

 Open Source")
MLflow tutorial : une plateforme de Machine Learning (ML) Open Source

23 mars 2020
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Introduction et principes de MLflow
Avec une puissance de calcul et un stockage de moins en moins chers et en même temps une collecte de données de plus en plus importante dans tous les domaines, de nombreuses entreprises ont intégré la science des données dans leur flux de travail. Au début, l’accent était mis sur l’amélioration de la puissance de prédiction des algorithmes pour améliorer les performances des entreprises. Mais maintenant que ce développement de modèle a mûri et a prouvé son utilité, nous sommes confrontés à de nouveaux défis. Comment partager les modèles en dehors des équipes de Data Science, sachant que les utilisateurs finaux ne sont généralement pas les mêmes que ceux qui les ont développés ? Comment assurer la reproductibilité des résultats, compte tenu des nombreux outils différents que les Data Scientists utilisent ? Et enfin et surtout, comment combler le fossé de compétences entre les data engineers, data scientists et les équipes opérationnelles, qui jouent tous des rôles très importants mais très différents dans le déploiement et la maintenance des modèles ?
MLflow est un outil qui permet de répondre à ces questions. Il permet aux Data Scientists de suivre facilement les progrès réalisés lors du développement et de la mise au point des modèles. Il s’occupe du packaging et du déploiement des modèles, quel que soit le cadre ou le langage de programmation utilisé pour les créer. En outre, MLflow fournit un registre, où les modèles que nous voulons conserver ou partager peuvent être stockés en toute sécurité et restent facilement accessibles. Une documentation abondante et de bonne qualité peut être trouvée sur le site officiel de MLflow (https://mlflow.org/docs/latest/index.html). Ce tutoriel a été conçu sur Arch Linux avec Python 3.7.6 et MLflow 1.6.0.
Tout d’abord, commençons par quelques définitions :
- Run est l’exécution individuelle du code d’un modèle. Chaque exécution va générer de nouveaux dossiers et fichiers, en fonction de ce que nous décidons d’enregistrer.
- Experiment est le nom donnée à un groupe de plusieurs exécutions.
MLflow est composé de quatre modules :
- MLflow Tracking - assure le suivi des exécutions en enregistrant les métriques, les paramètres, les balises et les artefacts. Il nous permet de les visualiser et de les comparer dans un navigateur de manière simple. De plus, il crée différents fichiers avec la description de l’environnement dans lequel l’exécution a été effectuée (MLmodel, conda.yaml, code modèle).
- MLflow Project - est un format permettant de packager du code de manière réutilisable et reproductible. Il utilise des artefacts enregistrés à l’étape du suivi.
- MLflow Model - est un format standard pour le packaging des modèles. Le format définit une convention qui permet de sauvegarder un modèle selon sa préférence (par exemple, fonction Python, fonction R, Scikit-learn, TensorFlow, Spark MLlib…) qui peuvent être interprété par différents outils complémentaires à MLflow.
- MLflow Registry - est un magasin de modèles centralisé. Il fournit la lignée du modèle (qui a produit le modèle), le versionnement du modèle, les transitions d’étape (par exemple du lab à la production) et les annotations.
Preparation de l’environnement de travail
Installer Miniconda avec Python 3.x.
$ cd Downloads
$ sh Miniconda3-latest-Linux-x86_64.sh
Miniconda3 will now be installed into this location:
/home/petra/miniconda3
- Press ENTER to confirm the location
...
Do you wish the installer to initialize Miniconda3 by running conda init? [yes|no]
[no] >>> yesIl est nécessaire d’ajouter le chemin pour Miniconda à la variable $PATH dans votre environnement. Allez dans ~/.profile et changez NMP global pour qu’il ressemble à ceci : export PATH=~/.nmp-global/bin:$PATH:~/miniconda3/bin.
Vérifiez si Miniconda a été ajouté au chemin et s’il est correctement détecté. Ensuite, mettez-le à jour.
