


Introduction à Ludwig et comment déployer un modèle de Deep Learning via Flask

2 mars 2020
- Catégories
- Data Science
- Tech Radar
- Tags
- Enseignement et tutorial
- Deep Learning
- Machine Learning
- Machine Learning
- Python [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Au cours de la dernière décennie, les modèles de Machine Learning et de Deep Learning se sont révélés très efficaces pour effectuer une grande variété de tâches tels que la détection de fraudes, la recommandation de produits, la conduite autonome, etc. En effet plusieurs de ces modèles sont actuellement en production dans le monde entier. Le challenge numéro 1 est celui de pouvoir développer, tester et mettre en production des modèles de Machine Learning et/ou de Deep Learning plus rapidement et plus efficacement.
Cet article porte sur Ludwig v0.2.1, une boîte à outils développée par Uber AI, construite sur Tensorflow qui permet aux utilisateurs confirmés ou novices de pouvoir entraîner et tester des modèles de Deep Learning sans nécessairement écrire de code. Nous allons, dans un premier temps, vous présenter Ludwig, puis développer un modèle de détection de cellules infectées ou non par la Malaria et voir comment facilement le mettre en production avec Flask.
Présentation de Ludwig
Ludwig est une boîte à outils construite sur Tensorflow qui permet d’entraîner et de tester des modèles de Deep Learning sans avoir nécessairement à écrire de code. Il permet aux utilisateurs de construire un modèle de Deep Learning en fournissant simplement un fichier tabulaire (tel que CSV) contenant les données et un fichier de configuration YAML qui spécifie les features d’entrée et de sortie ainsi que les différentes caractéristiques définissant le modèle. La simplicité du fichier de configuration permet un prototypage plus rapide, réduisant potentiellement le temps de développement à quelques minutes. Si plus d’une variable cible de sortie est spécifiée, Ludwig effectuera un apprentissage multitâches, en apprenant à prévoir toutes les sorties simultanément, tâche qui nécessite généralement un code personnalisé. Ludwig peut être utilisé par les développeurs confirmés pour entraîner et tester rapidement des modèles avancées de Deep Learning, ainsi que par les novices qui aimeraient entraîner des modèles simples de Deep Learning.
Ludwig fournit deux fonctionnalités principales :
- L’entraînement et la validation des différents modèles.
- La possibilité de visualiser différents types d’informations liés au modèle.
Les principes de base de la conception de Ludwig sont les suivants :
- Aucun code requis : Aucune compétence en développement n’est requise pour former un modèle et l’utiliser pour obtenir des prévisions.
- Généralité : Une nouvelle approche basée sur un type de données pour la conception de modèles de Deep Learning qui rend l’outil utilisable dans de nombreux cas d’utilisation différents.
- Flexibilité : Les utilisateurs expérimentés ont un contrôle approfondi sur la construction de modèles, tandis que les novices profiteront de la facilité d’utilisation.
- Extensibilité : Ajout facile d’une nouvelle architecture de modèle et de nouveaux types de données d’entités.
- Compréhensibilité : Les composants internes des modèles de Deep Learning sont souvent considérés comme des boîtes noires, mais Ludwig fournit des visualisations standard pour comprendre leurs performances et comparer leurs prévisions.
La nouvelle idée introduite par Ludwig est la notion de codeurs et de décodeurs spécifiques à un type de données, ce qui donne une architecture hautement extensible. C’est à dire que chaque type de données pris en charge (texte, images, catégories, etc.) possède une fonction de prétraitement spécifique.
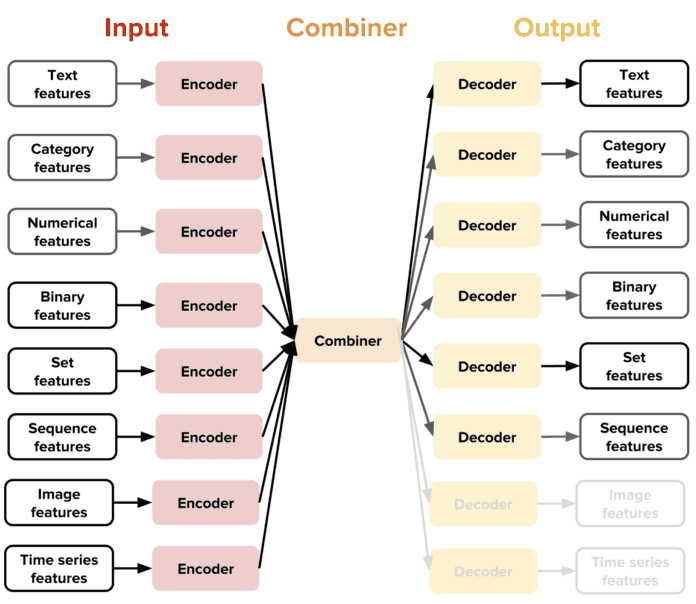
Avec cette conception, l’utilisateur a accès à des combinateurs qui combinent les encodeurs de toutes les features d’entrée, les traitent et renvoient le résultat aux décodeurs de sortie. Par exemple, en combinant un encodeur de texte et un décodeur de catégorie, l’utilisateur peut obtenir un classificateur de texte, tandis que la combinaison d’un encodeur d’image et d’un décodeur de texte permettra à l’utilisateur d’obtenir un modèle de sous-titrage d’image. Cette nouvelle idée permet de répondre à une grande variété de cas d’usage et permet surtout à l’utilisateur d’accéder à de nombreuses fonctions et options différentes qui lui permettent de créer des modèles de pointe pour un besoin spécifique.
