


Importer ses données dans Databricks : tables externes et Delta Lake

21 mai 2020
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Au cours d’un projet d’apprentissage automatique (Machine Learning, ML), nous devons garder une trace des données test que nous utilisons. Cela est important à des fins d’audit et pour évaluer la performance des modèles, développés ultérieurement. En fonction des propriétés d’un jeu de données, notamment sa taille ou son évolution prévue dans le temps, nous devons choisir un format approprié pour l’importer sur une plateforme d’analyse de données. Si nous disposons d’un petit tableau simple qui ne changera pas, nous pouvons généralement l’importer tel quel. Mais si le jeu de données est volumineux et qu’il est prévu de le modifier davantage (par exemple dans le cas d’applications de streaming), une solution plus sophistiquée comme Delta Lake supportant le versionnement des données est envisageable. Databricks offre les deux options et nous les découvrirons dans le prochain tutoriel.
Introduction au Databricks et Delta Lake
Databricks est une plateforme d’analyse de données unifiée, qui réunit des Data Scientists, des Data Engineers et des analystes métiers. L’environnement de développement convivial basé sur des notebooks prend en charge les languages Scala, Python, SQL et R. Les différents environnements d’exécution disponibles sont basés sur Apache Spark, un moteur de calcul distribué en mémoire. Ils ont été conçus et optimisés pour un traitement efficace des Big Data. Databricks est intégré à Amazon AWS et Microsoft Azure et peut se connecter à l’un des outils tiers, comme Tableau pour la visualisation.
Nous pouvons choisir entre deux modes d’essai gratuit pour obtenir un accès à Databricks. L’édition communautaire (CE), hébergée sur AWS, est principalement dédiée à l’apprentissage et sera utilisée pour ce tutoriel. En termes de calcul, elle offre 1 Driver avec 15,3 Go de mémoire, 2 cœurs, 1 DBU (Databrics Unit = unité de capacité de traitement par heure) et aucun worker node. Le temps d’utilisation n’est pas limité, mais après 2 heures d’inactivité, le cluster se termine automatiquement. Une autre possibilité est un essai gratuit de 14 jours, au cours duquel vous avez accès à toutes les fonctionnalités (vous serez toujours facturé pour l’utilisation des services du fournisseur de service cloud).
Delta Lake est une couche de stockage qui s’ajoute à un Data Lake existant (par exemple, le stockage Amazon S3 ou Azure ADLS), et il facilite la gestion et la qualité des données. Il permet des transactions ACID, une gestion échelonnable des métadonnées et le versionnement des données. Son format natif est le Parquet, ce qui signifie qu’il supporte des traitement parallèles et qu’il est entièrement compatible avec Spark. Une table dans Delta Lake est appelée table Delta. Contrairement aux tables Parquet, les tables Delta peuvent être directement modifiées par des insertions, des mises à jour, des suppressions et des fusions (opérations CRUD). De plus, elles peuvent être utilisées comme des tables classiques, ainsi que comme source ou puits de streaming. Lors du streaming de sources multiples ou de jobs batch simultanés, Delta Lake permet un traitement unique des événements. Il existe en version open-source et en version gérée sur Databricks.
Tout d’abord, créez un compte Community Edition si vous ne l’avez pas encore. Les fichiers que nous allons utiliser peuvent être téléchargés ici :
- notebook
data_import.ipynbavec le nécessaire pour importer un jeu de données dans Databricks et créer une table Delta - le jeu de données
winequality-red.csv
J’utilisais Databricks Runtime 6.4 (Apache Spark 2.4.5, Scala 2.11). Delta Lake est déjà intégré dans le runtime.
Créer une table externe
La version exacte des données de test doit être sauvegardée pour reproduire les expériences si nécessaire, par example à des fins d’audit. Nous allons examiner deux façons d’y atteindre : tout d’abord, nous chargerons un ensemble de données dans le système de fichiers Databricks (DBFS) et créerons une table externe. Ensuite, nous apprendrons également comment créer une table Delta et quels sont ses avantages. Le code de ce chapitre se trouve dans le notebook data_import.ipynb.
