


Passage à l'échelle de larges pipelines de données en temps réel avec Go

21 nov. 2017
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Il y a quelques semaines, à l’Open Source Summit à Prague, Jean de Klerk a tenu une conférence intitulée “Passage à l’échelle en temps réel de pipelines de données avec Go”.
Cet article passe en revue les principaux points de l’exposé, en détaillant les étapes que Jean a franchies en optimisant ses pipelines, en expliquant les parties critiques de son code et en reproduisant ses résultats de référence.
Tout le code de Jean, ainsi que les diapositives qu’il a utilisées pendant son discours, sont disponibles dans ce dépôt Github.
Qu’est-ce que Go ?
Go, ou Golang, est un langage de programmation créé par Google en 2007. Comme C ou Algol, il s’agit d’un langage compilé, statiquement typé. Il fournit la récupération de place (garbage collection) et prend en charge la gestion de la concurrence (concurrency) au niveau du langage. La syntaxe de Go est simple et facile à comprendre, et le code se compile très rapidement.
En raison de ses fonctionnalités de base, Go est mieux appliqué aux réseaux, aux systèmes et à la simultanéité. Comme l’a dit Mark C. Chu-Caroll :
Goroutines et les canaux fournissent le meilleur soutien que j’ai vu en dehors d’Erlang pour faire usage de la concurrence. Et franchement, je pense que Go est beaucoup moins moche qu’Erlang. (Désolé les fans d’Erlang, mais je n’aime vraiment pas Erlang.) Comparé à Java, que je pense être le principal concurrent de Go dans ce domaine, les goroutines et les canaux de Go sont tellement plus faciles à utiliser que les threads et verrous Java. il n’y a absolument aucune comparaison du tout. Go a à peu près détruit la concurrence dans ce domaine.
Nos pipelines de données
Nous voulons que nos pipelines de données soient hautement disponibles, qu’ils aient un faible taux d’abandon de messages et qu’ ils aient un débit élevé.
La haute disponibilité est obtenue en mettant en œuvre nos pipelines en tant que microservices sans états (stateless) et à échelle horizontale (horizontalscaling). L’activation d’un accès hautement concurrent entraîne un débit élevé. Pour limiter le taux de perte de messages, nous allons utiliser de petits tampons avec une capacité de vidage.
Exemples de pipelines
Les pipelines sont un concept simple : les passerelles traitent des messages - des paquets de données - envoyés depuis une source avant d’être envoyés vers une destination.
Exemple 1 : Les périphériques IoT, tels que les ampoules intelligentes, envoient des données via des pipelines à un serveur qui fournit des services, tels que la gradation automatique.
Exemple 2 : Les applications de messagerie envoient des messages via des pipelines où elles sont transférées vers d’autres applications de messagerie.
Exemple 3 : Les journaux (logs) ou les métriques sont envoyés via des pipelines où ils sont traités et stockés dans une base de données.
Alors, que font exactement les pipelines ? Ils peuvent souvent être décomposés en quatre étapes nécessaires : l’ingestion, l’analyse, le traitement et le transfert.
Notre pipeline barebone
Pour comparer différentes optimisations, Jean a créé un exemple de structure d’application :
type Queue interface {
Enqueue(data []byte)
Dequeue() ([]byte, bool)
}
type inputter interface {
StartAccepting(q queues.Queue)
}
type outputter interface {
StartOutputting(q queues.Queue)
}
type Processor struct {
i inputter
q queues.Queue
o outputter
wg *sync.WaitGroup
}
func (p *Processor) Start() {
go p.i.StartAccepting(p.q)
go p.o.StartOutputting(p.q)
p.wg.Wait()
}Ce code définit les interfaces pour les fonctions qui peuvent être implémentées de différentes manières. La meilleure façon de faire est précisément le sujet de la conversation de Jean.
Les fonctions StartAccepting et StartOutputting déterminent quels protocoles réseau sont utilisés pour envoyer des messages aux passerelles, ce qui est le premier aspect que nous allons optimiser. Les fonctions Enqueue et Dequeue définissent les structures de données que nos pipelines utilisent pour stocker les messages lors de leur passage, que nous optimiserons également plus tard.
