


Cloudera Sessions Paris 2017

Oct 16, 2017
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Adaltas was at the Cloudera Sessions on October 5, where Cloudera showcased their new products and offerings. Below you’ll find a summary of what we witnessed.
Note: the information were aggregated in this article with the help of David Worms (Adaltas), Axel Tifrani (Le Figaro) and Aargan Cointepas (Le Figaro, now Adaltas). You will also find at the end of the article a list of links offering more detailed information on each of the products presented.
Summary
Cloudera’s teams began with cloud-related offerings and products with the objective of establishing the cloud and hybrid architectures (on-premise / cloud) as a viable alternative to a full on-premise Hadoop cluster. The talks were mainly about:
- Cloudera Shared Data Experience
- Cloudera Director
- Cloudera Altus
The rest of the day was devoted to data science with Cloudera Data Science Workbench.
We also attended a roundtable on the ins and outs of the transition to Big Data in the enterprise.
Finally, we had the opportunity to discuss hardware hybrid computing architectures with HPE’s teams.
Products and offerings
Here’s what we have noted from the sessions:
Cloudera Director
Presented last year, Director was offered less focus this year, however, it is part of Cloudera’s promotion of the cloud and therefore makes sense here.
It is a component of the enterprise offering (same as Navigator or Manager), allowing to deploy and manage one or more CDH clusters on public (AWS & Azure, Google Cloud is only partially covered) and private clouds (RedHat OpenStack and VMWare) in a few clicks with a fully up and running Cloudera Manager. Once a cluster is installed, you can add or remove nodes on the fly.
Director makes it possible to completely bypass the default management consoles of the multiple cloud platforms for the provisioning of Hadoop clusters.
An interesting detail is given by the speaker: Cloudera tests and validates its solutions on 1000 nodes cluster. This was the case for tests conducted on the RedHat OpenStack platform.
Cloudera Altus
Altus was the flagship product of the day as it is the Cloudera’s first Platform-as-a-Service (PAAS) offering.
It is a service to create a Hadoop clusters with a CDH distribution on the fly, to deploy and run a job on data either stored on an existing cluster or on other sources such as S3 and once the job’s done you can delete (or reuse for another job) the instance.
It’s like Amazon EMR with EC2 spot instances but CDH based.

