


CDP partie 1 : introduction à l'architecture Data Lakehouse avec CDP

By BAUM Stephan
8 juin 2023
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Cloudera Data Platform (CDP) est une data platform hybride pour l’intégration de donnée, le machine learning et l’analyse de la data. Dans cette série d’articles nous allons décrire comment installer et utiliser une architecture big data bout en bout avec Cloudera CDP Public Cloud sur Amazon Web Services (AWS).
Cette architecture a été pensée pour récupérer de la donnée d’une API, la stocker dans un data lake puis la déplacer dans un data warehouse et enfin permettre sa restitution dans une application de datavisualisation à destination des analystes.
Cette série est composée des 6 articles suivants :
- CDP partie 1 : introduction à l’architecture Data Lakehouse avec CDP
- CDP partie 2 : déploiement d’un environnement CDP Public Cloud sur AWS
- CDP partie 3 : activation des Data Services en environnement CDP Public Cloud
- CDP partie 4 : gestion des utilisateurs sur CDP avec Keycloak
- CDP partie 5 : gestion des permissions utilisateurs sur CDP
- CDP partie 6 : cas d’usage bout en bout d’un Data Lakehouse avec CDP
Considérations architecturales
L’objectif de notre architecture est de proposer un data pipeline qui servira à analyser les variations de prix d’actions de plusieurs sociétés. Nous lui ferons récupérer de la donnée, l’ingérer et finalement l’afficher sur un graphique pour en faire ressortir des informations pertinentes.
Cette architecture doit répondre aux conditions ci-dessous :
-
Nous voulons une application qui extrait les cours des actions depuis une API web et les écrit dans le service de stockage d’un cloud public.
-
Nous voulons aussi des traitements qui transforment la donnée et les chargent dans un entrepôt de données.
-
Le data warehouse doit être capable d’absorber la donnée entrante et être requêtable en SQL. De plus, nous voulons pouvoir utiliser le tout récent format de table Apache Iceberg.
-
Enfin, nous utiliserons les services analytiques présents nativement dans la plateforme Cloudera.
Avec toutes ces informations, regardons plus en détail ce qu’offre CDP.
Architecture de CDP
Chaque compte CDP permet d’accéder à une console d’administration qui facilite le déploiement et les opérations des services CDP Public Cloud. Cloudera propose sa console d’administration dans trois régions : us-west-1 hébergée aux USA, eu-1 localisée en Allemagne, et ap-1 basée en Australie. Au moment de la rédaction de l’article, us-west-1 est la seule région disposant de la totalité des services de la plateforme. La documentation officielle CDP Public Cloud documentation liste les services disponibles pour chacune des régions.
