


Optimisation d'applicationS Spark dans Hadoop YARN

30 mars 2020
- Catégories
- Data Engineering
- Formation
- Tags
- Performance
- Hadoop
- Spark
- Python [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Apache Spark est un outil de traitement de données in-memory très répandu en entreprise pour traiter des problématiques Big Data. L’exécution d’une application Spark en production nécessite des ressources définies par l’utilisateur. Cet article présente plusieurs concepts de Spark en vue d’optimiser l’utilisation du moteur, à la fois dans l’écriture du code ainsi que dans le choix des paramètres d’éxécution. Ces concepts seront illustrés au travers d’un cas d’usage avec un focus porté sur les bonnes pratiques en terme d’allocations des ressources d’une application Spark dans un environnement Hadoop YARN.
Cluster Spark : terminologies et modes
Déployer une application Spark dans un cluster nécessite de comprendre le modèle “maître-esclave” ainsi que le fonctionnement de plusieurs composants : le Cluster Manager, le Driver Spark, les Exécuteurs Spark et le concept d’Edge Node.
Le modèle “maître-esclave” défini deux type d’entités : le maître contrôle et centralise les communications des esclaves. C’est un modèle qu’on applique souvent dans la mise en place de clusters et/ou pour du traitement parallélisés. C’est également le modèle utilisé par les applications Spark.
Le Cluster Manager maintient les machines physiques sur lesquelles vont s’exécuter le Driver et leurs Exécuteurs et attribue aux utilisateurs les ressources demandées. Spark supporte 4 Cluster Managers : Apache YARN, Mesos, Standalone et, depuis peu, Kubernetes. Nous nous focaliserons sur YARN.
Le Driver Spark est l’entité qui gère l’exécution de l’application Spark (le maître), à chaque application est associé un Driver. Son rôle consiste à interprèter le code de l’application pour le transformer en une suite de tâches et à maintenir tous les états et tâches des Exécuteurs.
Les Exécuteurs Spark sont les entitées responsables d’effectuer les tâches qui leurs ont été assigné par le Driver (les esclaves). Elles vont prendre connaissance de ces tâches, les exécuter et retourner leurs états (Réussite/Echec) et leurs résultats. Les Exécuteurs sont liés à une seule application à la fois.
Le Edge Node est une machine physique/virtuelle où les utilisateurs vont se connecter pour instancier leurs applications Spark. Il sert d’interface entre le cluster et le monde extérieur. C’est une zone de confort dans laquelle les composants sont préinstallés et surtout préconfigurés.
Modes d’exécutions
Il existe différents modes de déploiement d’une application Spark :
-
Le mode Cluster : C’est le plus commun, l’utilisateur envoie un fichier JAR ou un script Python au Cluster Manager. Ce dernier va instancier un Driver et des Exécuteurs sur les différents noeuds du cluster. Le CM est responsable de tous les processus liés à l’application Spark. Nous l’utiliserons pour traiter notre exemple : il facilite l’allocation des ressources et les libèrent dès que l’application est terminée.
-
Le mode Client : Quasiment identique au mode cluster à la différence que le Driver est instancié sur la machine où le job est soumis, soit à l’extérieur du cluster. Il est souvent utilisé pour le développement d’un programme car les logs sont directement affichés dans le terminal courant et l’instance du driver est liée à la session de l’utilisateur. Ce mode n’est pas recommandé en production car le Edge Node peut rapidement arriver à saturation en terme de ressources et l’Edge Node est un SPOF (Single Point Of Failure).
-
Le mode Local : le Driver et les Exécuteurs s’exécutent sur la machine sur laquelle l’utilisateur est connecté. Il est seulement recommandé dans le but de tester une application dans un environnement local ou pour l’exécution de tests unitaires.
On provisionne le nombre d’Exécuteurs et leurs ressources respectives directement dans la commande spark-submit, ou bien via des propriétés de configuration injectées à la création de l’objet SparkSession. Une fois les Exécuteurs créés, ils communiqueront avec le Driver qui distribuera les tâches de traitement.
Ressources
Une application Spark fonctionne de la manière suivante : les données sont stockées en mémoire et les CPUs sont chargés de réaliser les tâches d’une application. Celle-ci est donc contrainte par les ressources utilisées dont la mémoire et les CPUs, qui sont définies pour le Driver et les Exécuteurs.
