


H2O en pratique : un protocole combinant AutoML et les approches de modélisation traditionnelles

12 nov. 2021
- Catégories
- Data Science
- Formation
- Tags
- Automation
- Cloud
- H2O
- Machine Learning
- MLOps
- On-premises
- Open source
- Python
- XGBoost [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
H20 est livré avec de nombreuses fonctionnalités. La deuxième partie de la série H2O en pratique propose un protocole pour combiner la modélisation AutoML avec des approches de modélisation et d’optimisations traditionnelles. L’objectif est la définition d’un workflow que nous pourrions appliquer à de nouveaux cas d’utilisation pour gagner en performance et en délai de livraison.
En partenariat avec EDF Lab et ENEDIS, notre objectif commun est d’estimer la difficulté d’embarquer avec la plateforme H2O, de comprendre son fonctionnement, et de trouver ses forces et faiblesses dans le contexte d’un projet réel.
Dans le premier article, une expérience concrête avec H2O, le défi était de construire un modèle à l’aide d’AutoML, et de le comparer avec un modèle de référence, construit avec une approche traditionnelle. Pour le second défi, nous avons reçu un jeu de données prêt à l’emploi provenant d’un problème fonctionnel différent (toujours lié à la maintenance préventive) et cinq jours pour produire le meilleur modèle avec H2O. Pour nous y préparer, nous avons élaboré un protocole opérationnel, que nous présentons dans cet article. Il nous a permis d’entraîner un modèle de base comparable à celui existant en seulement deux jours.
Ce protocole fournit des indications sur la manière de combiner la modélisation AutoML avec les algorithmes de modèles individuels pour améliorer les performances. La durée d’entraînement est analysée à travers deux exemples pour obtenir une image globale de ce à quoi il faut s’attendre.
Environnement, jeux de données et description des projets
Projet 1, la détection de segments de câbles souterrains basse tension nécessitant un remplacement : les jeux de données d’entraînement et de test comportaient chacun un peu plus d’un million de lignes et 434 colonnes. Pour ce cas d’utilisation, nous avons utilisé Sparkling Water, qui combine H2O et Spark et qui distribue la charge sur un cluster Spark.
- H2O_cluster_version : 3.30.0.3
- H2O_cluster_total_nodes : 10
- H2O_cluster_free_memory : 88.9 Gb
- H2O_cluster_allowed_cores : 50
- H2O_API_Extensions : XGBoost, Algos, Amazon S3, Sparkling Water REST API Extensions, AutoML, Core V3, TargetEncoder, Core V4
- Python_version : 3.6.10 final
Projet 2, maintenance préventive, confidentiel : les jeux d’entraînement et de test contenaient environ 85 000 lignes chacun. 605 colonnes ont été utilisées pour l’apprentissage. Dans ce cas, nous avons utilisé une version non distribuée de H2O, fonctionnant sur un seul nœud.
- H2O_cluster_version : 3.30.1.2
- H2O_cluster_total_nodes : 1
- H2O_cluster_free_memory : 21.24 Gb
- H2O_cluster_allowed_cores : 144
- H2O_API_Extensions : Amazon S3, XGBoost, Algos, AutoML, Core V3, TargetEncoder, Core V4
- Python_version : 3.5.2 final
Dans les deux cas, la tâche était la classification d’un jeu de données fortement déséquilibré (< 0,5% de la classe 1). L’AUCPR a été utilisé comme métrique d’optimisation pendant l’apprentissage. Pour l’évaluation finale du modèle, deux métriques métiers ont été calculées, toutes les deux représentant le nombre de défaillances cumulées de lignes d’alimentation sur deux longueurs différentes. Une validation croisée de cinq fois a été utilisée pour valider les modèles. Le défi dans les deux projets était de comparer le meilleur modèle H2O avec le modèle interne de référence, qui était déjà optimisé.
