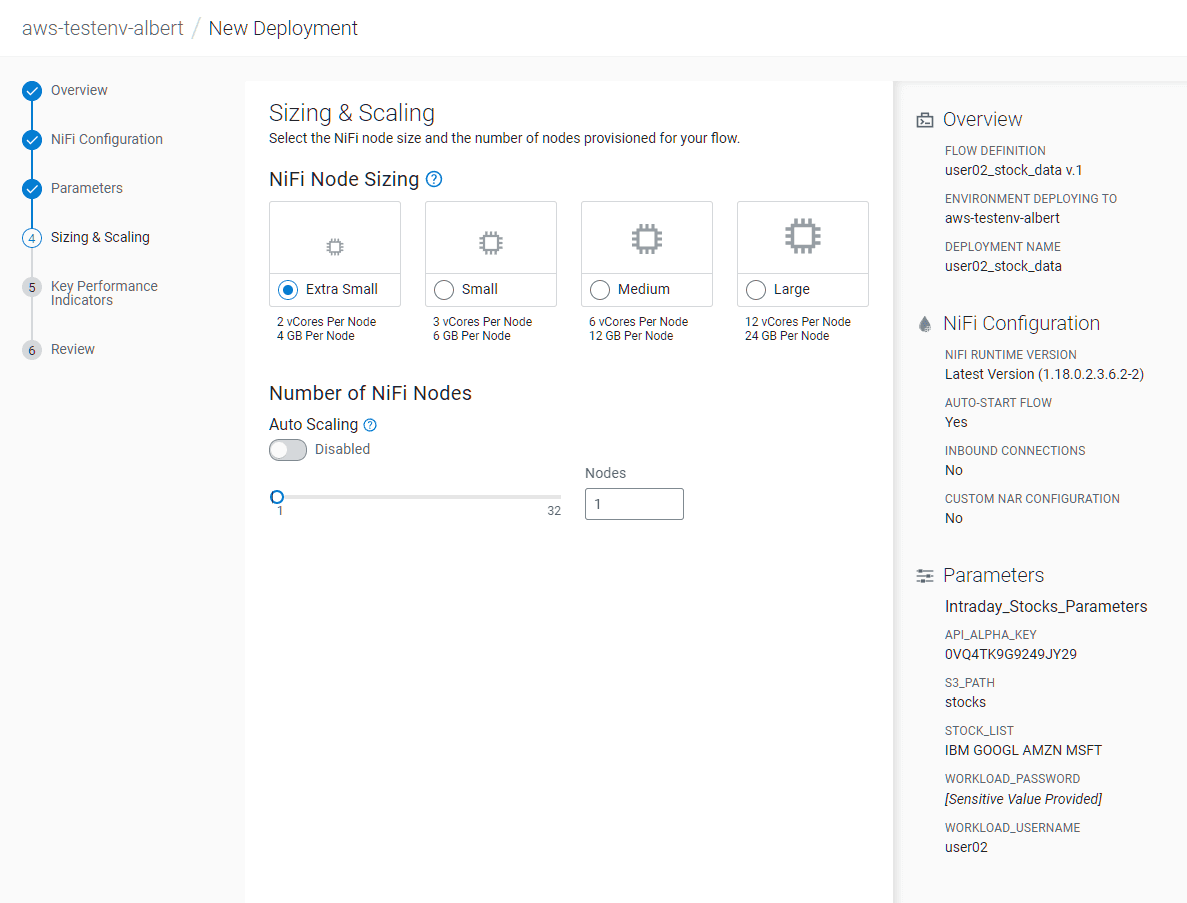
Dans l’écran Sizing & Scaling, mettre :
- NiFi Node Sizing :
Extra Small - Auto Scaling :
Disabled - Nodes :
1
- NiFi Node Sizing :
-
Dans la partie Key Performance Indicators, ne rien changer puis cliquer sur “Next”
-
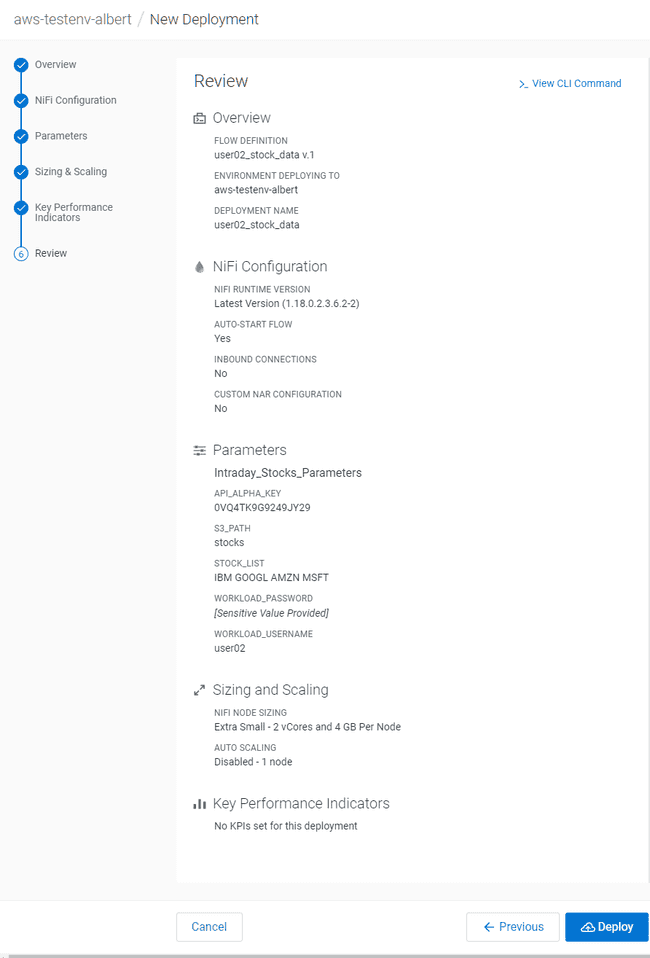
Validez la configuration, cliquer alors sur Deploy
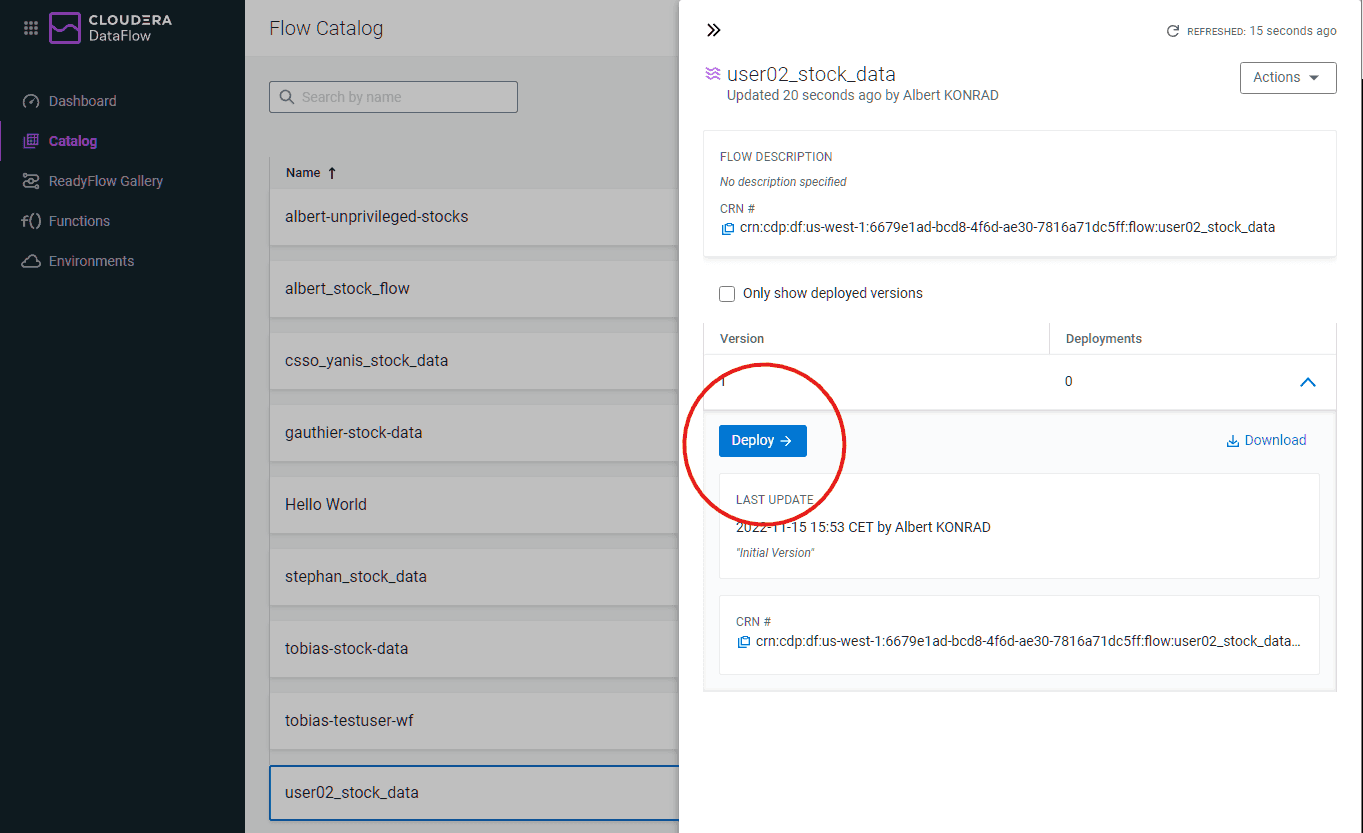
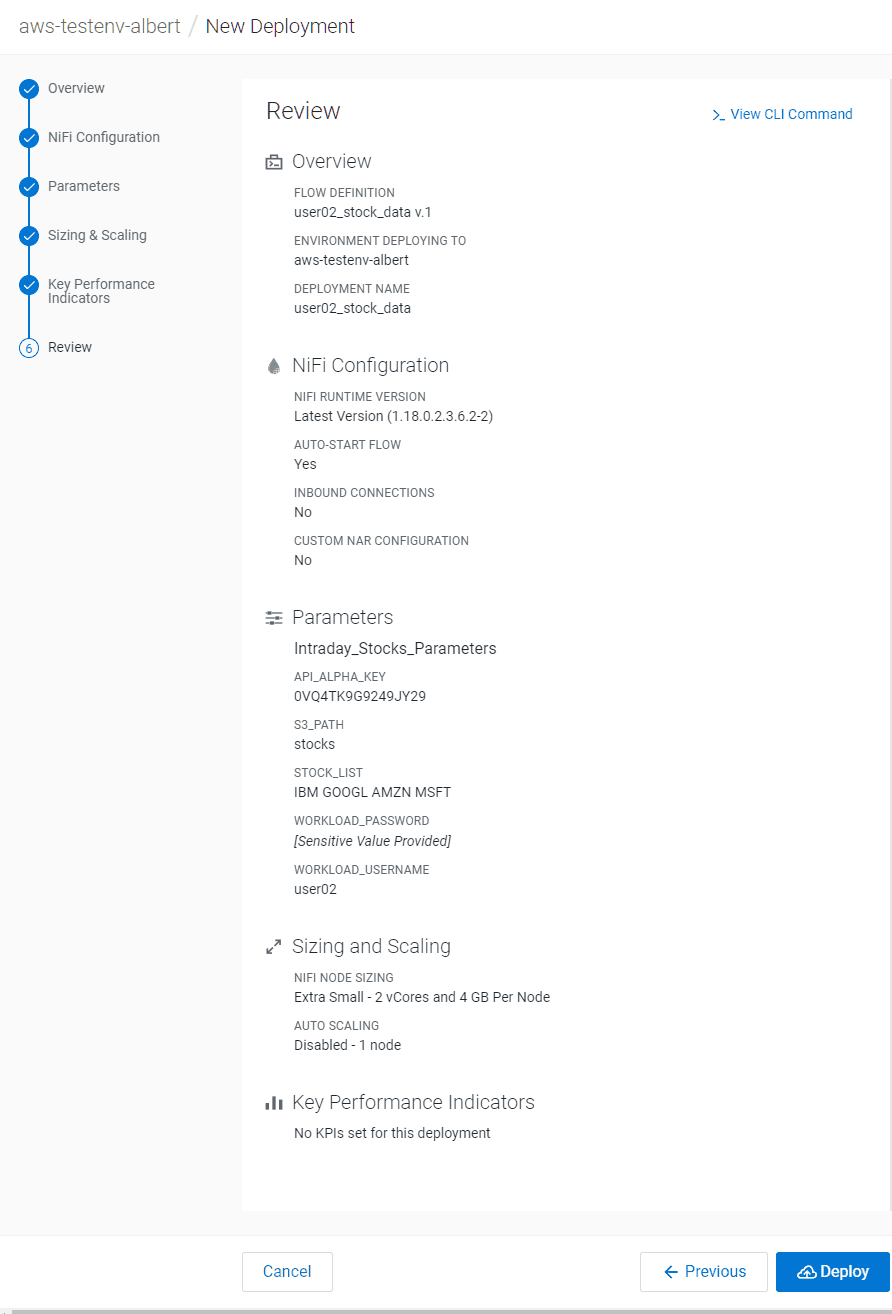
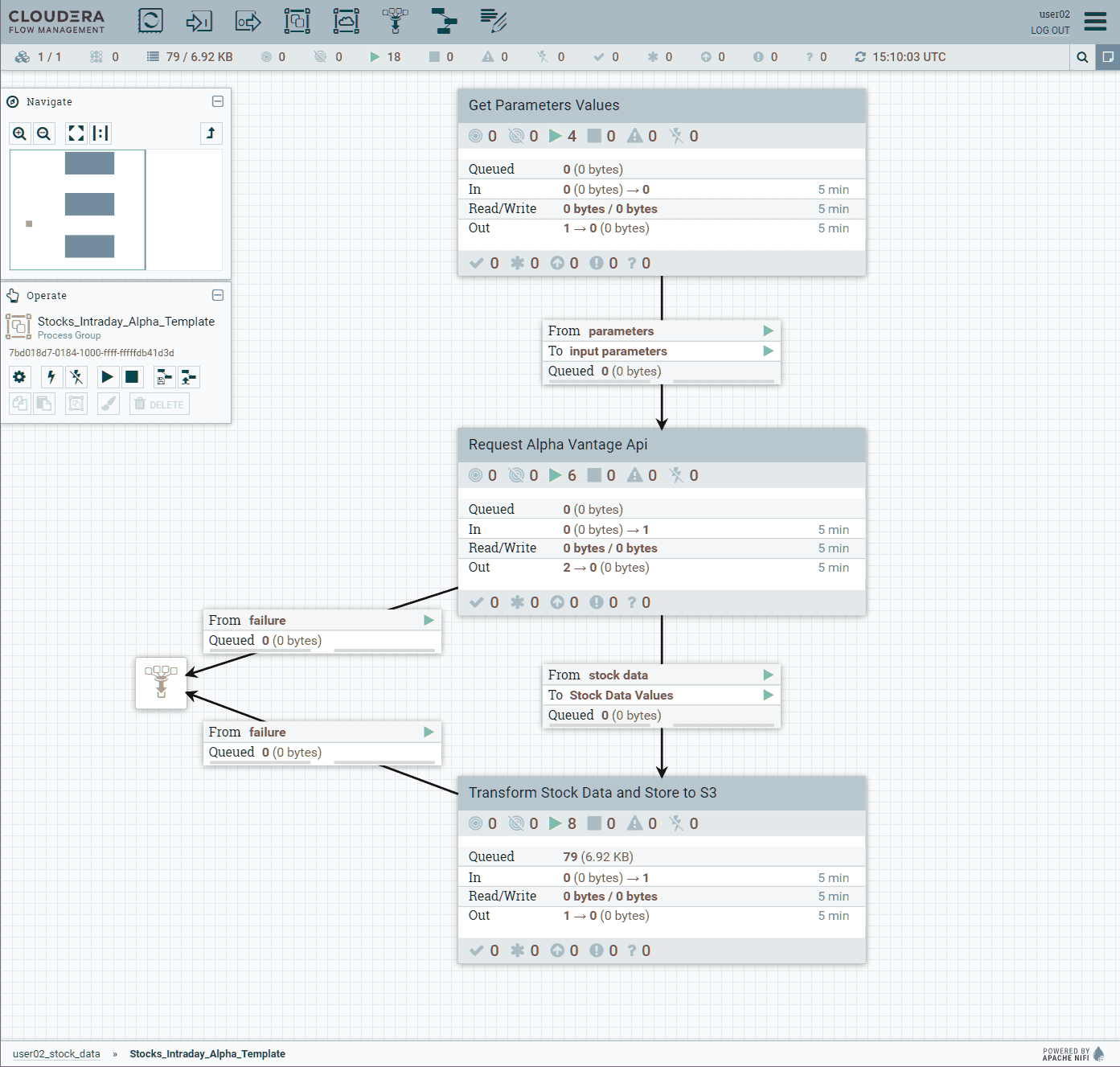
Cette ultime étape lance le flux NiFi. Il devrait mettre quelques minutes avant de tourner de manière nominale. Vous pouvez voir la progression dans le Dashboard de la page CDF.