For people who are not familiar with AWS services, EMR is a service to create Hadoop clusters on EC2 instances and EC2 spot instances allow you to bid on unused EC2 instances in order to have them at a better price. This makes it possible to answer the use case of “what if I need to process a fast job but my cluster is already full?”, just create a temporary cluster!
Note that I use AWS services to illustrate my point, however, Azure is also 100% supported.
Unlike Director who targets Hadoop Administrators, Altus is intended to be used by developers or data analysts.
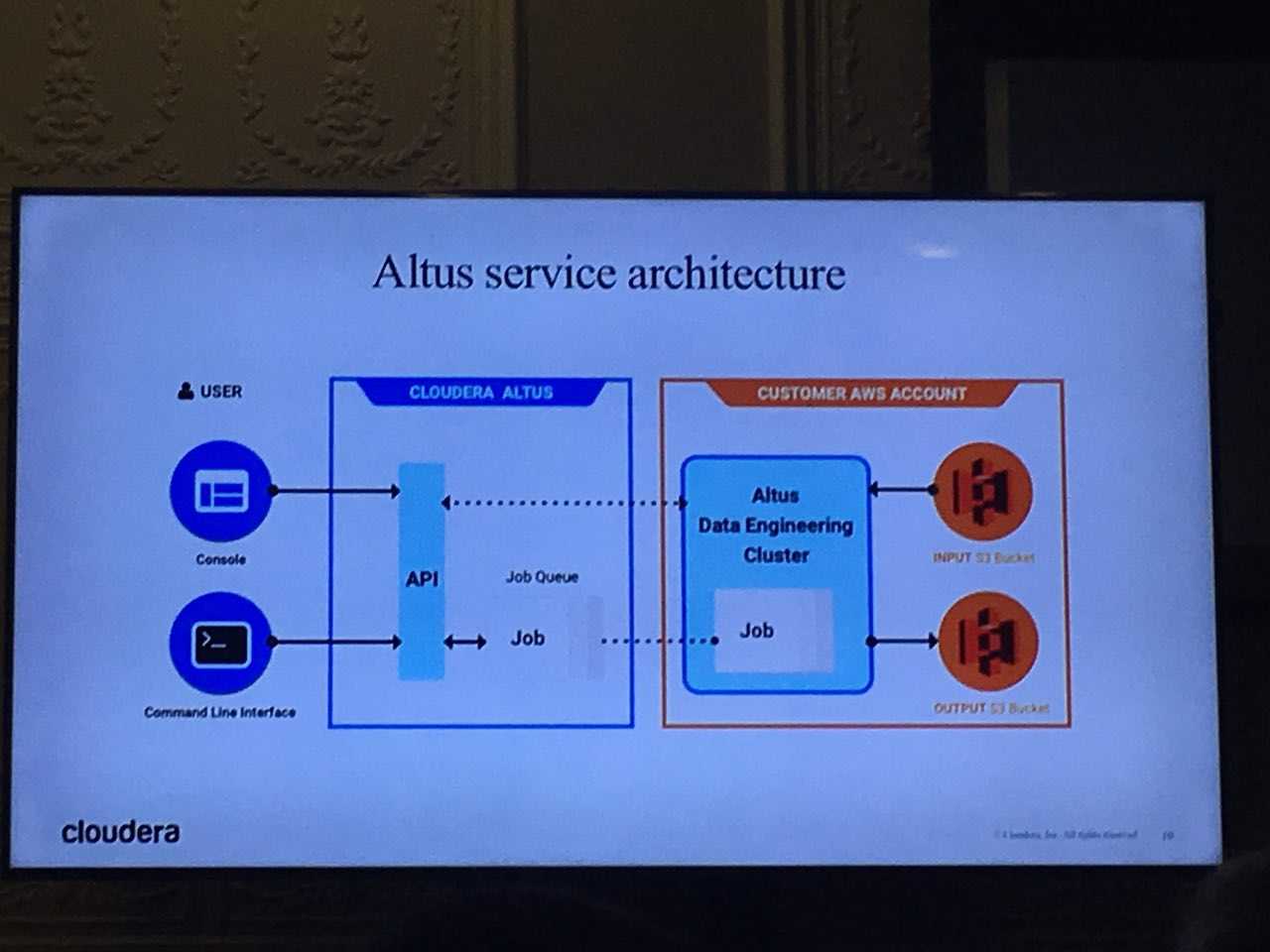
Architecture
Altus is a platform “as-a-service” (PAAS) and is therefore carried by Cloudera servers with web access via a management interface, CLI or API.
To manage the cloud platform and access the existing cluster, the service requires you:
- to have create/delete permissions on cloud instances
- to have R / W rights on the existing cluster and thus access your infrastructure. This can be set-up automatically or manually.
Notes
Here are the points that I noted following the presentation of the product:
- Altus allows you to create clusters on the fly by specifying a single type of instance and the max price you are willing to bid in the auction. This is a strong point, however, an important detail of spot instances is that the price is fixed by type of instance and when the price exceeds the bid you lose every instance of that type. It would have been interesting to be able to indicate several types of instances in order to limit the risk of losing your whole cluster.
- You can choose the version of CDH to be deployed (currently 5.11 and 5.12)
- Jobs can be Spark, Hive, MR2 or Hive-on-Spark
- You cannot deploy Altus locally (to manage a private cloud, turn to Director instead and reimplement automation mechanics)
- The PaaS makes it possible to have a platform always up to date with the latest features
- Billing of the service is in hourly credit, you can pre-pay or receive an invoice at the end of the month (does not include billing for the cloud service)
- Once a job is finished (failed or not)
- You can specify to automatically destroy the cluster
- You can clone the job to restart it
- Altus offers analytical tools such as:
- Execution summary, steps and execution time
- Logs aggregation
- Average execution time, useful if the job has been run several times and you want to identify bottlenecks
- Aggregated logs are stored on Altus servers and retrievable (to push them into ELK for example)
- The similarities with Director are stunning, the engine of Altus is a fork of the engine of Director.