$ echo $PATH
/home/petra/miniconda3/envs/env_mlflow/bin:/home/petra/miniconda3/bin:
/home/petra/miniconda3/condabin:/home/petra/.npm-global/bin:
/usr/local/bin:/usr/local/sbin:/usr/bin:/home/petra/miniconda3/bin:
/usr/lib/jvm/default/bin:/usr/bin/site_perl:/usr/bin/vendor_perl:
/usr/bin/core_perl:/home/petra/miniconda3/bien
$ conda --version
conda 4.8.2
$ conda update condaCréer et activer un environnement virtuel nommé env_mlflow avec Python 3.7.
$ conda create --name env_mlflow python=3.7
$ conda activate env_mlflowInstallez tous les paquets nécessaires pour le tutoriel de cet environnement. Tous les paquets installés par pip résideront dans env_mlflow. Scikit-learn est un framework Python de Machine Learning et matplotlib est utilisé pour les graphs. Postgresql, postgresql-contrib, postgresql-server-dev-all, gcc et psycopg2 sont nécessaires pour mettre en place la base de données PostgreSQL et la faire communiquer avec l’environnement MLflow.
$ pip install mlflow
$ pip install sklearn
$ pip install matplotlib
$ sudo apt-get install postgresql postgresql-contrib postgresql-server-dev-all
$ sudo apt install gcc
$ pip install psycopg2Téléchargement du code d’exemple
De nombreux exemples sont disponibles pour illustrer les diverses fonctionnalités du framework MLflow. Nous allons télécharger un ensemble assez complet, que vous êtes invités à explorer par vous-même puisque nous n’en couvrirons qu’une fraction. Clonez le repository.
$ git clone https://github.com/mlflow/mlflowPuisque nous allons utiliser l’exemple de sklearn_elasticnet_diabetes, vous pouvez vous déplacer dans son répertoire.
$ cd ~/mlflow/examples/sklearn_elasticnet_diabetes/linuxSi nous inspectons le code dans le train_diabetes.py, nous voyons que MLflow est importé et utilisé comme toute autre bibliothèque Python. Ici, différentes fonctions de log sont utilisées (log_param, log_metric, log_artifact et sklearn.log_model) pour enregistrer les deux entrées du modèle, trois métriques différentes, le modèle lui-même et un tracé. Pour l’instant, MLflow ne propose pas de registre de données, où l’on pourrait enregistrer les données d’entraînement. Quoi qu’il en soit, il est important de conserver l’ensemble des données d’entraînement pour que les expériences soient reproductibles. Ainsi, nous le sauvegarderons comme un artefact en ajoutant les lignes de code suivantes à la fin du script.
data.to_csv('diabetes.txt', encoding = 'utf-8', index=False)
mlflow.log_artifact('diabetes.txt')Mise en place du serveur de suivi
Nous pouvons enregistrer les données de suivi sur le système de fichiers local ou sur un serveur, dans un répertoire ou dans une base de données compatible avec SQLAlchemy. Au moment de la rédaction de cet article, la seule façon de stocker des modèles afin qu’ils puissent être enregistrés ultérieurement dans un registre est d’utiliser une base de données en tant que backend store. Ci-dessous, nous allons explorer deux options : enregistrer les exécutions sur un disque local, et/ou les sauvegarder sur un serveur local avec une base de données PostgreSQL comme backend store. Par conséquent, seul ce dernier exemple peut être utilisé pour enregistrer les modèles dans le registre.
Sauvegarder les exécutions sur un disque local
Si nous utilisons MLflow pour nos besoins personnels et que nous ne prévoyons pas de partager les modèles avec d’autres utilisateurs, nous pouvons opter pour le stockage local des exécutions. Cette option est très facile à mettre en œuvre. Elle permet de sauvegarder tous les fichiers générés au même endroit, ce qui simplifie également le suivi. Si vous lancez le fichier train_diabetes.py tel quel, les runs seront sauvegardés dans un répertoire de travail dans un sous-répertoire ./mlruns nouvellement créé. Exécutons le script avec trois jeux d’arguments différents.
$ python train_diabetes.py 0.1 0.9
$ python train_diabetes.py 0.5 0.5
$ python train_diabetes.py 0.9 0.1Pour inspecter les données enregistrées de manière esthétique, restez dans le même répertoire et lancez mlflow ui.