Voir l’exécution du flux dans NiFi
Il est possible de vérifier et de revalider le flux dans l’interface web alors qu’il est en cours d’exécution :
-
Cliquer sur la flèche bleue située à droite du flux déployé
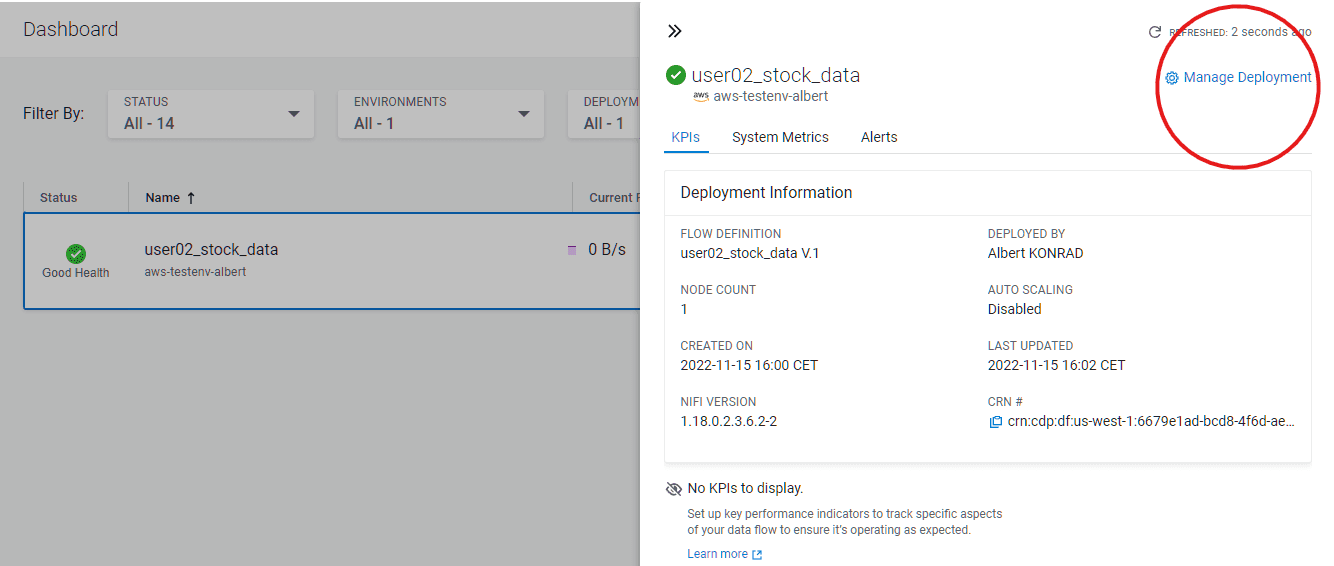
-
Cliquer sur Manage Deployment dans le coin supérieur droit
-
Dans Deployment Manager, cliquer sur Actions puis sur View in NiFi
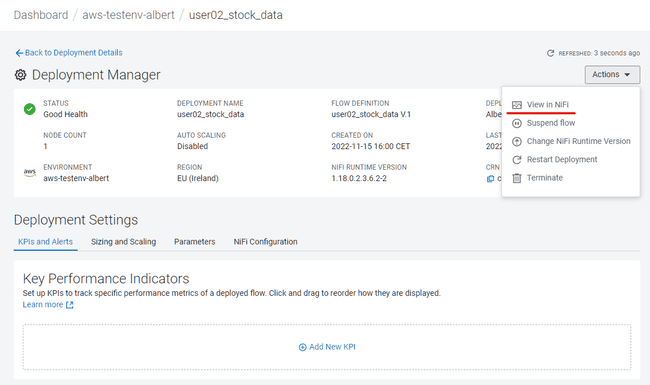
-
Cette action ouvre un nouvel onglet dans le navigateur affichant le flux NiFi
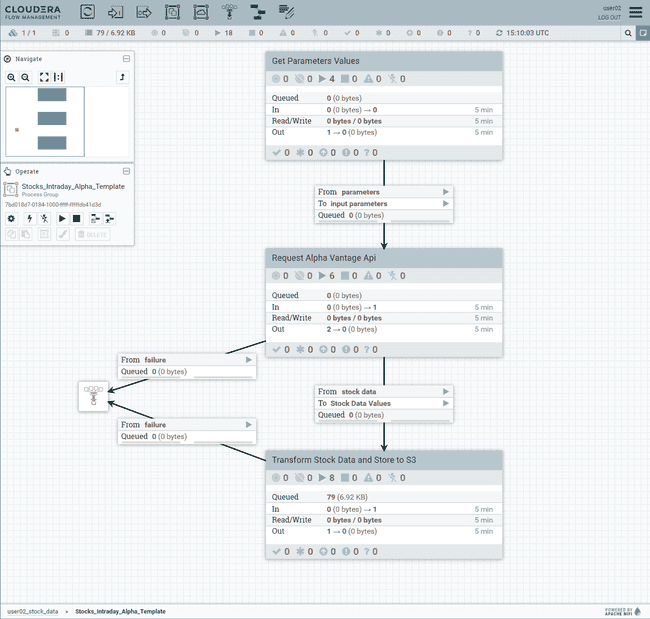
-
Prenez quelques minutes pour parcourir et comprendre les différents composants du flux
-
Puisqu’il n’est pas nécessaire pour l’exercice de récupérer de la donnée de façon continue, retournez dans Deployment Manager, Actions, et cliquez sur Suspend flow
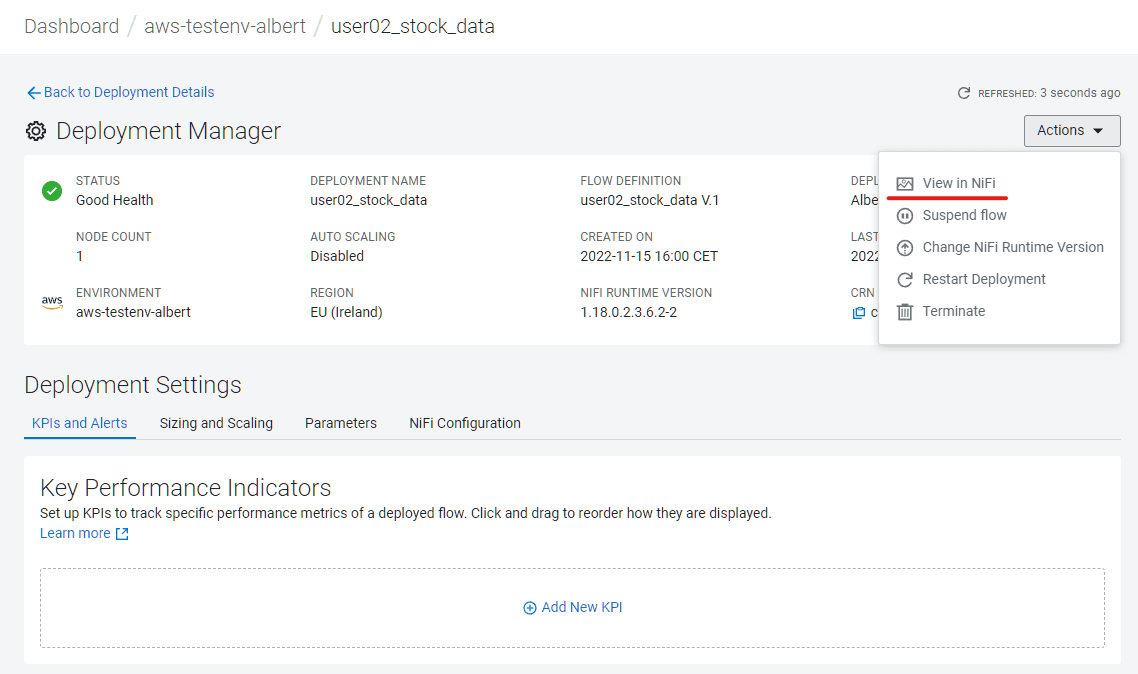
Stockage analytique : le Data Warehouse
L’étape suivante consiste à déplacer la donnée brute depuis le Data Lake vers un stockage analytique. Dans cette optique, notre choix s’est porté sur une table Apache Iceberg, un format de stockage moderne avec de nombreux avantages. Passons maintenant à la création de la table Iceberg.
Création de la table Iceberg
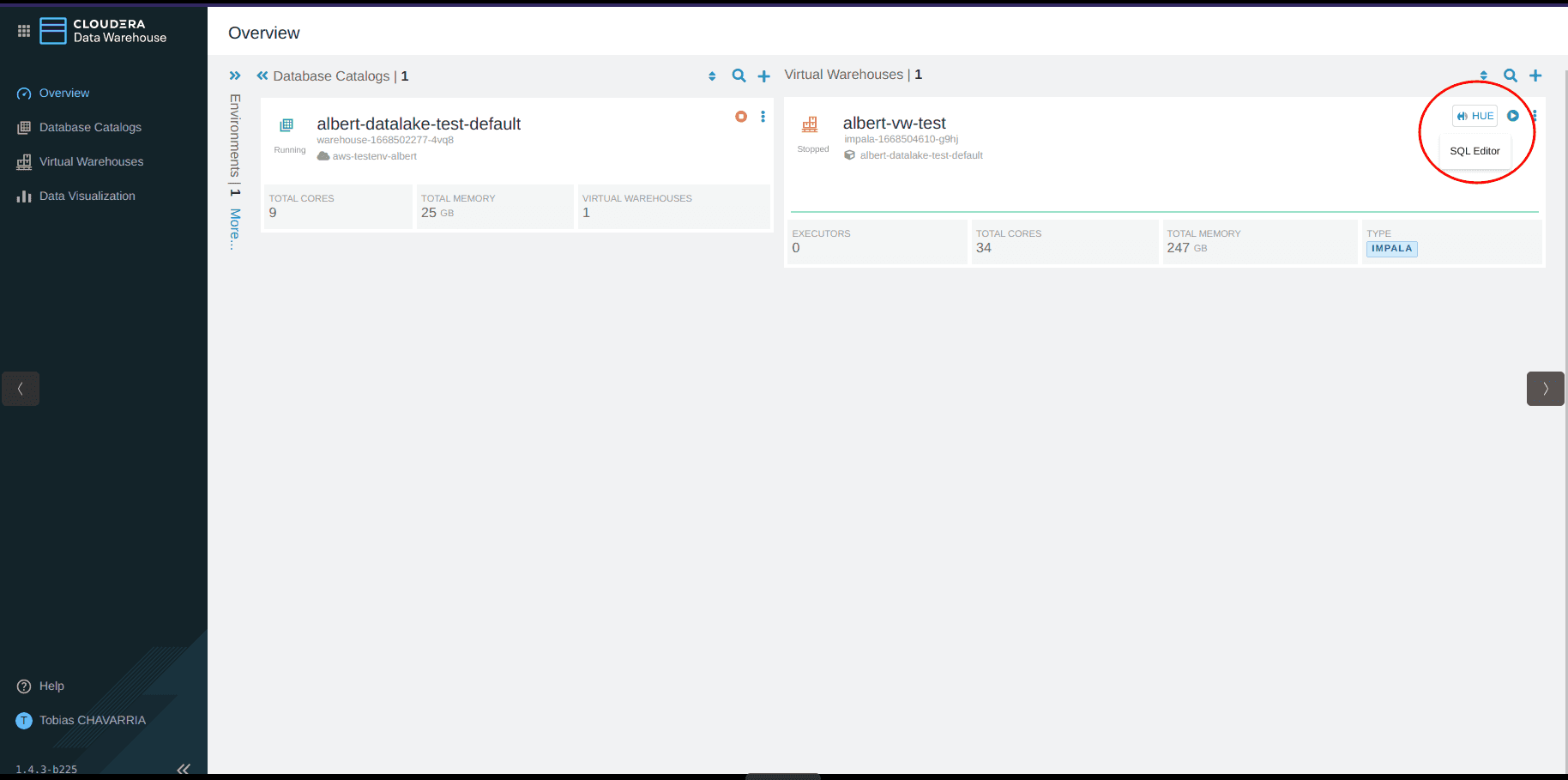
A partir de la console CDP :
-
Sélectionner Data Warehouse
-
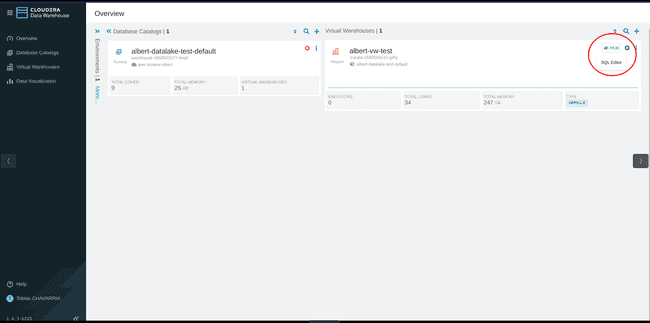
Cliquer sur le bouton HUE dans le coin supérieur droit, ce qui va ouvrir l’éditeur HUE
-
Créez une database en utilisant votre
<username>CREATE DATABASE <username>_stocks;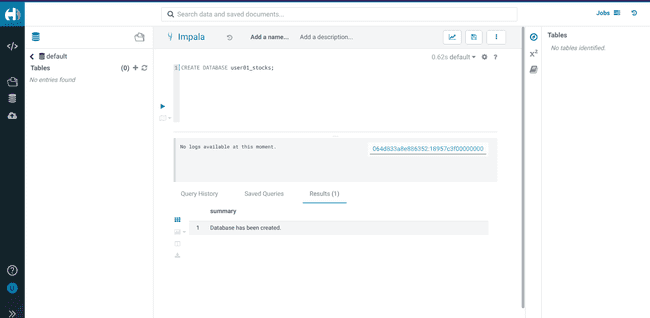
-
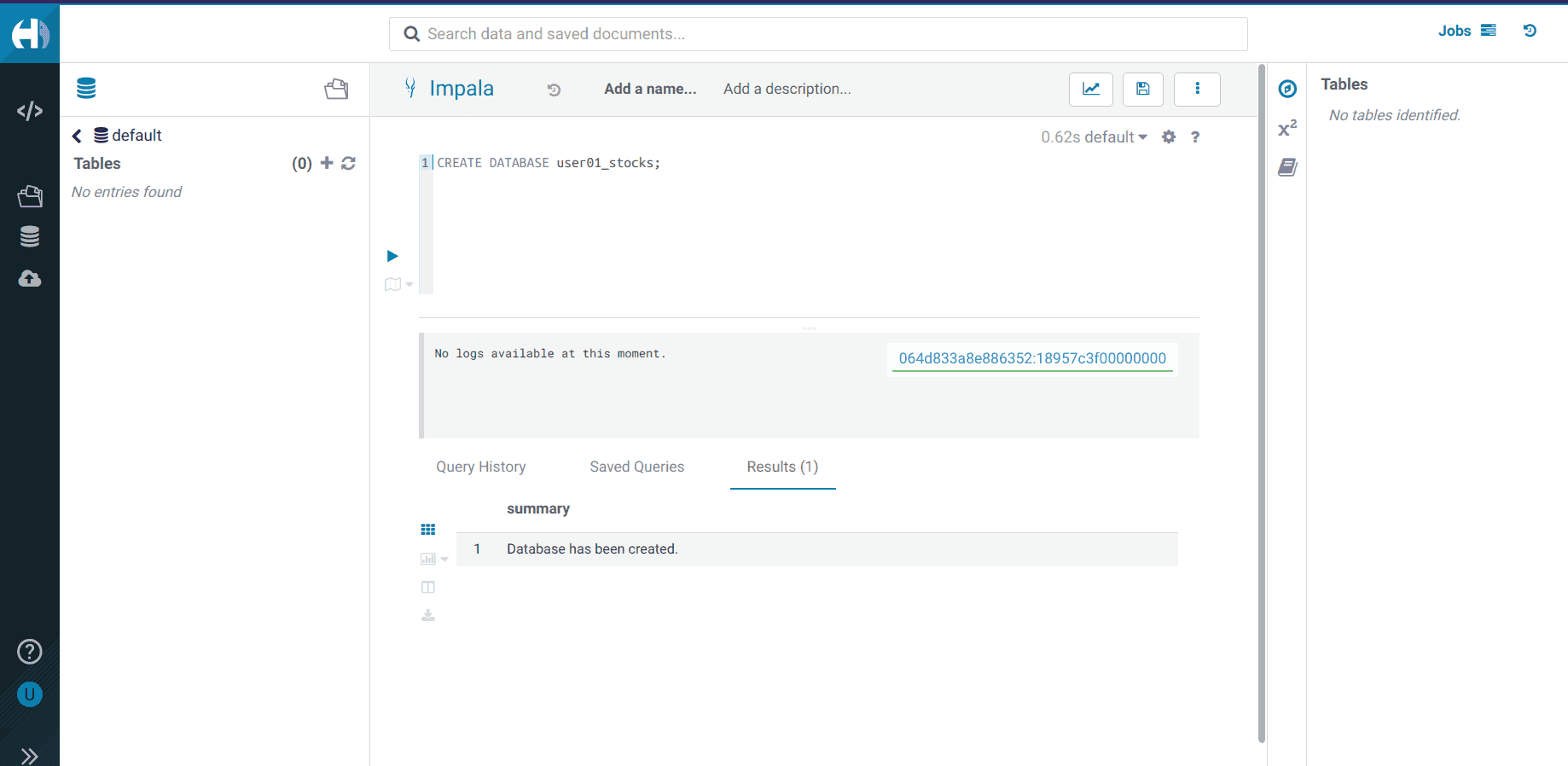
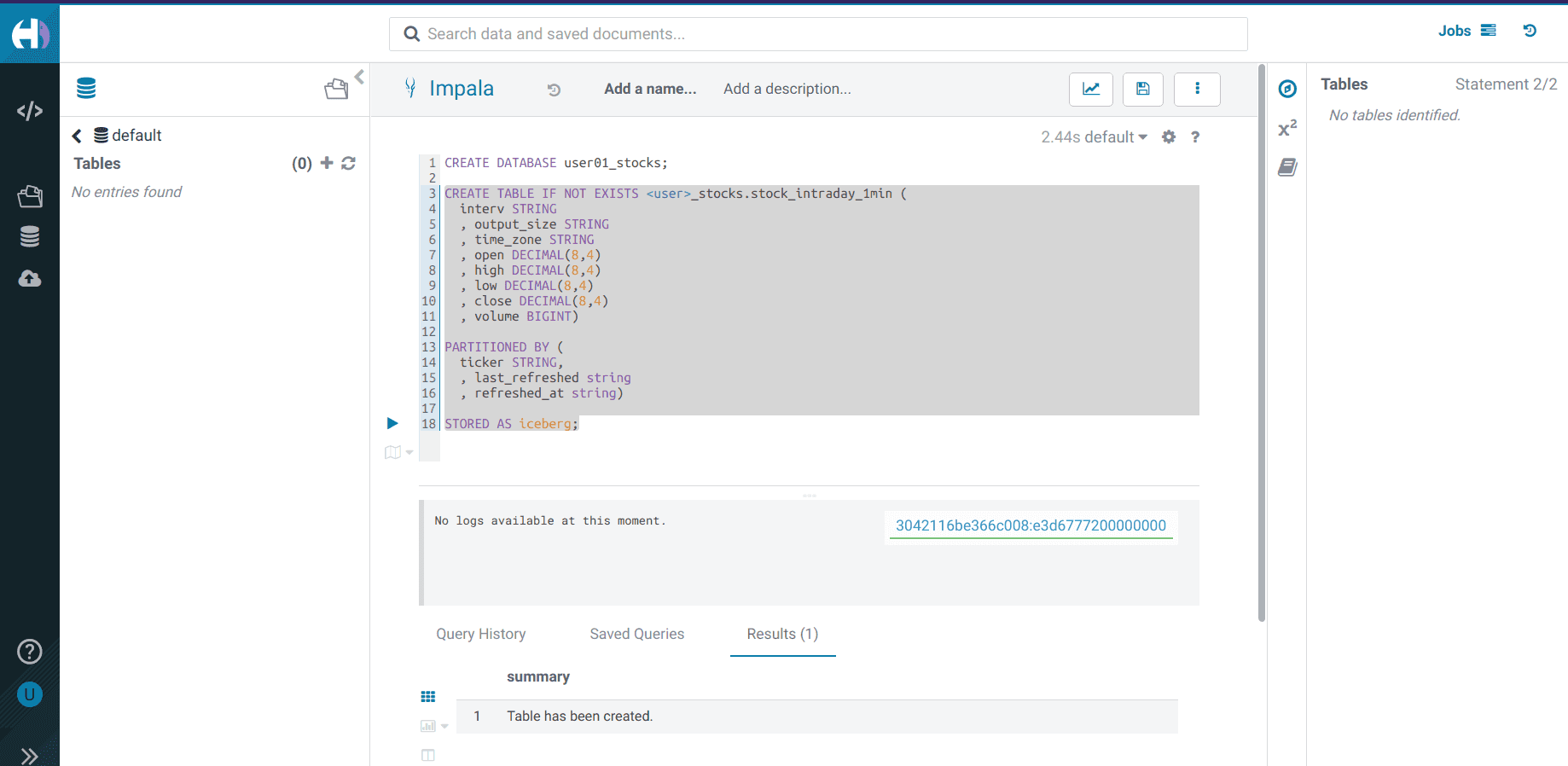
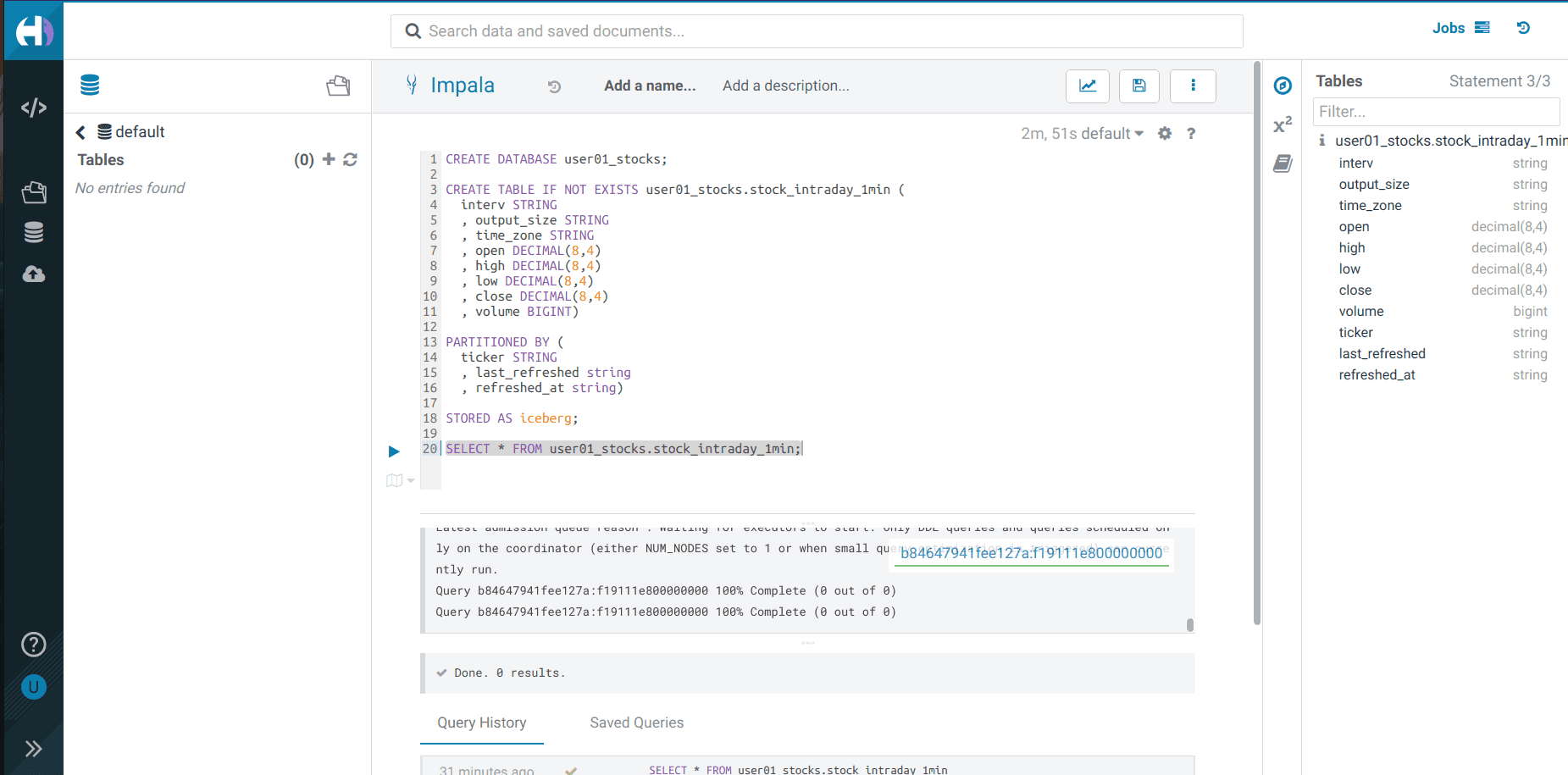
Dans cette database, créez une table Iceberg
