


YARN et le calcul distribué sur GPU pour le machine learning

By JOUET Grégor
30 mai 2018
- Catégories
- Data Science
- DataWorks Summit 2018
- Tags
- GPU
- YARN
- Machine Learning
- Réseau de neurones
- Storage [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Dans cet article nous verrons les principes fondamentaux du Machine Learning et les outils actuellement utilisés pour exécuter ce type d’algorithmes, puis nous expliquerons comment un gestionnaire de ressources tel que YARN peut s’avérer utile dans ce contexte et comment il peut aider des algorithmes à s’exécuter sereinement. Cet article s’inspire d’une conférence du DataWork Summit 2018 à Berlin par Wangda Tan et Sunil Govindan.
Quelques bases de Machine Learning
Prenons un exemple : nous voulons créer une application capable de dire si une image donnée est une photo de chat ou non :

A CAT
NOT A CAT
En partant de rien, et sans utiliser de modèle préfait, nous commençons par chercher un grand nombre d’images étiquetées, ImageNet peut dans ce cas là nous fournir toutes les données nécessaires.
Nous ne pouvons pas nous contenter d’images de chats et non chats sans labels, il nous faut savoir à l’avance ce que contient l’image. Pour entrainer notre modèle, en entrainement supervisé, il faut connaitre la sortie attendue par l’algorithme.
D’ailleurs à propos de modèles, c’est le moment d’en définir un. Il prendra une image en entrée et donnera en sortie un nombre entre 0 et 1, représentant la probabilité que l’image soit un chat ou non. Nous ne verrons pas ici les détails d’un tel modèle mais voici un lien pour une lecture complémentaire avec cet article sur la classification d’images.
Nous sommes maintenant prêts à implémenter et entrainer notre modèle, mais avant ça il nous faut choisir un framework. Tensorflow, Caffe ou Mxnet par exemple. Il en existe beaucoup et ce choix va principalement dépendre du cas d’usage et des outils avec lesquels vous êtes les plus à l’aise.
Le modèle est à présent en cours d’entrainement et devrait être prêt dans quelques heures grâce à nos GPUs. En effet, vous avez sûrement entendu dire que les modèles de Machine Learning s’entrainaient sur des cartes graphiques, c’est tout à fait vrai, mais pourquoi ? Pour résumer, nous avons une grande quantité de calcul à effectuer mais ce sont des calculs simples et qui peuvent être faits en même temps. Dans ce contexte, les cartes graphiques ont su montrer des performances très avantageuses.
À présent que nous avons un modèle, il est possible de le tester. Les tests s’effectuent sur une partie des images qui n’a pas servi à entrainer le modèle, pour voir comment ce dernier réagit à une nouvelle donnée. Si le modèle montre des performances intéressantes, il sera peut-être même utilisé en production.
Les besoins du Machine Learning
Comme nous venons de le voir, entrainer un modèle de Machine Learning a demandé un certain nombre de ressources :
- Espace de stockage : la quantité de données requises pour entrainer convenablement un modèle peut être surprenamment grande, mais plus notre jeu de données est important et divers, plus notre modèle aura de bonnes performances.
- GPU : de nos jours l’unité graphique où sont entrainés ou utilisés les modèles est une contrainte forte lorsqu’on exige une réponse en temps réel, et encore plus dans des applications critiques comme la conduite autonome. La contrainte et les exigences sont très fortes si on ne peut pas se permettre de latence.
Les modèles de Machine Learning en production
Tout ce que nous avons vu jusqu’ici n’était qu’une petite partie de ce qui se passe lorsqu’on souhaite mettre un modèle en production
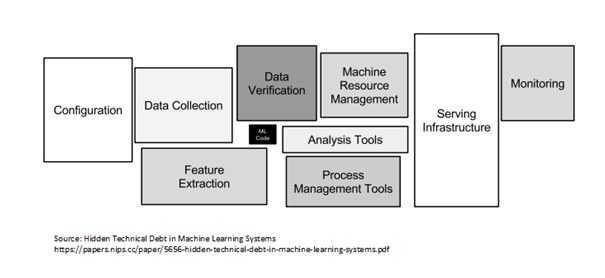
L’écriture du modèle ne représente finalement qu’une mince partie du travail, surtout en prenant en compte l’allure rapide à laquelle les recherches et les articles scientifiques paraissent. Les trouvailles et accomplissements de ces recherches peuvent être consultés sur le célèbre site Arxiv. L’écriture des modèles est un peu plus simple lorsqu’elle est soutenue par des papiers de recherche solides sur lesquels il est possible de s’appuyer.
En pratique, le travail le plus chronophage est tout ce qui entoure et complémente notre modèle. Dans notre exemple cela aurait pu être : vérifier la validité des images et des labels, créer une infrastructure et un environnement d’exécution, un registre de modèles, des outils de maintenance et de supervision etc…
Comment YARN peut-t-il nous aider ?

YARN (Yet Another Ressource Negociator) est un gestionnaire de ressources qui fait partie de l’écosystème Hadoop.
L’objectif de YARN est de distribuer les ressources qui sont mises à sa disposition entre les applications qui les réclament, il s’assure que des applications désignées ont toujours une certaine quantité de ressources et peut refuser l’obtention de certaines ressources à des applications en cas de manque. Les ressources en question peuvent aussi bien être de l’espace de stockage (SATA, SSD, …), de la mémoire vive, des CPUs et, depuis la version 3.1, des GPUs.
YARN donne un moyen aux applications de réserver des ressources à l’avance, il est possible de faire un planning de ses besoins et de les réserver comme on réserverait un billet d’avion. Il est aussi possible de garder un oeil sur ses données à travers des outils comme Grafana. On peut également définir des droits d’accès par utilisateur pour chaque ressource, définir des quotas, et isoler les utilisateurs les uns des autres lors de l’utilisation de ressources managées.
En quoi est-ce utile dans un contexte de Machine Learning ?
Il n’est pas rare qu’un processus d’entrainement de modèle dépasse la mémoire GPU maximale disponible (erreurs OutOfMemory). Dans certains cas d’utilisation spécifiques, la quantité de mémoire requise peut être extrêmement importante.
Cela peut être un problème sérieux si l’entrainement n’est pas isolé du reste de l’infrastructure. Considérant un exemple sans gestionnaire de ressources avec un modèle exécuté dans un environnement de production, le démarrage d’une session d’apprentissage mal configurée peut entraîner le réquisitionnement de toute la mémoire GPU disponible, privant d’autres applications qui termineront en échec suite à un manque de mémoire.
YARN est aussi très utile de par sa faculté de distribuer et orchestrer des applications distribuées.
En effet, il est rare aujourd’hui d’entrainer un modèle sur un seule GPU, ils sont plutôt entrainés sur des fermes de serveurs dédiées. La plupart des frameworks ont maintenant une option pour faire fonctionner un modèle (ou une formation) sur plusieurs machines en même temps, ce qui signifie que ces machines doivent toutes être disponibles. L’idée d’un gestionnaire de ressources et de planification apparaît naturellement.
De plus, YARN prend désormais en charge l’utilisation de conteneurs Docker, qui résolvent le cauchemar de dépendance de pilotes graphiques et ajoutent une couche d’abstraction et d’isolation ainsi que plusieurs autres outils.
Conclusion
YARN peut être très utile dans un environnement d’apprentissage automatique. Ses capacités en termes de planification et de gestion des ressources sont précieuses lorsqu’elles sont appliquées à quelque chose d’aussi volatile que des GPU.