$ mlflow ui
[2020-03-04 15:14:57 +0100] [15651] [INFO] Starting gunicorn 20.0.4
[2020-03-04 15:14:57 +0100] [15651] [INFO] Listening at: http://127.0.0.1:5000 (15651)Copiez l’URL affichée dans votre navigateur web et regardez les résultats. Vous verrez un tableau avec de nombreux détails sur l’exécution, y compris les paramètres passés à l’exécution et les métriques enregistrées. Comme nous n’avons pas donné de nom à l’expérience, les essais sont enregistrés sous l’onglet “Default”.
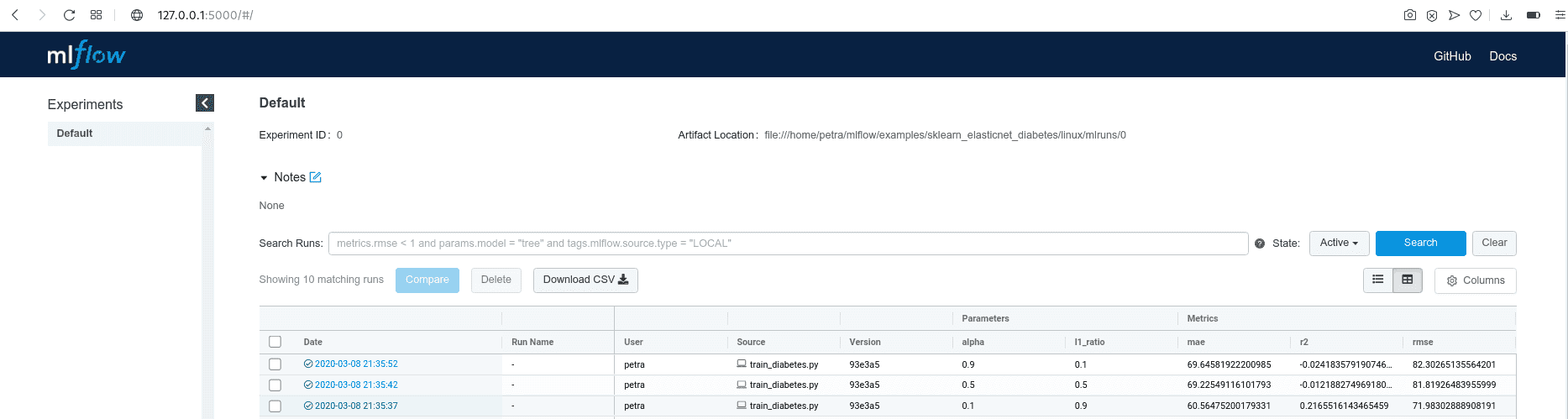
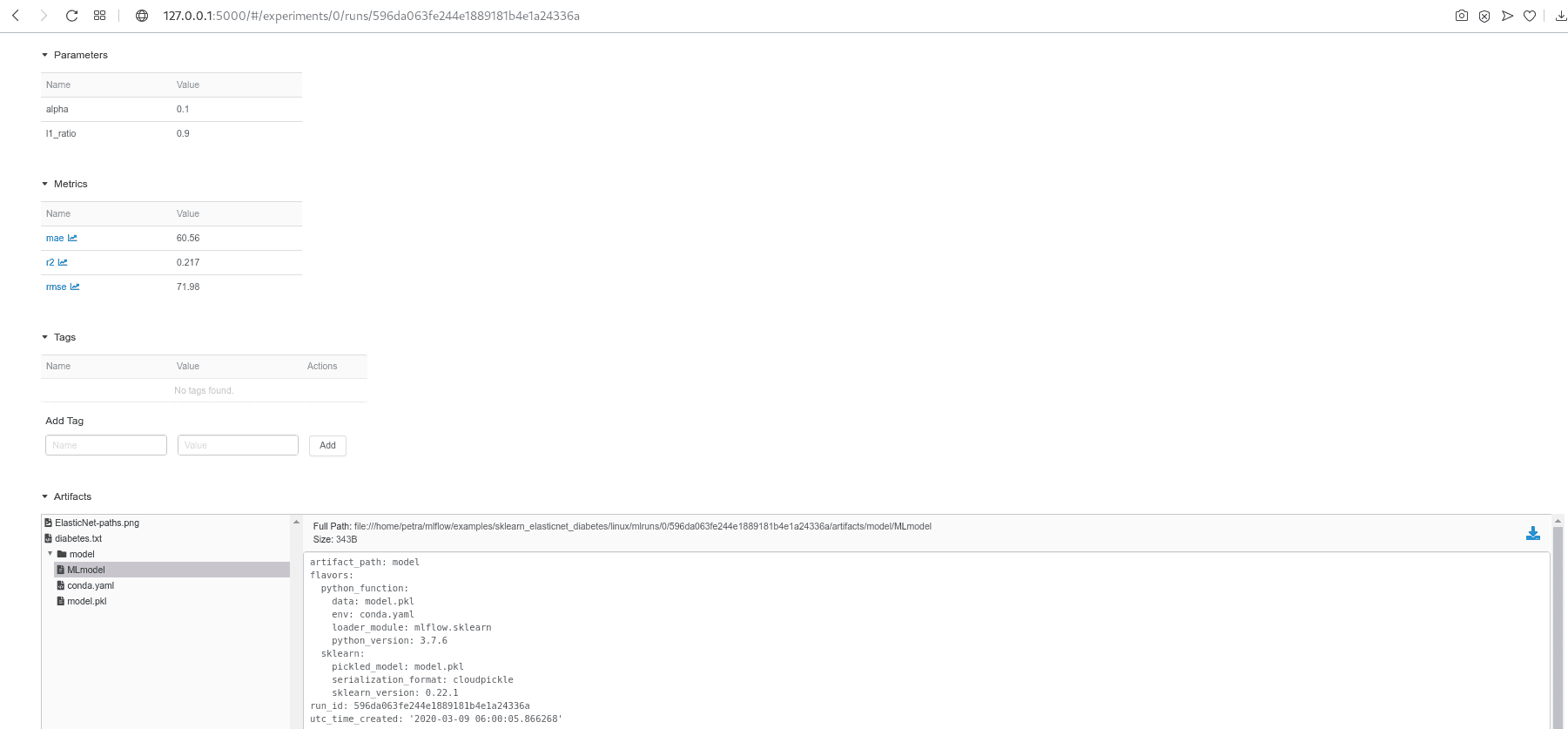
En cliquant sur la date d’une exécution, vous pouvez en voir tous les détails, examiner les artefacts et visualiser le comportement de vos métriques.
Si vous préférez enregistrer les exécutions à un endroit désigné, vous pouvez le spécifier au début du programme comme suit :
import mlflow
import mlflow.sklearn
mlflow.set_tracking_uri('file:/home/petra/mlrun_store')NOTE : Le dossier spécifié doit être créé pendant l’exécution lorsqu’il est référencé pour la première fois. S’il est créé à l’avance, le script se termine par le message d’erreur suivant : mlflow.exceptions.MlflowException: Could not find experiment with ID 0.
Pour afficher les données enregistrées dans le navigateur dans ce cas, vous devez transmettre l’adresse de votre emplacement de stockage à mlflow ui.
$ mlflow ui --backend-store-uri file:/home/petra/mlrun_store \
--default-artifact-root file:/home/petra/mlrun_store \
--host 0.0.0.0 \
--port 5000Même si la commande renvoie WARNING:root:Malformed experiment 'mlruns'. Detailed error Yaml file '/home/petra/mlrun_store/mlruns/meta.yaml' does not exist., elle fonctionne correctement et continue à enregistrer et à afficher les nouvelles exécutions.
Après le tutoriel, vous voudrez probablement arrêter les modules MLflow et libérer les ports. Tout d’abord, vous pouvez lister les ports utilisés avec ss -tuna. Ensuite, par exemple, pour tuer un processus sur un port 5000, exécutez une commande kill $(lsof -t -i :5000).
Enregistrement des exécutions sur un serveur local
Puisque nous avons décidé d’utiliser la base de données PostgreSQL comme backend store, nous devons la mettre en place.