stock_intraday_1min:CREATE TABLE IF NOT EXISTS <username>_stocks.stock_intraday_1min ( interv STRING , output_size STRING , time_zone STRING , open DECIMAL(8,4) , high DECIMAL(8,4) , low DECIMAL(8,4) , close DECIMAL(8,4) , volume BIGINT) PARTITIONED BY ( ticker STRING , last_refreshed string , refreshed_at string) STORED AS iceberg;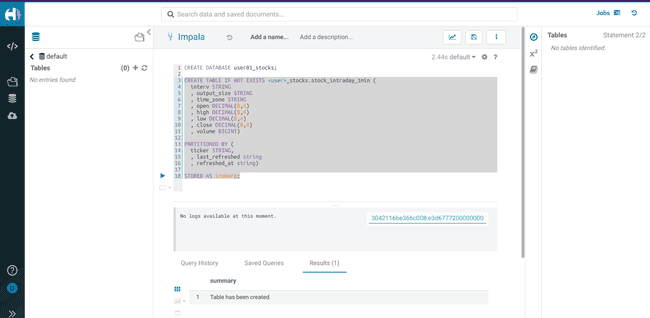
-
Lancez un
SELECTpour vérifier que les permissions nécessaires sont bien configurées :SELECT * FROM <username>_stocks.stock_intraday_1min;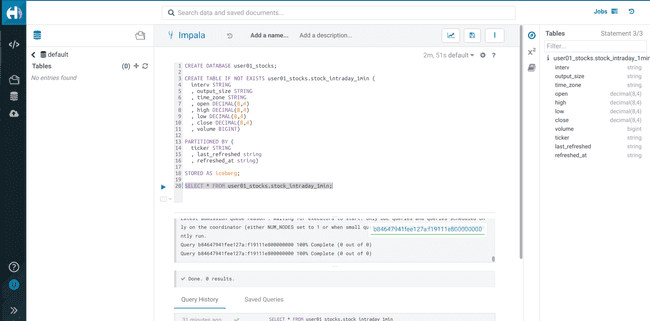
Création d’un pipeline pour le chargement des données
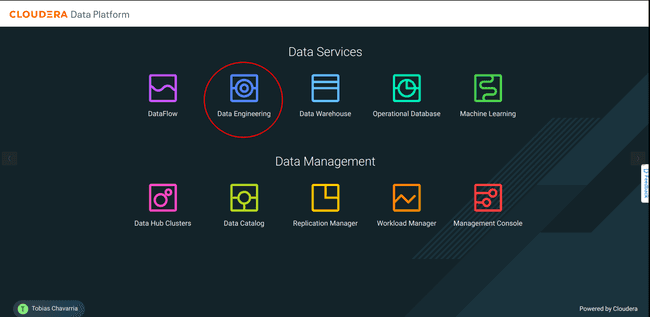
Maintenant que notre table Iceberg est prête et que notre donnée est stockée dans le Data Lake, nous allons devoir créer un pipeline de chargement. Ce pipeline va devoir détecter de nouveaux fichiers dans le Data Lake et charger leur contenu dans la table Iceberg. Nous allons utiliser à cette occasion le service Data Engineering qui, pour rappel, repose sur Apache Spark.
A partir de la console CDP :
-
Téléchargez le fichier
.jarcontenant un job Apache Spark déjà compilé : stockdatabase_2.12-1.0.jar -
Sélectionnez Data Engineering
-
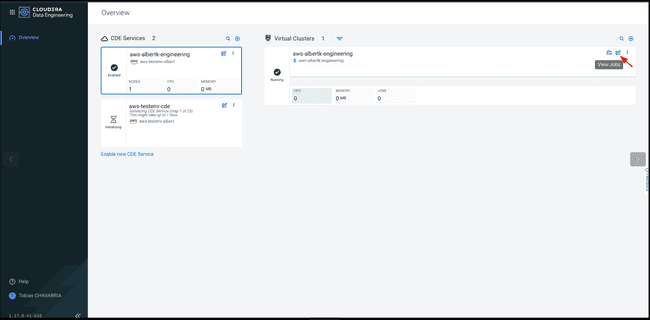
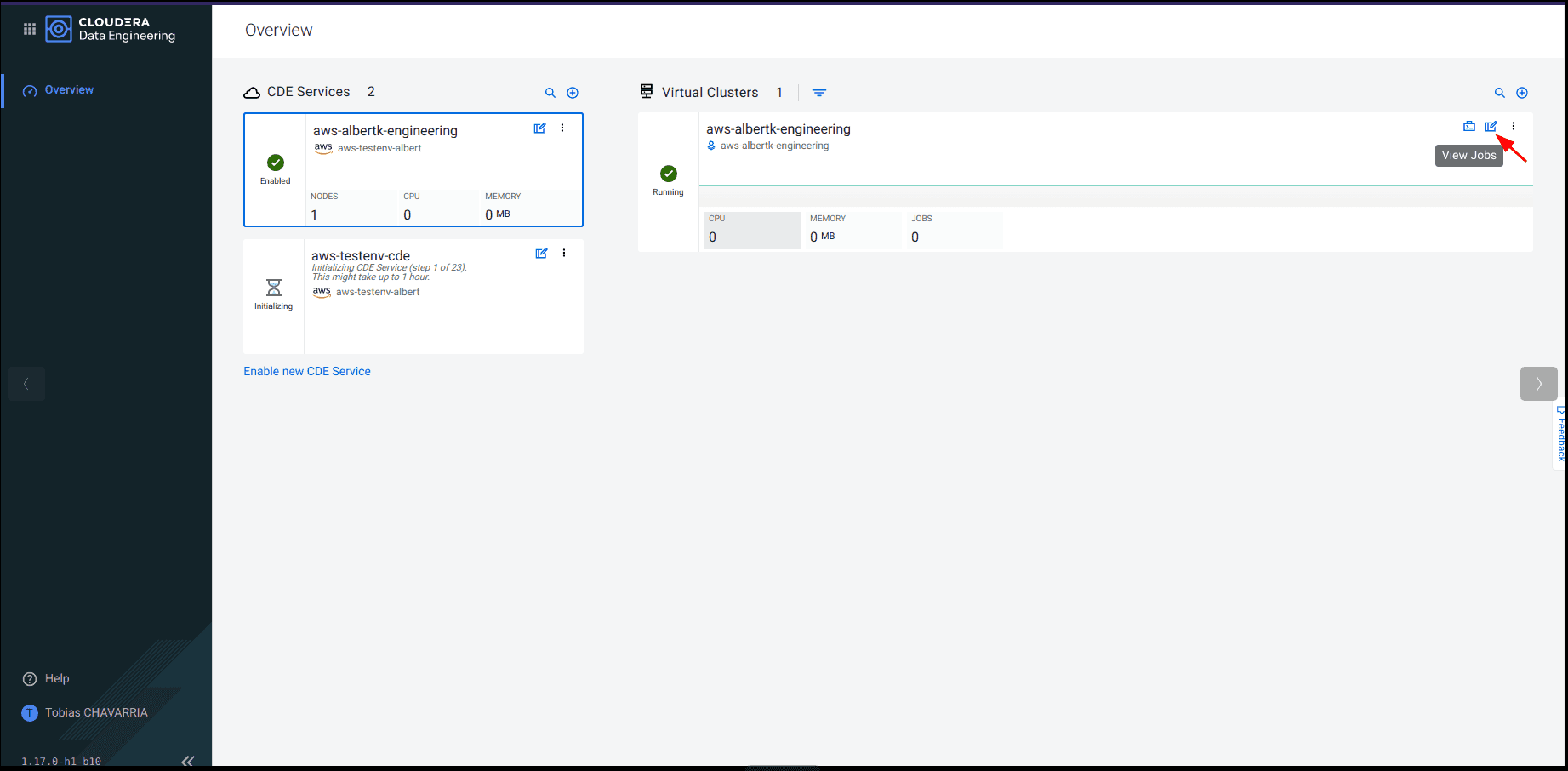
Sur le Virtual Cluster disponible, cliquer sur le bouton View Jobs situé dans le coin supérieur droit du panneau.
-
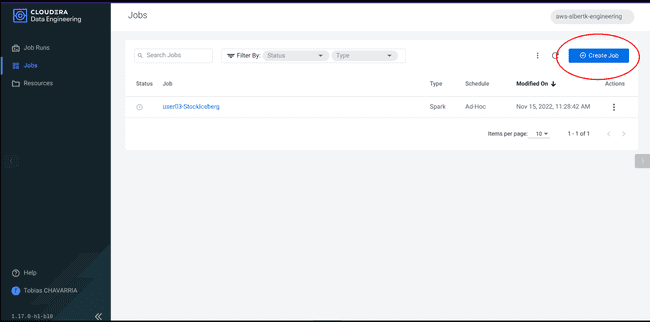
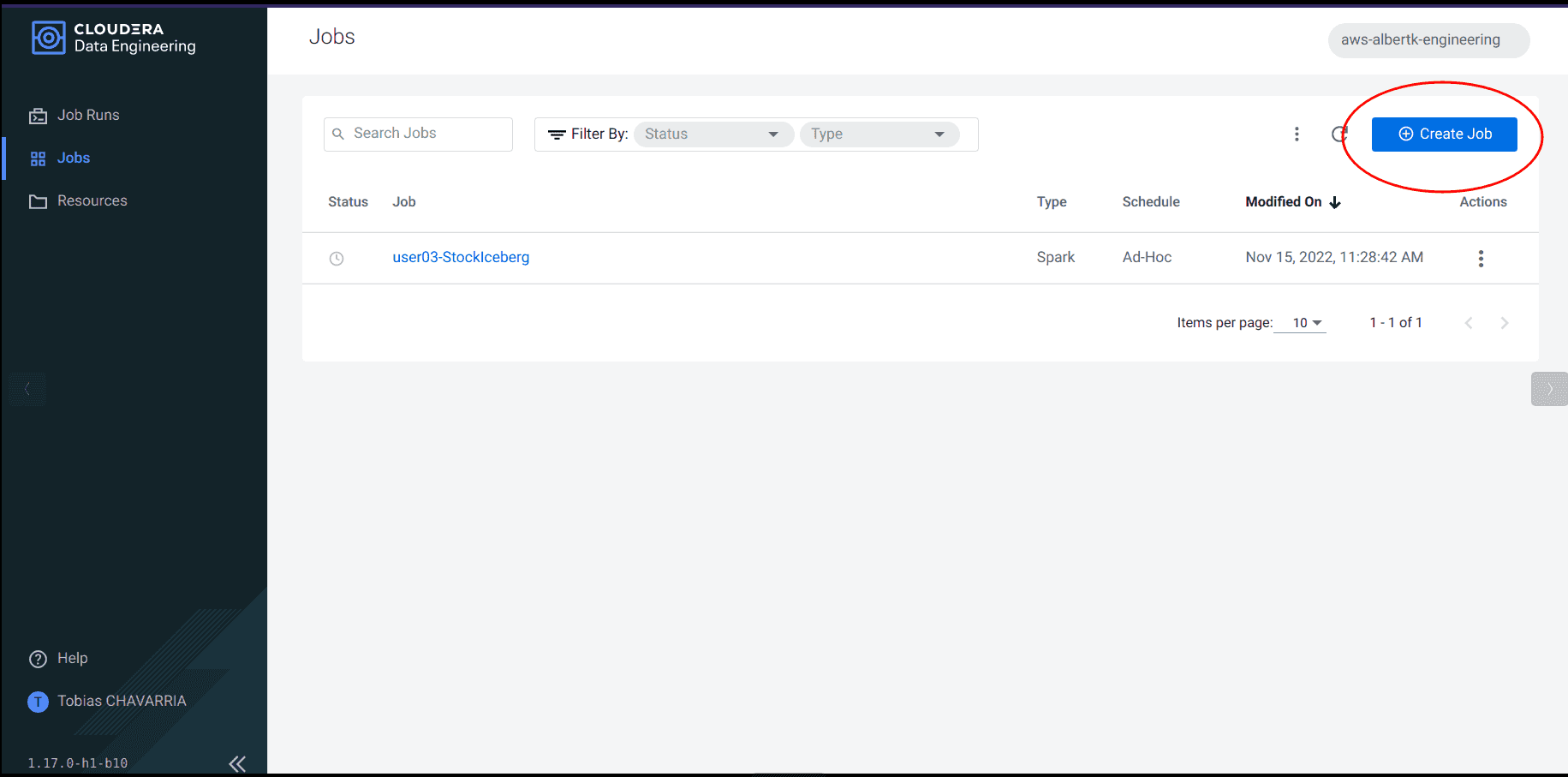
Aller sur l’onglet Jobs et cliquer sur Create a Job
-
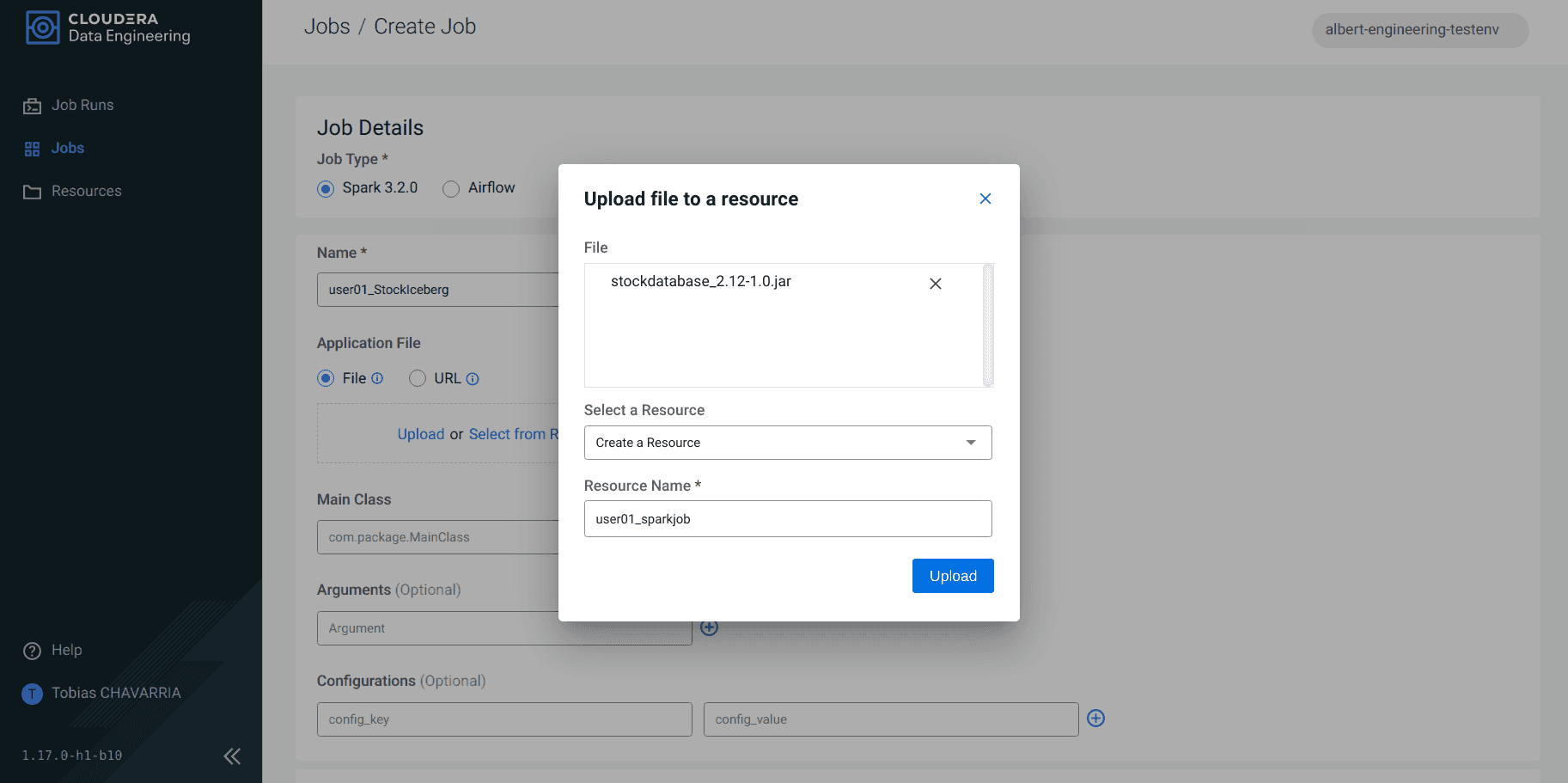
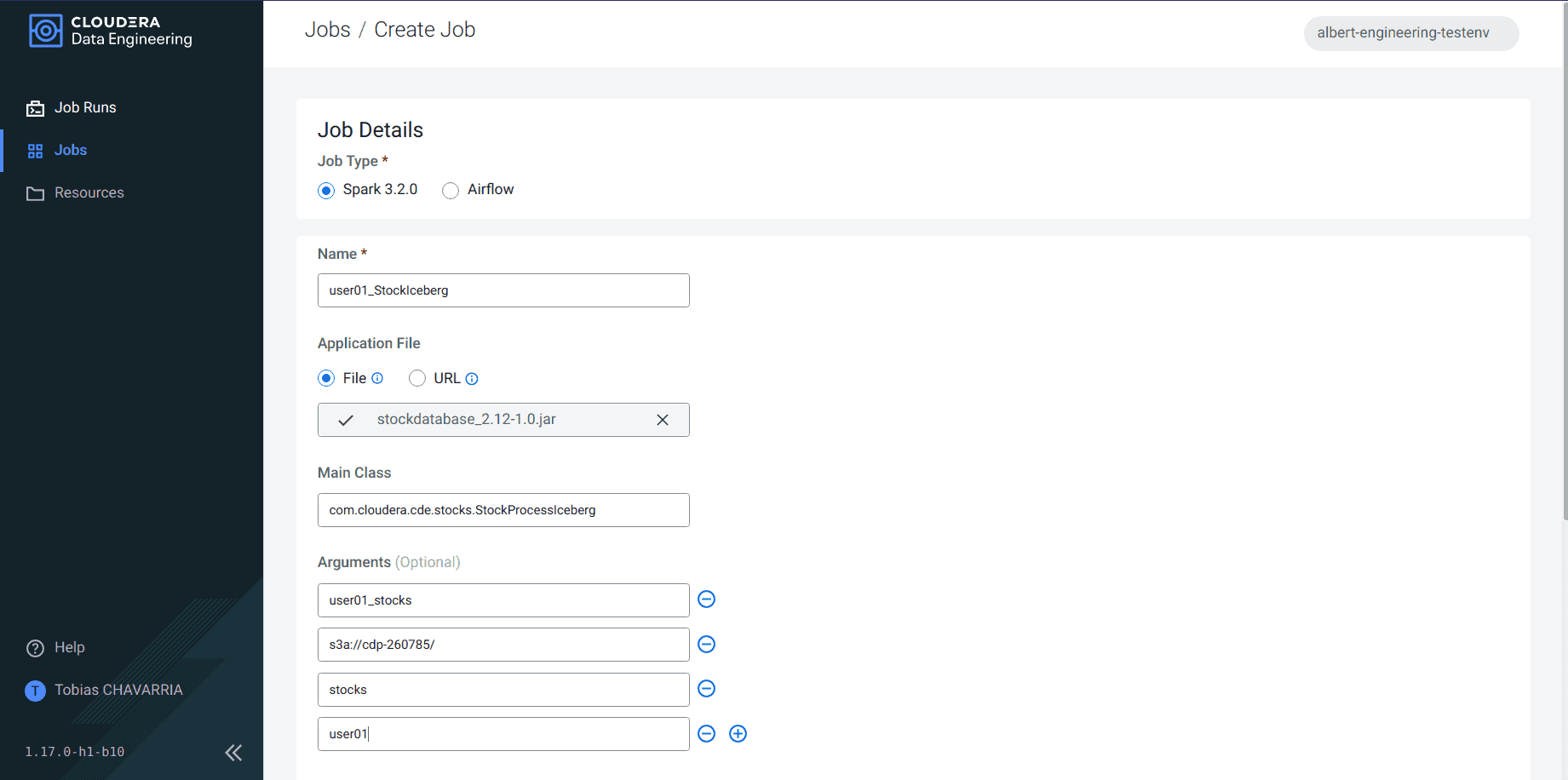
Renseigner les Job details :
- Job type :
Spark 3.2.0 - Name :
<username>_StockIceberg - Application File :