Pour créer une table, nous devons d’abord importer un fichier source dans le système de fichiers Databricks. Il s’agit d’un système de fichiers distribué monté dans un espace de travail Databricks et disponible sur les clusters Databricks. Il est important de savoir que tous les utilisateurs ont un accès en lecture et en écriture aux données. Vous pouvez y accéder de différentes manières : avec le CLI DBFS, l’API DBFS, les utilitaires DBFS, l’API Spark et l’API de fichiers locaux. Nous utiliserons les utilitaires DBFS. Par exemple, nous pouvons examiner la racine DBFS.
display(dbutils.fs.ls('dbfs:/'))| path | name | size |
|---|---|---|
| dbfs:/FileStore/ | FileStore/ | 0 |
| dbfs:/databricks/ | databricks/ | 0 |
| dbfs:/databricks-datasets/ | databricks-datasets/ | 0 |
| dbfs:/databricks-results/ | databricks-results/ | 0 |
| dbfs:/mnt/ | mnt/ | 0 |
| dbfs:/tmp/ | tmp/ | 0 |
| dbfs:/user/ | user/ | 0 |
Les fichiers importés via l’interface utilisateur seront stockés dans le répertoire /FileStore/tables. Si vous supprimez un fichier de ce dossier, la table que vous avez créée à partir de celui-ci pourrait ne plus être accessible. Les artefacts des exécutions de MLflow peuvent être trouvés dans /databricks/mlflow/. Dans /databricks-datasets/ vous pouvez accéder à de nombreux jeux de données publiques, que vous pouvez utiliser pour l’apprentissage.
Le jeu de données sur la qualité du vin n’est qu’une petite table propre et nous pouvons l’importer directement en utilisant le menu lateral Data puis en suivant les instructions. Cela copiera le fichier CSV dans DBFS et créera une table. Nous pouvons utiliser les API Spark ou Spark SQL pour l’interroger ou effectuer des opérations dessus. Une nouvelle table peut être enregistrée dans une base de données default ou bien dans une base de donnée créée par l’utilisateur, ce que nous ferons ensuite.
