


Éviter les blocages dans les pipelines distribués de Deep Learning avec Horovod

By JOUET Grégor
15 nov. 2019
- Catégories
- Data Science
- Tags
- GPU
- Deep Learning
- Horovod
- Keras
- TensorFlow [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
L’entraînement des modèles Deep Learning peut être grandement accéléré en utilisant un cluster de GPUs. Lorsqu’il s’agit de grandes quantités de données, effectuer des calculs distribués devient rapidement un défi. Un obstacle récurrent qui est difficile à traiter est l’apparition de blocages entraînant une perte d’efficacité importante lors de l’entrainement d’un modèle.
Aperçu de l’entraînement d’un processus Deep Learning
Quelles sont les étapes de création d’un modèle de Deep Learning ? Prenons l’exemple d’un modèle capable de détecter divers objets dans une image.
- La première étape consiste à acquérir des données, collectées en interne ou à l’aide d’un ensemble de données publiques. Pour la reconnaissance d’images, ImageNet est un bon candidat. Selon le cas d’utilisation, la taille de l’ensemble de données peut varier du giga au téraoctets. N’oubliez pas qu’avec l’apprentissage automatique, plus il y a de données, mieux c’est. Une fois les données recueillies, la prochaine étape obligatoire est de les nettoyer, il faut consacrer beaucoup de temps à cette étape, car un mauvais ensemble de données aura une incidence directe sur l’exactitude du modèle. Rejeter des données à cette étape est courant et un training sur moins de données est préférable à un training sur de mauvaises données. Dans le cas d’un ensemble de données publiques, cette étape ne devrait pas prendre beaucoup de temps, mais les données utilisées devraient toujours être vérifiées.
- L’étape suivante consiste à construire le modèle de Deep Learning pour votre tâche. Dans le cadre de notre exemple, nous pouvons réutiliser des architectures connues telles que VGG ou ResNet. Avec un cas d’utilisation peu commun ou à la pointe de la technologie, vous pouvez trouver de l’inspiration sur le blog de recherche de Google, et également sur le blog de recherche de Facebook. La chose importante à retenir ici est que plus votre modèle est grand, plus vous aurez besoin de données.
Lorsque tout ce qui précède est fait, nous pouvons commencer à entrainer notre modèle. L’entrainement d’un modèle est un processus en 5 étapes :
- Lire l’ensemble des données à partir de la source (disque, mémoire objet, base de données…)
- Associer les données d’entrée (une image) à ses étiquettes de sortie (liste d’objets)
- Mélangez votre ensemble de données
- Enrichir votre ensemble de données, par exemple, avec des images, nous pourrions faire des rotations, des distorsions, des recadrages etc…
- Envoyer les données par lots aux GPU
Lorsque l’ensemble des données a transité par les GPU, vous avez fait une “epoch” et vous aurez besoin de plusieurs “epochs” pour avoir un modèle satisfaisant. Le framework Deep Learning que vous avez choisi fera le reste du travail, c’est-à-dire le calcul des différentes couches de réseaux de neurones, le calcul des gradients, la rétro-propagation, etc…
Une façon intéressante d’étalonner ce processus, ou du moins d’avoir une référence, est d’utiliser des données synthétiques. Au lieu de lire un ensemble de données, utilisez du bruit aléatoire comme entrée. Bien sûr, le modèle sera inutilisable, mais la performance que vous mesurerez vous donnera une idée du coût temporel des quatre premières étapes de notre processus. L’objectif est alors de faire correspondre la “performance synthétique” avec les données réelles de l’ensemble de données.
Le goulot
En exécutant ce processus sur un seul GPU, la différence entre la vitesse synthétique et la vitesse réelle est d’environ 5%. Mais en utilisant 32 d’entre eux, la différence monte à 42%. Cela signifie que nos 32 GPU sont inactifs pendant une longue période. Il y a quelques moyens classiques d’améliorer les performances : pré-recherche ou mise en cache des données de l’ensemble de données, limiter le nombre de threads pour ne pas surabonner le CPU, mais l’écart reste important. Même si certains coûts généraux sont inévitables lors de l’exécution d’un calcul parallèle, la réduction de cet écart est important pour optimiser l’investissement dans l’acquisition de GPUs.