CDP Public Cloud ne stocke pas de donnée ni n’effectue de traitement par elle-même. Lors d’un déploiement sur un cloud public, CDP utilise l’infrastructure d’un cloud public tiers - AWS, Azure, ou Google Cloud - pour effectuer les calculs et stocker la donnée des services qu’elle propose. CDP offre aussi à ses utilisateurs la possibilité de se déployer sur un cloud privé, pouvant être installé sur du matériel on-premise ou sur une infrastructure cloud ; Cloudera fournit alors l’application Cloudera Manager qui est hébergée sur votre infrastructure afin de configurer et de monitorer précisément ce type de clusters privés. Dans cet article et les suivants, nous nous focaliserons exclusivement sur un déploiement sur le cloud public AWS.
CDP Public Cloud permet aussi à ses utilisateurs de créer de multiples environnements hébergés sur des clouds publics différents. Un environnement est constitué de machines et de réseaux virtuels sur lesquels seront installés les services managés. Un environnement comporte aussi des configurations telles que les utilisateurs habilités et les permissions associées.
Chaque environnement est indépendant : un même utilisateur CDP peut lancer des environnements sur un seul cloud ou des environnements sur des clouds publics différents.
Néanmoins, il est important de souligner que certains services ne sont pas disponibles pour l’ensemble des clouds publics. Par exemple, au moment de la rédaction de l’article, seuls les environnements hébergés sur AWS permettent l’utilisation des tables Apache Iceberg avec le service CDP Data Engineering.
Le schéma ci-dessous décrit les interactions entre CDP et le fournisseur cloud externe :
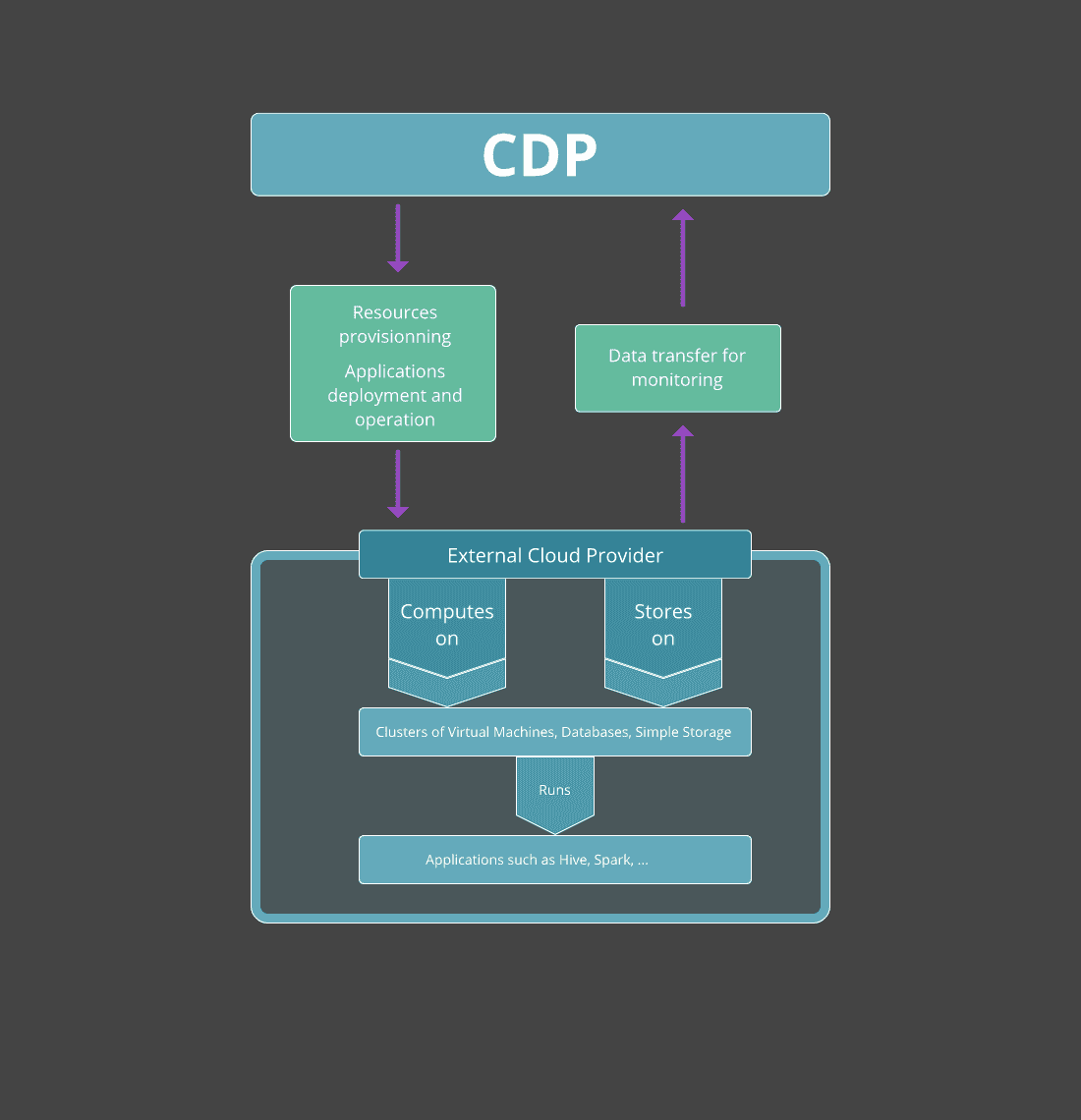
Les Services de CDP
L’image ci-dessous montre la page d’accueil de la console CDP, l’interface web de la plateforme, dans la région us-west-1 :
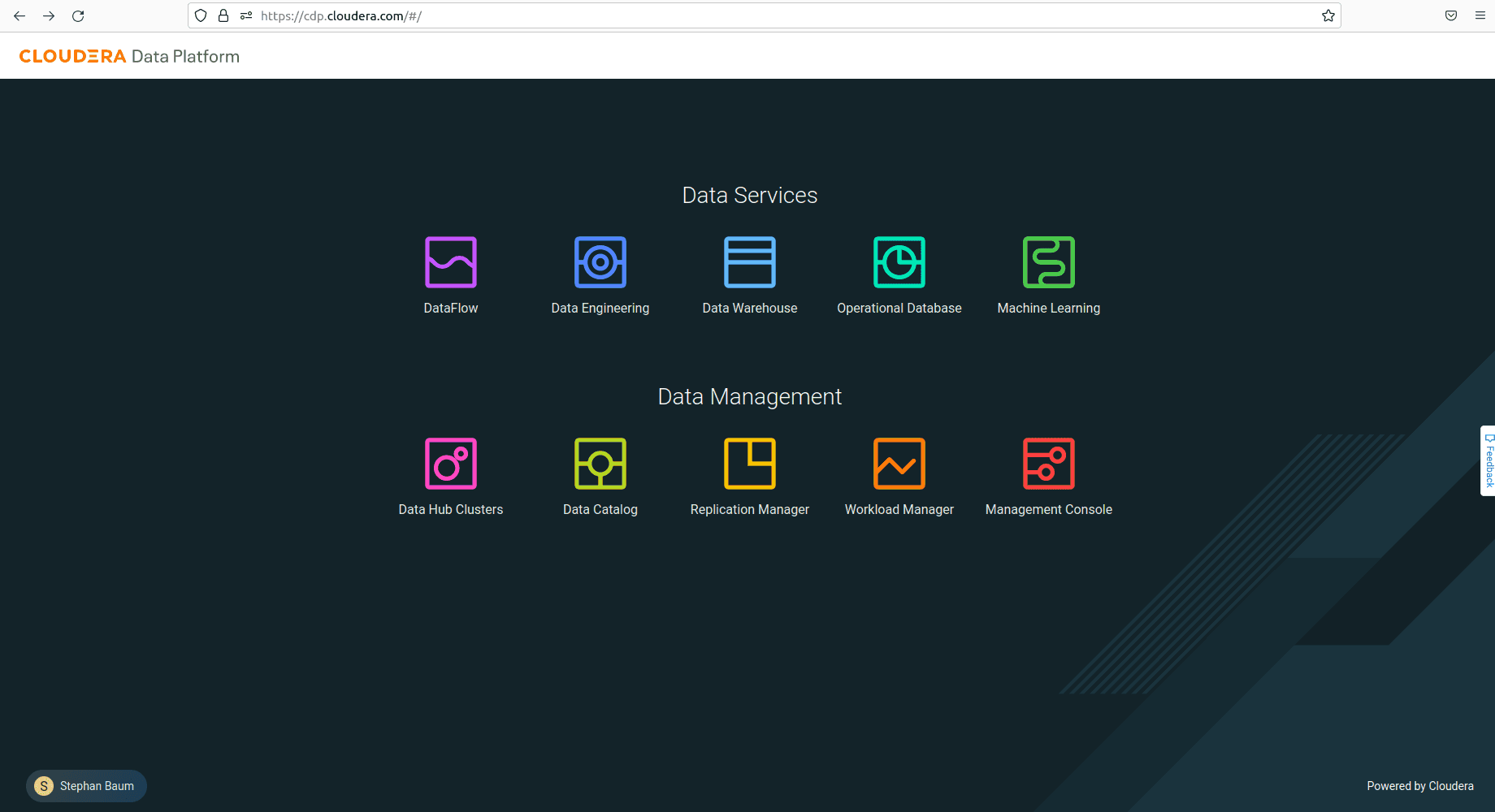
L’ordre d’affichage des services, de la gauche vers la droite, correspond à la logique d’un pipeline de traitement. Le service DataFlow extrait de la donnée depuis différentes sources, le service Data Engineering s’occupe ensuite des transformations à appliquer dessus. Les services Data Warehouse et Operational Database proposent de la donnée prête à l’emploi et enfin, le service Machine Learning permet aux data scientists d’appliquer des traitements d’Intelligence Artificielle (IA) sur la donnée.
