


Introduction à OpenLineage

19 déc. 2023
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
OpenLineage est une spécification open source de lineage des données. La spécification est complétée par Marquez, son implémentation de référence. Depuis son lancement fin 2020, OpenLineage est présent au buzzWords summit à Berlin et suscitent un intérêt croissant. Ayant personnellement assisté aux discussions entre les développeurs contribuant à ce projet, voyons les problèmes et les questionnement auxquels ils font face, les solutions retenues, la définition de la spécification et les développements en cours.
Le lineage qu’est-ce que c’est ?
Le lineage est un ensemble de relations symbolisées par des lignes reliant des tables à différents processus de traitement, en entrée ou en sortie. Dans Marquez, cela donne par exemple :

L’un des objectifs est l’identification des doublons. C’est une fonctionnalité fondamentale à toute architecture d’ingestion de données big data, et pas seulement. Avec des classifications (« tags ») comme par exemple « données à caractère personnel » ou « date d’expiration », qui se propagent avec le lineage, on peut proposer d’automatiser des traitements. Ainsi, sans lineage, une copie de table induirait de démasquer des données. En termes d’emploi, les principaux cas d’usage sont :
- la fiabilisation, par exemple en permettant d’identifier une source, données ou processus, comme étant la cause racine d’un résultat aberrant ;
- la conformité, par exemple au Règlement Général sur la Protection des Données (RGPD) qui impose aux entreprises de disposer d’un registre des traitements effectuées sur les données personnelles. Un tel registre peut être produit à partir de la solution de lineage de votre plateforme car on connait alors les données utilisées et les traitements successifs qui sont réalisés.
Dans l’écosystème Hadoop, le lineage statique, c’est-à-dire sur la création ou l’import de données, est réalisé avec Apache Atlas. Dans son volet dynamique, typiquement lorsqu’un dataset est issu d’un calcul fait dans Apache Spark, c’est Apache Falcon qui était historiquement mis en œuvre. Malheureusement, ce projet a été mis au grenier en 2019 en raison d’une activité trop faible. Des solutions alternatives existent pour pallier ce vide. Pour Spark par exemple, citons Spline (pour SPark LINEage), ou encore Open Metadata sur le périmètre plus large de la gouvernance. Cependant le lineage est compromis s’il ne se réalise pas dans toutes les briques de l’infrastructure. Le champ est alors libre pour les solutions payantes qui, à ce jour, offrent un lineage plus complet.
Comment faire ?
Prenons l’analogie du photographe (figures issues de la conférence). On peut inférer des choses en regardant l’image, mais le plus simple est de tracer les informations depuis l’appareil photo, comme le propose la norme EXIF (Exchangeable image file format).

Il s’agit donc de produire une spécification avec une API REST pour produire et consommer ces métadonnées. Le lineage ne repose plus alors sur la mise en place de nombreux connecteurs, mais d’un seul comme l’illustre la figure suivante. Les producteurs (en haut de la figure) génèrent les informations pour les consommateurs (en bas de la figure), avec un formalisme commun.