Optimisation des I/O réseau
Jean a examiné plusieurs méthodes différentes d’I/O réseau :
- Unary HTTP
- Unary HTTP/2 with gRPC
- UDP
- Streaming TCP
- Streaming web sockets
- Streaming HTTP/2 with gRPC
Unary HTTP
Unary HTTP permet d’envoyer un message via une connexion HTTP typique.
Avantages :
- Facile de savoir si la connexion a réussi et si le pipeline a correctement reçu le message.
- Facile à mettre en œuvre.
Inconvénients :
- Les connexions unaires sont lentes.
Voici l’implémentation de Jean :
func (l *HttpListener) StartAccepting(q queues.Queue) {
fmt.Printf("Starting HTTP listening on port %d\n", l.port)
m := http.NewServeMux()
m.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
body, err := ioutil.ReadAll(r.Body)
if err != nil {
panic(err)
}
q.Enqueue(body)
})
log.Fatal(http.ListenAndServe(fmt.Sprintf(":%d", l.port), m))
}Le code ci-dessus est simple : il écoute les requêtes HTTP entrantes et ajoute les données entrantes à la file d’attente de la passerelle.
Unary HTTP/2 avec gRPC
Passant de HTTP à HTTP/2, l’implémentation suivante utilise gRPC au lieu d’une requête HTTP typique.
Google a développé puis open-sourcé gRPC, et décrivent gRPC ainsi :
gRPC est un framework d’appel de procédures distantes (RPC) Open Source moderne qui peut être exécuté n’importe où. Il permet aux applications clientes et serveurs de communiquer de manière transparente et facilite la création de systèmes connectés.
Google a développé puis open-sourcé protocol buffers, ou protobuf, et décrivent protocol buffers ainsi :
Protocol buffers est le mécanisme extensible de Google, indépendant d’un langage ou d’une plateforme, pour la sérialisation de données structurées - pensez XML, mais plus petit, plus rapide et plus simple. Vous définissez comment vous voulez que vos données soient structurées une fois, puis vous pouvez utiliser un code source généré spécial pour écrire et lire facilement vos données structurées vers et à partir de divers flux de données et en utilisant une variété de langages informatiques.
Avantages :
- gRPC utilise protobuf, qui permet le décodage binaire à partir de modèle.
- gRPC utilise protobuf, ce qui rend agnostique le langage de service et de spécification.
- HTTP/2 est meilleur que HTTP.
- gRPC est construit avec l’équilibrage des charge I/O en tête.
Voici l’implémentation de Jean :
func (l *UnaryGrpcListener) StartAccepting(q queues.Queue) {
fmt.Printf("Starting gRPC listening on port %d\n", l.port)
lis, err := net.Listen("tcp", fmt.Sprintf(":%d", l.port))
if err != nil {
panic(err)
}
s := grpc.NewServer()
r := unaryGrpcServerReplier{q: q}
model.RegisterGrpcUnaryInputterServiceServer(s, r)
reflection.Register(s)
if err := s.Serve(lis); err != nil {
panic(err)
}
}
func (r unaryGrpcServerReplier) MakeRequest(ctx context.Context, in *model.Request) (*model.Empty, error) {
r.q.Enqueue([]byte(in.Message))
return &model.Empty{}, nil
}Ce code utilise l’infrastructure gRPC pour recevoir des messages et les insérer dans la file d’attente de la passerelle.
UDP
HTTP utilise TCP sur la couche de transport. Un autre protocole de couche de transport est UDP, que cette prochaine implémentation utilise pour atteindre une vitesse accrue.
Contrairement à TCP, UDP est un protocole sans connexion, ce qui signifie que l’expéditeur n’obtient aucun accusé de réception du récepteur indiquant si les données souhaitées ont été reçues ou non.
Avantages :
- UDP est rapide car on ne perd pas de temps à se reconnaître.
Inconvénients :
- UDP est “lossy” car aucune connexion n’est établie.
- Il est difficile de savoir combien de paquets sont perdus pendant la transmission.