Décrivons les services plus en détail, en nous attardant sur ceux que nous utiliserons dans notre architecture bout en bout.
DataFlow
Ce service est une application de streaming qui permet à l’utilisateur de récupérer de la donnée de diverses sources via des déclencheurs et de la stocker dans diverses destinations, comme un bucket AWS S3, en attente de leur traitement.
Le composant sous-jacent de ce service est Apache NiFi.
Tous les flux de données créés par les utilisateurs sont stockés dans un catalogue. Les utilisateurs peuvent en sélectionner parmi ceux disponibles et les déployer sur un environnement. Il existe des flux prêts à l’emploi pour des cas spécifiques disponibles dans la ReadyFlow gallery visible ci-dessous.
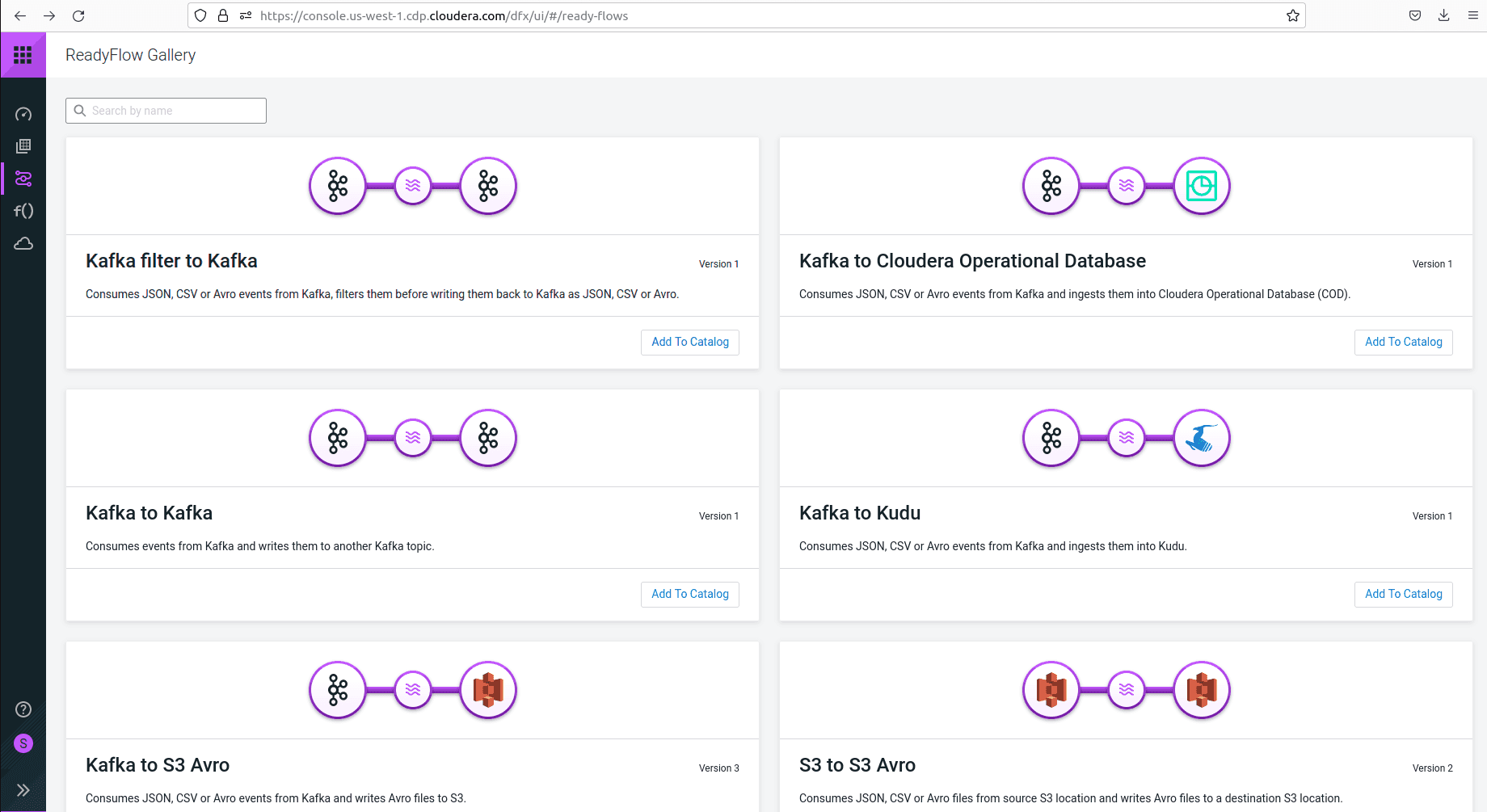
Dataflow peut être activé soit sous forme de “déploiement”, ce qui provisionne un cluster dédié chez votre fournisseur cloud, ou dans un mode “fonctions” qui s’appuie sur des technologies serverless (AWS Lambda, Azure Functions ou Google Cloud Functions).
Data Engineering
Dans CDP Public Cloud, ce service est le composant principal servant d’ETL (Extract, Transform and Load). Il prend en charge l’orchestration automatique d’un pipeline pour l’ingestion et le traitement des données afin de les préparer pour des usages ultérieurs. Il prend les données d’une zone de stockage alimentée par DataFlow pour lancer ensuite des jobs Spark ou AirFlow. Pour pouvoir utiliser ce service, les utilisateurs doivent l’activer et créer un cluster virtuel sur lequel ces jobs d’orchestration peuvent être lancés. Ce service a donc aussi besoin de machines virtuelles et de clusters de bases de données hébergées chez votre fournisseur cloud.