Cloudera Shared Data Experience
With the two previous products, Cloudera allows its clients to create flexible architectures integrating cloud and on-premise as well as mixing permanent clusters and temporary instances, which leaves the following questions:
- Who uses the data / when / how?
- How do I secure access to my data?
- How do I make sure I have not lost any data?
- …
These are questions that products like Navigator or Sentry have addressed in the past, however, how do I manage my data in so many different places? This is where the Cloudera Shared Data Experience solution comes in.
It is a framework centralizing metadata of a “logical” cluster in order to ensure the security and governance of the data, as well as the consistency of workflows and processing jobs, through different sources. It is the technology that enables Cloudera to offer a platform that ensures the durability of your data, both persistent and temporary, with Altus and that will ensure the same level of service in the next version of CDH (5.13).
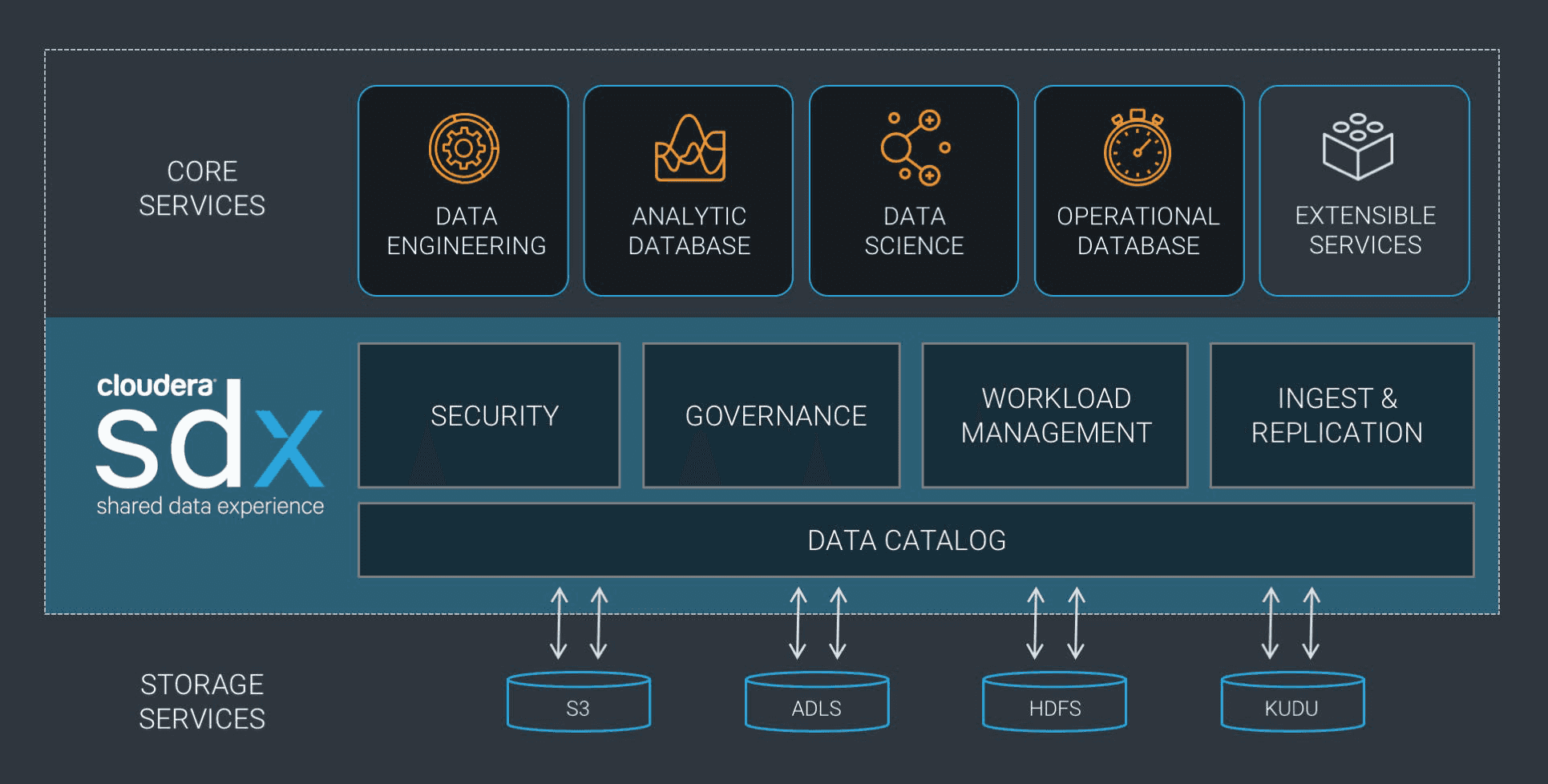
Note that unlike solutions such as Navigator, Sentry or Manager, this is not an active service to deploy and monitor, but a framework built into Cloudera’s suite of tools.
Cloudera Datascience Workbench (CDSW)
Cloudera strikes a major blow in the world of “notebooks” and decentralized development platform with the announcement of Data Science Workbench (CDSW). It is a new component of the CDH suite, offering a multi-tenant development environment dedicated to data science-oriented projects.