J’ai échangé quelques courriels avec Jean, et il a expliqué ce qui pourrait avoir un impact sur la perte de l’UDP :
Plus il y a de nœuds intermédiaires ‘occupés’, plus la perte de données d’UDP est exacerbée ; TCP renverra les paquets abandonnés (et en fait traitera les paquets abandonnés comme indication de limitation de débit), mais dans le cas d’UDP ils sont juste perdus. Plus un nœud est occupé (routeur, proxy, équilibreur de charge, etc.), plus il est probable qu’un paquet soit perdu. La perte de connexion et d’autres types d’évènements perturbateurs peuvent également entraîner une perte de paquets.
Voici l’implémentation de Jean :
func (l *UdpListener) StartAccepting(q queues.Queue) {
fmt.Printf("Starting UDP listening on port %d\n", l.port)
addr, err := net.ResolveUDPAddr("udp", fmt.Sprintf(":%d", l.port))
if err != nil {
fmt.Println(err)
}
conn, err := net.ListenUDP("udp", addr)
if err != nil {
fmt.Println(err)
}
defer conn.Close()
buf := make([]byte, 65536)
for {
n, _, err := conn.ReadFromUDP(buf)
if err != nil {
fmt.Println("Error: ", err)
}
message := buf[0:n]
q.Enqueue(message)
}
}Ce code écoute en permanence les messages envoyés via UDP et ajoute les messages à la file d’attente de la passerelle.
Streaming TCP
En s’éloignant des connexions unaires, nous pouvons essayer le streaming, ce qui nous permettra d’envoyer plusieurs messages via une seule connexion. Commençons par TCP.
Avantages :
- Le streaming est rapide car une seule connexion est établie.
Inconvénients :
- Cela nécessite la construction de votre protocole.
- Cela nécessite la construction de votre modèle de sécurité.
- Cela nécessite la construction de vos codes de statut.
- etc.
Voici l’implémentation de Jean :
func (l *TcpListener) StartAccepting(q queues.Queue) {
fmt.Printf("Starting TCP listening on port %d\n", l.port)
ln, err := net.Listen("tcp", fmt.Sprintf(":%d", l.port))
if err != nil {
panic(err)
}
for {
conn, err := ln.Accept()
if err != nil {
panic(err)
}
go readFromConn(conn, q) // incl process buffer manually, retry logic, etc
}
}
func readFromConn(c net.Conn, q queues.Queue) {
var add = make(chan ([]byte), 1024)
go processBuffer(add, q)
for {
msg := make([]byte, 1024)
_, err := c.Read(msg)
if err != nil {
if err == io.EOF {
c.Close()
return
}
panic(err)
}
add <- msg
}
}
func processBuffer(add chan ([]byte), q queues.Queue) {
b := bytes.NewBuffer([]byte{})
for {
select {
case msg := <-add:
b.Write(msg)
break
default:
l, err := b.ReadBytes('\n')
if err != nil {
if err == io.EOF {
break
}
panic(err)
}
if len(l) <= 1 || l[0] == 0 { // kinda hacky way to check if it's a fully-formed message
break
}
q.Enqueue(l)
}
}
}Ce code écoute les connexions TCP entrantes et lit continuellement les données dans un tampon qu’il ajoute ensuite à la file d’attente de la passerelle une fois qu’un message entier est reçu.
Remarque : Cette implémentation est simpliste et ne fonctionne pas lors de l’envoi de messages volumineux.
Streaming avec des WebSockets
Au lieu de diffuser via TCP, peut-être pouvons-nous utiliser un protocole de plus haut niveau comme les WebSockets.
Mozilla décrit les WebSockets comme ceci :
WebSockets est une technologie avancée qui permet d’ouvrir une session de communication interactive entre le navigateur de l’utilisateur et un serveur. Avec cette API, vous pouvez envoyer des messages à un serveur et recevoir des réponses événementielles sans devoir interroger le serveur pour obtenir une réponse.
Avantages :
- Le streaming avec des sockets Web est très rapide.
Inconvénients :
- Il est difficile de savoir si la connexion de la WebSocket est active.