%sql
CREATE DATABASE IF NOT EXISTS wine_dbImportez le fichier winequality-red.csv comme indiqué ci-dessous. Changez le nom de la table et placez-la dans une base de données appropriée. Faites attention à cocher les cases pour utiliser la première ligne comme une ligne d’en-tête et pour déduire le schéma de la table. Aucune de ces opérations n’est effectuée par défaut dans Spark.
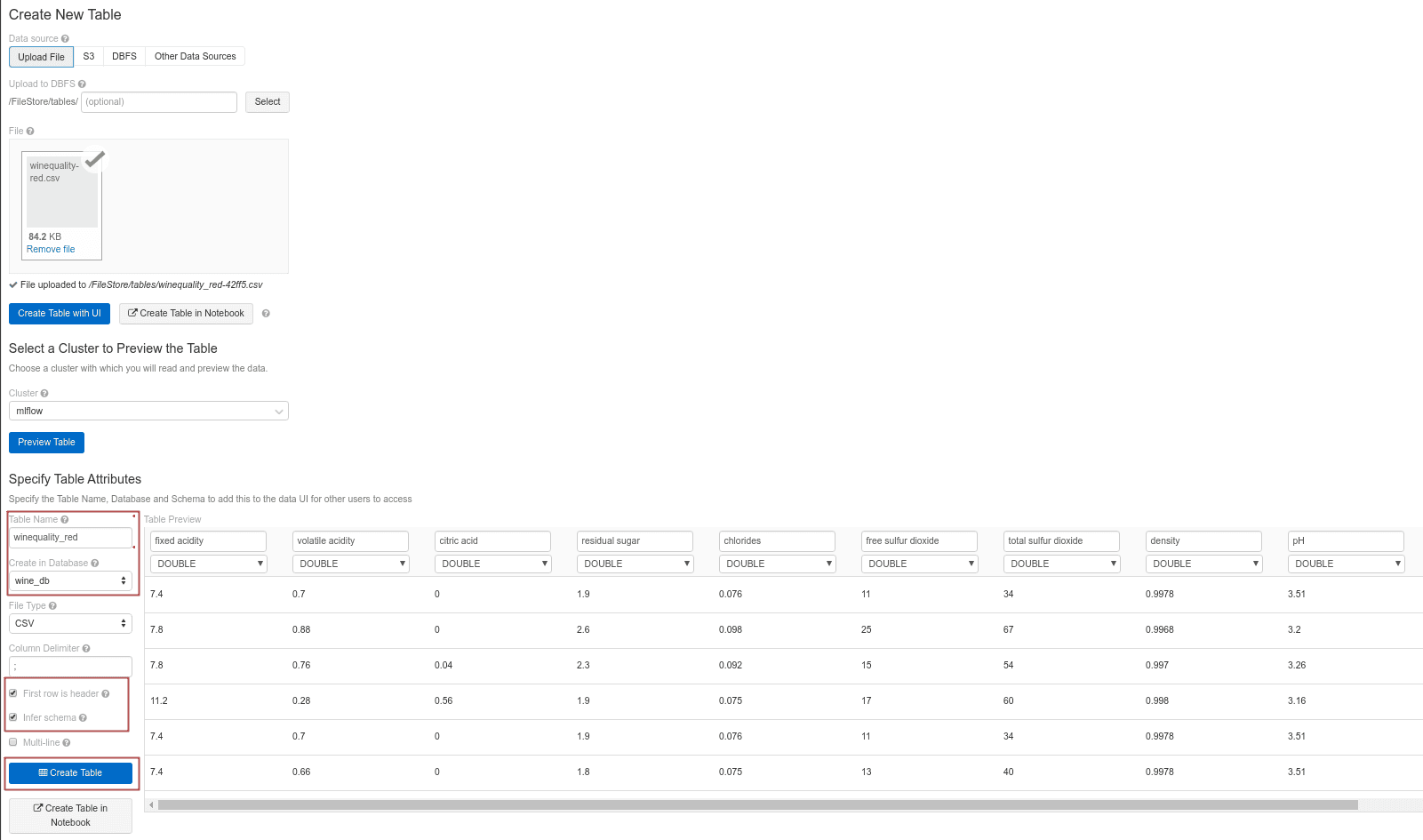
Une fois que la table est créée, il n’est pas facile de la modifier. La seule façon de le faire est de modifier puis de recharger le fichier source avant de rafraîchir la table. Nous pouvons accéder aux données depuis un programme de plusieurs façons. Voici un exemple avec l’API Spark :
query = "select * from winequality_red"
wine = spark.sql(query)
display(wine)Et le même exemple avec Spark SQL :
%sql
SELECT * FROM winequality_redCréer une table Delta
Maintenant, répétons la création de la table avec les mêmes paramètres que nous avons fait auparavant, nommez la table wine_quality_delta et cliquez sur Create Table with a notebook à la fin. Cela va générer un code, qui devrait préciser la création de la table Delta. Nous pouvons le diviser en quatre étapes :
-
Importer le fichier dans DBFS
-
Créer un DataFrame
file_location = "/FileStore/tables/wine_quality-42ff5.csv"
file_type = "csv"
infer_schema = "true"
first_row_is_header = "true"
delimiter = ";"
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
display(df)- A partir du DataFrame, créez une vue temporaire. Si vous ne souhaitez pas enregistrer la table, vous pouvez utiliser cette vue temporaire pour travailler, mais elle n’est accessible qu’à partir du notebook où elle a été créée. Si vous n’en avez pas besoin, vous pouvez sauter cette étape.