Data Warehouse
Ce service propose aux utilisateurs de créer des bases de données et des tables et de requêter la donnée via du SQL. Un Datawarehouse stocke la donnée de manière à pouvoir l’analyser, et le service inclut la possibilité de visualiser les données. Les utilisateurs doivent activer le service Data Warehouse pour leur environnement et créer un “data warehouse virtuel” pour prendre en charge les traitements analytiques. Ces actions provisionnent des clusters Kubernetes et un filesystem pour le stockage (EFS chez AWS) sur le cloud externe.
Operational Database
Ce service provisionne des bases de données pour traiter des opérations dynamiquement et est plus particulièrement optimisé pour les transactions interactives (OLTP). Il se distingue en ça du service Data Warehouse, qui a été optimisé pour l’analyse à froid (OLAP). Comme nous n’avons pas besoin de base de données OLTP, nous n’utiliserons pas le service Operational Database, et nous ne le verrons pas plus en détail. Vous pourrez comparer les solutions OLTP and OLAP dans notre article sur les différents formats de fichier en Big Data et avoir plus de détail concernant Operational Datastore dans la documentation officielle Cloudera.
Machine Learning
CDP Machine Learning est l’outil utilisé par les data scientists pour effectuer des prévisions, classifications et autres tâches en relation avec l’IA. Nous ne rentrerons pas dans les détails de ce service, car il n’est pas utilisé dans notre architecture cible. Pour toute information complémentaire, vous pouvez vous référer au site de Cloudera.
Notre Architecture
Maintenant que nous avons survolé les services proposés par CDP, l’architecture suivante se détache :
-
Notre environnement CDP Public Cloud sera hébergé sur AWS car c’est actuellement la seule option pour utiliser les tables Iceberg.
-
Les données sont récupérées en utilisant CDP DataFlow et stockées dans un data lake construit sur Amazon S3.
-
