


Snowflake, le Data Warehouse conçu pour le cloud, introduction et premiers pas

7 avr. 2020
- Catégories
- Business Intelligence
- Cloud computing
- Tags
- Cloud
- Data Lake
- Data Science
- Entrepôt de données (Data Warehouse)
- Snowflake [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Snowflake est une plateforme d’entrepôt de données en mode SaaS qui centralise, dans le cloud, le stockage et le traitement de données structurées et semi-structurées. La génération croissante de données produites dans le monde entier nécessite une infrastructure moderne pour traiter les données. Le stockage de données structurées et semi-structurées se heurte à un grand nombre de solutions possibles, et il n’est pas toujours facile d’en choisir une. Si vous décidez de faire appel à des fournisseurs de cloud public, allez-vous utiliser leurs solutions internes ou un logiciel tiers ? Quelles sont vos solutions pour éviter le vendor-locking ? Quels sont vos solutions de clonage et de réplication des données ? Le marché du travail offre-t-il des professionels ayant les compétences nécessaires pour construire votre infrastructure ?
Les utilisateurs de Snowflake approvisionnent et dimensionnent facilement des entrepôts virtuels pour effectuer des traitements sur des données structurées et semi-structurées. Parmi ses nombreuses caractéristiques, Snowflake est conforme à la norme ACID, permet le partage et le clonage de données en quelques secondes, la mise à l’échelle de son infrastructure de manière flexible et offre une large gamme de connecteurs avec plus de 70 partenaires tiers. En ce qui concerne le stockage, Snowflake provisionne automatiquement des objects storage sur la plateforme du fournisseur de cloud computing sélectionné lors du processus d’inscription. Grâce à l’utilisation d’un moteur de base de données SQL pour permettre des interactions avec son infrastructure, la gestion des données dans Snowflake nécessite une connaissance en SQL, qui bénéficie d’une faible barrière d’entrée, et simplifie les interactions avec la plateforme.
Snowflake dispose également d’une architecture hybride entre les modèles “shared-nothing” et “shared-disk”. D’une part, un dépôt central de données est présent pour les données persistantes, accessible depuis tous les nœuds d’un cluster. D’autre part, Snowflake exécute les demandes soumises en utilisant des clusters de traitement massivement parallèle (MPP pour Massively Parallel Processing), où chaque nœud du cluster stocke une partie de l’ensemble global de données. Ce type d’architecture, breveté par l’entreprise, lie les avantages des deux modèles dans une solution unique.
Les entrepôts virtuels peuvent être redimensionnés à tout moment (même lors de l’exécution de requêtes), modifiés dans le cadre d’une approche multi-cluster pour prendre en charge plus d’utilisateurs simultanément, etc. La maîtrise des compétences nécessaires pour adapter votre infrastructure est facile à acquérir, et est également couverte dans ce tutoriel. Regardons donc ce que Snowflake propose, tout d’abord via son architecture, puis dans un exemple de création d’un espace de travail.
Snowflake, une architecture pour le cloud
Avant tout, il faut se méfier de la confusion entre les terme de Data Warehouse “traditionnel” et d’entrepôt de données : Snowflake est en effet une solution d’entrepôt de données, mais les entrepôts virtuels sont des moteurs de traitement Snowflake pour exécuter des opérations DML (Data Manipulation Language), charger des données et exécuter des requêtes.
Les entrepôts virtuels sont constitués de machines virtuelles, hébergées sur les infrastructures des fournisseurs de cloud computing (AWS, GCP ou Azure), pour supporter la puissance de traitement requise par les utilisateurs de Snowflake. En bref, plus vous souhaitez une vitesse élevée pour le traitement de vos requêtes et le téléchargement de vos données, plus vos entrepôts virtuels doivent être grands.
En ce qui concerne le stockage, Snowflake utilise un stockage en colonnes avec un système de micro-partitionnement, qui contient de 50 Mo à 500 Mo de données non compressées. Les micro-partitions sont dérivées automatiquement, et le regroupement des données est automatique et peut être modifié par l’utilisateur pour permettre une récupération plus rapide des requêtes. Les coûts de stockage et de calcul sont directement sous-traités aux fournisseurs de cloud (AWS, Microsoft Azure ou GCP) choisis lors de l’inscription. Cette approche permet une centralisation des coûts, ce qui améliore la clarté et la transparence.