Upload- File : stockdatabase_2.12-1.0.jar
- Select a Resource :
Create a Resource - Resource name :
<username>_sparkjob
- Main Class :
com.cloudera.cde.stocks.StockProcessIceberg - Arguments :
<username>_stockss3a://<data lake's bucket>/stocks<username>
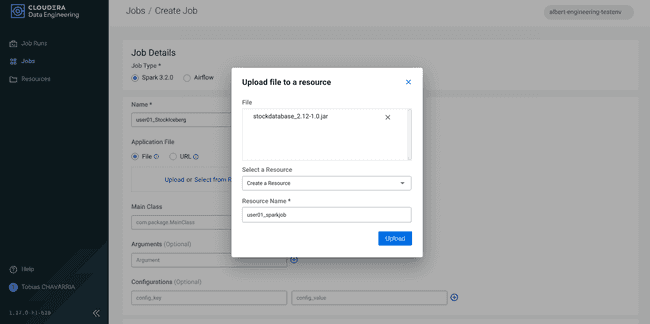
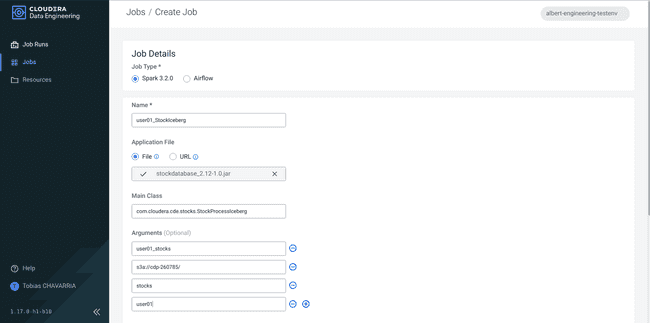
- Job type :
-
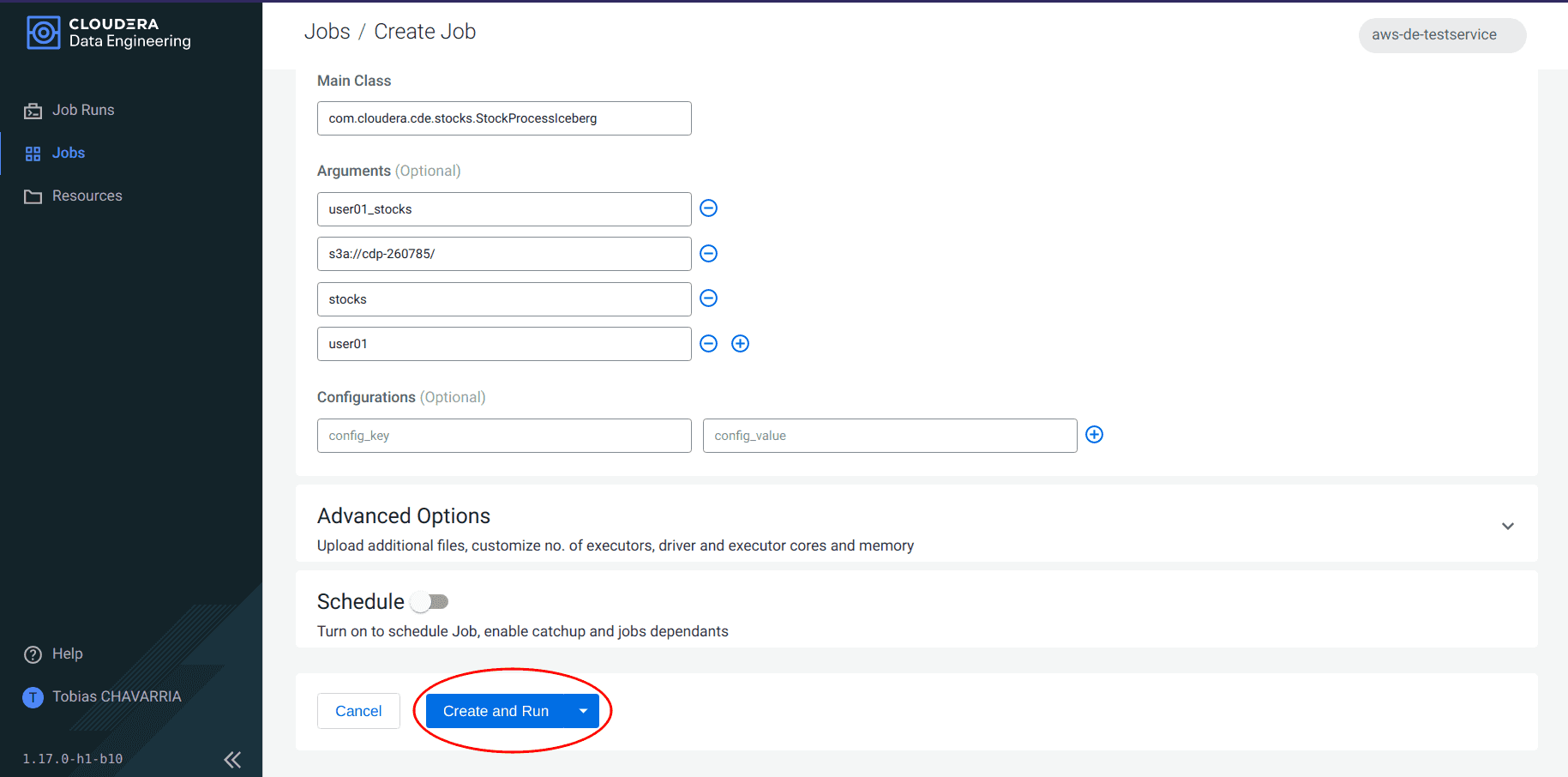
Cliquer sur Create and Run
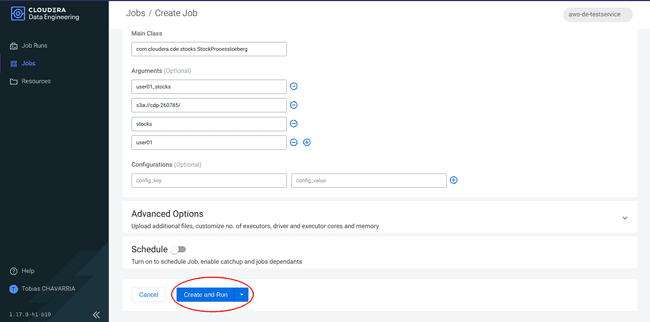
-
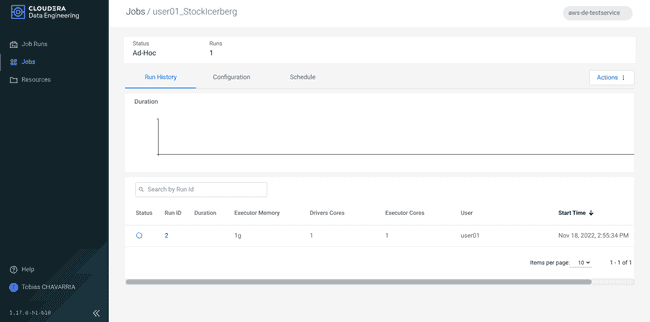
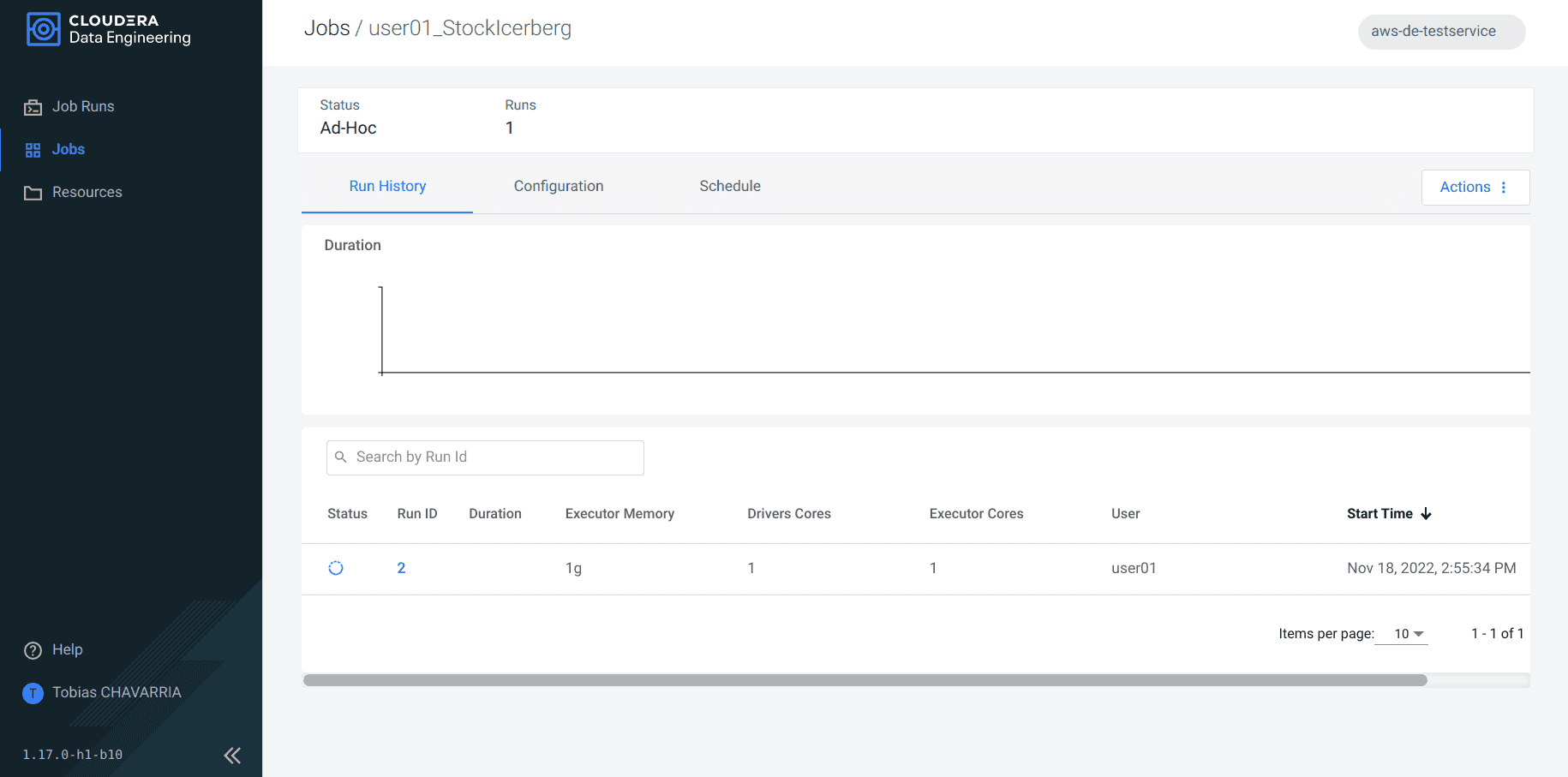
Cliquer sur Jobs dans le panneau de gauche et sélectionner le job créé précédemment pour vérifier son statut.
L’application lancée effectue les actions suivantes :
- Scrute l’arrivée de nouveaux fichiers dans le répertoire
new - Création d’une table temporaire dans Spark et identification des lignes en doublon (au cas où NiFi a chargé deux fois les mêmes données)
MERGE INTOsur la table de destination, ce quiINSERTles nouvelles lignes etUPDATEles lignes existantes.- Archivage des fichiers dans le bucket
- Après l’exécution, les fichiers traités restent dans le bucket S3 mais sont déplacés dans le répertoire
processed-data.
Couche de présentation : un dashboard dans CDP Data Visualization
La dernière étape de notre architecture bout-en-bout est de mettre en place la solution d’exploration de la donnée. Pour cela, nous utiliserons l’outil de Data Visualization incluse dans le service Data Warehouse.
Création d’un Dataset
-
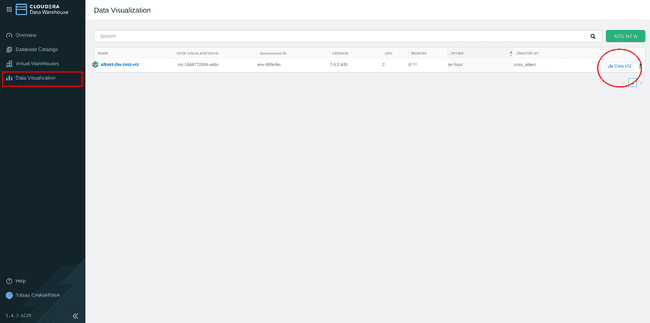
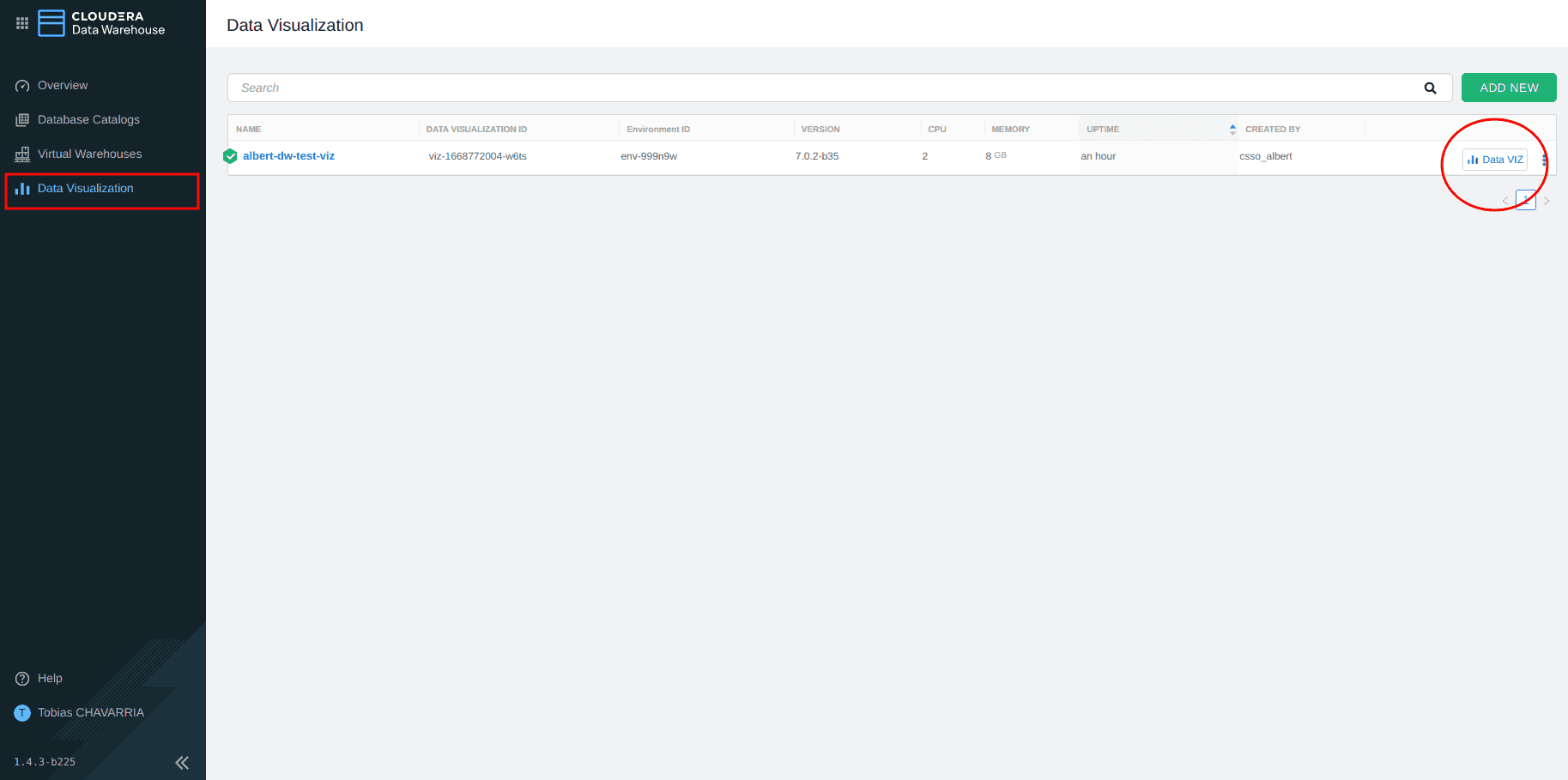
Retournez au niveau de Cloudera Data Warehouse
-
Dans le menu de gauche, choisir : Data Visualization et cliquer sur le bouton Data VIZ situé à droite.