Actuellement, Ludwig propose les encodeurs et les décodeurs pour les types de données suivants :
- Binaire
- Numérique
- Catégorie
- Ensemble
- Sac
- Séquence
- Texte
- Timeseries
- Image
- Audio
- Date
- H3
- Vecteur
Ludwig donne la possibilité d’entraîner des modèles sur un ou plusieurs GPU. Il permet également d’utiliser Horovod, un framework qui permet de distribuer ses traitements. Une API de programmation est également disponible pour utiliser Ludwig à partir de votre code/script python. Cette information est très importante. En effet, Ludwig ne supporte que les fichiers tabulaires, tels que des fichiers CSV, en entrée. Cependant avec l’utilisation de l’API il est possible d’utiliser Ludwig avec des dataframes Pandas. Cela permet de pouvoir fournir des données d’entrées de tous types, moyennant des pré-traitements pour les transformer en dataframes Pandas. Une suite d’outils de visualisation permet d’analyser les performances d’apprentissage et de test des modèles et de les comparer.
Installation de Ludwig
Ludwig a été développé et testé avec Python 3. Les dépendances sont les suivantes :
- tensorflow
- numpy
- pandas
- scipy
- scikit-learn
- Cython
- h5py
- tabulate
- tqdm
- PyYAML
- absl-py
Nous recommandons d’utiliser un environnement virtuel (virtenv ou conda) afin d’avoir un environnement Python isolé. Nous avons décidé d’utiliser conda pour sa simplicité. Vous pouvez télécharger anaconda (un environnement conda comprenant les packages les plus utilisés en data science) pour Python 3 ici : https://www.anaconda.com/distribution/. Une fois téléchargé il suffit d’exécuter le script bash d’installation :
cd ~/Téléchargements
bash Anaconda3*.shPour utiliser l’environnement, il faut l’activer au préalable. Nous allons activer notre environnement et installer Ludwig.
conda activate
pip install ludwigLe pip install ludwig installe uniquement les dépendances de base. Cependant, différentes fonctionnalités nécessitent des dépendances supplémentaires. Elles sont divisées en plusieurs catégories afin que vous puissiez installer uniquement ceux dont vous avez vraiment besoin. L’objectif est d’avoir un environnement virtuel isolé et minimaliste afin de pouvoir maintenir et déployer votre environnement plus facilement et efficacement.
Précision :
Anaconda, qui permet d’avoir dès l’installation la majorité des packages les plus utilisés en Python, ne permet pas d’avoir un environnement le plus minimaliste possible. Pour cela, nous vous conseillons de télécharger plutôt miniconda disponible ici : https://docs.conda.io/en/latest/miniconda.html.
Nous utilisons anaconda, pour simplifier l’expérimentation.
Les différentes catégories des différentes fonctionnalités sont :
- Texte :
pip install ludwig[text]- spacy
- bert-tensorflow
- Image :
pip install ludwig[image]- scikit-image
- Audio :
pip install ludwig[audio]- soundfile
- Visualisation :
pip install ludwig[viz]- matplotlib
- Model Serving :
pip install ludwig[serve]- fastapi
- uvicorn
- pydantic
- python-multipart
Vous pouvez installer les dépendances de plusieurs fonctionnalités en même temps :
pip install ludwig[text,images]Si vous comptez entraîner vos modèles sur du GPU, il va falloir désinstaller tensorflow, installé par défaut, afin d’installer à la place tensorflow-gpu
pip uninstall tensorFlow
pip install tensorflow-gpuNous avons deux manières d’utiliser Ludwig, en ligne de commande directement en spécifiant le fichier contenant la définition du modèle et les données d’entrées sous format CSV ou en utilisant l’API directement depuis un code/script python. Nous allons d’abord préparer nos jeux de données pour l’expérimentation.