Les données seront traitées par des jobs Spark lancés via le service Data Engineering.
-
Les données ainsi traitées seront chargées dans un Data Warehouse et, en bout de chaîne, seront visualisables grâce à la fonctionnalité Data Visualization.
Les deux prochains articles seront sur la configuration de l’environnement. Le suivant vous apprendra à gérer les utilisateurs et les permissions. Enfin, nous créerons le pipeline de traitement de la donnée.
Pour poursuivre : Les prérequis
Si vous voulez suivre la progression de notre série d’articles et déployer votre propre architecture, certains prérequis sont nécessaires.
Besoins en ressources AWS et gestion des quotas
Comme vu dans les sections précédentes, chaque service CDP provisionne des ressources chez le fournisseur cloud externe. Par exemple, le lancement de tous les services nécessaires déploiera une flottille d’instances EC2 utilisant un nombre conséquent de CPU virtuels.
Par conséquent, vous devez être attentif au quota du service Standard Instance Run on Demand (A, C, D, H, I, M, R, T, Z). Ce quota détermine combien de CPUs virtuels peuvent être provisionnés de manière simultanée.
Pour vérifier que votre quota est suffisamment élevé et l’augmenter si nécessaire, faites les actions suivantes dans votre console AWS :
- Choisissez la région dans laquelle vous souhaitez provisionner les ressources
- Cliquez sur votre nom d’utilisateur
- Cliquez sur Service Quotas
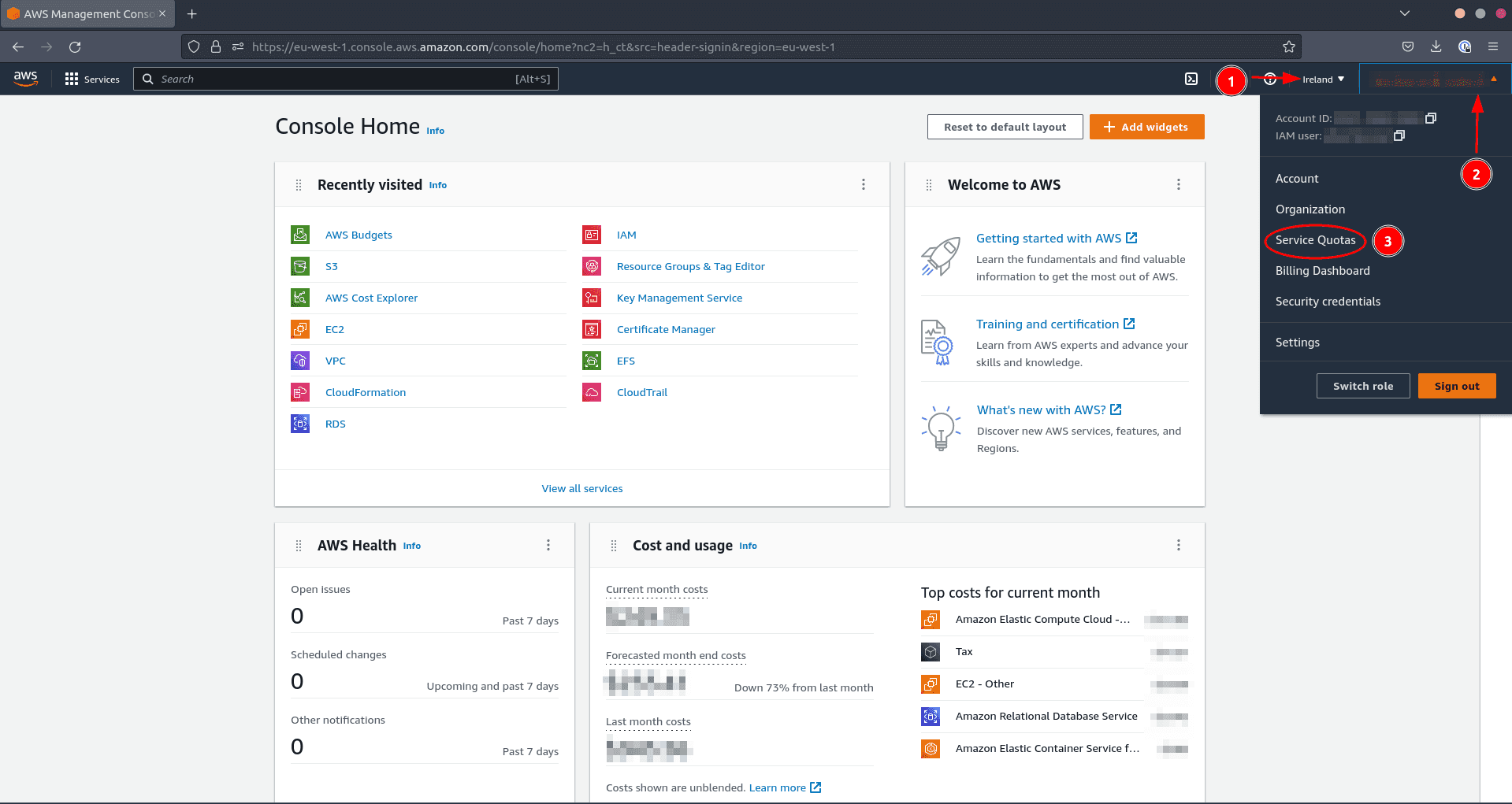
Regardons maintenant les quotas pour EC2
- Cliquez sur Amazon Elastic Compute Cloud (Amazon EC2)
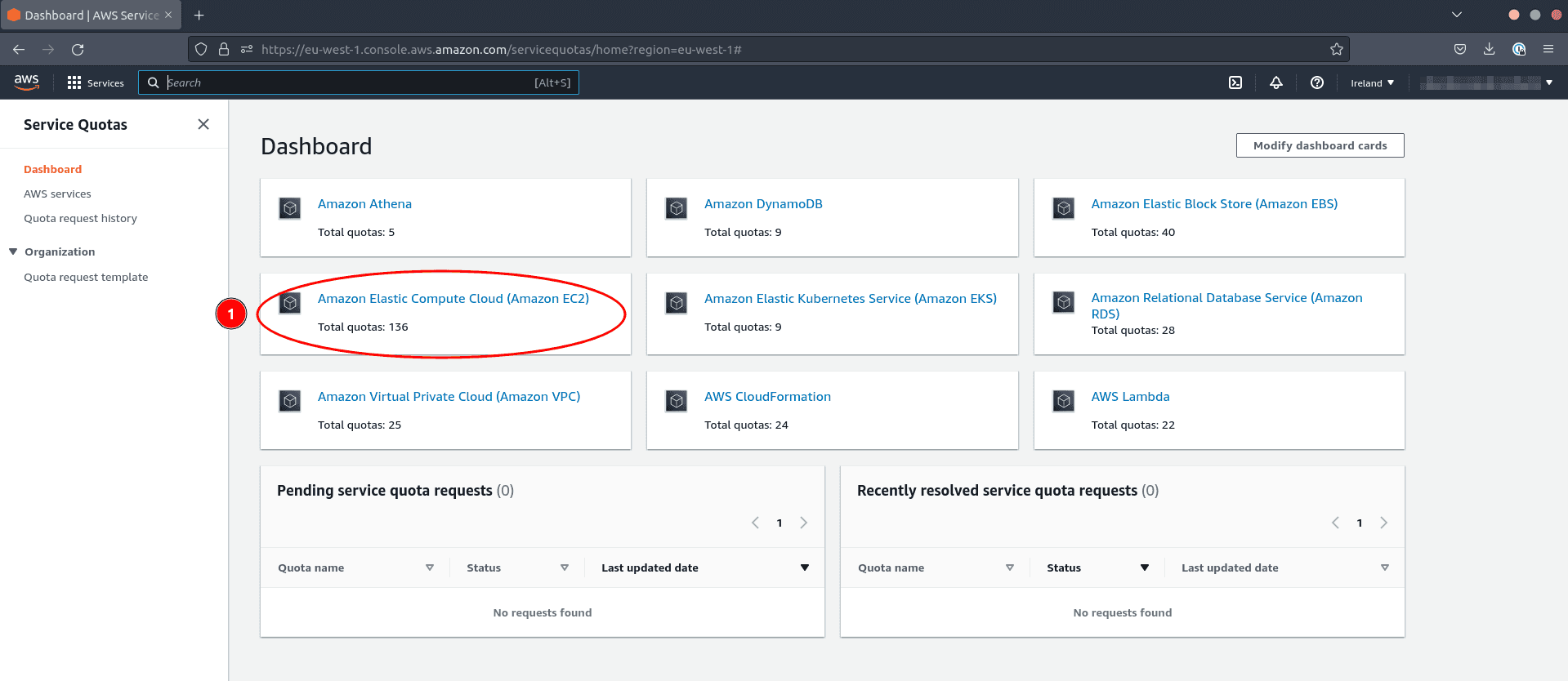
Pour vérifier le quota précis limitant votre usage de vCPU :
- Tapez
Running On-Demand Standard (A, C, D, H, I, M, R, T, Z) instances - Vérifiez que le nombre de CPUs virtuel est supérieur à 300 pour être confortable.
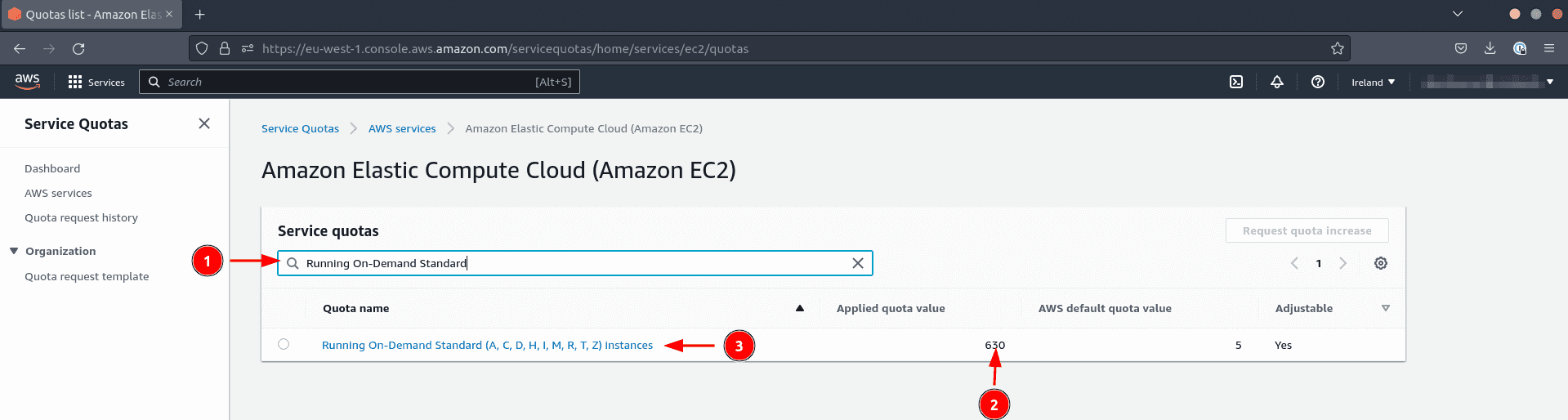
Si le quota est trop bas, faites une demande d’augmentation du quota. Cette demande peut prendre plus de 24 heures à être validée.