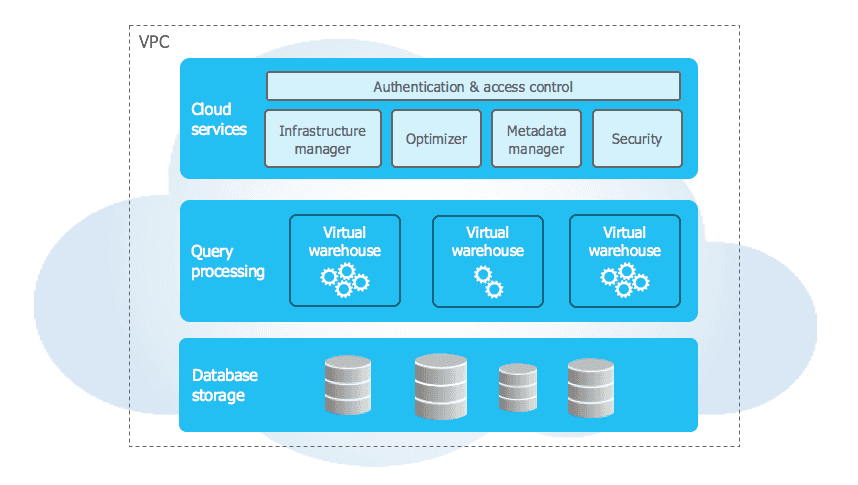
Pour permettre à ces 2 couches (stockage et traitement) de communiquer entre elles, une 3ème couche est présente pour coordonner la mise en place de la plateforme : la couche des services clouds. Elle est responsable, entre autre, de :
- la politique de sécurité (authentification et ACL)
- la politique de provisionnement des machines virtuelles
- la compilation et l’optimisation des requêtes
- la gestion des métadonnées…
Intéragir avec Snowflake
Au niveau de l’utilisation, il est possible d’intéragir avec Snowflake de différente manières. Une interface web est mise à disposition des utilisateurs, ainsi qu’une interface en ligne de commande, nommé SnowSQL. Nous reviendrons, dans le tutoriel, sur la manière d’installer SnowSQL pour différents systèmes d’exploitations.
Compatibilité de la plateforme
Il est possible de transférer des données dans Snowflake de plusieurs manières : via son propre système et un accès au terminal ou via des plateformes de stockage d’object dans le cloud, tel que des buckets S3, Google Cloud Storage et/ou Azure Blob storage. Plus généralement, on trouve également différents connecteurs : JDBC, ODBC, Python, R, Spark, Kafka, Node.js, .Net, Databricks etc.
Au niveau des formats supportés, on retrouve ceux adaptés au traitement du Big Data : CSV, XML, JSON, AVRO, Parquet et ORC.
Snowflake compresse par défault les données importées en gzip. Il est possible de modifier cette configuration avec des compressions en snappy, brotli, bzip2…
Tutoriel sur l’utilisation de Snowflake
Création d’un compte
Il est nécessaire de créer un compte dans le but d’accéder aux services de la plateforme. Le lien précédant vous emmènera sur le site officiel de Snowflake, et vous bénéficierez d’une offre d’essai comportant 400$ de crédits. Vous aurez le choix entre une édition Standard, Premier, Enterprise, ou Business Critical. Dans notre tutorial, nous avons utilisé l’édition Standard. Les autres éditions permettent notamment d’avoir un support plus fourni avec le service client, d’autoriser les warehouses en mode multi-cluster, etc…
Installer SnowSQL
Ce guide a pour vocation d’utiliser l’interface en ligne de commande SnowSQL. Il faut donc l’installer sur votre poste. Installer SnowSQL vous permettra d’intéragir avec les services de Snowflake via un terminal.
Pour MacOS en utilisant Homebrew :
brew cask install snowflake-snowsqlPour Windows :
Télécharger la dernière version de SnowSQL (1.2.5 à l’écriture de cet article) :
curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/windows_x86_64/snowsql-1.2.5-windows_x86_64.msiDouble cliquer directement sur le fichier téléchargé pour l’ouvrir et lancer l’installation.
Pour Linux :
Télécharger la dernière version de SnowSQL (1.2.5 à l’écriture de cet article) :
curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowsql-1.2.5-linux_x86_64.bashAller dans votre dossier Téléchargements et exécuter la commande suivante :
bash snowsql-1.2.5-linux_x86_64.bashSe connecter via SnowSQL
En utilisant les identifiants de connexion reçu lors de la création de son compte, on peut utiliser la commande suivante pour se connecter à son compte via un terminal :
snowsql -a [accountname] -u [username]Ici, accountname aura la forme suivante : accountID.accountregion. Ces informations sont envoyées lors de l’inscription à Snowflake. Exemple : hu67890.eu-central-1 peut être un nom de compte valide.