-
Tout en haut de l’écran, cliquer sur DATA
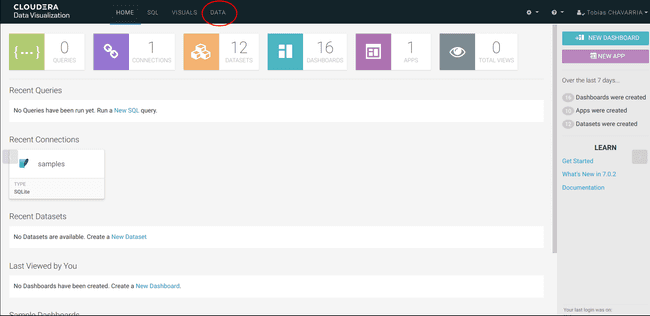
-
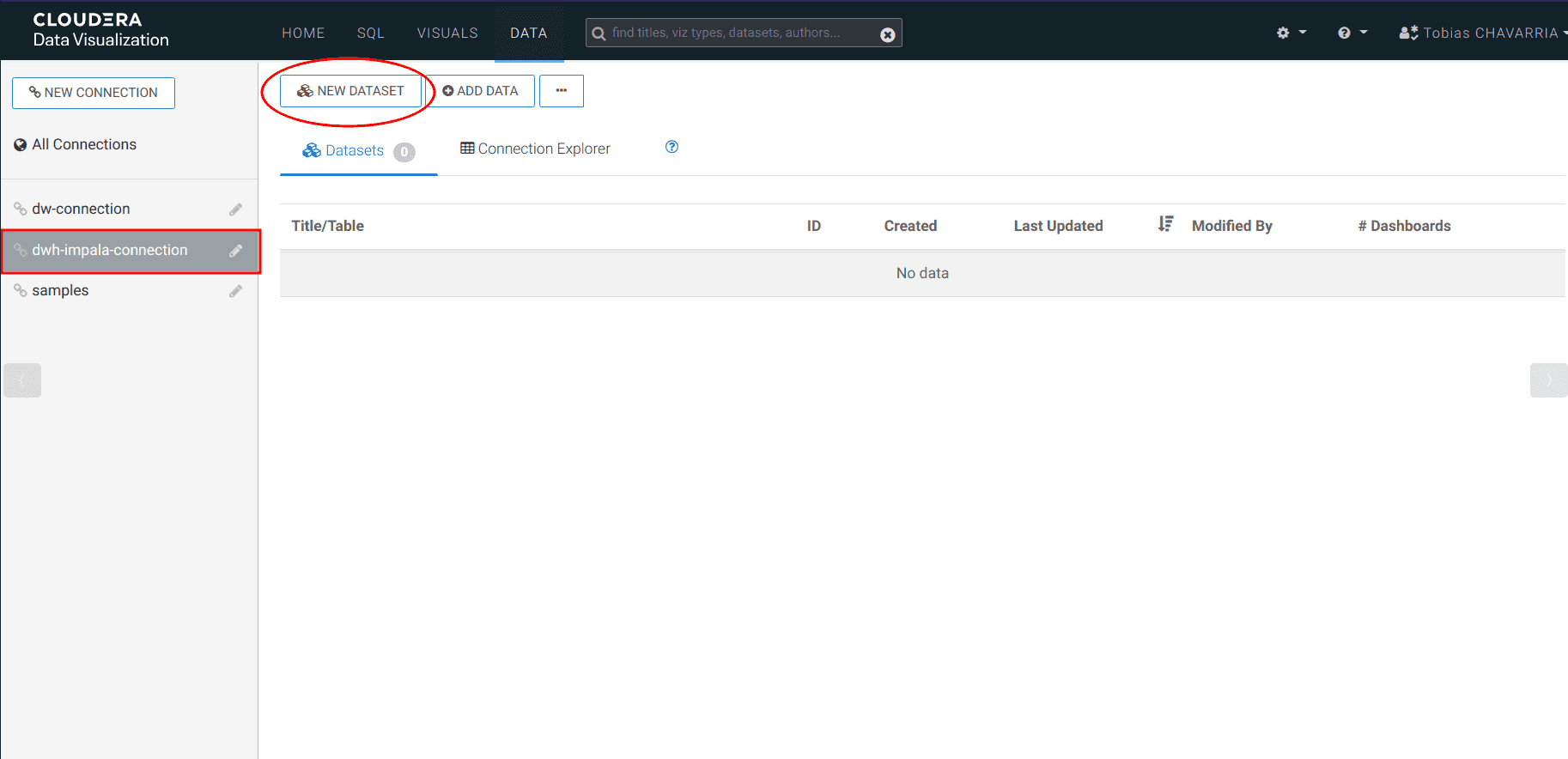
Sur la gauche, sélectionner la connexion dwh-impala-connection
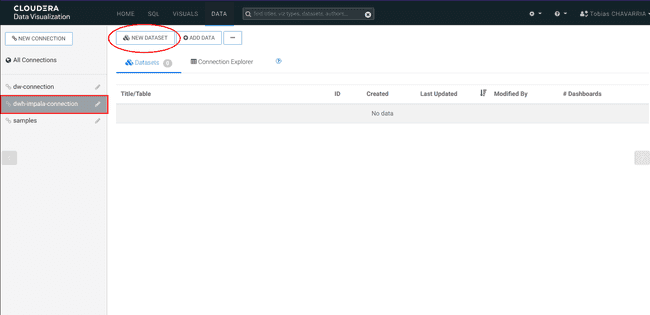
-
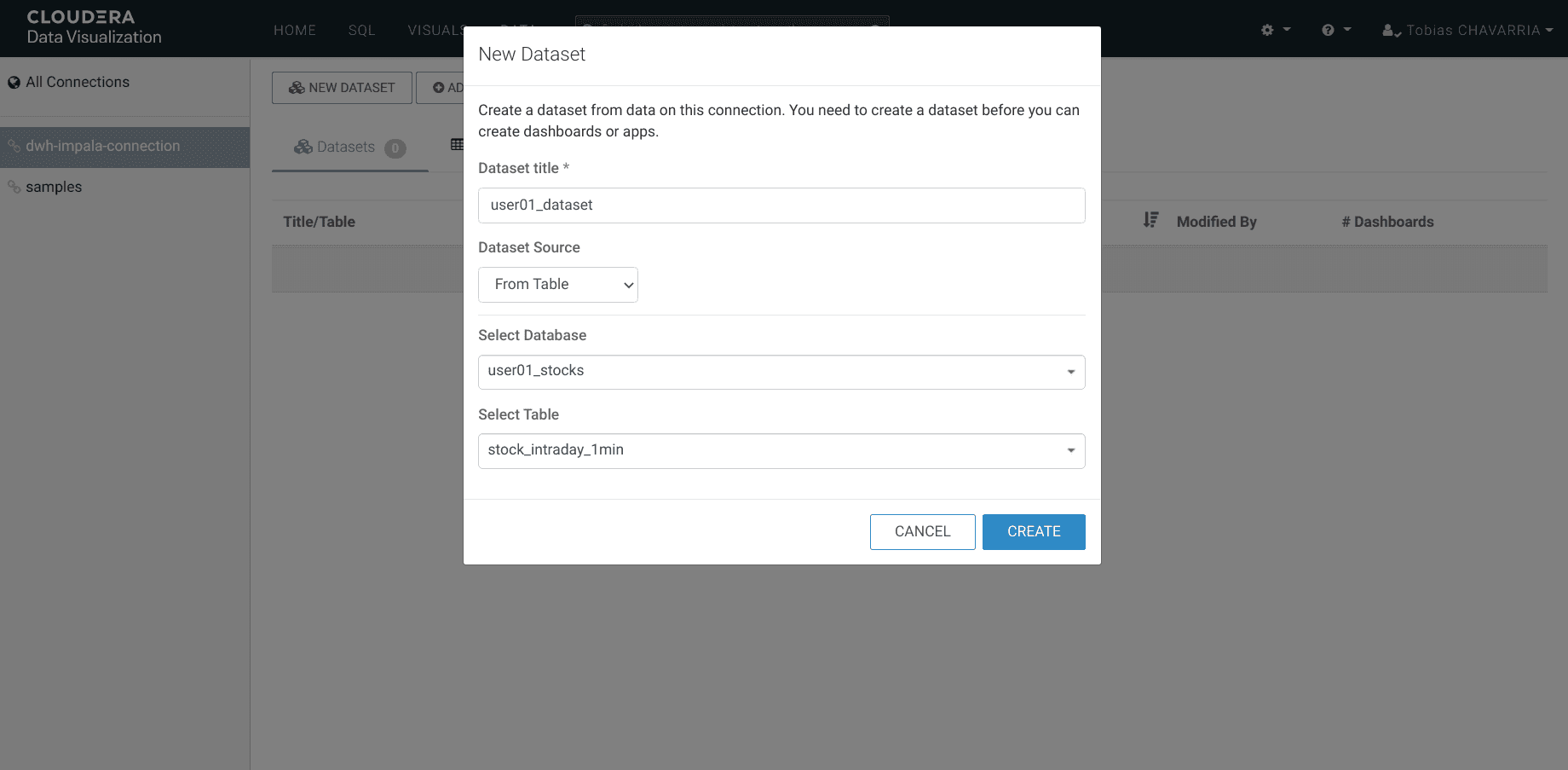
Puis cliquer sur NEW DATASET et saisir :
- Dataset title :
<username>_dataset - Dataset Source :
From Table - Select Database :
<username>_stocks - Select Table :
stocks_intraday_1min - Create
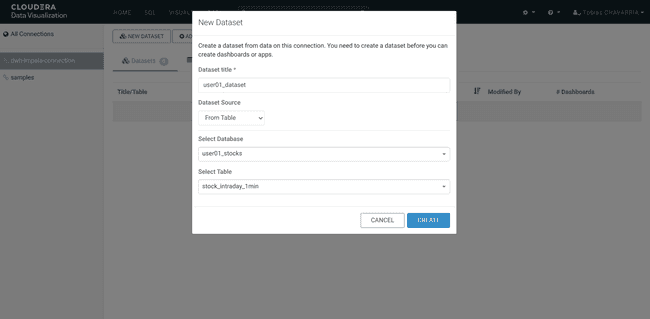
- Dataset title :
Création d’un dashboard
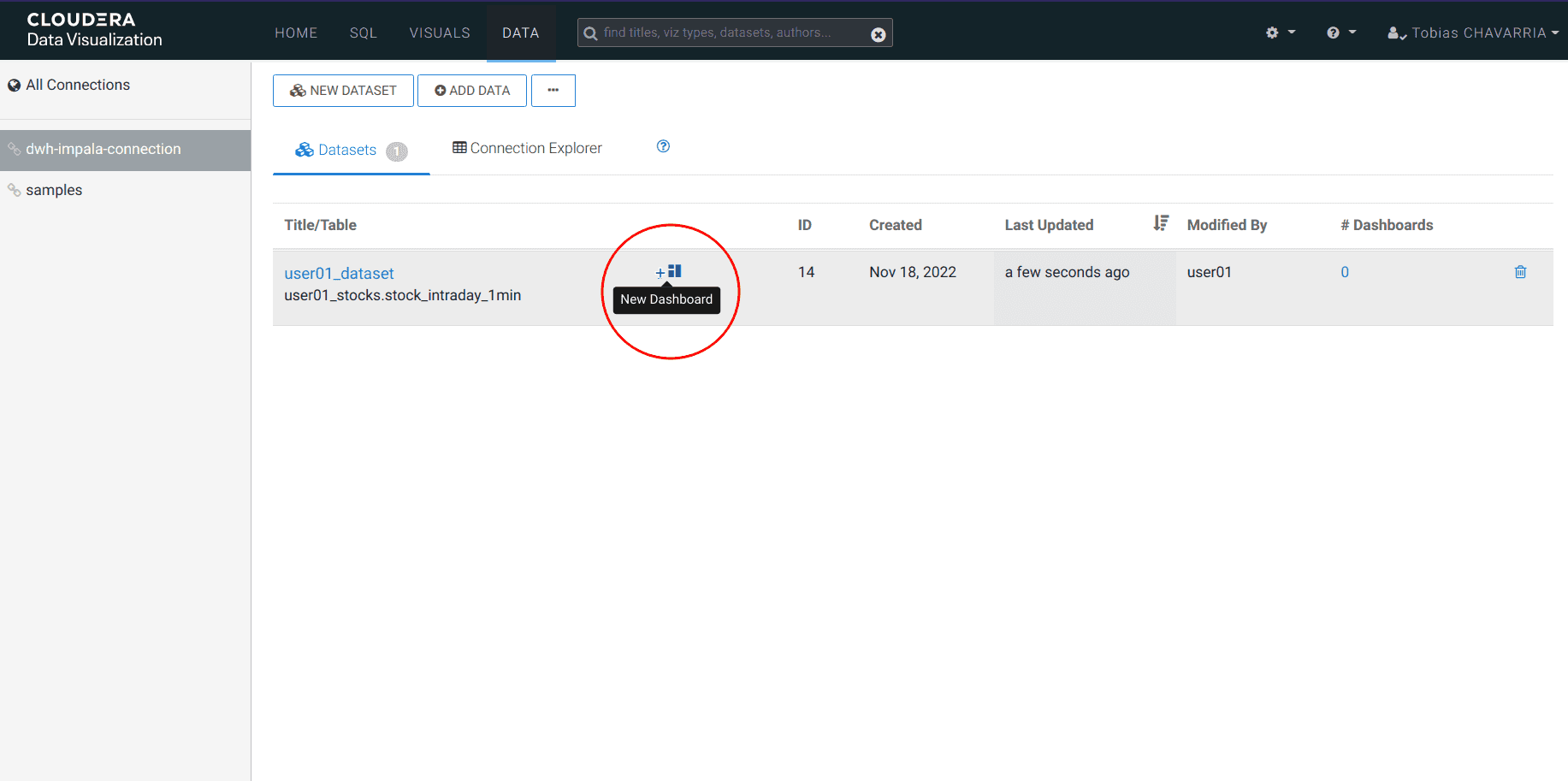
-
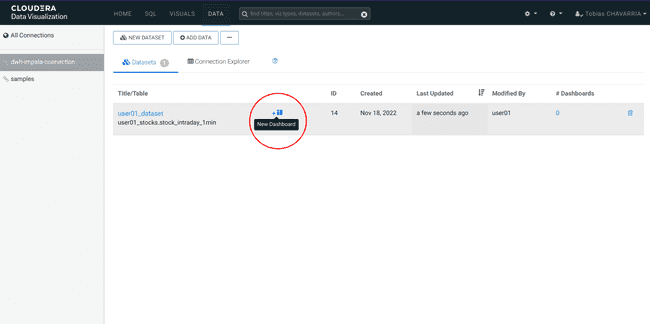
Cliquer sur New Dashboard
-
Attendre quelques secondes, jusqu’à obtenir l’écran suivant :
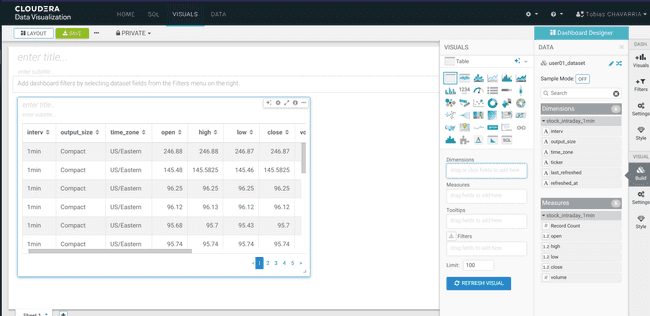
-
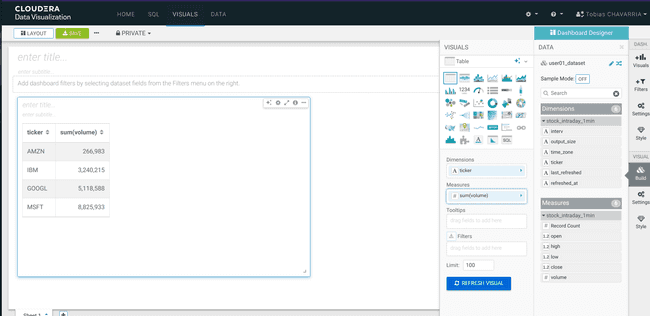
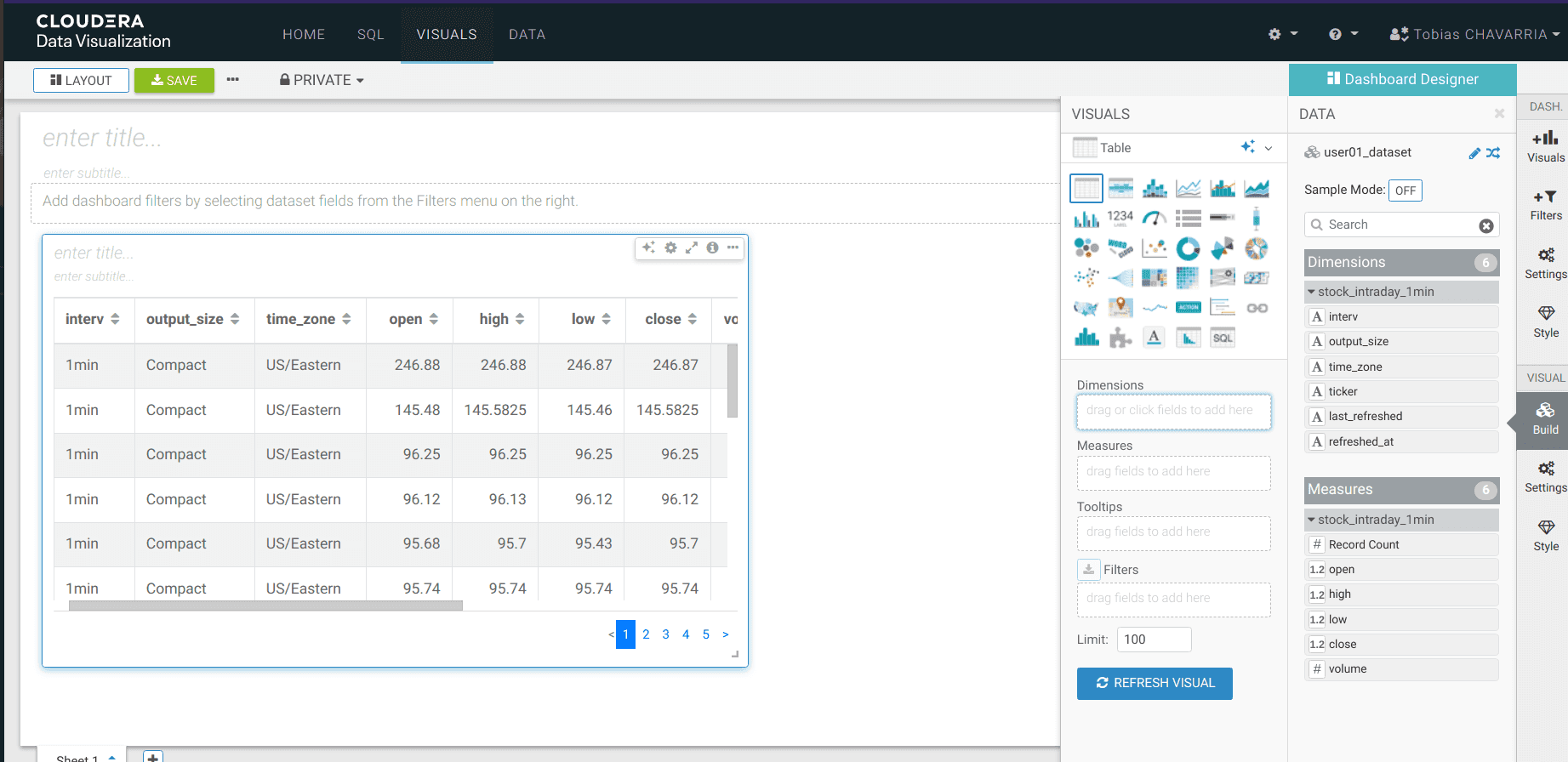