Préparation des jeux de données
Nous allons utiliser le jeu de données “Malaria Cell Images Dataset” disponible sur Kaggle. Le dossier contient 27.558 images de cellules. 13779 pour les cellules infectées et 13779 pour les cellules saines. Nous allons créer un dossier dans lequel nous allons travailler tout au long de l’article et dans lequel nous allons copier les données que nous avons préalablement téléchargés. L’arborescence du dossier est le suivant :
workdir
├── Parasitized
│ ├── C167P128ReThinF_IMG_20151201_110011_cell_162.png
│ ├── C167P128ReThinF_IMG_20151201_110011_cell_163.png
│ ├── ...
└── Uninfected
├── C100P61ThinF_IMG_20150918_144104_cell_128.png
├── C100P61ThinF_IMG_20150918_144104_cell_127.png
└── ...Nous allons renommer les répertoire par défaut et créer trois autres à partir de ces derniers, dans le but de créer trois jeux de données (train, validation et test). Les jeux de données train et validation permettront de développer le modèle et le jeu de données test permettra de tester le modèle et de pouvoir le valider ou non.
#Delete all the files "Tumbs.db"
rm -rf Parasitized/Thumbs.db
rm -rf Uninfected/Thumbs.db
#Rename directories
mv Parasitized Parasitized_all
mv Uninfected Uninfected_all
#Create the new directories
for i in "_train" "_test" "_validation"; do mkdir Parasitized$i && mkdir Uninfected$i; done
#Transfer data into the specific directory
echo "---Parasitized---"
cd Parasitized_all
cp `ls Parasitized_all | head -5000` ../Parasitized_train
cp `ls Parasitized | tail -n+5001 | head -5000 | wc -l` ..Parasitized_validation
cp `ls Parasitized | tail -n+5001 | tail -3779 | wc -l` ..Parasitized_test
echo "---Uninfected---"
cd Uninfected_all
cp `ls Uninfected_all | head -5000` ../Uninfected_train
cp `ls Uninfected_all | tail -n+5001 | head -5000 | wc -l` ../Uninfected_validation
cp `ls Uninfected_all | tail -n+5001 | tail -3779 | wc -l` ../Uninfected_testVous pouvez modifier le nombre d’éléments qui seront présent dans les différents jeux de données afin de pouvoir tester rapidement. Plus le volume des jeux de données est important, plus l’entraînement du modèle sera long. L’arborescence finale du dossier de travail doit ressembler à celle-ci :
workdir
├── Parasitized_all
│ ├── ...
├── Parasitized_test
│ ├── ...
├── Parasitized_train
│ ├── ...
├── Parasitized_validation
│ ├── ...
├── Uninfected_all
│ ├── ...
├── Uninfected_test
│ ├── ...
├── Uninfected_train
│ ├── ...
└── Uninfected_validation
└── ...Maintenant que nous avons nos répertoires de données, nous allons créer nos trois datasets :
- malaria_cells_train.csv
- malaria_cells_validation.csv
- malaria_cells_test.csv
Pour cela nous allons utiliser un script Python “create_dataset.py”, écrit par Gilbert Tanner, que nous avons modifié pour simplifier la création de nos jeux de données :
import os
import pandas as pd
import argparse
def folder_structure_to_csv(path: str, name: str):
all_folders = [["Parasitized_train","Uninfected_train"],["Parasitized_test","Uninfected_test"],
["Parasitized_validation","Uninfected_validation"]]
for folders in all_folders :
paths = []
labels = []
for folder in folders:
for image in os.listdir(path+'/'+folder):
paths.append(folder+'/'+image)
labels.append(folder.split("_")[0])
df = pd.DataFrame({'image_path': paths,'label': labels})
split_name=name.split(".")