On peut généralement distinguer les applications Spark selon 2 types :
-
Memory-intensive : Les applications impliquant des jointures massives ou alors le traitement de HashMap. Ces opérations sont coûteuses en terme de mémoire.
-
CPU-intensive : Toutes applications impliquant des opérations de triage ou de recherche de données particulières. Ces types de jobs deviennent intensifs en fonction de la fréquence de ces opérations.
Quelques applications sont à la fois intensive en mémoire et CPUs : certains modèles de Machine Learning demandent par exemple un grand nombre de boucles d’opérations gourmandes en calcul et stockent les résultats intérmédiaires en mémoire.
Le fonctionnement de la mémoire des Exécuteurs a 2 grandes parties concernant le stockage et l’éxécution. Grâce au mécanisme Unified Memory Manager, la mémoire-stockage et la mémoire-exécution partagent un même espace, cela permet ainsi à l’une d’occuper les ressources non utilisées de l’autre.
-
La première concerne le stockage des données dans le cache lorsqu’on utilise par exemple
.cache()oubroadcast(). -
L’autre partie (exécution) est utilisée pour stocker les résultats temporaires des procédés de shuffle, join, d’aggrégation, etc.
L’allocation de la mémoire aux Exécuteurs est étroitement liée à l’allocation des CPUs : un coeur réalise une tâche sur une partition donc si un Exécuteur a 4 coeurs, celui-ci devra avoir la capacité de stocker ces 4 partitions ainsi que les résultats intermédiaires, les métadonnées… Ainsi, l’utilisateur doit fixer les quantités de mémoire et de coeurs allouées à chaque Exécuteurs au regard de l’application qu’il souhaite traiter et du fichier source : un fichier est partitionné par défault en fonction du nombre total de coeurs du cluster.
Ce lien énonce différentes bonnes pratiques d’utilisation et de configuration de cluster. Le schéma qui suit, tiré du lien précédent, donne une vue d’ensemble du fonctionnement de la mémoire d’un Exécuteur. Une remarque importante est que la mémoire attribuée à un Exécuteur sera toujours plus élevée que la valeur spécifiée en raison du memoryOverhead qui représente par défaut 10% de la dite valeur.
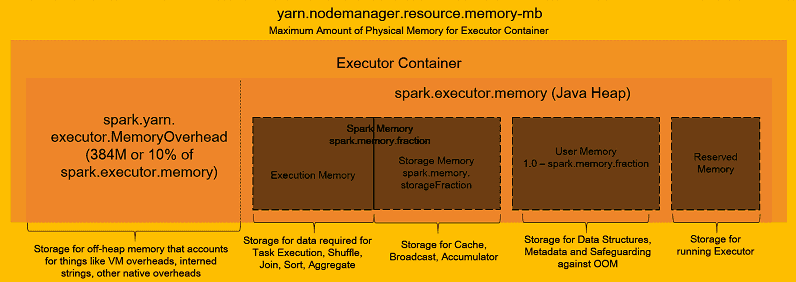
Fonctionnement d’une application Spark
Dans un cluster multi-utilisateurs, les ressources disponibles à chaque utilisateurs ne sont pas illimitées. Elles sont contraintes à un quantité donnée de mémoire, de CPU et d’espace de stockage, afin d’éviter la monopolisation des resources par un nombre restreint d’utilisateurs. Ces règles d’allocation sont définies et gérées par l’administrateur du cluster en charge de son exploitation.
Dans le cas d’Apache YARN, on peut répartir ces ressources par file. Ainsi, un utilisateur peut n’avoir la permission de soumettre ses applications que dans une seule file YARN dans laquelle la quantité de ressources disponibles est contrainte par une taille maximale de mémoire et de CPUs.
Les composants et leurs ressources utilisées par une application Spark sont paramétrables via :
-
la commande
spark-submità l’aide des arguments--executor-memory,--executor-cores,--num-executors,--driver-coreset--driver-memory. -
l’objet
SparkSessionen configurant par exemple.config("spark.executor.instances", "7")(voir les scripts dans le projet GitHub). -
les options du fichier de configuration
spark-defaults.conf.
L’utilisateur peut également laisser Spark décider du nombre d’Exécuteurs nécessaires en fonction des traitements à faire via les paramètres suivants :
spark = SparkSession.builder \
.appName("<XxXxX>") \
.config("spark.dynamicAllocation.enabled", "true") \
.config("spark.executor.cores", "2") \
.config("spark.dynamicAllocation.minExecutors","1") \
.config("spark.dynamicAllocation.maxExecutors","5") \
.getOrCreate()Ainsi, l’application ne monopolise pas plus de ressources que nécessaire dans un environnement multi-utilisateur. Plus de détails sont décrits dans cet article expliquant comment Facebook ajuste Apache Spark pour ses workloads à grande échelle (en anglais).
Concernant le système de fichier sous-jacent où les données sont stockées, deux règles d’optimisations sont importantes :
-