Like Jupyter or Zeppelin (open source) or Dataïku (private), CDSW allows a team, through a web interface, to create a collaborative project workspace to develop and experiment with various jobs and run them on a CDH cluster. Users can use multiple languages (R, python, and scala for Spark, …) and Git integration allows the code to be versioned.
In practice, CDSW is a cluster with a master node exposing an access interface and workers executing the jobs, each node being connected to your cluster via a gateway. The nodes are Docker containers orchestrated with Kubernetes in a completely transparent way for the administrators and users of the service. Each job executed with CDSW is also a Docker container with its own access to the CDH cluster allowing a complete isolation with respect to the other jobs, a real management of multi-tenancy and the use of libraries and multiple dependencies according to the user’s need.
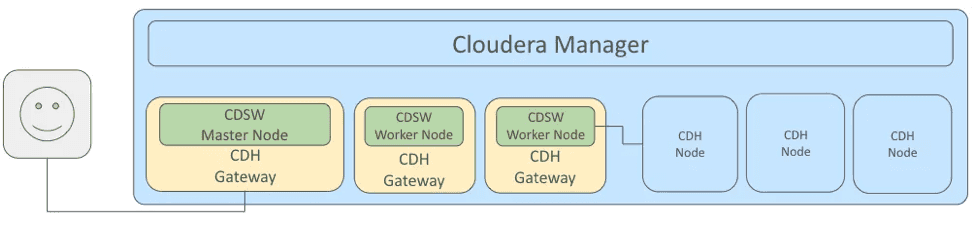
Note that this is the first Cloudera product based on containers.
During the day, Mr. Xavier Illy of Covéa shared feedback on the beta of CDSW which they used for several months and allowed them to quickly put in place a Datalab with multiple teams working on projects in parallel. The main theme of the presentation was the ease of adaptation to the CDSW platform that enabled them to set up heterogeneous teams integrating on one platform with the different profiles required for a successful project.

CDSW RPMs are already available for download from Cloudera servers.
Roundtable - transition to Big Data in the enterprise
Presented as a roundtable, the session was an extremely well prepared scripted Q & A session.
The topics were relevant and the background of the three speakers provided a good diversity of perspectives.