- Cliquez sur le nom du quota (action 3 dans l’image précédente)
- Cliquez sur Request quota increase pour demander une augmentation
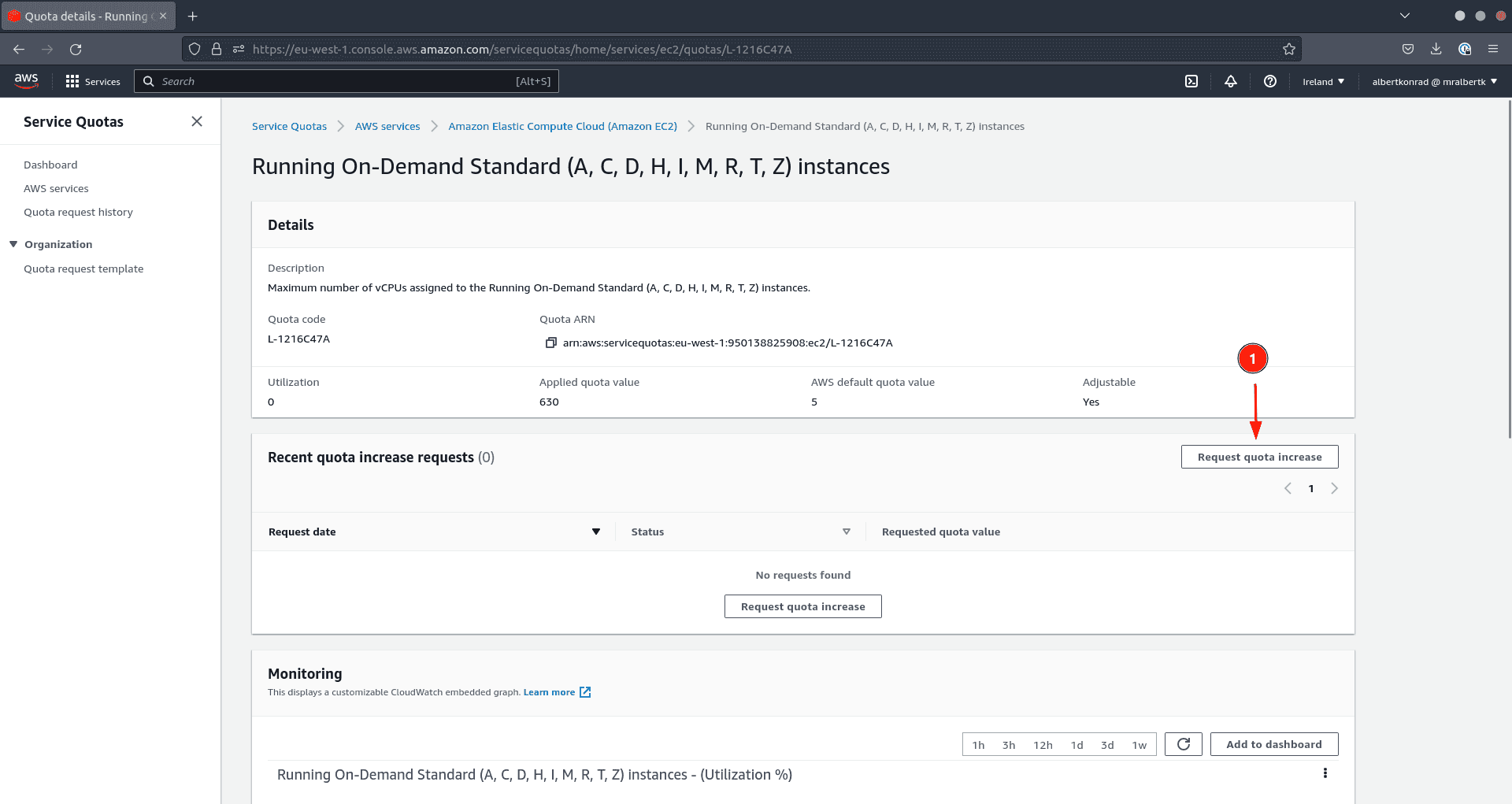
Les autres fournisseurs de clouds publics ont aussi des quotas pour la création de machines virtuelles. Si vous vous retrouvez à vouloir ajouter des services managés CDP à un environnement et que c’est un échec, il peut s’avérer utile de vérifier si les quotas en sont la cause.
Il faut garder à l’esprit que les quotas sont une barrière de sécurité financière. Utiliser plus de ressources aura pour conséquence une facture plus élevée. Soyez aussi conscient que le fait de suivre l’ensemble des étapes décrites dans cette série d’articles engendrera la création de ressources sur votre compte AWS et que ces ressources vous seront facturées. Quel que soit le cloud public sur lequel vous vous exercez, assurez-vous d’anticiper les coûts, et de supprimer immédiatement toute ressource devenue inutile.
Permissions du compte AWS
Vous avez besoin d’avoir accès à un compte AWS avec au moins les droits administrateurs pour effectuer les configurations nécessaires à un déploiement de CDP Public Cloud. Ce type de compte utilisateur peut uniquement être configuré par un utilisateur racine d’un compte AWS. Vous pouvez suivre la documentation officielle AWS pour gérer les permissions suivant les besoins.