$ sudo -U postgres -i
# Créer un nouvel utilisateur: mlflow_user
[postgres@archlinux ~]$ createuser --interactive -P
Enter name of role to add: mlflow_user
Enter password for new role: mlflow
Enter it again: mlflow
Shall the new role be a superuser? (y/n) n
Shall the new role be allowed to create databases? (y/n) n
Shall the new role be allowed to create more new roles? (y/n) n
# Créer la base de donnée mlflow_bd qui appartient à mlflow_user
$ createdb -O mlflow_user mlflow_dbDossier local pour les artefacts créés lors des runs :
$ mkdir ~/artifact_rootLa différence avec le stockage local, où tout est stocké dans un seul répertoire, est que dans ce cas, nous avons deux emplacements de stockage : --backend-store-uri pour tout sauf les artefacts et --default-artefact-root pour les artefacts uniquement. La base de données doit être encodée comme suit : dialect+driver://username:password@host:port/database.
Lancez le serveur de suivi comme serveur local :
$ mlflow server --backend-store-uri postgresql://mlflow_user@localhost/mlflow_db \
--default-artifact-root file:/home/petra/artifact_root \
--host 0.0.0.0 \
--port 5000
[2020-03-04 16:52:18 +0100] [22268] [INFO] Starting gunicorn 20.0.4
[2020-03-04 16:52:18 +0100] [22268] [INFO] Listening at: http://0.0.0.0:5000 (22268)Définissez l’URI de suivi au début de votre programme, avec le même host:port que vous avez utilisé pour configurer le serveur mlflow :
import mlflow
import mlflow.sklearn
mlflow.set_tracking_uri('http://0.0.0.0:5000')Effectuez quelques exécutions comme précédemment et consultez-les dans votre navigateur. Nous pouvons également examiner mlflow_db. Connectez-vous à la base de données et répertoriez toutes les tables.
$ psql -d mlflow_db -U mlflow_user
mlflow_db=> \d+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+-------------------------------+----------+-------------+------------+-------------
public | alembic_version | table | mlflow_user | 8192 bytes |
public | experiment_tags | table | mlflow_user | 8192 bytes |
public | experiments | table | mlflow_user | 16 kB |
public | experiments_experiment_id_seq | sequence | mlflow_user | 8192 bytes |
public | latest_metrics | table | mlflow_user | 8192 bytes |
public | metrics | table | mlflow_user | 8192 bytes |
public | model_versions | table | mlflow_user | 16 kB |
public | params | table | mlflow_user | 16 kB |
public | registered_models | table | mlflow_user | 16 kB |
public | runs | table | mlflow_user | 16 kB |
public | tags | table | mlflow_user | 16 kB |
(11 rows)Sélectionnez un tableau et affichez son contenu. Pour quitter la vue, tapez :q.
mlflow_db=> select * from metrics;
key | value | timestamp | run_uuid | step | is_nan
------+------------------------+---------------+----------------------------------+------+--------
rmse | 78.59248628523486 | 1583337265410 | a365d280a43f4af89378fc608f2bba0f | 0 | f
r2 | 0.06607454600721252 | 1583337265421 | a365d280a43f4af89378fc608f2bba0f | 0 | f
mae | 66.30996047256438 | 1583337265430 | a365d280a43f4af89378fc608f2bba0f | 0 | f
rmse | 71.98302888908191 | 1583401098173 | a2491ceec4c64084a0ae8a07ff8e299a | 0 | f
r2 | 0.2165516143465459 | 1583401098267 | a2491ceec4c64084a0ae8a07ff8e299a | 0 | f
mae | 60.56475200179331 | 1583401098338 | a2491ceec4c64084a0ae8a07ff8e299a | 0 | fmlflow_db=> exitSi vous utilisez le serveur de suivi comme nous venons de le faire, vous devrez le redémarrer après chaque redémarrage de votre ordinateur, car le mlflow server sera arrêté. Comme alternative, nous allons créer un service résilient, qui redémarrera automatiquement après chaque déconnexion ou redémarrage du système. Il fonctionnera comme un service en arrière-plan.
Tout d’abord, nous devons créer un dossier pour la sortie standard et les journaux d’erreurs standard, sinon, vous rencontrerez ce message 209/STDOUT error.
$ mkdir ~/mlrunsCréez un fichier portant le nom mlflow-tracking.service et copiez le contenu ci-dessous. Adaptez les chemins d’accès en conséquence.