save_path=split_name[0]+"_"+folder.split("_")[-1]+"."+split_name[-1]
df.to_csv(save_path, index=None)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Create CSV from folder structure of a data-set')
parser.add_argument('-p', '--path', type=str, required=True, help='Path to the data-set directory')
parser.add_argument('-n', '--name', type=str, required=True, help='Name of the data-set')
args = parser.parse_args()
folder_structure_to_csv(args.path, args.name)Pour créer les jeux de données il faut exécuter :
python create_dataset.py -p `pwd` -n malaria_cells.csvNous aurons ainsi nos trois datasets avec la structure suivante :
| image_path | label |
|---|---|
| Parasitized_train/C109P70ThinF_IMG_20150930_102716_cell_187.png | Parasitized |
| Uninfected_train/C136P97ThinF_IMG_20151005_144727_cell_100.png | Uninfected |
| ... | ... |
Utilisation de Ludwig
Nous avons nos jeux de données prêt à être utilisé, nous allons pouvoir commencer à manipuler Ludwig. Le but de cette démo est d’entraîner et de tester un modèle de Deep Learning permettant de définir si une cellule est infectée par la Malaria ou pas. Cette section s’organisera comme suit :
- Ludwig en ligne de commande
- Ludwig via l’API de programmation
- Visualisation des statistiques du modèle
Ludwig en ligne de commande
Pour entraîner un modèle, il faut une définition de modèle et le jeu de données sous format CSV. Une définition de modèle est un fichier de configuration YAML qui spécifie les features d’entrée et de sortie ainsi que les différentes caractéristiques du modèle. Vous pouvez avoir plus d’informations, sur la documentation officielle de Ludwig sur quelles sont les différentes caractéristiques que vous pouvez éditer en fonction de votre modèle. Vous pouvez également trouver des exemples de différents cas d’utilisation de Ludwig ici. Voici un exemple simple de définition du modèle pour notre cas d’usage :
input_features:
-
name: image_path
type: image
encoder: stacked_cnn
preprocessing:
resize_method: crop_or_pad
width: 128
height: 128
output_features:
-
name: label
type: category
training:
batch_size: 8
epochs: 2Cette définition de modèle définit les features d’entrées et de sorties ainsi que les différents paramètres nécessaires à la modélisation. Ici nous avons définit pour :
- la feature d’entrée :
- la colonne correspondante dans notre jeu de données
- le type de la donnée
- l’encoder :
stacked_cnnpour appliquer un réseau de neurones convolutif. Vous pouvez également tester avecresnetpour utiliser la méthode ResNet. Vous pouvez retrouver d’avantages d’encodeurs sur la documentation officielle. - un pré-traitement : nous avons redimensionner les images afin que toutes les images soient uniformes
- la feature de sortie :
- la colonne correspondante dans notre jeu de données
- le type de la donnée
- la phase entraînement :
- la valeur du batch_size
- le nombre d’epochs : Nous avons choisi 2 pour tester rapidement
Afin d’entraîner notre modèle nous allons fournir à Ludwig :
- notre jeu de données d’entraînement
- notre jeu de données de validation
- notre définition du modèle
- le répertoire de sortie (par défaut “result”)
ludwig train --data_train_csv malaria_cells_train.csv --data_test_csv malaria_cells_validation.csv --model_definition_file model_definition.yaml --output_directory result_demo
╒══════════╕
│ TRAINING │
╘══════════╛
2019-12-06 16:13:44.099617: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2019-12-06 16:13:44.122479: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2904000000 Hz
2019-12-06 16:13:44.123563: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x563d9e31edd0 executing computations on platform Host. Devices:
2019-12-06 16:13:44.123610: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): <undefined>, <undefined>
2019-12-06 16:13:44.439433: W tensorflow/compiler/jit/mark_for_compilation_pass.cc:1412] (One-time warning): Not using XLA:CPU for cluster because envvar TF_XLA_FLAGS=--tf_xla_cpu_global_jit was not set. If you want XLA:CPU, either set that envvar, or use experimental_jit_scope to enable XLA:CPU. To confirm that XLA is active, pass --vmodule=xla_compilation_cache=1 (as a proper command-line flag, not via TF_XLA_FLAGS) or set the envvar XLA_FLAGS=--xla_hlo_profile.
Epoch 1
Training: 100%|█████████████████████████████| 1250/1250 [03:11<00:00, 6.36it/s]
Evaluation train: 100%|█████████████████████| 1250/1250 [00:35<00:00, 35.48it/s]
Evaluation test : 100%|█████████████████████| 1250/1250 [00:34<00:00, 36.16it/s]
Took 4m 21.4362s
╒═════════╤══════════╤════════════╤═════════════╕
│ label │ loss │ accuracy │ hits_at_k │
╞═════════╪══════════╪════════════╪═════════════╡
│ train │ 0.5079 │ 0.7602 │ 1.0000 │
├─────────┼──────────┼────────────┼─────────────┤
│ test │ 139.5151 │ 0.0000 │ 0.2605 │
╘═════════╧══════════╧════════════╧═════════════╛
Epoch 2
Training: 100%|█████████████████████████████| 1250/1250 [03:13<00:00, 5.88it/s]
Evaluation train: 100%|█████████████████████| 1250/1250 [00:38<00:00, 32.25it/s]
Evaluation test : 100%|█████████████████████| 1250/1250 [00:37<00:00, 36.56it/s]
Took 4m 29.5023s
╒═════════╤═════════╤════════════╤═════════════╕
│ label │ loss │ accuracy │ hits_at_k │
╞═════════╪═════════╪════════════╪═════════════╡
│ train │ 0.3946 │ 0.8311 │ 1.0000 │
├─────────┼─────────┼────────────┼─────────────┤
│ test │ 59.6096 │ 0.3000 │ 0.1752 │