- La répartition de charge peut être difficile avec les WebSockets.
Voici l’implementation de Jean :
func (l *WebsocketListener) StartAccepting(q queues.Queue) {
fmt.Printf("Starting websocket listening on port %d\n", l.port)
m := http.NewServeMux()
m.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
c, err := upgrader.Upgrade(w, r, nil)
if err != nil {
return
}
defer c.Close()
for {
_, message, err := c.ReadMessage()
if err != nil {
break
}
q.Enqueue(message)
}
})
log.Fatal(http.ListenAndServe(fmt.Sprintf("localhost:%d", l.port), m))
}Ce code écoute en continu sur une WebSocket, en ajoutant les messages entrants à la file d’attente de la passerelle.
Streaming HTTP/2 avec gRPC
gRPC peut travailler en streaming, en ajoutant les points forts de la technologie à la vitesse du streaming.
Avantages :
- Le streaming avec gRPC est très rapide.
- gRPC utilise protobuf, qui permet le décodage binaire dans les modèles.
- gRPC utilise protobuf, ce qui rend agnostique le langage de service et de spécification.
- gRPC utilise protobuf, qui permet aux petits paquets de se déplacer dans le réseau.
- HTTP/2 est meilleur que HTTP.
- gRPC est construit avec l’équilibrage de charge en tête.
Inconvénients :
- Il est difficile de savoir si la connexion est vivante.
Voici l’implementation de Jean :
func (l *StreamingGrpcListener) StartAccepting(q queues.Queue) {
fmt.Printf("Starting gRPC listening on port %d\n", l.port)
lis, err := net.Listen("tcp", fmt.Sprintf(":%d", l.port))
if err != nil {
panic(err)
}
s := grpc.NewServer()
model.RegisterGrpcStreamingInputterServiceServer(s, &streamingGrpcServerReplier{q: q})
s.Serve(lis)
}
func (r streamingGrpcServerReplier) MakeRequest(request model.GrpcStreamingInputterService_MakeRequestServer) error {
for {
req, err := request.Recv()
if err != nil {
return err
}
r.q.Enqueue([]byte(req.Message))
}
return nil
}Ce code utilise l’infrastructure gRPC pour recevoir en continu des messages et les insérer dans la file d’attente de la passerelle.
Benchmarks
Jean a écrit un programme pour comparer les différentes méthodes décrites ci-dessus. J’ai lancé ses benchmarks et voici les résultats obtenus sur mon poste.
| Protocol | Parallel Sending | Small Message | Medium Message | Large Message | Very Large Message |
|---|---|---|---|---|---|
| HTTP Simple | Non | 46942 | 57682 | 58412 | 170765 |
| HTTP Simple | Oui | 44874 | 40308 | 40461 | 98686 |
| UDP Simple | Non | 10647 | 12890 | 13388 | |
| UDP Simple | Oui | 1775 | 2801 | 3063 | |
| gRPC Simple | Non | 70816 | 93274 | 92594 | 212194 |
| gRPC Simple | Oui | 18813 | 25950 | 28199 | 127414 |
| Streaming TCP | Non | 3261 | |||
| Streaming TCP | Oui | 3106 | |||
| Streaming UDP | Non | 1955 | 3544 | 4400 | |
| Streaming UDP | Oui | 2324 | 4010 | 4543 | |
| Streaming Websocket | Non | 3769 | 10107 | 10646 | 120604 |
| Streaming Websocket | Oui | 1090 | 4498 | 4951 | 47776 |
| Streaming gRPC | Non | 3004 | 9883 | 13296 | 123162 |
| Streaming gRPC | Oui | 1075 | 6810 | 8813 | 73845 |
Les résultats sont en nanosecondes / operation.
Voici les différentes tailles de messages :
- Small : 18 bytes
- Medium : 4266 bytes
- Large : 6786 bytes
- Very Large : 79435 bytes
Certains résultats sont manquants. Les messages étendus envoyés via UDP semblent avoir été perdus, et l’implémentation de Jean de streaming TCP n’a pas pu traiter les messages de trop grandes tailles. Comme il l’a décrit lors de l’un de nos échange par email :
Le décodage TCP est juste une implémentation de référence, et n’est pas capable de gérer l’assemblage de données incomplètes. Les petits paquets ont tendance à arriver entiers, et les plus gros paquets ont tendance à arriver brisés.