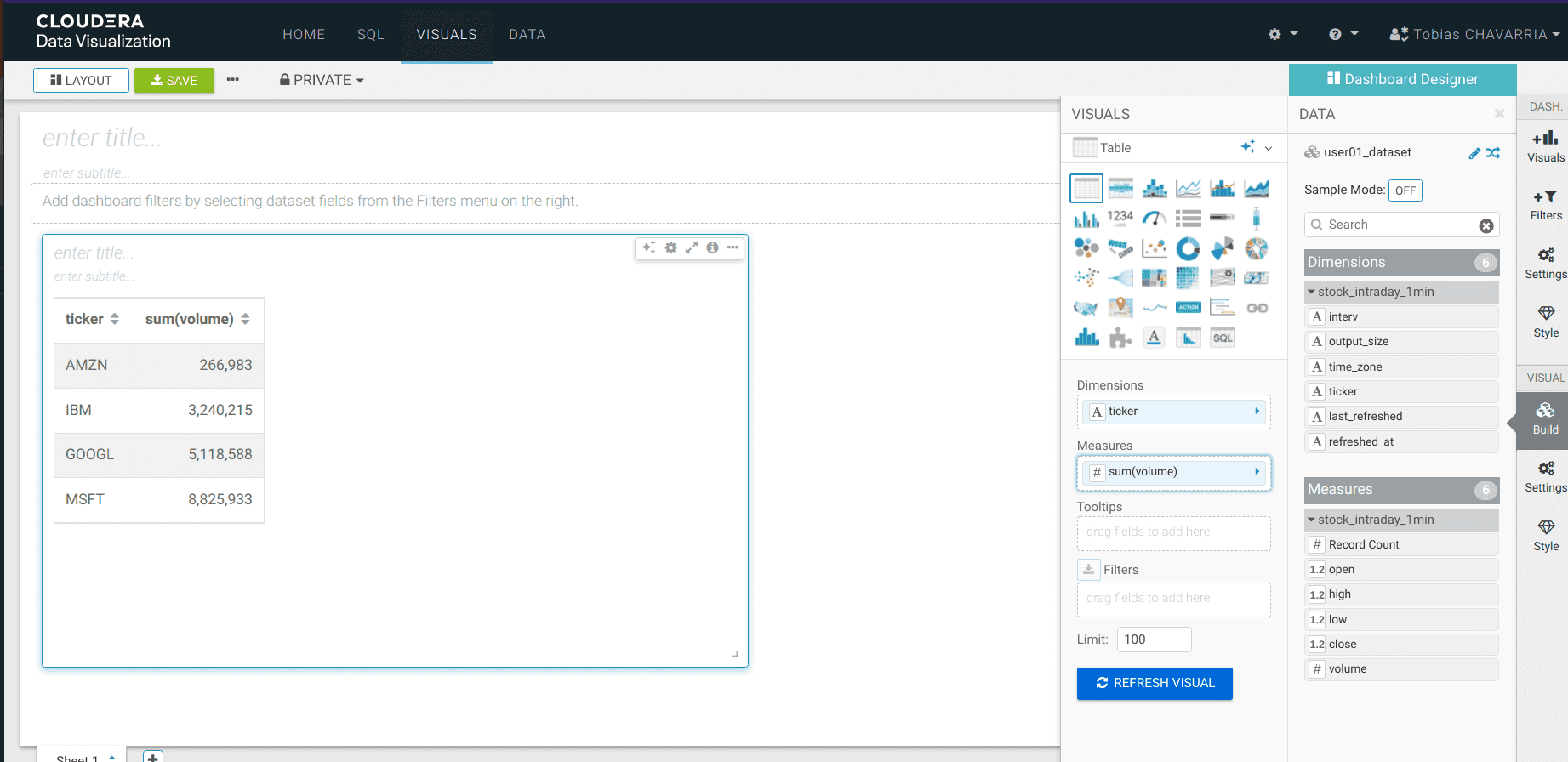
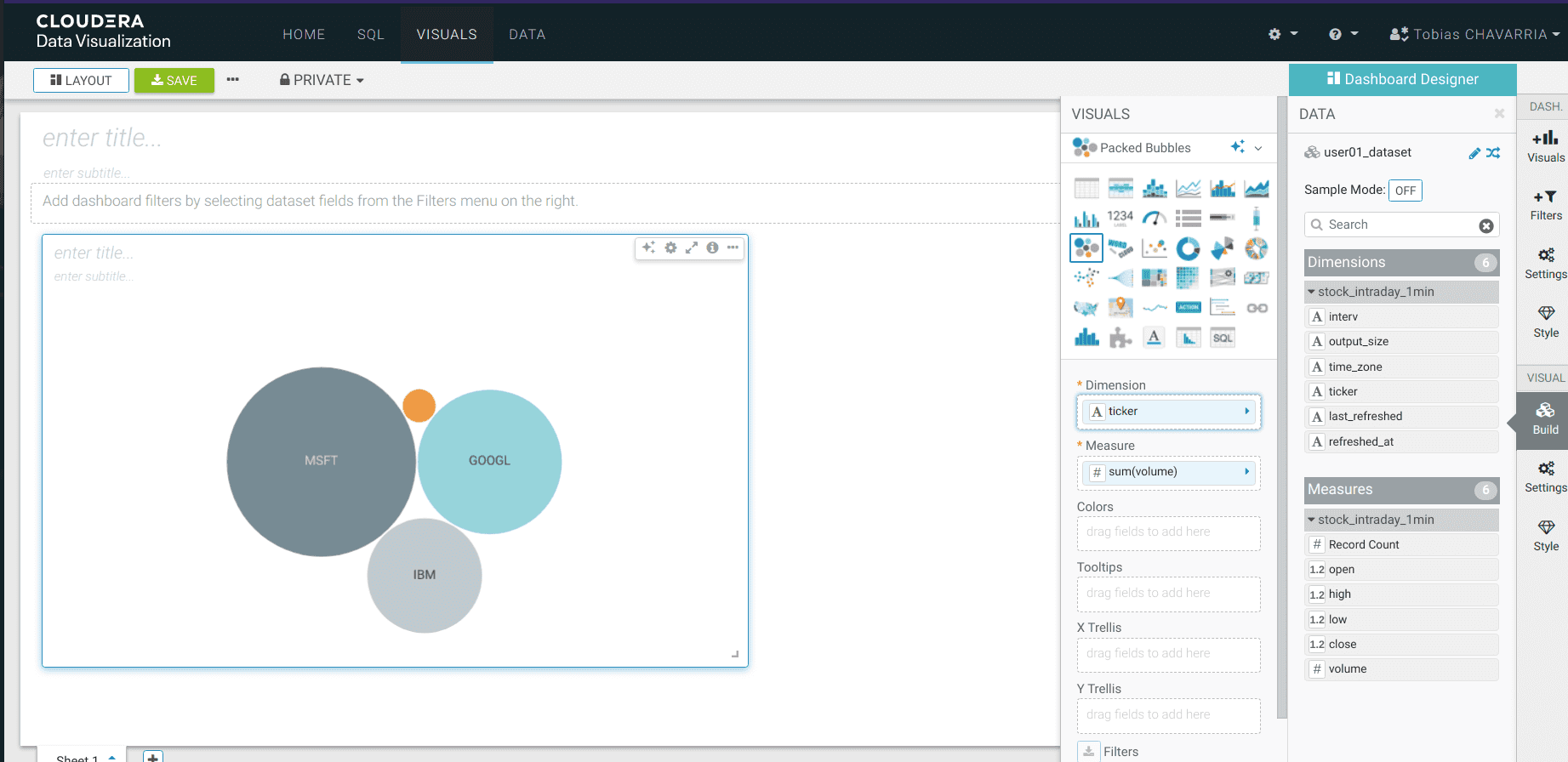
Depuis la barre d’outils DATA, glisser les informations suivantes vers la barre Visuals :
- Dimensions :
ticker - Measure :
volume REFRESH VISUAL- Visuals ->
Packed Bubbles
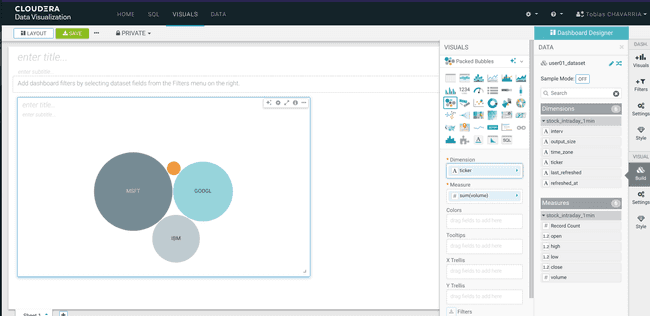
- Dimensions :
-
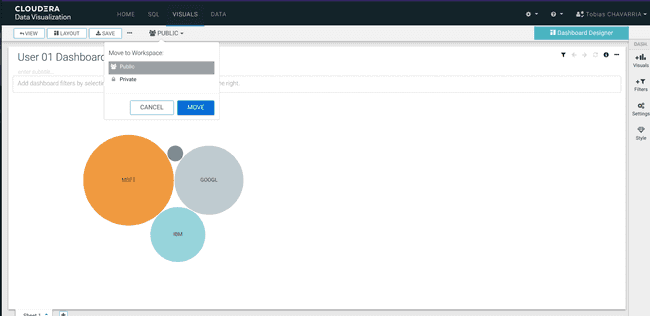
Enregistrer le Dashboard et le rendre public
- Saisir un titre :
<username> Dashboard - Aller dans le coin supérieur gauche et cliquer sur
Save - Modifier :
Private->Public - Cliquer sur Move
- Saisir un titre :
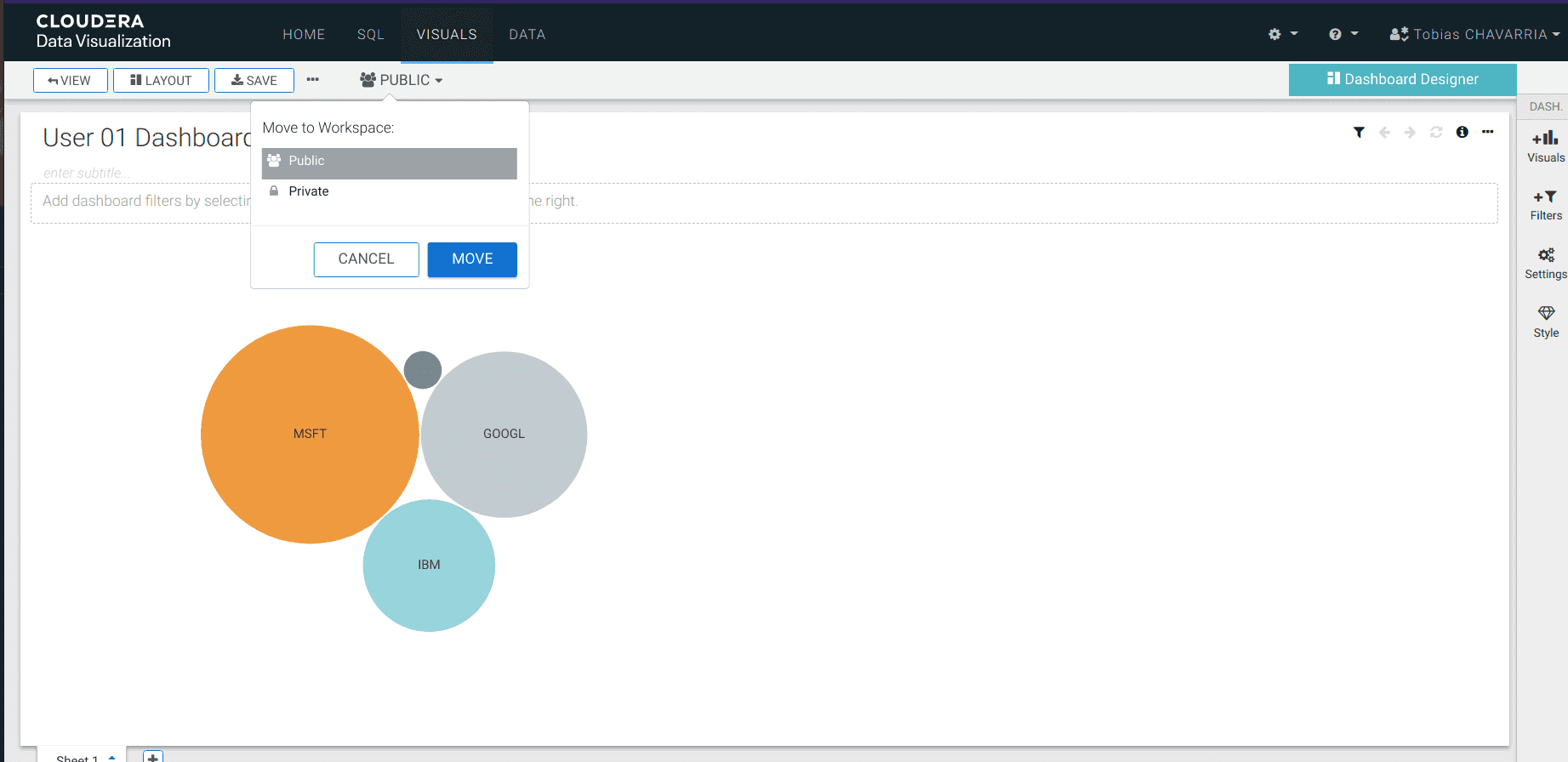
Et le tour est joué ! Vous avez créé une solution big data bout-en-bout de traitement de la donnée grâce à CDP Public Cloud. Enfin, suivons une cotation supplémentaire et enregistrons-la dans Data Warehouse.