╘═════════╧═════════╧════════════╧═════════════╛
A la fin, un répertoire de sortie est créé, ici nommé result_demo. A chaque exécution, un nouveau répertoire sera créé. Les répertoires seront nommés experiment_run pour le premier et les autres seront nommés experiment_run_$i avec $i allant de 0 au nombre de lancement moins 2. Étant donné que nous avons fait qu’un seul lancement, nous avons qu’un seul répertoire nommé experiment_run. C’est dans ce dossier qu’est enregistré notre modèle ainsi que toutes les caractéristiques et statistiques de notre modèle. L’arborescence du répertoire créé est le suivant :
tree result_demo
experiment_run/
├── description.json
├── training_statistics.json
└── model
├── checkpoint
├── log
│ └── train
│ └── events.out.tfevents.1575645224.Precision5520
├── model_hyperparameters.json
├── model_weights.data-00000-of-00001
├── model_weights.index
├── model_weights.meta
├── model_weights_progress.data-00000-of-00001
├── model_weights_progress.index
├── model_weights_progress.meta
├── training_progress.json
└── train_set_metadata.json
Le répertoire est composé de :
- description.json : qui décrit le modèle
- training_statistics.json : les statistiques liées aux entraînements et tests du modèle
- le modèle
Afin de prédire à partir de notre modèle nous allons fournir à Ludwig :
- notre jeu de données de test
- le lien vers notre modèle
- le répertoire de sortie (par défaut “results”) :
ludwig predict --data_csv malaria_cells_test.csv --model_path result_demo/experiment_run/model/ --output_directory result_demo/output
╒═══════════════╕
│ LOADING MODEL │
╘═══════════════╛
╒═════════╕
│ PREDICT │
╘═════════╛
2019-12-06 16:30:37.706708: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2019-12-06 16:30:37.730468: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2904000000 Hz
2019-12-06 16:30:37.731185: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x56411fbb6d30 executing computations on platform Host. Devices:
2019-12-06 16:30:37.731203: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): <undefined>, <undefined>
2019-12-06 16:30:38.049110: W tensorflow/compiler/jit/mark_for_compilation_pass.cc:1412] (One-time warning): Not using XLA:CPU for cluster because envvar TF_XLA_FLAGS=--tf_xla_cpu_global_jit was not set. If you want XLA:CPU, either set that envvar, or use experimental_jit_scope to enable XLA:CPU. To confirm that XLA is active, pass --vmodule=xla_compilation_cache=1 (as a proper command-line flag, not via TF_XLA_FLAGS) or set the envvar XLA_FLAGS=--xla_hlo_profile.
WARNING:tensorflow:From /home/user/anaconda3/lib/python3.7/site-packages/tensorflow/python/training/saver.py:1276: checkpoint_exists (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.
Instructions for updating:
Use standard file APIs to check for files with this prefix.
Evaluation: 100%|█████████████████████████████████| 1/1 [00:00<00:00, 20.76it/s]
Saved to: result_demo/outputLes résultats sont enregistrés dans le répertoire result_demo/output/. Dans ce répertoire nous avons plusieurs fichiers de différents formats contenant les résultats. Les résultats sont les labels prédits pour chacune des images fournis dans le jeu de données de validation. Nous avons ainsi créer un modèle et prédit des données à partir de celui-ci. Il est possible de fournir une définition de modèle plus avancée. Vous pouvez trouver des exemples de modèles de définition avancées dans la documentation officielle ou sur le site de Gilbert Tanner pour différents cas d’usage.
Ludwig API
Comme mentionné précédemment, l’utilisation de l’API nous permet d’utiliser Ludwig avec des dataframes Pandas. Cela offre une plus grande flexibilité. En effet cela nous permet, par exemple, de croiser des données depuis différentes sources. Il faut effectivement une partie pré-traitement des données, qui au final nous permet d’utiliser Ludwig sur tous types de données. Le script suivant permet d’entraîner le même modèle que celui de la section précédente, avec la possibilité de fournir au choix des dataframes Pandas ou les fichiers CSV.
import ludwig
import yaml
import pandas as pd
from ludwig.api import LudwigModel
#Load CSV
train = pd.read_csv("malaria_cells_train.csv")
test = pd.read_csv("malaria_cells_test.csv")
validation = pd.read_csv("malaria_cells_validation.csv")
# train a model
model_definition = {
"input_features":
[
{"name": "image_name", "type": "image", "encoder":"stacked_cnn","preprocessing":
{"resize_method": "crop_or_pad", "width":128, "height":128}
}
],
"output_features":
[
{"name": "label", "type": "category"}
],
"training":
{"batch_size": 8, "epochs": 2}
}
model = LudwigModel(model_definition)
train_stats = model.train(data_train_df=train,data_test_df=validation)
# or train_stats = model.train(data_train_csv="malaria_cells_train.csv",data_test_csv="malaria_cells_validation.csv")
# or load a model
model_path = "result_demo/experiment_run/model"
model = LudwigModel.load(model_path)
# obtain predictions
predictions = model.predict(data_df=test)
# or predictions = model.predict(data_csv="malaria_cells_test.csv")
model.close()Visualisation des statistiques du modèle
Ludwig propose de visualiser plusieurs types d’informations en lien avec notre modèle. Nous allons vous parler de deux types de visualisations. Vous pouvez trouver plus d’informations sur la documentation officielle de Ludwig.