En analysant les résultats des benchmarks, nous pouvons voir que l’envoi de messages en streaming sur une seule connexion vers notre passerelle est beaucoup plus rapide que l’utilisation de connexions unaires. La vitesse accrue est encore plus visible lors de l’envoi simultané de plusieurs messages.
Optimisation de l’ingestion de données
Une fois que les messages ont atteint notre passerelle, ils doivent être stockés dans une file d’attente pendant le traitement. Alors que certains threads vont écrire - ou ajouter - de nouveaux messages dans la file d’attente, d’autres les liront ou les retireront pour les traiter.
Lors de sa présentation, Jean a examiné plusieurs structures de données différentes :
- File d’attente en tableau à l’aide de mutex
- File d’attente avec canal
- File d’attente en tampon circulaire utilisant des mutex
- File d’attente en tampon circulaire utilisant des atomics
Tableau avec mutex
Cette file d’attente est implémentée comme un tableau simple, avec un mutex pour éviter l’écriture ou la lecture simultanées par différents threads.
Si vous ne savez pas ce qu’est un mutex, ou un sémaphore MUTuellement EXclusive, alors l’explication de Xetius et de Петър Петров devrait aider :
Quand j’ai une discussion animée au travail, j’utilise un poulet en caoutchouc que je garde dans mon bureau pour de telles occasions. La personne qui tient le poulet est la seule personne autorisée à parler. Si vous ne tenez pas le poulet, vous ne pouvez pas parler. Vous pouvez seulement indiquer que vous voulez le poulet et attendre jusqu’à ce que vous l’obteniez avant que vous parlez. Une fois que vous avez fini de parler, vous pouvez remettre le poulet au modérateur qui le transmettra à la personne suivante pour parler. Cela garantit que les gens ne parlent pas les uns aux autres, et ont aussi leur propre espace pour parler.
Remplacer le poulet avec Mutex et la personne avec un thread et vous avez essentiellement le concept d’un mutex.
Le poulet est le mutex. Les gens qui tiennent le mu … poulet sont des threads concurrents. Le modérateur est le système d’exploitation. Lorsque les gens demandent le poulet, ils font une demande de verrouillage. Lorsque vous appelez mutex.lock(), votre thread se bloque dans lock() et envoie une requête de verrouillage au système d’exploitation. Lorsque le système d’exploitation détecte que le mutex a été libéré d’un thread, il le donne simplement à vous, et lock() renvoit - le mutex est maintenant le vôtre et seulement le vôtre. Personne d’autre ne peut le voler, car l’appel de lock() le bloquera. Il y a aussi try_lock() qui bloquera et retournera vrai quand le mutex est à vous et immédiatement faux si le mutex est utilisé.
Avantages :
- Aucun. Ce n’est pas une bonne implémentation.
Inconvénients :
- Verrouiller et déverrouiller continuellement le mutex est lent.
- Redimensionner le tableau est terriblement lent.
- Si vos lectures sont plus lentes que vos écritures, alors le tableau grandira et grandira de façon incontrôlable.
Voici l’implementation de Jean :
func (q *MutexArrayQueue) Enqueue(data []byte) {
q.mu.Lock()
defer q.mu.Unlock()
q.data = append(q.data, data)
}
func (q *MutexArrayQueue) Dequeue() ([]byte, bool) {
q.mu.Lock()
defer q.mu.Unlock()
if len(q.data) == 0 {
return nil, false
}
data := q.data[0]
q.data = q.data[1:len(q.data)]
return data, true
}Ce code ajoute / écrit de nouveaux messages à la fin du tableau / file d’attente et supprime / lit les messages les plus anciens depuis le début du tableau / file d’attente.
Bien que ce soit probablement la solution la plus directe et la plus intuitive, c’est l’une des plus lentes.