Après avoir examiné le pipeline de données, il semble que l’augmentation du jeu de données prend beaucoup de temps. Mais pourquoi ne pas l’augmenter avant l’entraînement et l’envoyer directement au GPU, cela ne devrait-il pas être plus rapide ? Théoriquement oui, mais ces distorsions et ces rotations se font au hasard et à plusieurs reprises, une fois par “epoch” pour chaque élément du jeu de données. La croissance des données doit se faire juste avant que le modèle ne s’entraîne dessus. De plus, l’ensemble de données enrichi serait d’un ordre de grandeur supérieur à l’ensemble de données original, ce qui créerait de nouveaux problèmes de stockage.
Résoudre le problème des goulots d’étranglement
Tout d’abord, nous voulons que nos GPU soient alimentés en données afin de maintenir l’utilisation à son maximum, le préchargement est donc une nécessité absolue. Des logiciels sont en cours d’élaboration pour s’attaquer au problème des goulots d’étranglement. Horovod en est un bon exemple. Horovod est un framework de training distribué facile à interfacer avec Tensorflow, Keras, PyTorch ou d’autres frameworks de Deep Learning.
Le premier objectif de Horovod est de permettre un training distribuée multi GPU aussi transparent que possible, et avec un minimum de modification du code. Si vous entrainez un modèle sur un seul GPU, il devrait être facile de le passer en multi GPU avec Horovod. Le deuxième objectif de Horovod est d’être rapide. Cela semble évident, mais si Horovod prend du retard par rapport au serveur distribué par défaut de Tensorflow, il ne servira à rien. Il peut être utilisé avec TCP ou RDMA (Remote Direct Memory Access). Bien sûr, vous aurez toujours des coûts généraux, mais des technologies comme RDMA peuvent vous aider à les réduire au minimum. Le dépôt GIT de Horovod contient quelques exemples de processus d’entrainement. Voyons par exemple ce qui devrait être ajouté dans un entraînement avec Keras : Tout d’abord, nous importons la bibliothèque Horovod pour Keras :
import horovod.keras as hvdEnsuite, nous sélectionnons le GPU que nous allons utiliser. Si vous utilisez plusieurs instances d’Horovod sur une même machine, cela permettra à Horovod de partager les GPU entre les processus (généralement un GPU par processus). La fonction hvd.local_rank identifie le processus Horovod local. Vous pouvez bien sûr utiliser plusieurs processus sur une machine pour une seule session d’entraînement mais chacun sera géré par un processus Horovod différent et devrait utiliser un seul GPU. Cette configuration se fait avec le code suivant :
import horovod as hvd
import tensorflow as tf
from keras import backend as K
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(hvd.local_rank())
K.set_session(tf.Session(config=config))Ensuite, nous voulons ajuster le taux d’apprentissage (learning rate) de l’optimiseur en fonction de la taille du cluster. Ensuite, nous construisons l’optimiseur distribué à partir de l’optimiseur choisi. Dans cet exemple, l’optimiseur est Adadelta.
import horovod as hvd
import keras
opt = keras.optimizers.Adadelta(1.0 * hvd.size())
opt = hvd.DistributedOptimizer(opt)Enfin, avant de lancer la session, il est crucial que toutes les sessions soient dans le même état avant l’entraînement. Nous ne pouvons pas initialiser aléatoirement les poids sur tous les nœuds, les gradients n’auraient aucun sens. La session qui lance l’entraînement (celle de rang 0) diffuse l’état initial du modèle. Ceci est implémenté via un callback :
hvd.callbacks.BroadcastGlobalVariablesCallback(0)La commande horovodrun fournit un point d’entrée simple. Le programme ouvrira une connexion ssh vers les hôtes déclarés et commencera la session d’entraînement. Les dépendances (Drivers,OpenMPI, Keras ou Tensorflow etc…) doivent être installées au préalable et une connexion ssh sans mot de passe est requise.
Les concepts derrière Horovod
A la différence du serveur de training distribué de Tensorflow, Horovod s’adosse sur OpenMPI. Le projet MPI est une solution mature dans le domaine de l’informatique distribuée : sa première version date de 1994. Il implémente une fonction de réduction distribuée : allreduce. Cette fonction est utilisée par l’optimiseur Horovod pour agréger les tenseurs denses et les redistribuer à tous les processus.