Enregistrement du compte CDP
Vous aurez aussi besoin d’une licence Cloudera et d’un compte utilisateur ayant au moins les privilèges PowerUser. Si votre société possède déjà une licence Cloudera, contactez un administrateur pour obtenir le niveau de droit suffisant. Vous avez aussi la possibilité de vous inscrire sur le site de Cloudera pour une évaluation de CDP Public Cloud.
Interfaces AWS and CDP en ligne de commande (CLI)
Si vous n’êtes pas à l’aise avec les outils en ligne de commande (CLI), les articles illustreront aussi les tâches effectuées avec des captures d’écran des interfaces web fournies par Cloudera et AWS. Toutefois, vous avez le choix d’installer les outils en ligne de commande AWS et CDP sur votre machine. Ces outils vous permettront de déployer des environnements et d’activer des services de manière généralement plus rapide et plus reproductible.
Installer et configurer la CLI AWS
L’installation de la CLI AWS est expliquée dans la documentation AWS.
Si jamais vous utilisez NixOS ou le gestionnaire de package Nix, vous pouvez installer la CLI AWS via le site web des packages Nix.
Afin de configurer la CLI AWS, vous aurez besoin d’utiliser l’Access key et la Secret Access key de votre compte tel qu’expliqué dans la documentation AWS.
Lancer ensuite les commandes suivantes :
aws configureRenseignez votre Access key et votre Secret Access key, la région où vous souhaitez créer vos ressources et assurez-vous de sélectionner json comme Default output format. Vous êtes maintenant prêt à utiliser les commandes de la CLI AWS.