La taille de partition devrait être au minimum 128MB et, si possible, en fonction d’un attribut clé.
-
Le nombre de CPUs/Executor devrait être compris en 4 et 6.
Dans l’application Spark présentée plus bas, nous utiliserons le jeu de données des taxis verts New-Yorkais de 2018. Le script suivant permet de télécharger le fichier et de l’enregister dans HDFS :
# Télécharger le jeu de donnée
curl https://data.cityofnewyork.us/api/views/w7fs-fd9i/rows.csv?accessType=DOWNLOAD \
-o ~/trip_taxi_green2018.csv
# Créer un fichier HDFS
hdfs dfs -mkdir ~/nyctrip
# Charger le jeu de donnée dans HDFS
hdfs dfs -put \
~/trip_taxi_green2018.csv \
~/nyctrip/trip_taxi_green2018.csv \
-D dfs.block.size=128M
# Supprimer le jeu de donnée original
rm ~/trip_taxi_green2018.csvNotre fichier de 793MB divisé en bloc de 128MB nous donne 793/128 = 6,19 soit 7 partitions.
Si on demande 7 Exécuteurs, ils auront respectivement en mémoire ~113MB. Avec 4 Exécuteurs ayant 2 CPUs, ils auront cette fois ~200MB de données. Il faut réfléchir sur l’allocation de la mémoire selon l’application traitée : si le jeu de données est plusieurs fois transformé, un bon point de départ est d’allouer deux fois plus de GB de RAM que de coeurs par Exécuteurs.
Développement et traitement d’une application Spark
Nous aborderons plusieurs aspects d’optimisation au travers de l’écriture en Python d’une simple application Spark. Celle-ci sera déployée dans Spark via YARN en utilisant le mode de déploiement cluster. Comme énoncé plus haut, nous utiliserons les données des taxis verts New-Yorkais de 2018. La problématique sera de déterminer laquelle des 2 sociétés de taxis référencées dans le jeu de données fût la plus performante de l’année 2018 en terme de courses traitées.
Dans cette partie, nous détaillons chaque partie du code. Les scripts complets sont disponibles sur GitHub.
Importations et déclaration d’une SparkSession
Par souci de clarté, les importations des classes et fonctions Spark sont généralement déclarées en premier. Dans une application Spark, nous avons expliqué que l’utilisateur doit déclarer une SparkSession suivie de la classe builder afin de nommer et de configurer les options de traitement de l’application via appName() et config("key", "value"). L’argument .getOrCreate() vérifie s’il existe déjà une SparkSession ou en créer une nouvelle. Si une SparkSession existe déjà et qu’une nouvelle est créée, les options de la nouvelle seront également ajoutées à la précédente.
from pyspark.sql import SparkSession
from pyspark.sql.functions import desc, broadcast
spark = SparkSession.builder \
.appName("Best Driver 2018") \
.config("spark.sql.shuffle.partitions", "7") \
.config("spark.executor.memory", "2g") \
.config("spark.executor.instances", "4") \
.config("spark.executor.cores", "2") \
.getOrCreate()Importation du jeu de données
Lorsqu’une application Spark est traitée en Batch processing, l’utilisateur a le choix entre déclarer le schéma du jeu de données ou laisser Spark inférer ce schéma. Ce n’est pas le cas des applications streaming où l’utilisateur doit obligatoirement déclarer le schéma. La déclaration du schéma des données peut se faire via un format DDL (qui est utilisé ici) ou via l’utilisation des types StructType et StructField.
schema = "VendorID INT,pickup_datetime TIMESTAMP,dropoff_datetime TIMESTAMP,store_and_fwd_flag STRING,RatecodeID INT,PULocationID INT,DOLocationID INT,passenger_count INT,trip_distance FLOAT,fare_amount FLOAT,extra FLOAT,mta_tax FLOAT,tip_amount FLOAT,tolls_amount FLOAT,ehail_fee FLOAT,improvement_surcharge FLOAT,total_amount FLOAT,payment_type INT,trip_type INT,congestion_surcharge FLOAT"
driver_df = spark.read \
.csv(path="/home/ferdinand.de-baecque-dsti/nyctrip/trip_taxi.csv", schema=schema,header=True) \
# .csv(path="/home/ferdinand.de-baecque-dsti/nyctrip/trip_taxi.csv", inferSchema=True,header=True) \
.select("VendorID") \
.repartition(7, "VendorID")On utilise ici la fonction .csv() qui fait partie de la classe DataFrameReader et permet de configurer plusieurs paramètres pour créer un DataFrame à partir du jeu de données. Spark partitionne les données en fonction du nombre total de coeurs du cluster. On finit par “repartitionner” le DataFrame en fonction de l’attribut VendorID à l’aide de la fonction .repartition(<#_partitions>, <"column_name">).
Lecture sans schéma : avec l’option inferSchema=True.