La différence entre Horovod et le serveur de training distribué par défaut de Tensorflow réside dans leur architecture respective : Tensorflow a une architecture master-slave autoritaire. Cela signifie que tous les workers recevront un lot de données, calculeront les gradients, les enverront au master, le master recevra tous les gradients des workers, fera la moyenne et renverra le gradient moyen aux workers. L’architecture est la même pour les gradients que pour la mise à jour des poids. Horovod, grâce à OpenMPI, utilise l’algorithme ring-allreduce, qui optimise l’utilisation du réseau et ne nécessite pas un serveur principal dont dépend le processus d’entraînement. Chaque instance envoie les vecteurs à réduire sur le réseau à un seul pair dans un mode ‘merry-go-round’ (carrousel), jusqu’à ce que tous les vecteurs soient réduits.
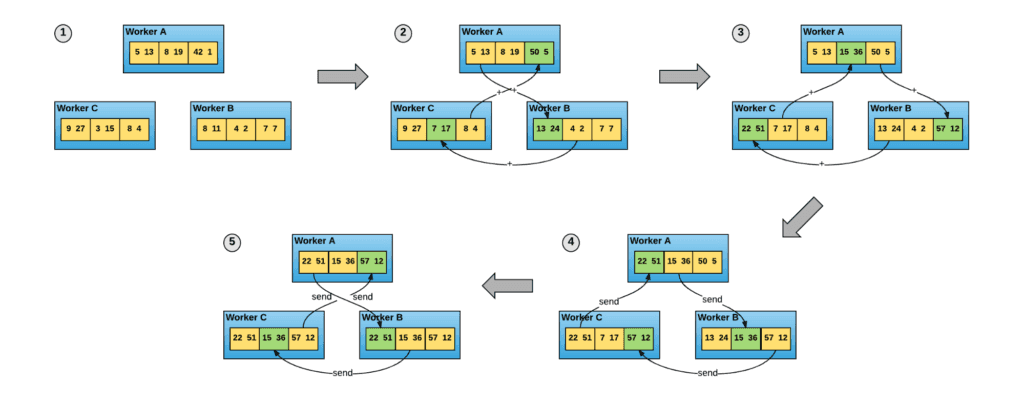
Alors que Tensorflow vous permet de choisir votre stratégie d’entrainement distribué, Horovod et OpenMPI sont de plus bas niveau et profitent de cette proximité avec le matériel (surtout avec RDMA par Ethernet) et ont tendance à surperformer Tensorflow.
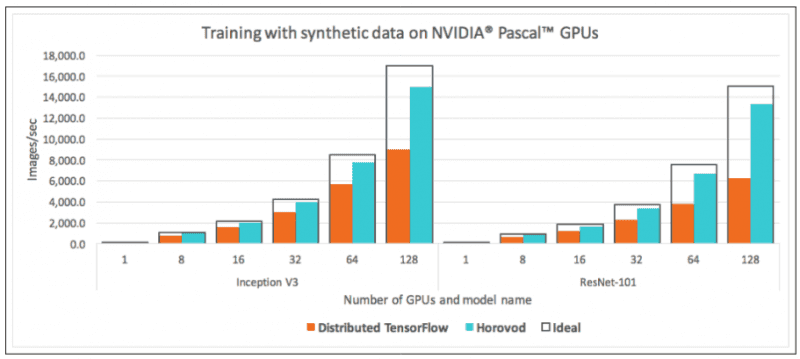
De plus, la version 2 de Tensorflow présente des fonctionnalités majeures, notamment une nouvelle stratégie d’entrainement distribuée : la stratégie CollectiveAllReduce, qui semble donner des résultats remarquables. Horovod reste d’actualité, en particulier avec l’utilisation de PyTorch qui gagne en popularité.
Points clés
- L’informatique distribuée présente de nombreux nouveaux défis, mais c’est une étape obligatoire pour disposer d’un pipeline de Deep Learning efficace.
- Parmi ces problèmes, des goulots d’étranglement peuvent annuler les avantages d’un cluster de Deep Learning.
- Des projets tels que Horovod tentent de fournir une solution rapide et transparente pour un entrainement de Deep Learning distribué.
Sources
- High-Performance Input Pipelines for Scalable Deep Learning : https://www.slideshare.net/Hadoop_Summit/highperformance-input-pipelines-for-scalable-deep-learning
- Article de Uber sur Horovod : https://arxiv.org/pdf/1802.05799.pdf
- OpenMPI : https://www.open-mpi.org/
- Tutoriels OpenMPI : http://mpitutorial.com/tutorials/
- Le dépôt d’Horovod : https://github.com/horovod/horovod
- Papier d’Adadelta : https://arxiv.org/pdf/1212.5701.pdf