Installer et configurer la CLI CDP
La CLI CDP se base sur python 3.6 ou ultérieur et nécessite pip pour pouvoir s’installer sur votre machine. La documentation Cloudera vous guide durant tout le processus d’installation.
Si vous utilisez NixOS ou le gestionnaire de package Nix, il est recommandé d’installer d’abord le package virtualenv et ensuite suivre les étapes pour Linux.
Pour vérifier le bon fonctionnement de la CLI, lancer la ligne de commande suivante :
cdp --versionTout comme la CLI AWS, la CLI nécessite une Access key et une Secret Access key. Connectez-vous à la console CDP pour les récupérer. Notez que pour pouvoir effectuer les actions décrites plus bas, l’utilisateur doit avoir le rôle PowerUser ou IAMUser dans CDP :
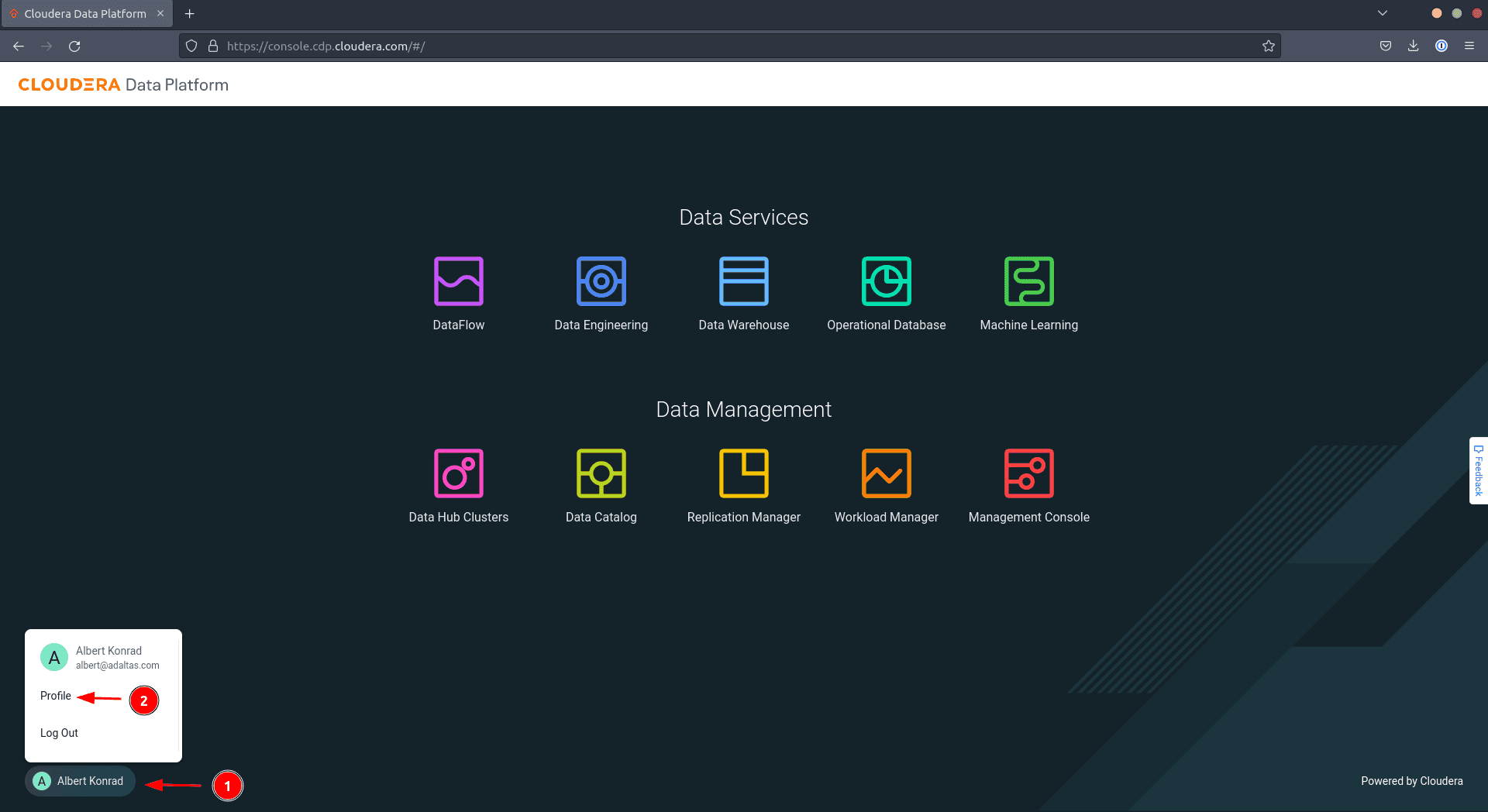
-
Cliquez sur votre nom d’utilisateur dans le coin en bas à gauche et sélectionnez Profile
-
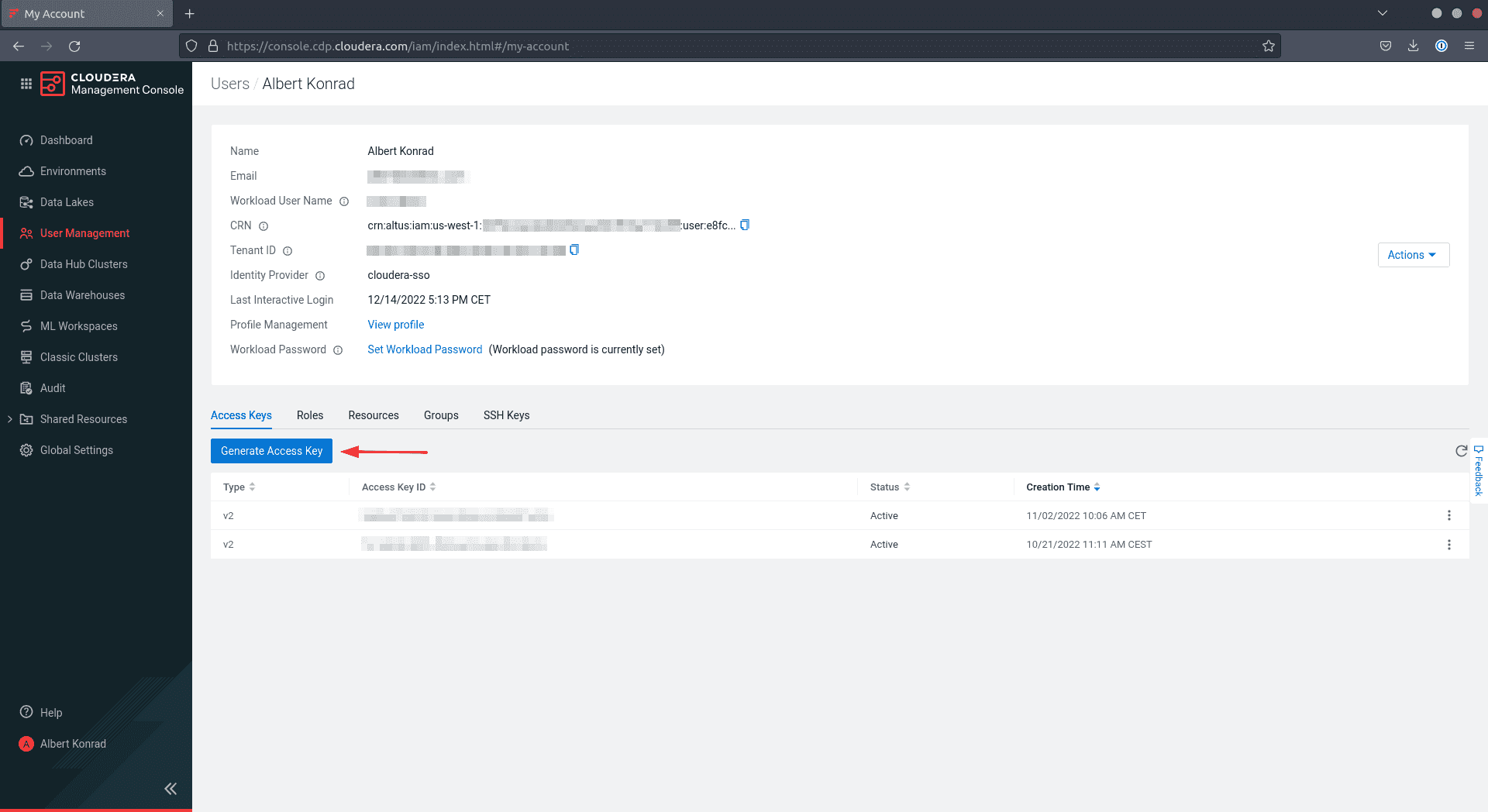
Sur l’onglet Access Keys, cliquez sur Generate Access Key
-
CDP crée la clé et affiche les informations à l’écran. Vous pouvez alors soit télécharger la clé et l’enregistrer dans le répertoire
~/.cdp/credentials, soit lancer la commandecdp configurequi créera le fichier pour vous.
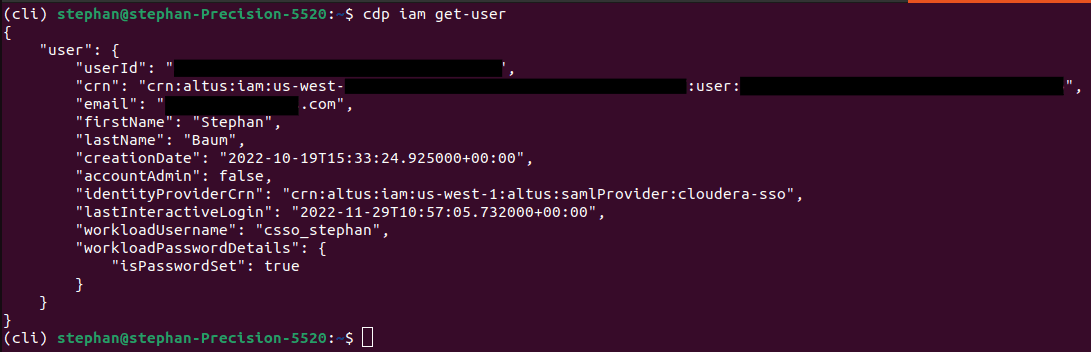
Pour valider l’installation, lancez la ligne de commande ci-dessous, qui devrait renvoyer une réponse similaire à celle affichée plus bas :
cdp iam get-user
Maintenant que tout est prêt, vous allez pouvoir poursuivre ! Dans le prochain article de cette série, nous allons déployer un environnement CDP Public Cloud sur AWS.