Protocole de modélisation avec H2O
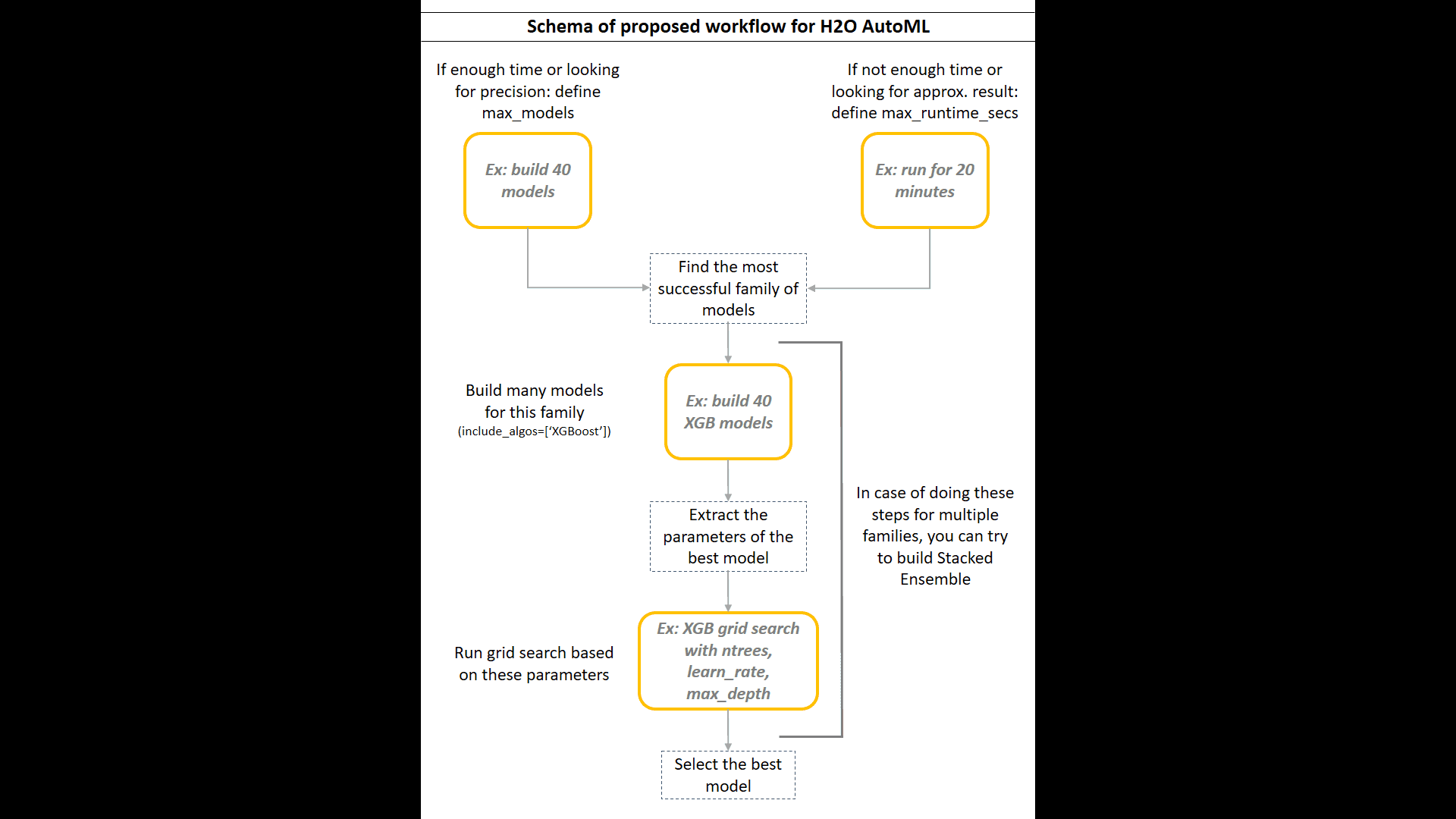
Nous avons combiné les fonctionnalités d’AutoML avec des algorithmes de modélisation individuels pour obtenir le meilleur des deux mondes. Après avoir essayé différentes approches, nous avons trouvé que le protocole proposé suivant était le plus concis et le plus simple.
- En fonction du temps disponible :
- Si vous avez assez de temps, lancez AutoML pour construire beaucoup de modèles (30+) sans limite de temps, pour obtenir l’entraînement le plus long et le plus précis (
H2OAutoML:max_models). - Si vous manquez de temps, ou si vous ne cherchez qu’un résultat approximatif pour estimer la performance de base, définissez le temps maximal d’entraînement (
H2OAutoML:max_runtime_secs).
-
Calculez une métrique métier (et/ou les métriques supplémentaires) pour chaque modèle et rassemblez-les dans un tableau de classement customisé.
-
Fusionner le tableau de classement AutoML et le tableau de classement customisé et inspecter :
- Quelle famille de modèles atteint le score le plus élevé ?
- Comment les métriques métiers et métriques statistiques sont-elles corrélées ?
- Les performances de certains modèles sont-elles si mauvaises que nous ne voulons pas passer plus de temps à les optimiser ?
En raison de la confidentialité du projet, nous ne décrirons que les résultats pour illustrer l’exemple. La famille XGBoost a obtenu de bien meilleures performances que tout autre algorithme. L’apprentissage profond a obtenu les pires résultats, ce qui n’est pas surprenant sur des données tabulaires. Par exemple, le meilleur modèle XGBoost a trouvé 3 à 4 fois plus d’incidents que le meilleur modèle d’apprentissage profond, en fonction de la métrique métier. La deuxième famille la plus performante était GBM, qui, dans le meilleur des cas, a trouvé environ 90 % des incidents de XGBoost. Dans les deux projets, les modèles avec l’AUCPR le plus élevé avaient les métriques métiers les plus élevées, mais généralement, la corrélation n’était pas importante.