$ sudo vim /etc/systemd/system/mlflow-tracking.service[Unit]
Description=Serveur de tracking MLfow
After=network.target
[Service]
Restart=on-failure
RestartSec=30
StandardOutput=file:/home/petra/mlruns/stdout.log
StandardError=file:/home/petra/mlruns/stderr.log
ExecStart=/bin/bash -c 'PATH=/home/petra/miniconda3/envs/env_mlflow/bin/:$PATH exec mlflow server --backend-store-uri postgresql://mlflow_user@localhost/mlflow_db --default-artifact-root file:/home/petra/artifact_root --host 0.0.0.0 --port 5000'
[Install]
WantedBy=multi-user.targetCe service doit être activé et démarré.
# Recharge les fichiers unitaires
$ sudo systemctl daemon-reload
$ sudo systemctl enable mlflow-tracking
$ sudo systemctl start mlflow-tracking
# Vérification de fonctionnement
$ sudo systemctl status mlflow-trackingVous devriez voir le service actif et en fonctionnement. Lorsque vous voulez l’arrêter, utilisez sudo systemctl stop mlflow-tracking.
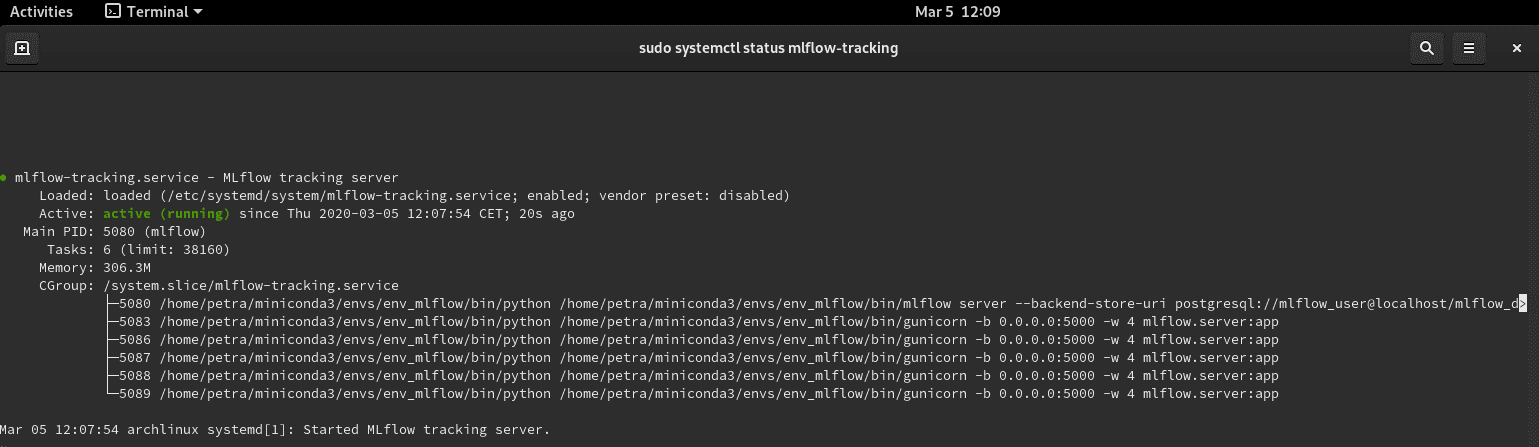
Redémarrez le terminal pour relire les fichiers .service. Réactivez l’environnement virtuel env_mlflow. Relancez python train_diabetes.py. Pour voir les données enregistrées, allez sur http://localhost:5000 et actualisez la page si nécessaire.
Après avoir testé plusieurs combinaisons de paramètres d’entrée du modèle, nous pouvons sélectionner le plus performant (par exemple le plus grand r2) dans l’interface utilisateur. À ce stade, nous devons décider de la destinée du modèle. Si nous voulons le mettre à la disposition d’autres utilisateurs, nous pouvons le packager et le déployer. Si nous voulons simplement le sauvegarder pour un usage ultérieur, nous pouvons le mettre dans le repository. Les deux cas sont décrits ci-dessous.