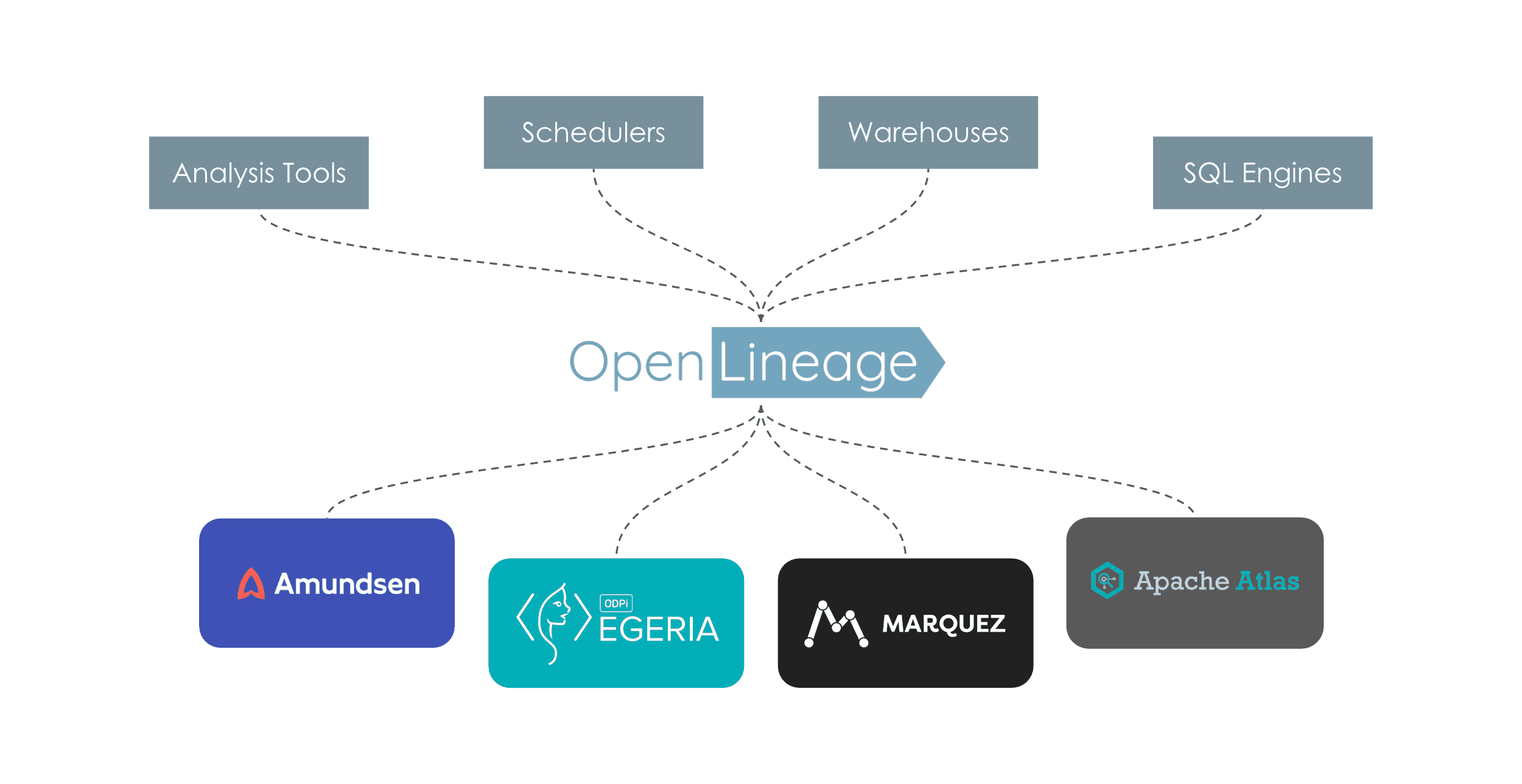
La spécification
Les informations à tracer sont nombreuses et de natures très différentes. Il y a le schéma de la table par exemple, mais également toute la description sur la construction du jeu de données : quel outil, quand, par qui …
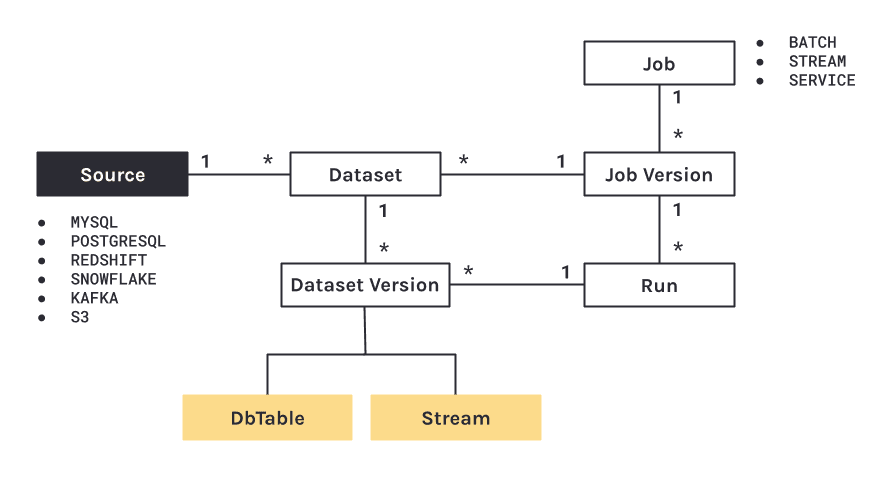
Ces données sont regroupées au sein de fichiers JSON appelés « facettes ». Il existe trois facettes racines, mais qui peuvent s’enrichir avec des facettes filles définies par l’utilisateur. Il s’agit de :
- la facette dataset : le schéma, les statistiques, de la documentation, en entrée et en sortie ;
- la facette job : par exemple la requête SQL du traitement ou la localisation du code source utilisé ;
- la facette run : les informations liées à l’exécution d’une tâche comme l’horodatage de début et de fin, les éventuels messages erreurs.