Snapshots Iceberg
Remontons l’historique de la table Iceberg :
-
Retourner dans l’éditeur Hue
-
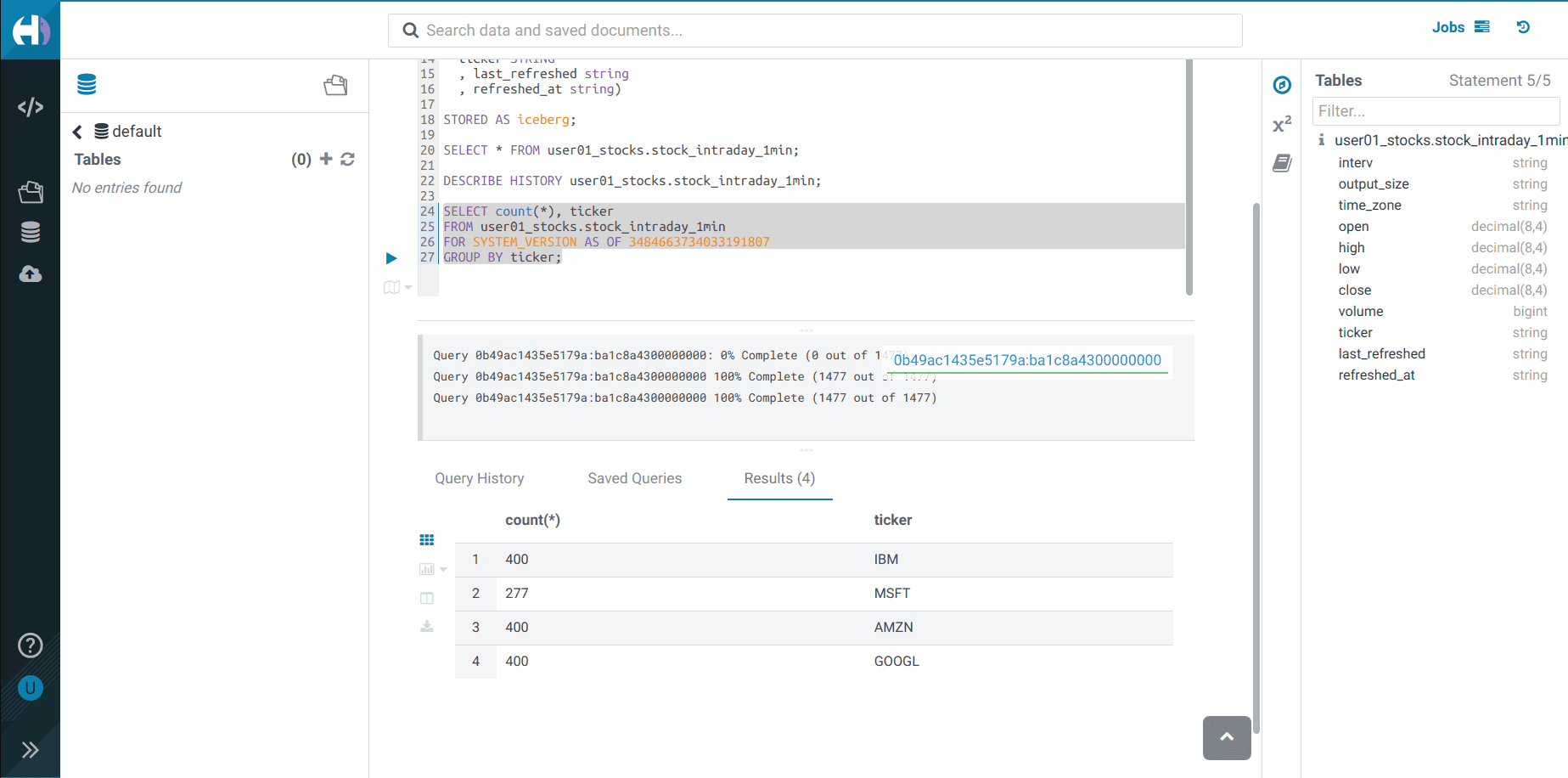
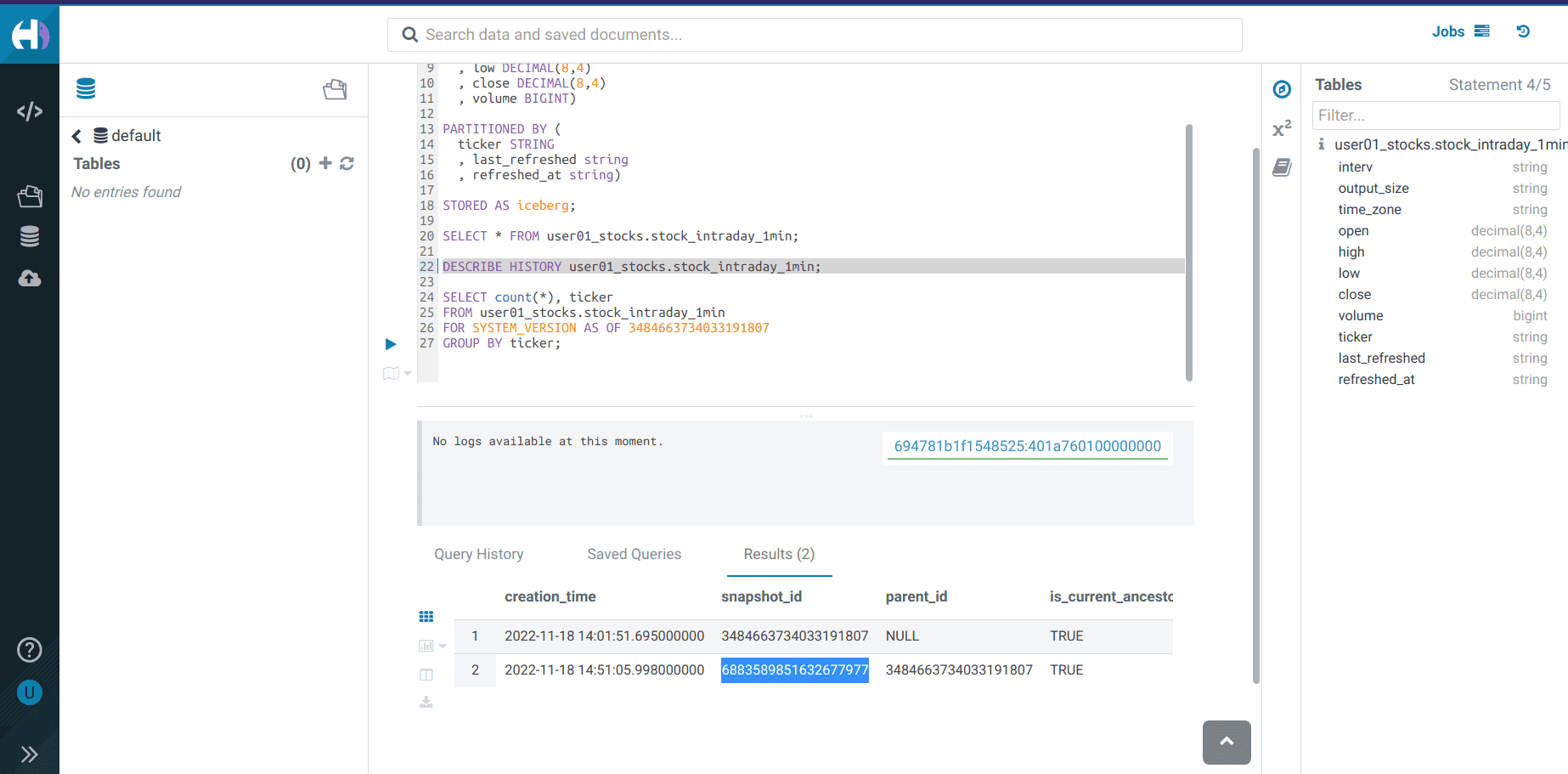
Exécuter la requête suivante et prendre note du
<snapshot_id>DESCRIBE HISTORY <username>_stocks.stock_intraday_1min;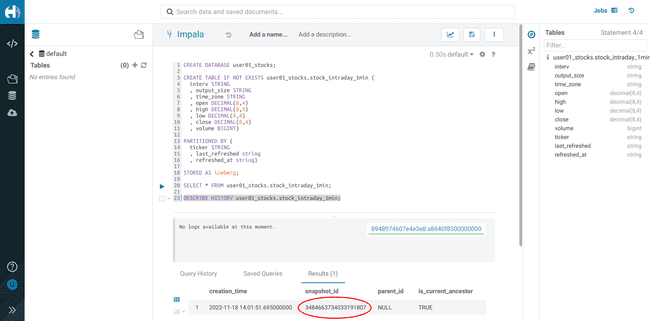
-
Exécuter la requête Impala :
SELECT count(*), ticker FROM <username>_stocks.stock_intraday_1min FOR SYSTEM_VERSION AS OF <snapshot_id> GROUP BY ticker;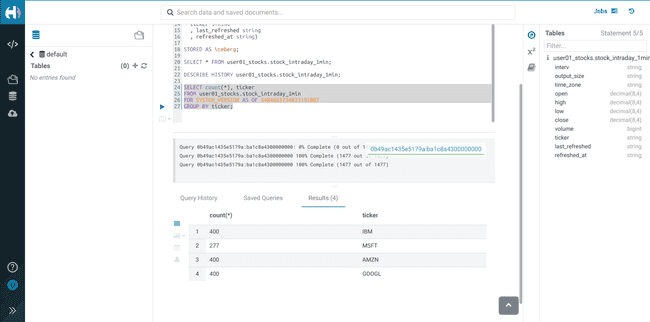
Ajouter un nouveau cours d’actions
-
Retournez au [Deployment Manager]](#voir_l_execution_du_flux_dans_nifi) du Flow NiFi
-
Sélectionner Parameters
-
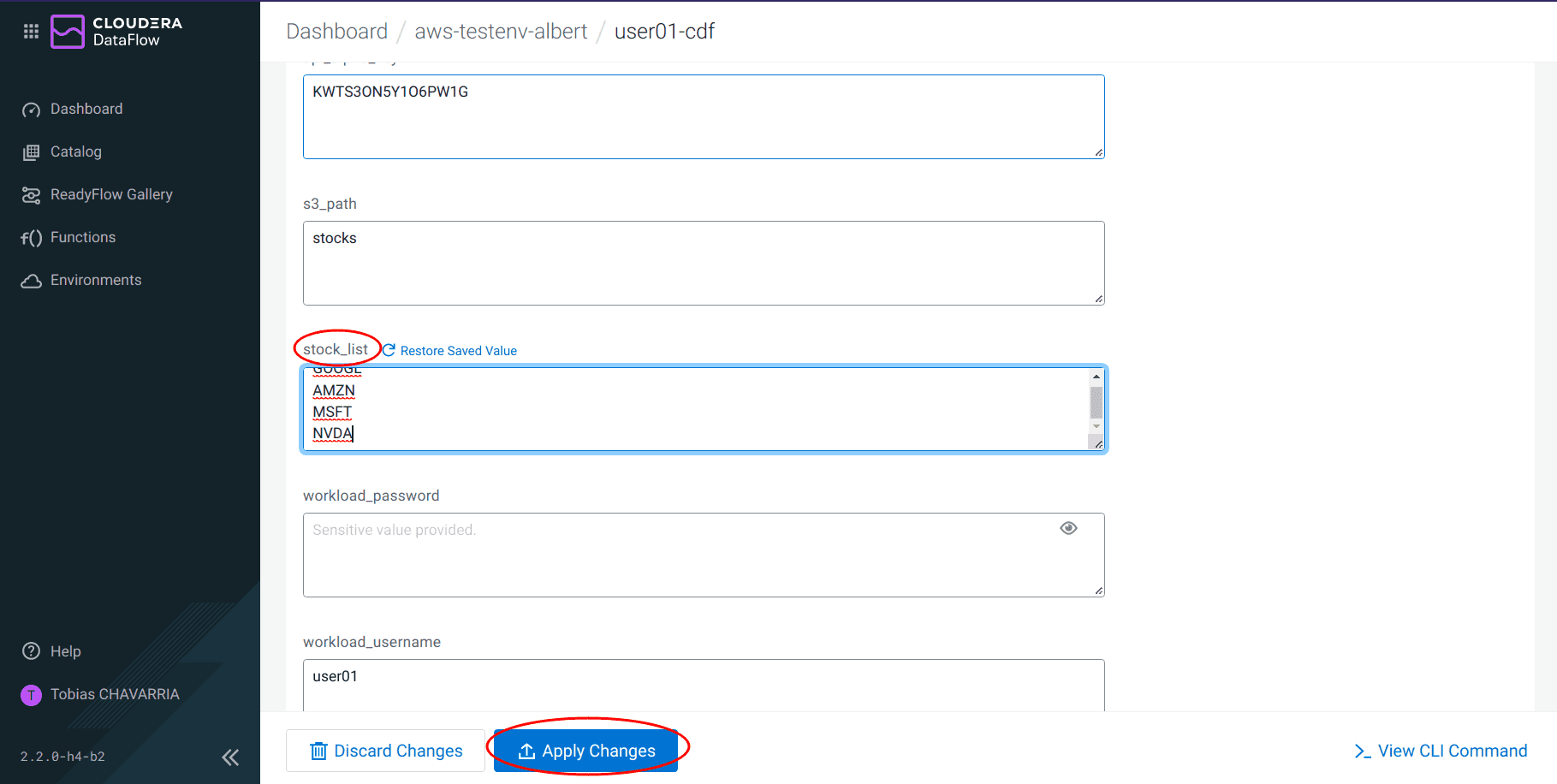
Ajouter dans les valeurs du paramètre
stock_listl’action NVDA (NVIDIA), et cliquer sur Apply Changes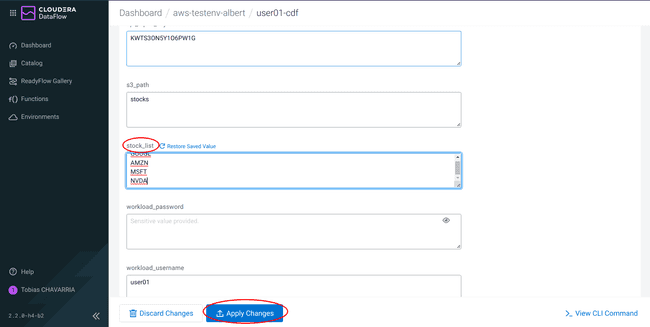
-
Une fois les modifications appliquées, cliquer sur Actions, Start flow
Relancer le job Spark
-
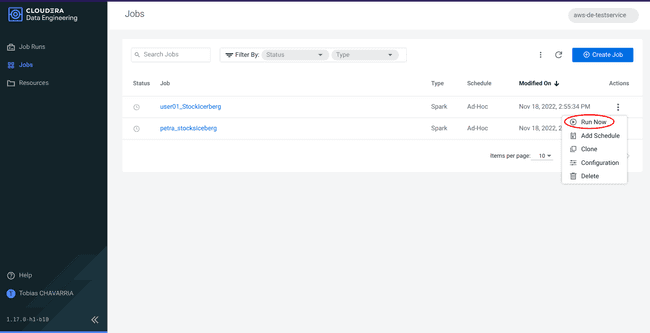
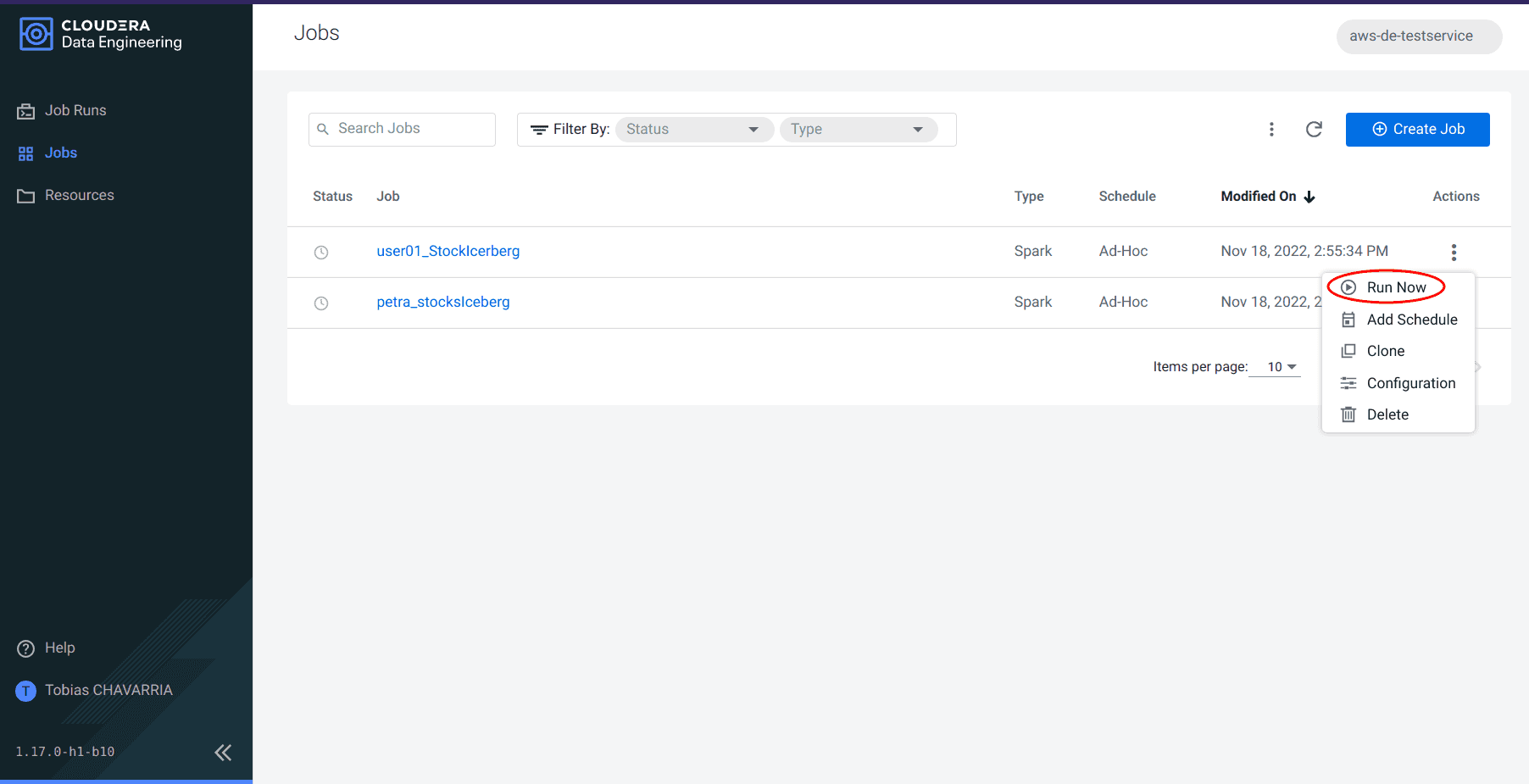
Retournez dans le service Data Engineering, dans l’onglet Jobs
-
Cliquer sur le bouton avec les 3 points correspondant à votre job et cliquer sur Run now
Consulter le nouvel historique des snapshots
-
Retournez vers l’éditeur Hue
-
Vérifier l’historique des snapshots avec la commande ci-dessous et notez le dernier
<snapshot_id>DESCRIBE HISTORY <username>_stocks.stock_intraday_1min; -
Visualiser les données du nouveau snapshot
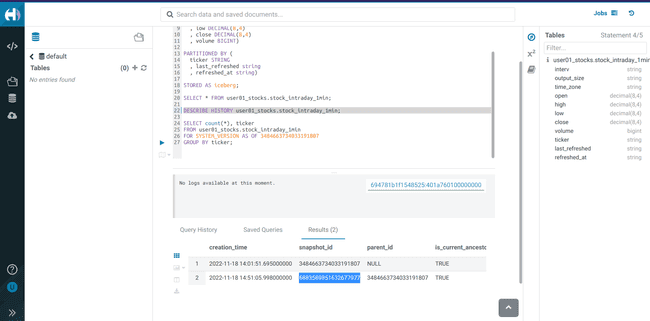
-
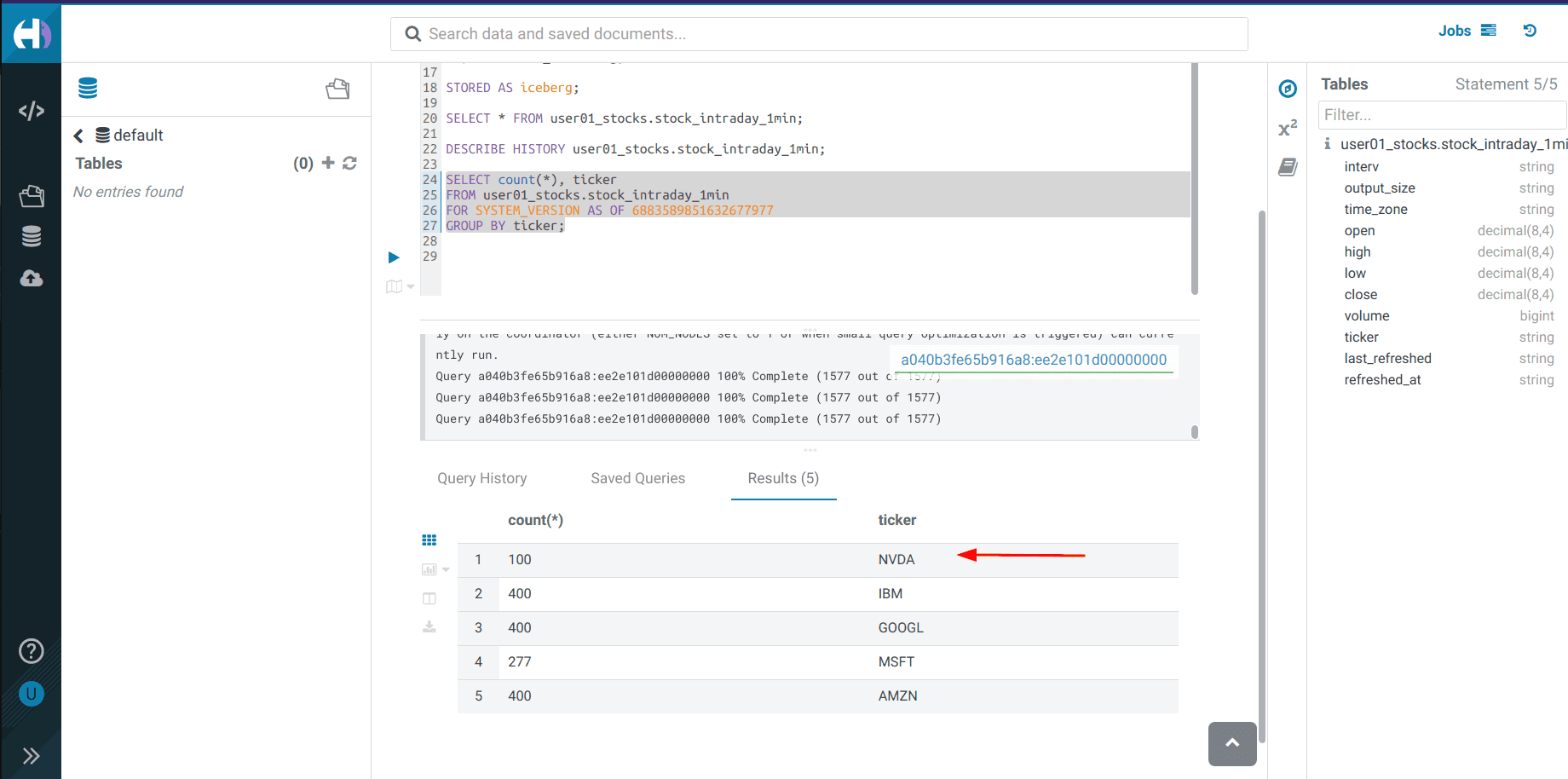
Exécuter un
SELECTen utilisant le nouveau<snapshot_id>pour voir que les données du nouveau cours de bourse ont été ajoutées.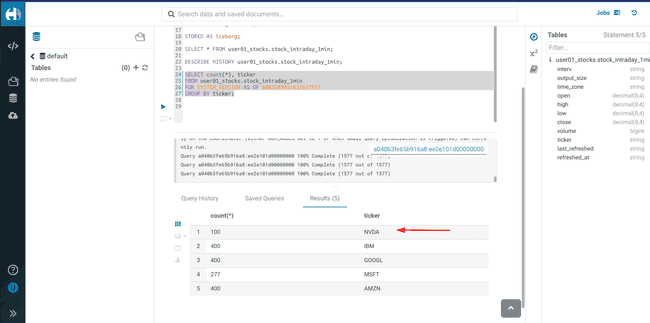
-
Lancer la requête suivante, sans snapshot, pour récupérer l’intégralité des données, sur l’ensemble des snapshots parents et enfants.