Speakers
- Didier Mamma, Global Head of Commercial Travel Intelligenceat Amadeus (A)
- Damien Gralan, OSS Chief Data Officerat Bouygues Telecom (BT)
- Jean Christophe Prandini, Deputy Head of the Department of Technologies and ISof the Ministry of Interior (MI)
This panel represented services, telecommunications, and the public sector.

Debriefing
Here are the questions asked and the different answers:
What are the stages of digital transformation?
Note: This was more about the switch to Big Data technologies, however, we retain the wording used.
- IM - the ministry’s IS was an aggregate of functional requirements translated into infrastructure, the transformation consisted of providing a better structure and understanding of the existing data by determining the added value of the technologies available. Mr. Prandini also acknowledged that the data concerned were not worth the use of Big Data in terms of size, but required new processing jobs (predictive analysis, …)
- A - For M. Mamma, the first step is to unlearn the habits and paradigms of usual relational systems, in order to work in a “data-driven” mode with new architectures and uses, which means managing change in the company. He noted rightly that the companies that are today the most disruptive (Airbnb, Uber, …) benefit from not having to unlearn.
What were the impacts on the business and the industry?
- BT - The move to Big Data was an opportunity to change internal ways of working, from a desire for quality of service (equipment monitoring) to a quality of customer experience (what does the customer do?). This resulted in the destruction of the company’s silos and the promotion of exchanges between teams
- A - Being a traveling services sales company, Mr. Mamma introduced us the stakes of his customers, airline companies. “What to do with the data? How to survive against low-cost?” are the questions that prompted these companies to offer a hyper-customization of the customer’s experience, which involves predictive analysis and allowing their different teams to react in real time.
- MI - More than impacts, Mr. Prandini presented us with two uses of data: an aggregation of the data to present a global view of a case and quality control of the data, which also leads to prediction.
How far do you go with the data? (legally speaking)
- BT - Telecoms in France are framed by several levels of security:
- The CNIL enforcing the Data Protection Act
- European data protection legislation (GDPR)
- A French code for telecommunication companies
- An internal code of ethics
As a result, our data is anonymized on the fly as soon as it is obtained.
- A - Airlines face a dilemma, protect the privacy of customers or offer an ultra-customized experience. To answer that, they ask the customer what they want to share (in the small lines of the conditions of use!)
- MI - Being a state entity, the question does not arise and the rules of the GDPR are already integrated!
Discussions with HPE
We talked about hybrid computing architectures in the Big Data world. I mean machines that include graphics cards and therefore GPUs.
Once mathematicians fantasy for their enormous matrix calculation capabilities coupled with Big Data, several companies have embarked on the acquisition of such machines as Sanofi for genome sequencing or molecule calculations.
Two points to note about hybrid architectures:
- The GPU is a processor optimized for matrix computation, that is to say, a repetitive operation on a huge set of data (originally visual rendering), it is necessary therefore to target the need and the processing for which it is used
- The GPU is not going to get the data by itself, data has to be prepared and sent to the GPU, which means having very powerful CPUs if one wishes to fully exploit its power, leading to extremely expensive machines.
Conclusion
Cloudera continues to strive to make its suite a Swiss knife for data processing in the enterprise and clearly sets out its future objectives to put the cloud in the spotlight, freeing the big data infrastructure from the physical limits of a conventional Hadoop cluster and easing access to machine learning.
Useful links
- Cloudera Altus getting started: https://blog.cloudera.com/blog/2017/05/data-engineering-with-cloudera-altus/
- SDX Introduction: https://vision.cloudera.com/introducing-cloudera-sdx-a-shared-data-experience-for-the-hybrid-cloud/
- SDX technical presentation: https://blog.cloudera.com/blog/2017/09/cloudera-sdx-under-the-hood/
- CDSW technical presentation: https://blog.cloudera.com/blog/2017/05/getting-started-with-cloudera-data-science-workbench/
- CDSW Documentation - Git integration: https://www.cloudera.com/documentation/data-science-workbench/latest/topics/cdsw_using_git.html