Canal
Dans Go, les canaux sont des structures pré-allouées dans lesquelles un thread peut ajouter / écrire des données dans une extrémité ou supprimer / lire des données dans l’autre extrémité. Les canaux sont, en substance, des files d’attente.
Avantages :
- Les canaux sont rapides, car ils constituent une caractéristique essentielle de Go.
Inconvénients :
- Les canaux finissent par se remplir, laissant tomber les dernières données. Les données les plus anciennes sont prioritaires.
- Les canaux utilisent parfois des mutex en interne, ce qui peut les ralentir un peu.
Voici l’implementation de Jean :
func (q *ChannelQueue) Enqueue(data []byte) {
select {
case q.c <- data:
default:
// Queue was full! Data dropped
// metrics.Record("dropped_messages", 1)
}
}
func (q *ChannelQueue) Dequeue() ([]byte, bool) {
select {
case data := <-q.c:
return data, true
default:
return nil, false
}
}Ce code écrit / ajoute des messages à la file d’attente si elle n’est pas complète. Si la file d’attente est pleine, tous les nouveaux messages sont supprimés. Les messages dans le canal peuvent être lus / supprimés.
Tampon circulaire avec mutex
Si nos écritures sont plus rapides que nos lectures, notre file d’attente se remplira. Les canaux priorisent les messages plus anciens, mais nous préférerions prioriser les nouveaux messages en vidant les anciens messages lorsque les écritures sont trop loin devant les lectures.
La solution pour cela est d’utiliser un tampon circulaire. Un tampon circulaire est un tableau qui se boucle sur lui-même. Lorsque vous atteignez la fin, vous recommencez au début. Deux pointeurs gardent la trace de l’endroit où les messages doivent être écrits ou lus. Un mutex est utilisé pour éviter l’écriture ou la lecture simultanées par différents threads.
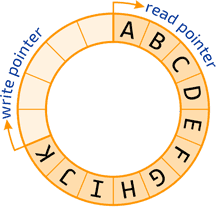

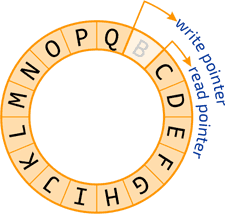
Avantages :
- Si les écritures dépassent les lectures par une boucle complète, le tampon se vide : les lectures agissent sur les nouveaux messages et les messages les plus anciens sont écrasés.
- Cela donne la priorité aux nouveaux messages.
Inconvénients :
- Verrouiller et déverrouiller continuellement le mutex est lent.
Voici l’implementation de Jean :
func (q *MutexRingBufferQueue) Enqueue(data []byte) {
q.mu.Lock()
defer q.mu.Unlock()
q.buffer[q.inputCursor] = data
if q.inputCursor == len(q.buffer)-1 {
q.inputCursor = -1
}
q.inputCursor++
}
func (q *MutexRingBufferQueue) Dequeue() ([]byte, bool) {
q.mu.Lock()
defer q.mu.Unlock()
if q.outputCursor == q.inputCursor {
return nil, false
}
data := q.buffer[q.outputCursor]
if q.outputCursor == len(q.buffer)-1 {
q.outputCursor = -1
}
q.outputCursor++
return data, true
}Ce code implémente un tampon circulaire en tant que file d’attente. Les pointeurs qui gardent la trace de l’endroit où écrire et lire sont appelés curseurs ici.
Tampon circulaire avec atomics
Dans Go, les atomics sont des implémentations de bas niveau d’opérations simples comme l’ajout, l’échange, etc. En raison de leur nature atomique, ces actions n’exigent pas de mutex.
Nous pouvons réimplémenter une mémoire tampon sans mutice en utilisant les atomics de Go.
Avantages :
- Si les écritures dépassent les lectures par une boucle complète, le tampon se vide effectivement : les lectures agissent sur les nouveaux messages et les messages les plus anciens sont écrasés. Cela donne la priorité aux nouveaux messages.
- Les opérations atomiques sont rapides.
Inconvénients :
- Aucun.