Visualiser les statistiques d’entraînement de notre modèle
Nous avons la possibilité de visualiser différentes informations en lien avec l’entraînement de notre modèle en fonction des différents epochs :
- les erreurs
- la précision du modèle
- etc.
Pour cela il faut fournir :
- le lien vers le fichier
training_statistics.jsonse trouvant dans le répertoireresult_demo/experiment_run/training_statistics.json
ludwig visualize --visualization learning_curves --training_statistics result_demo/experiment_run/training_statistics.json
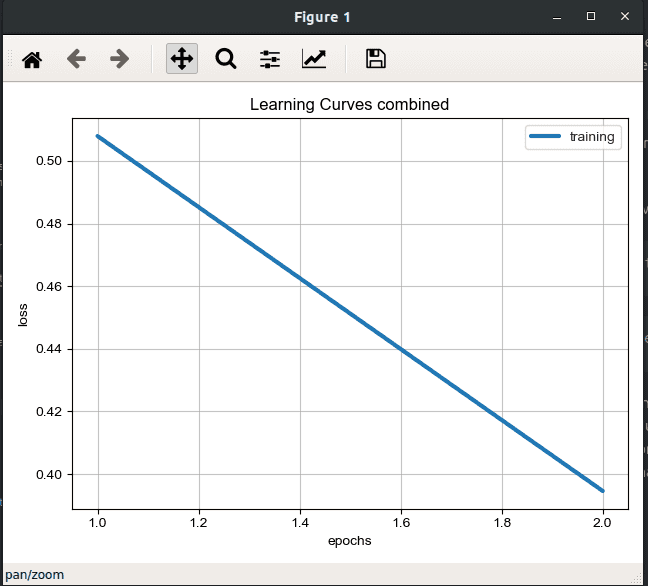
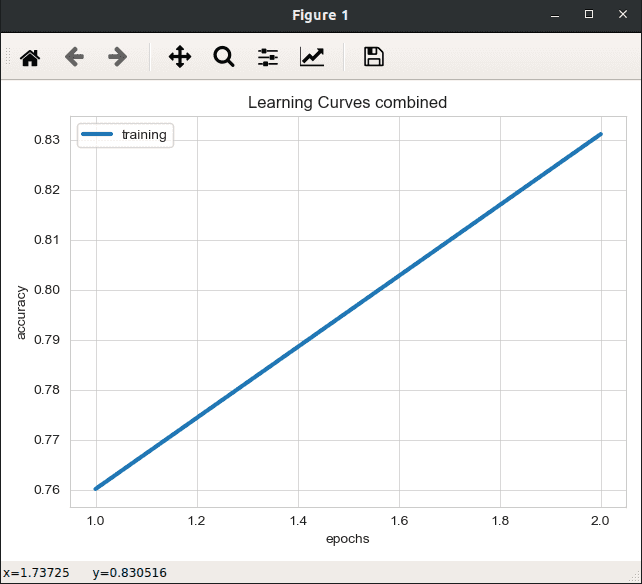
Comparer différents modèles
Nous pouvons également comparer deux modèles afin de pouvoir déceler les forces de l’un et les faiblesses de l’autre. Ce qui peut nous permettre d’affiner notre modèle par exemple. Pour cela il faut fournir :
- le lien vers le fichier
test_statistics_model.jsondes deux modèles.
Dans notre cas, nous avons juste un modèle, mais voici la commande qui permet de faire la comparaison ainsi qu’un exemple de visualisation.
ludwig visualize --visualization compare_performance --test_statistics path/to/test_statistics_model_1.json path/to/test_statistics_model_2.json
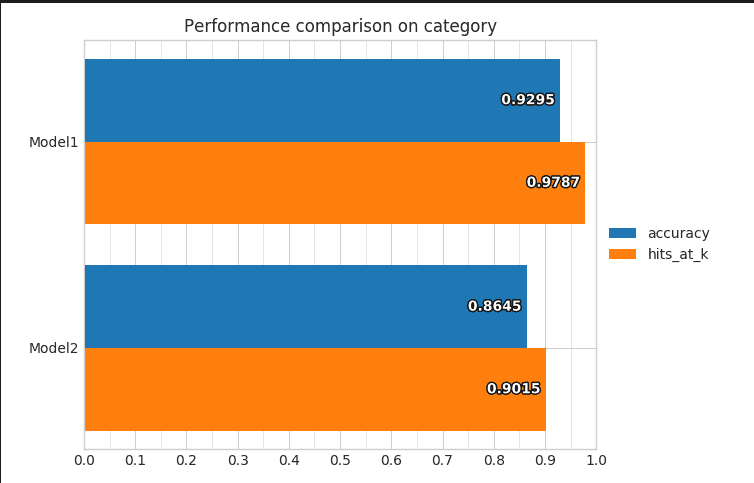
Les deux méthodes d’entraînement de modèles, en ligne de commande ou en utilisant l’API, nous permettent de modéliser facilement et rapidement des modèles de Deep Learning. L’un des avantages également de Ludwig est de pouvoir mettre en production facilement le modèle pré entraîné. En effet sachant qu’un répertoire constitue le modèle, faisant moins de 200Mo, il est plus facile de déplacer et de transférer les modèles. Nous allons vous proposer un moyen de mise en production avec Flask, pour mettre en service un site web qui permettrait de charger une image de cellule et de savoir si la cellule est infectée ou pas via notre modèle.