Lecture avec schéma : avec l’option schema=schema.

La lecture du jeu de données est plus rapide lorsque l’utilisateur déclare son schéma.
Enfin, si on enlève la partie .select("VendorID") à driver_df, on a :

Définition de la requête
La requête de notre problématique tient en une ligne grâce aux fonctions natives de Spark appelées higher-ordered functions. Elles sont optimisées par le moteur et sont à privilégier par rapport à des User-Defined Functions (UDF) écrites par un utilisateur. Utiliser une fonction higher-order permet à Spark de comprendre ce que l’utilisateur cherche à obtenir et optimiser le traitement de l’application. A contrario, Spark ne voit pas le contenu d’une UDF (opaque) et donc ne comprend pas le but recherché, il n’est pas en mesure d’optimiser son traitement. De nouvelles fonctions natives sont ajoutées au fur et à mesure des évolutions de Spark.
Les fonctions natives fonctionnent de la manière suivante : le moteur construit plusieurs plans “logiques” puis implémente et compare la façon dont ces plans sont traités pour sélectionner le plus performant - c’est ce plan, appelé Physical Plan, qui est imprimé avec la fonction .explain(). Ces aspects d’optimisations sont liés au projet Tungsten et au Catalyst Optimizer.
count_trip = driver_df.groupBy("VendorID").count().sort(desc("count"))
count_trip.explain()
count_trip.show()Dans notre requête, on commence par regrouper les sociétés entres elles avec groupBy(). Vient ensuite le comptage du nombre d’occurences avec count(). On finit par trier les résultats avec sort(desc()) pour que la société la plus performante apparaisse en tête. Cette dernière fonction fait partie de la famille des wide transformations créant un transit des données (shuffle) entres les Exécuteurs passant par le réseau, le graphique ci-dessous schématise bien ce concept. Par défaut, Spark crée 200 partitions lorsque ces wide transformations sont appelées, une bonne pratique est de redéfinir cette valeur en fonction du scénario.
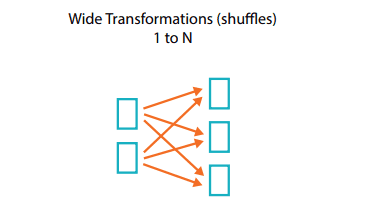
En déclarant la classe SparkSession, nous avons fixé .config("spark.sql.shuffle.partitions", "7"). Cette option est liée aux wide transformations, elle limite la création de partition suite à un shuffle : l’opération sort(desc()) crée 7 partitions au lieu de 200.
Sans cette option de configuration, on a :

Avec l’option, on a :

Changer la valeur de défaut de ce paramètre de configuration peut grandement optimiser ces types de transformation. Ici, on passe de 0,6 à 0,2 secondes en limitant à 7 le nombre de partition crée par les shuffles. La valeur a été fixé en fonction du nombre de coeurs dans le cluster.
Le plan physique donné par explain() est :

Enfin, .show() est une Action dans Spark qui retourne le résultat dans les logs ou dans la console selon la configuration de Spark. C’est cette fonction qui va déclencher l’exécution des transformations qui la précède dans l’application, c’est le principe de Lazy Evaluation.
Le résultat de notre requête est :

Traitement de la requête
Les captures précédentes ont été réalisées avec 7 Exécuteurs de 1 CPU et 2GB de RAM. La commande pour exécuter l’application dans Spark est :
spark-submit --master yarn --deploy-mode cluster \
--queue adaltas ./scripts_countTrip/query_7Exécuteurs.pyDans le SparkSession.builder, si on fixe à 4 Exécuteurs ayant chacun 2 CPUs et 4g de RAM tout en modifiant spark.shuffle.partitions avec 8, on obtient un gain de 1 seconde sur le scan de notre fichier :
spark-submit --master yarn --deploy-mode cluster \
--queue adaltas scripts/scripts_countTrip/query_4executors.py \
<Chemin_a_votre_HDFS_ou_fichier_local>