Packaging d’un modèle
Le module MLflow Models s’occupe du packaging de notre modèle. Si nous regardons dans le répertoire artefact-root, nous voyons que pour chaque exécution existe un sous-répertoire /model, avec les fichiers conda.yaml, MLmodel et model.pkl. MLmodel contient des informations sur la référence de son environnement de création (conda.yaml), sa représentation persistante (model.pkl) et des détails supplémentaires sur l’exécution. Grâce à ces informations, nous pouvons reproduire notre modèle ailleurs.
Les options actuellement supportées sont les suivantes : Fonction Python, Fonction R, H2O, Keras, MLeap, PyTorch, Scikit-learn, Spark MLlib, TensorFlow, ONNX, MXNet Gluon, XGBoost et LightGBM.
Déploiement d’un modèle
MLflow offre plusieurs options pour déployer un modèle. Nous pouvons le déployer localement, sur Amazon SageMaker, Microsoft Azure ML ou nous pouvons l’exporter sous forme de fonction définie par l’utilisateur dans Apache Spark pour l’exécuter sur un cluster Spark. Toutes les méthodes de déploiement ne sont pas disponibles pour toutes les saveurs de modèles. Lorsque nous avons décidé quel modèle nous voulons déployer, nous devons trouver l’emplacement des artefacts. Nous l’obtenons en cliquant sur Artifacts/model dans l’interface utilisateur et en copiant le Full Path à côté du bouton Register Model ou Download(voir l’image ci-dessus). Comme pour le serveur de suivi, nous pouvons servir un modèle temporairement ou comme un service résilient.
$ mlflow models serve \
-m file:/home/petra/artifact_root/0/6a01bc26500c48b589bb993153fb92a3/artifacts/model \
-h 0.0.0.0 \
-p 8003Vous pouvez interroger le modèle avec de nouvelles observations et obtenir des prédictions.
$ curl --request POST http://0.0.0.0:8003/invocations \
--header "Content-Type:application/json; format=pandas-split" \
--data '{
"columns":["age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"],
"data":[[0.01628, -0.04464, 0.00133, 0.00810, 0.00531, 0.01089, 0.03023, -0.03949, -0.04542, 0.03205]]
}'Comme auparavant, nous aimerions avoir un service résilient. C’est pourquoi nous devons créer un nouveau fichier .service, cette fois-ci avec des informations sur le modèle.
$ sudo vim /etc/systemd/system/mlflow-production.serviceLe contenu doit être le suivant :
[Unit]
Description=Modèle MLFlow en production
After=network.target
[Service]
Restart=on-failure
RestartSec=30
StandardOutput=file:/home/petra/mlruns/stdout.log
StandardError=file:/home/petra/mlruns/stderr.log
Environment=MLFLOW_TRACKING_URI=http://0.0.0.0:8001
Environment=MLFLOW_CONDA_HOME=/home/petra/miniconda3
ExecStart=/bin/bash -c 'PATH=/home/petra/miniconda3/envs/env_mlflow/bin/:$PATH exec mlflow models serve -m file:/home/petra/artifact_root/0/6a01bc26500c48b589bb993153fb92a3/artifacts/model -h 0.0.0.0 -p 8001'
[Install]
WantedBy=multi-user.target$ sudo systemctl daemon-reload
$ sudo systemctl enable mlflow-production
$ sudo systemctl start mlflow-production
$ sudo systemctl status mlflow-productionRedémarrez le terminal et interrogez le modèle.
$ curl --request POST http://0.0.0.0:8001/invocations \
--header "Content-Type:application/json; format=pandas-split" \
--data '{
"columns":["age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"],
"data":[[0.01628, -0.04464, 0.00133, 0.00810, 0.00531, 0.01089, 0.03023, -0.03949, -0.04542, 0.03205]]
}'Comme vous pouvez le remarquer, le env_mlflow n’a plus besoin d’être activé, puisque le modèle déployé crée son propre environnement. Une autre chose qui mérite d’être mentionnée est que maintenant, l’API est le seul moyen d’interagir avec le modèle. Même si les URI de suivi sont toujours sous la forme d’adresses HTTP, nous n’y avons plus accès dans le navigateur.