Voici l’implementation de Jean :
func (d *OneToOne) Enqueue(data []byte) {
writeIndex := atomic.AddUint64(&d.writeIndex, 1)
idx := writeIndex % uint64(len(d.buffer))
newBucket := &bucket{
data: data,
seq: writeIndex,
}
atomic.StorePointer(&d.buffer[idx], unsafe.Pointer(newBucket))
}
func (d *OneToOne) Dequeue() ([]byte, bool) {
readIndex := atomic.LoadUint64(&d.readIndex)
idx := readIndex % uint64(len(d.buffer))
value, ok := d.tryNext(idx)
if ok {
atomic.AddUint64(&d.readIndex, 1)
}
return value, ok
}
func (d *OneToOne) tryNext(idx uint64) ([]byte, bool) {
result := (*bucket)(atomic.SwapPointer(&d.buffer[idx], nil))
if result == nil {
return nil, false
}
if result.seq > d.readIndex {
atomic.StoreUint64(&d.readIndex, result.seq)
}
return result.data, true
}Ce code implémente un tampon circulaire (ring buffer) avec des opérations atomiques au lieu de mutex. Cela nécessite un peu plus de code que l’implémentation précédente précisément à cause de cela.
Benchmarks
Jean a écrit un code pour comparer les différentes structures de données décrites ci-dessus. J’ai exécuté ces benchmarks et voici les résultats.
| Data Structure | Small Message | Medium Message | Large Message | Very Large Message |
|---|---|---|---|---|
| Tableau & Mutex | 15969 | 16370 | 15961 | 15947 |
| Canaux | 6888 | 6862 | 6805 | 6416 |
| Tampon circulaire & Mutex | 11812 | 11869 | 13097 | 11891 |
| Tampon circulaire & Atomics | 6339 | 6199 | 6317 | 6177 |
Les résultats sont en nanosecondes / opération.
Voici les différentes tailles de message :
- Petit : 18 octets
- Moyen : 4266 octets
- Large : 6786 octets
- Très grand : 79435 octets
Ces résultats ne semblent pas dépendre de la taille des messages, uniquement parce que lorsqu’un message est ajouté ou supprimé de la file d’attente, il n’est pas copié. Seule son adresse en mémoire l’est.
En analysant ces benchmarks, nous pouvons voir que l’utilisation de mutex est assez lente, donc l’utilisation des opérations atomiques peut être meilleure. Alors que le tampon circulairenécessite un code plus complexe que celui implémentant les channels, il priorise les données les plus récentes par rapport aux données plus anciennes. Une structure de données moins classique est ainsi avantageuse.
Profilage dans Go
Avant de commencer l’optimisation, Jean vous recommande de profiler votre code.
Wikipedia explique ce que le profilage est raisonnablement bien :
En génie logiciel, le profilage est une forme d’analyse de programme dynamique qui mesure, par exemple, l’espace (mémoire) ou la complexité temporelle d’un programme, l’utilisation d’instructions particulières ou la fréquence et la durée des appels de fonction. Le plus souvent, les informations de profil servent à faciliter l’optimisation du programme.
Vous pouvez profiler votre code en utilisant pprof, qui donne une trace du temps d’exécution, ou avec gotrace, qui crée un graphique dynamique de tous les threads au moment de l’exécution.
Conclusion
Après avoir essayé toutes ces différentes optimisations, nous pouvons affirmer que pour obtenir les meilleures performances, nous devons envoyer nos messages en streaming sur un minimum de connexions vers nos pipelines, et nos pipelines doivent implémenter leurs files d’attente comme des tampons circulaires avec atomiques.
Jean a partagé quelques idées à la fin de son discours :
- Les métriques sont plus utiles que les logs, et elles ont également tendance à être plus petites.
- Les files d’attente sont bien, principalement lorsqu’elles sont correctement implémentées.
- Assurez-vous de profiler vos applications.
- Les canaux sont brillants, mais pas toujours parfaits ; vous devriez peut-être profiler votre code pour en être sûr.
Sur une note personnelle, j’ajouterai que les développeurs devraient avoir une certaine connaissance des algorithmes et des structures de données, afin qu’ils puissent optimiser leur code de la meilleure façon possible. L’optimisation commence par connaître ses options.