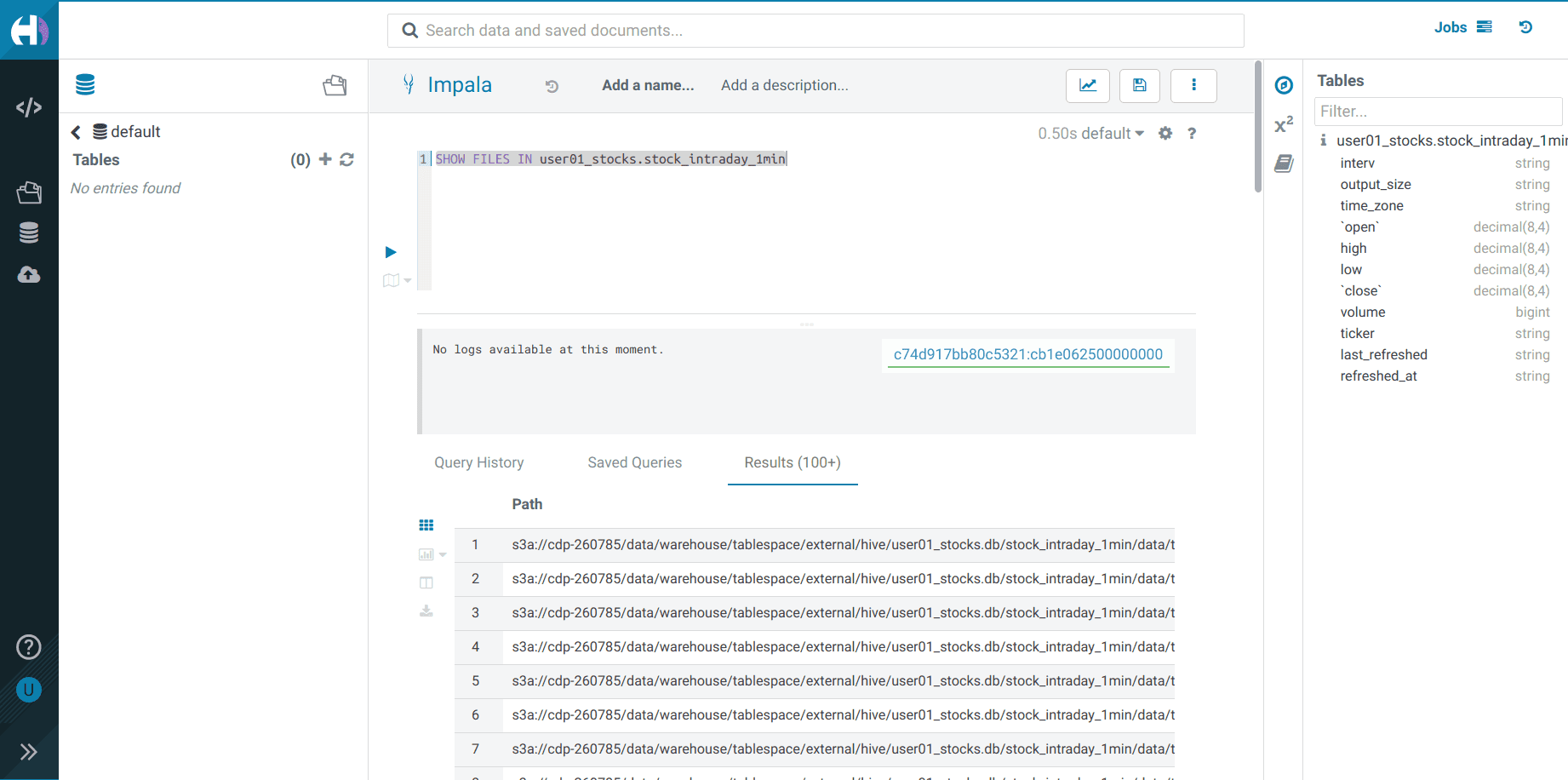
SELECT * FROM <username>_stocks.stock_intraday_1min -
Pour lister les fichiers dans le bucket S3 :
SHOW FILES IN <username>_stocks.stock_intraday_1min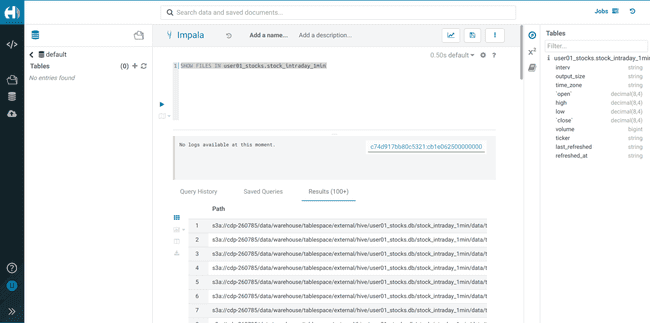
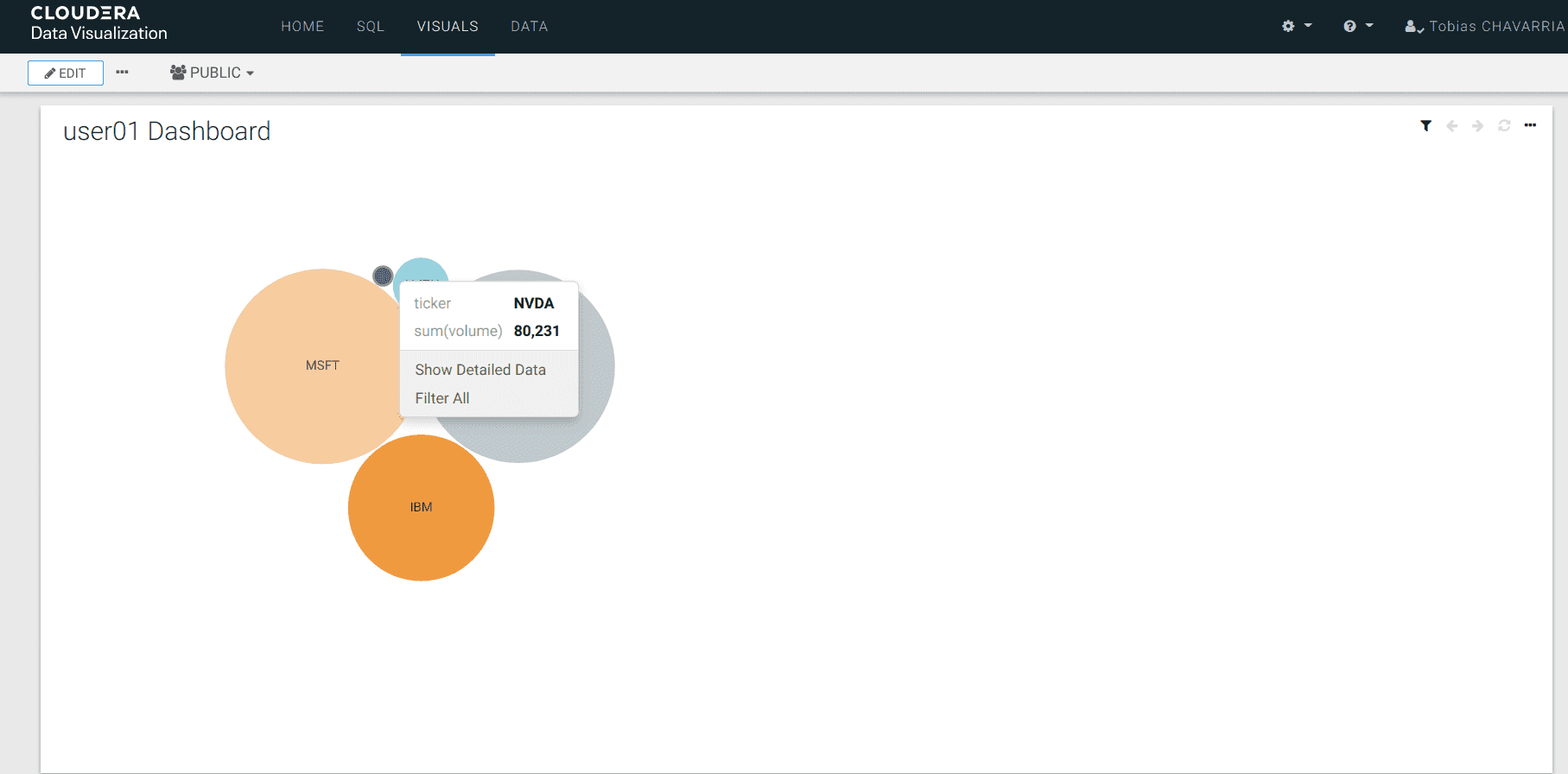
Jouer avec les graphiques
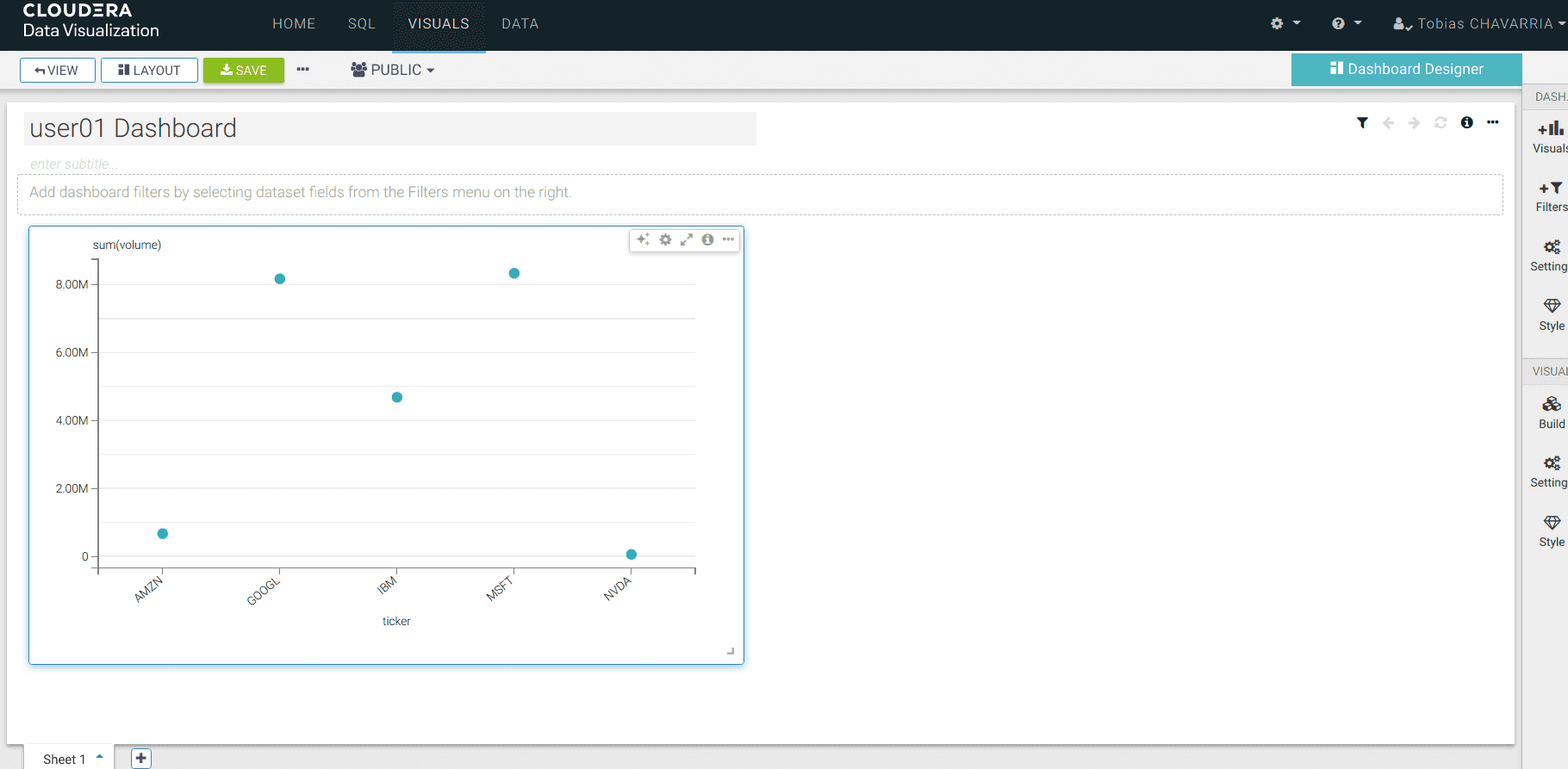
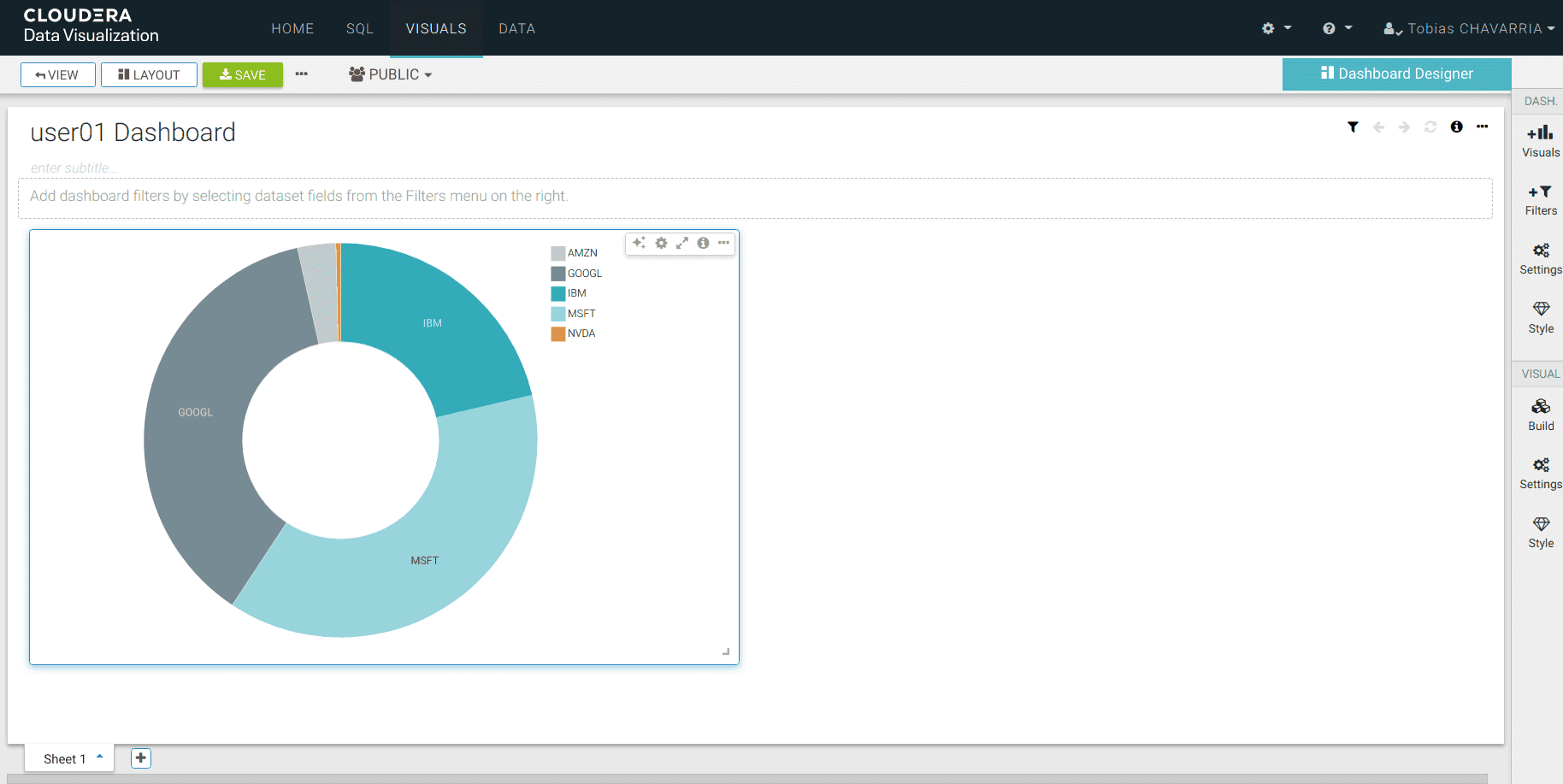
Vous pouvez retourner dans Data Visualizations et découvrir les différentes possibilités pour le dashboard.
Conclusion
Cette série a couvert toutes les tâches nécessaires à la mise en place d’une solution de pipeline d’ingénierie de données depuis le début. Nous avons commencé par déployer l’infrastructure CDP Public Cloud en utilisant les ressources AWS, configuré Keycloak pour l’authentification des utilisateurs sur ce même cluster, géré les permissions des utilisateurs et enfin construit un pipeline en utilisant les différents services CDP. Vous pouvez expérimenter certaines fonctionnalités avancées si vous le souhaitez. Cela dit, n’oubliez pas que les ressources créées sur AWS ne sont pas gratuites et que vous aurez des coûts tant que votre infrastructure sera active. N’oubliez pas de libérer toutes vos ressources AWS lorsque vous avez terminé le lab afin d’éviter des coûts non désirés.