Enregistrement d’un modèle dans le registre
Peut-être que le but d’un projet de data science n’est pas de produire un modèle. Cependant, nous aimerions conserver la meilleure version actuelle dans un endroit sûr, où nous pourrions facilement la récupérer le moment venu. Dans ce cas, la sauvegarde dans le registre MLflow est l’option la plus simple. Elle est extrêmement rapide puisqu’elle ne nécessite qu’un clic. Une fois enregistré, d’autres personnes peuvent y accéder, c’est donc un moyen confortable de partager le code pour des collaborations ou des retours d’expériences. De plus, un modèle peut être expérimenté dans un lab ou mis en production directement à partir du registre.
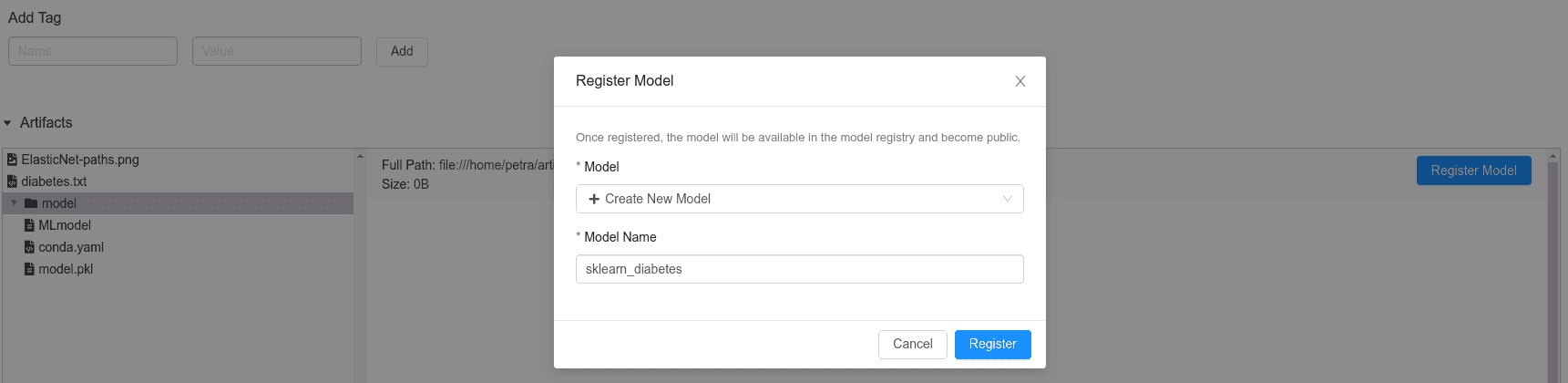
Vous pouvez trouver le registre sur http://0.0.0.0:5000/#/models/ ou directement dans le mlflow_db dans la table registered_models.

mlflow_db=> select * from registered_models;
name | creation_time | last_updated_time | description
---------------------------+---------------+-------------------+-------------
sklearn_diabetes | 1583408657063 | 1583419663533 |
(1 row)NOTE : Cette option ne fonctionnera que si vous utilisez une base de données comme stockage. Au moment de la rédaction de ce document, le magasin de fichiers n’était pas supporté et il lançait un INTERNAL_SERVER_ERROR.
Conclusion
Dans cet article, nous avons fait les premiers pas vers un Data Science reproductibles et le déploiement de modèles avec MLflow. Nous avons examiné les différentes façons d’utiliser sa version open source. Nous voyons comment nous pouvons suivre les expériences dans un répertoire local et une base de données PostgreSQL, nous avons utilisé l’interface utilisateur dans un navigateur pour une vue d’ensemble plus facile et nous avons enregistré le modèle le plus prometteur dans un registre. Dans la deuxième partie, nous explorerons l’édition communautaire de Databricks et la version gérée de MLflow et, dans la troisième partie, Databricks hébergée par Azure, avec un projet plus complet de Data Science.
Références
https://www.mlflow.org/docs/latest/tutorials-and-examples/index.html
https://www.youtube.com/watch?v=6z0_n8kxh-g
https://thegurus.tech/posts/2019/06/mlflow-production-setup/
http://postgresguide.com/utilities/psql.html