La documentation conseille d’avoir 2-3 fois plus de partitions que de coeurs disponibles dans le cluster, les données et donc les tâches seront mieux distribuées. Les coeurs ne traitent pas forcément une tâche à la même vitesse. Par exemple on peut repartitionner notre fichier en deux partitions en fonction de la colonne VendorID (car elle possède deux occurence) à l’aide de la fonction .repartition(2, "VendorID") ajoutée à la fin de driver_df. Avec 2 Exécuteurs ayant 1 CPU, l’un des CPU traitera son .count() beaucoup plus lentement que l’autre.
Les jointures dans Spark
Les opérations de jointures sont récurrentes dans les applications Spark, il faut les optimiser afin d’éviter des shuffles inutiles. Nous allons créer un petit jeu de données directement dans l’application et le but sera de joindre ce petit DataFrame avec notre grande base de données des taxis. Dans ce cas précis, la bonne pratique consiste à utiliser la fonction broadcast() permettant de dupliquer le contenu du petit DataFrame sur tous les Exécuteurs. Les shuffles ne seront pas nécessaires car chaque Exécuteurs aura sa propre partition du grand DataFrame et également l’intégralité du petit DataFrame.
Jointure 1 : jointure par défaut.
littleDf = spark.createDataFrame([(1, "The First Company"), (2, "The second company")], ("VendorID","VendorName"))
# Jointure 1
detailledDf = driver_df.join(littleDf, driver_df["VendorID"] == littleDf["VendorID"])
detailledDf.explain()
detailledDf.show()spark-submit --master yarn --deploy-mode cluster --queue adaltas \
scripts/scripts_join/default_join.py \
<Chemin_a_votre_HDFS_ou_fichier_local>- le Physical Plan est :

- Le temps d’exécution de l’application est :

Jointure 2 : Utilisation du BroadcastJoin.
detailledDfBroad = driver_df.join(broadcast(littleDf), driver_df["VendorID"] == littleDf["VendorID"])
detailledDfBroad.explain()
detailledDfBroad.show()spark-submit --master yarn --deploy-mode cluster --queue adaltas \
scripts/scripts_join/broadcast_join.py \
<Chemin_a_votre_HDFS_ou_fichier_local>- Le Physical Plan donne :

- Le temps d’exécution :

La technique du broadcast() nous fait passer de ~13 secondes à ~10 secondes au total. C’est efficace si l’intégralité du petit jeu de données peut être stocké dans le cache de chaque Exécuteurs.
Enfin, la mise en pratique de ce que préconise la documentation de Spark ainsi que la connaissance du nombre de blocs dans HDFS - à savoir, repartir les données sur 16 (8CPUx2) partitions et fixer à 16 les partitions de shuffle - diminue le TaskTime total de la jointure 2 de 0.1 secondes :
spark-submit --master yarn --deploy-mode cluster --queue adaltas scripts_join/final_countJoin.py