#temp_table_name = "winequality_red-42ff5_csv"
temp_table_name = "winequality_red_view"
df.createOrReplaceTempView(temp_table_name)NB : Si le nom du fichier inclut un -, alors le temp_table_name inclura - (par exemple -42ff5). Cela provoque une erreur lors de l’exécution du code. Effacez ou remplacez le -.
- Sauvegarder le DataFrame comme table Delta. Ces données sont accessibles depuis tous les notebooks de votre espace de travail.
permanent_table_name = "wine_quality_delta"
df.write.format("delta").saveAsTable(permanent_table_name)NB : Si les noms des colonnes incluent des espaces ou des caractères spéciaux, vous rencontrerez une erreur. La solution consiste à renommer les colonnes en utilisant un alias avant de les enregistrer :
from pyspark.sql.functions import col
df_corr = df.select(col('fixed acidity').alias('fixed_acidity'), col('volatile acidity').alias('volatile_acidity'), \
col('citric acid').alias('citric_acid'), col('residual sugar').alias('residual_sugar'), col('chlorides'), \
col('free sulfur dioxide').alias('free_sulfur_dioxide'), col('total sulfur dioxide').alias('total_sulfur_dioxide'), \
col('density'), col('pH'), col('sulphates'), col('alcohol'), col('quality'))
display(df_corr)
df_corr.write.format("delta").saveAsTable(permanent_table_name)Cette table Delta a été sauvée dans le Hive store :
display(dbutils.fs.ls('user/hive/warehouse'))Notez que même si nous avons spécifié une base de données, cette option est ignorée. Contrairement à la table créée précédemment, les tables Delta sont mutables, elles peuvent donc être utilisées pour stocker des jeux de données évolutifs ou pour alimenter des tables par des applications de streaming. Elles prennent également en charge la gestion des versions de données, en permettant de consulter l’historique des modifications. Nous pouvons facilement utiliser ou même restaurer n’importe quelle version historique de la table.
Pour illustrer cette fonctionnalité, imaginons que nous sommes le chimiste qui a analysé les échantillons de vin et qui a compilé ce jeu de données. Supposons que nous découvrions que la procédure d’analyse pour déterminer la quantité d’acide citrique est moins sensible que nous le pensions. Nous avons décidé de ne pas supprimer les échantillons de l’ensemble de données, mais de changer toutes les valeurs citric_acid inférieures à 0,1 en 0. Mettons à jour la table.
%sql
UPDATE wine_quality_delta SET citric_acid = 0 WHERE citric_acid < 0.1Cependant, en jouant trop, nous avons accidentellement supprimé une partie de la table.
%sql
DELETE FROM wine_quality_delta WHERE citric_acid = 0Après toutes ces modifications, nous pouvons vérifier l’historique.
%sql
DESCRIBE HISTORY wine_quality_delta

Nous voyons tous les changements énumérés dans le tableau avec de nombreux détails supplémentaires. Si nous voulons récupérer une version spécifique de la table, nous pouvons l’interroger par numéro de version ou par horodatage. Pour récupérer une version avant la suppression, nous sélectionnons VERSION AS OF 1.
%sql
SELECT * FROM wine_quality_delta VERSION AS OF 1
-- ou
SELECT * FROM wine_quality_delta TIMESTAMP AS OF '2020-04-09T15:20:11.000+0000'Conclusion
Dans ce tutoriel, nous avons examiné deux façons d’importer des données dans Databricks. La table externe est plus adaptée aux données immutables ou qui ne changent pas fréquemment, puisque nous ne pouvons les modifier qu’en les recréant et en les écrasant. Elle n’offre pas de version des données. Au contraire, une table Delta peut être facilement modifiée par des insertions, des suppressions et des fusions. De plus, toutes ces modifications peuvent être annulées pour revenir sur une version antérieure dans table Delta. De cette façon, Delta Lake nous offre un stockage flexible et nous aide à maintenir le contrôle sur les modifications des données.