Mise en production via Flask
Flask est un framework de développement web en Python. Il en existe d’autres. Les plus connus sont Django et Flask. En alliant le langage de programmation Python et un système de templates très riche, on peut créer assez facilement une application web . Dans notre cas, Flask nous permettrait de créer une application Web ou une API simple pouvant être déployée sur de nombreuses plates-formes différentes et permettant ainsi de simplifier la production des modèles de Machine Learning/Deep Learning écrits en Python.
Pour installer Flask :
pip install FlaskPour débuter, voici un code de base application.py qui permet de créer une application web minimaliste :
from flask import Flask
app = Flask(__name__) # create a Flask app
@app.route("/")
def hello():
return "Hello World!"
if __name__=='__main__':
app.run()- Nous importons le module Flask
- Nous créons une route sur la racine de l’application Web
- Nous choisissons de retourner un
Hello World
Pour lancer l’application :
python application.pySi nous allons sur un navigateur et tapons localhost:5000, 5000 étant le port par défaut, nous allons avoir le message suivant : Hello World!
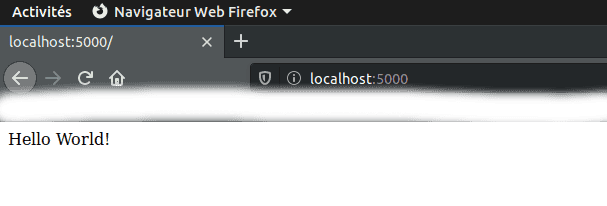
Précision :
Le serveur de développement Flask n’est pas destiné à être utilisé sur des systèmes de production. Il a été conçu spécialement à des fins de développement et fonctionne mal sous une charge élevée. Pour les configurations de déploiement, nous allons utiliser gunicorn. Cela ne change en rien notre façon de développer. Le changement se fera au lancement de l’application web. Au lieu d’exécuter python application.py cela sera plutôt gunicorn -w 4 -b localhost:5000 application:app. Cela permettra de lancer un serveur web plus résistant et plus sécurisé avec plusieurs process, ici 4.
Nous allons développer notre serveur web à partir de ce code minimaliste. Une arborescence type Flask est la suivante :
├── application.py
├── static
│ ├── file.css
│ └── file.js
├── templates
├── index.html
└── upload.html- Le script application .py
- un répertoire
staticqui contiendra tous les fichiers CSS et JavaScript - un répertoire
templatesqui contiendra les pages HTML de notre site web.
Nous allons créer un répertoire templates. Le dossier static n’est pas nécessaire dans notre cas vu que nous allons faire des pages html minimalistes.
mkdir templatesNous allons à présent créer un fichier index.html dans ce répertoire :
<!DOCTYPE html>
<html >
<head>
<meta charset="utf-8">
<title>Malaria Cells Detection </title>
</head>
<body>
<div>
<h1>Upload an image</h1>
<hr>
<form action="/" method="POST" enctype="multipart/form-data">
<label>Select image</label>
<input type="file" name="image" id="image">
<label for="image">Select image...</label>
<button type="submit">Upload</button>
</form>
<br>
<br>
{% if result %}
<h2> The results are : </h2>
{{ result | safe }}
{% endif %}
</div>
</body>
</html>Ce code permet de charger une image et d’afficher un résultat s’il y en a un. Nous aurons un résultat après que l’utilisateur ait chargé une image. Toute la partie backend se fait via le script application.py suivant :
from flask import Flask, render_template, url_for, request
import ludwig
import pandas as pd
from ludwig.api import LudwigModel
app = Flask(__name__)
to_predict={"image_path":["Uploads/image_to_predict.png"]}
# load the model
model_path = "result_demo/experiment_run/model"
model = LudwigModel.load(model_path)
@app.route("/",methods=["POST","GET"])
def home():
if request.method == "GET" :
return render_template("index.html",uid="GET")
elif request.method == "POST" :
if request.files:
image = request.files["image"]
image.filename = "image_to_predict.png"
image.save("Uploads/"+image.filename)
result = model.predict(data_dict=to_predict)
return render_template("index.html", result=result.to_html())
if __name__ == "__main__":
app.run()Ce code permet, dans l’ordre :
- De préparer le jeu de donnée de prédiction avec l’image téléchargée qui se nommera toujours
image_to_predict.png - Nous chargeons notre modèle de Deep Learning déjà pré-entraîné.