Monitoring
Toutes les captures d’écrans concernant l’application proviennent de l’interface web du RessourceManager de YARN. C’est là qu’on retrouve toutes les informations des applications Spark. Grâce au Spark History Server qui est activé dans le cluster, les métriques des applications Spark sont accessibles après leurs traitements.
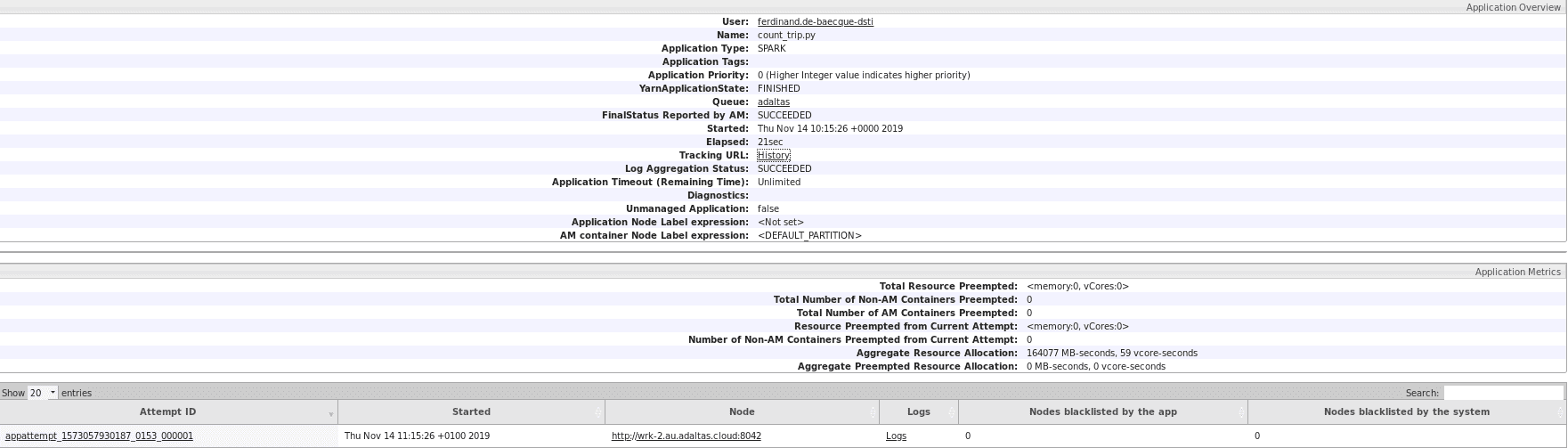
En cliquant sur l’ID de l’application : on peut soit regarder ses Logs - où apparaissent les résultats des requêtes dans mon cas - soit cliquer sur ApplicationMaster / History afin d’obtenir des détails sur ses tâches et les Exécuteurs.
Après avoir cliqué sur History et en allant dans l’onglet Stages, on peut voir le DAG (Direct Acyclic Graph) de chaque stages qui équivaut à une partie du contenu retourné par explain() sous forme graphique :
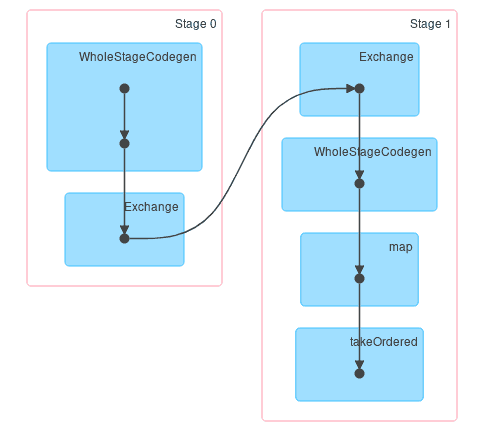
Un utilisateur Spark cherche à tendre vers l’uniformisation des Task Time de chaque Executor faisant foi de la bonne distribution des données, on retrouve cette information dans l’onglet Exécuteurs :

Si ce n’est pas le cas, c’est souvent qu’il y a un problème de distribution du jeu de données. Une solution est d’augmenter le nombre de partition grâce à la fonction .repartition() ou alors de partitionner le dataset avant de le consommer dans Spark. Si votre application prend plus de temps que vous ne le pensiez, vous pouvez suivre l’avancement des tâches de chaque Exécuteurs en allant dans l’onglet Exécuteurs puis en cliquant sur les différents Thread Dump.
Ici, réduire la RAM des Exécuteurs à 1GB au lieu de 2 n’est pas impactant : on ne fait pas de transformation sur l’ensemble des données. Ce choix est propre au scénario car chaque Executor possède 2 partitions d’un total de ~200MB. Cette mémoire en trop pourra être utilisée par une autre application.

Conclusion
Un certain nombre d’applications sont exécutées en concurence dans un environnement de production : la bonne allocation des ressources aux composants Spark tend à maximiser la performance d’une application ainsi que le nombre d’applications accueillies.
Nous avons présenté, à travers un cas d’usage, les relations entres coeurs & partitions, mémoire & transformations ainsi que le fonctionnement des fonctions natives. Notre application a été écrite en Python bien que ce langage ajoute une étape au traitement, appelée SerDe, que cet article explique très bien. C’est la raison principale faisant que les applications écrites en Scala sont plus performantes. Bien que ce ne soit pas notre cas ici, une comparaison est faite dans GitHub. Sur le plan de la consommation des données, Spark conseille d’utiliser le format Parquet : il conserve le schéma des données, celles-ci sont compressées et sauvegardées par colonnes (attributs) ce qui facilite leur extraction.