-
Exécuter une recherche de grille AutoML sur les familles d’algorithmes les plus performantes (
H2OAutoML:include_algos). Testez de nombreux modèles. Sélectionnez les modèles que vous souhaitez optimiser (modèles d’intérêt) et sauvegardez-les. -
Imprimez les paramètres réels des modèles d’intérêt (
h2o.get_model(model_name).actual_params). -
Utilisez ces paramètres comme base dans la définition manuelle du modèle. Définissez les hyperparamètres pour la recherche de grille (
H2OGridSearch). Si vous voulez tester beaucoup ou si vous manquez de temps, utilisez la stratégie de recherche aléatoire sur grille. Sinon, construisez les modèles à partir de toutes les combinaisons des hyperparamètres (stratégie cartésienne). -
Calculez des métriques supplémentaires sur les modèles de recherche en grille et inspectez éventuellement l’importance des variables. Les modèles ayant des scores similaires peuvent être basés sur un ensemble différent de variables, qui peuvent être plus importantes pour le contexte commercial que le simple score.
-
Sélectionnez le(s) meilleur(s) modèle(s) pour chaque famille et enregistrez-le(s).
-
En option, construisez des ensembles empilés et recalculez les métriques supplémentaires.
Combien de temps cela prend-il ?
Nous avons utilisé deux jeux de données de tailles différentes (1 million de lignes x 343 colonnes et 85 000 lignes x 605 colonnes). Comme ils ont été traités dans deux environnements différents, nous ne pouvons pas comparer directement les temps de traitement. Avec les estimations approximatives de la durée de chaque phase, nous aimerions vous donner une idée de ce à quoi vous pouvez vous attendre.
Déroulement du projet 1 :
- construire 40 modèles AutoML → ~ 8.5 h
- extraire les paramètres du meilleur modèle de chaque famille et définir les hyperparamètres pour l’optimisation (dans ce cas, XGB et GBM)
- recherche aléatoire :
- 56 modèles XGB → ~ 8 h (+ métriques métiers → ~ 4,5 h)
- 6 modèles GBM → ~ 1 h (+ métriques métiers → ~ 0,5 h)
- recherche aléatoire :
- Sauvegarder les meilleurs modèles
Compte tenu du fait que les jeux de données n’était pas très grand (< 200 Mo), nous avons été surpris qu’il ait fallu autant de temps à AutoML pour terminer 40 modèles. Peut-être qu’ils n’ont pas bien convergé, ou que nous devrions optimiser les ressources du cluster. Notre solution privilégiée était de commencer les longs calculs en fin de journée et d’avoir les résultats le matin.
Déroulement du projet 2 :
- exécution d’AutoML pendant 10 minutes (temps déterminé ; + métriques métiers ~ 15 minutes)
- construire 30 modèles GBM avec AutoML → ~ 0,5 h (+ métriques métiers → ~ 1 h)
- extraire les paramètres du meilleur modèle et définir les hyperparamètres pour la recherche de grille
- recherche aléatoire : 72 modèles GBM → ~ 1 h (+ métriques métiers → ~ 2 h)
- sauvegarder le meilleur modèle
Le deuxième jeux de données était plutôt petit, et nous avons réussi à exécuter toutes les étapes en une journée de travail.
Les modèles étaient-ils bons ?
La comparaison était basée uniquement sur les valeurs des métriques métiers. Nous n’avons pas effectué de tests statistiques appropriés sur les résultats, bien que nous ayons pris en compte la variance de nos résultats. Il ne s’agit donc pas d’une référence mais d’une observation. Dans les deux cas, nous sommes parvenus à produire des modèles ayant à peu près les mêmes performances que les références. En général, nous avions plusieurs candidats avec des scores similaires. Plus important encore, nous avons atteint ce résultat en une fraction du temps nécessaire pour le modèle de référence.
Conclusion
Nous avons montré sur deux problèmes réels comment réduire le temps nécessaire à la construction d’un bon modèle de base en tirant parti de l’apprentissage automatisé avec H2O. Après avoir investi du temps pour comprendre les avantages et les limites de la plateforme, nous avons été en mesure de construire un modèle comparable au modèle de référence en seulement quelques jours. C’est un gain de temps considérable par rapport à l’approche traditionnele. De plus, l’API facile à utiliser réduit le temps de codage et simplifie la maintenance du code.
Remerciements
Les collaborateurs ayant contribué à ce travail sont :
- Somsakun Maneerat, EDF Lab, Data scientist
- Benoît Grossin, EDF Lab, Project manager
- Jérémie Mérigeault, ENEDIS, Data scientist