- Nous définissons une seule route
/. - Nous définissons une suite de traitements en fonction de la requête passée :
- Pour un GET :
- Nous affichons la page
index.htmlsans résultat.
- Nous affichons la page
- Pour un POST :
- Nous vérifions que l’utilisateur a bien chargé une image
- Nous enregistrons l’image dans le répertoire
Uploadsen le renommant. - Nous utilisons notre modèle afin de prédire si la cellule contenue dans l’image est infectée ou pas
- Nous renvoyons le résultat sous forme de tableau HTML en même temps que la page
index.html
- Pour un GET :
Précision : Ce script n’est pas optimal. Ce code permet d’avoir une vision simplifiée de ce que l’on peut faire via Flask pour mettre en production un modèle de Machine Learning/Deep Learning.
Lançons le serveur web :
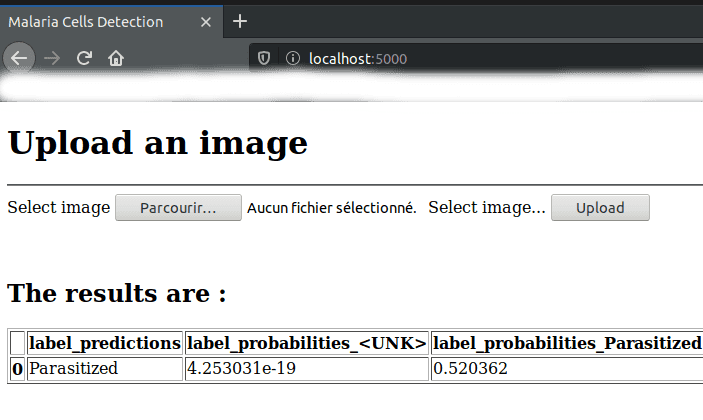
gunicorn -w 4 -b localhost:5000 application:appVoilà à quoi ressemble notre application web :
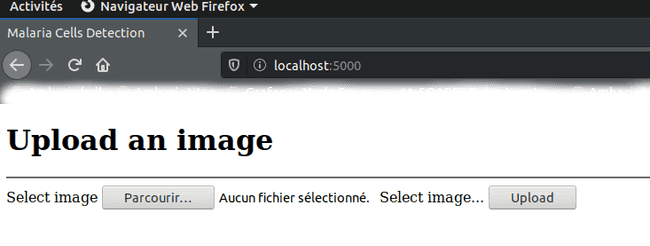
-
En accédant à l’application
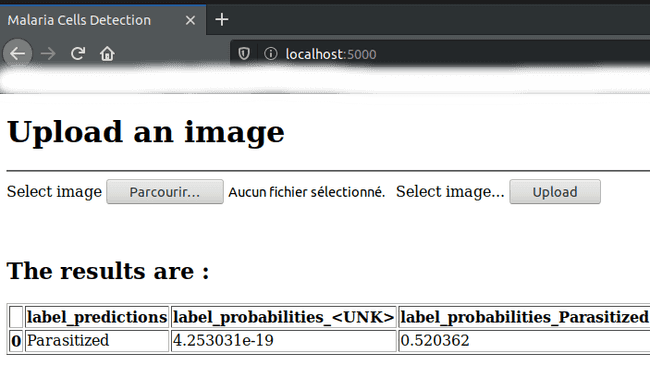
-
En ayant chargé une image
Conclusion
Ludwig est une boîte à outils construite sur Tensorflow qui permet d’entraîner et de tester des modèles de Deep Learning sans avoir nécessairement à écrire de code. En effet, les confirmés pourront entraîner des modèles avancées de Deep Learning, en se focalisant sur le modèle,sans avoir à perdre inutilement du temps sur le développement et/ou problèmes liées aux scripts et non au modèle. Et les novices, pourront débuter facilement et évoluer à leur rythme dans l’entraînement de modèles. En plus de la facilité d’utilisation, Ludwig nous permet de transférer facilement notre modèle pré entraîné sans avoir à passer par des formats pickle ou hdf5 qui peuvent parfois être très volumineux. Suite à notre test de Ludwig, nous pouvons conclure que c’est une technologie très intéressante, que nous allons continuer à suivre. La version actuelle de Ludwig est la 0.2.1, des évolutions majeures sont à prévoir.