Ce mode de construction permet de converger rapidement sur une « core spec » très générale mais facile à étendre. On évite ainsi la difficulté liée à la granularité des métadonnées, car prendre en compte toutes les informations est le moyen le plus sûr pour ne pas obtenir un consensus des différents sponsors.
Travaux présentés au buzzwords summit
En 2021, l’accent était mis sur une introduction globale du projet et de ses contributeurs. 2022 était l’occasion d’une première démonstration des outils. Au cours de cette année, une attention particulière a été portée au lineage au niveau des colonnes. De nombreuses bases de données sont conçues avec une structure en colonnes, ce qui rend la création d’un lineage à ce niveau particulièrement pertinente. Cet aspect avait d’ailleurs été abordé dans un article du blog d’OpenLineage. nous avons également pu assister à une démonstration de cette fonctionnalité.
Pour y parvenir, il s’agit de créer une facette spécifique liée à la facette dataset. Plus concrètement, chaque colonne modifiée génère les éléments suivants :
- une liste des colonnes en entrée (identifiés par un nom de colonne) ;
- une description textuelle de la transformation, par exemple une formule de calcul ;
- un type de transformation (actuellement « IDENTITY » et « MASKED » existent pour décrire des données non modifiées ou des données masquées via un hachage).
Pour que cette solution puisse réellement s’imposer, il est essentiel d’enrichir la typologie des transformations, mais également d’étendre ce mécanisme à l’insertion de données au niveau le plus bas, c’est-à-dire directement dans HDFS, sans nécessiter l’utilisation de Hive. Ces évolutions permettront d’accroître les capacités du système et d’offrir une solution plus complète et adaptable aux besoins des utilisateurs.
Conclusion
En introduction, nous avons mentionné l’existence de solutions concurrentes pour le lineage, néanmoins cette solution a des atouts significatifs qui pourraient lui permettre de se démarquer :
- la structuration du projet qui s’inspire de celle d’OpenTelemetry. Ainsi le projet propose une spécification, une API, un SDK et des outils, avec également une fondation en appui : la Linux Foundation pour OpenLineage ;
- le périmètre est plus restreint que pour d’autres produits équivalents : il ne s’agit que du lineage, et même pour être précis du lineage horizontal. Ainsi, il n’y a pas de prise en compte ni des processus métiers ni de l’organigramme de l’entreprise, qui constituent le lineage vertical. Ceci est de nature à accélérer l’aboutissement des travaux ;
- au-delà, ajoutons la vision globale des développeurs avec un triptyque normatif : Parquet - Iceberg - OpenLineage. Ces trois projets open source ont des développeurs en commun mais également des problématiques communes. Ainsi par exemple Iceberg généralise l’emploi des métadonnées présentes dans Parquet et OpenLineage implémente les transformations présentes dans Iceberg (sur les partitions). Les synergies sont donc réelles.
Ainsi avec OpenLineage dans votre pile logicielle vous aurez un système plus ouvert et plus simple à maintenir. Cette norme pourrait donc s’imposer et ainsi relancer la dynamique pour les outils open source de gouvernance de la donnée.
Sources
Les conférences berlin buzzwords :
D’autres sources Internet des contributeurs du projet :