Il est important de faire attention, lors de l’inscription, au choix du fournisseur cloud et de la région associée. En effet, les entrepôts provisionnés par Snowflake pour le traitement seront implémentés dans la même zone que choisis pour la région. Pour chaque nouvelle région, il est nécessaire de recréer toute l’infrastructure. Des possibilités de réplications de données existent, mais pas de configuration d’une infrastructure déjà existante, notamment warehouse et schéma.
S’identifier en tant qu’administrateur du compte
Une fois connecté, il faut indiquer à Snowflake que l’on souhaite utiliser un rôle avec suffisament de privilèges pour pouvoir créer de nouveaux utilisateurs et leur attribuer les autorisations pour interagir avec la plateforme.
Snowflake propose 4 types de rôles par défault (nous verrons qu’il est possible d’en créer davantages) :
- PUBLIC : rôle donné automatiquement à chaque utilisateur. Si des objets sont attribués à ce rôle, tout les utilisateurs pourront y avoir accès.
- SYSADMIN (Administrateur Système) : rôle qui donne le pouvoir de créer des warehouses, des base de données et d’autre objets.
- SECURITYADMIN (Administrateur Sécurité) : rôle qui donne le droit de créer, mod:ifier et gérer les rôles et utilisateurs de la plateforme.
- ACCOUNTADMIN (Administrateur Compte) : englobe les rôles de SYSADMIN et SECURITYADMIN.
Même si votre compte possède le rôle d’Administrateur du Compte, il est nécessaire de l’indiquer lors de la connexion à Snowflake. Par défaut, l’utilisateur est authentifié comme administrateur système, qui ne donne pas le droit d’autoriser d’autre utilisateurs à créer des base de données, des warehouses…
On utilisera donc la commande suivante (qui peut s’apparenter à un sudo su sur Linux) pour s’authentifier comme administrateur du compte :
use role ACCOUNTADMIN;Créer un warehouse
Comme dit auparavant, les warehouses (et notamment leurs nombres et tailles) constituent la puissance de traitement de la plateforme.
Dans le but de pouvoir mieux contrôler les coûts et séparer l’utilisations des ressources, une bonne pratique consiste à créer un warehouse spécifiquement pour ce nouveau groupe d’utilisateurs.
La commande SQL suivante crée un warehouse qui sera utilisé pour traiter les requêtes ultérieures.
create or replace warehouse "new_wh"
warehouse_size = XSMALL
AUTO_SUSPEND = 180
AUTO_RESUME = TRUE
initially_suspended = TRUE
comment = "warehouse à la disposition des nouveaux utilisateurs";Quelques explications sur les différents arguments :
- warehouse_size : On spécifie la taille du warehouse. On retrouve ici une similarité avec le provisionnement de machines virtuelles sur AWS, GCP ou Microsoft Azure.
- AUTO_SUSPEND : Le paramètre auto_suspend correspond à la durée maximum au bout de laquelle le warehouse sera automatiquement mis en pause si il n’est pas sollicité par un utilisateur. Ici, on spécifie que 180 secondes doivent s’écouler avant que celui-ci ne se mette en veille.
- AUTO_RESUME : Ce paramètre permet d’automatiser la reprise du warehouse lors de l’envoi d’une requête sans avoir à manuellement le relancer. La mise en service d’un warehouse suspendu prend généralement moins de 10 secondes.
Créer une base de donnée
Cette commande va créer une base de donnée pour permettre aux futurs utilisateurs d’y insérer de nouvelles tables et données.
create or replace database "new_db";Créer un schéma
Le schéma est la seconde unité d’architecture de stockage, après la base de donnée. C’est dans le schéma que l’on peut retrouver par exemple les vues, les tables, et les zones de transition relatives à la base de donnée sur laquelle le schéma est lié. Il est également nécessaire d’en créer un pour le nouveau groupe d’utilisateurs.
create or replace schema "new_sch";Créer un rôle
Les rôles sont un maillon essentiel dans l’établissement de la stratégie de sécurité de Snowflake. C’est à un rôle que l’on va attribuer des privilèges, et, dans un second temps, à un utilisateur que l’on va attribuer un rôle.
create or replace role "new_role";Donner les autorisations aux utilisateurs
Désormais, il s’agit de donner des privilèges au rôle fraichement créé pour lui permettre plus tard d’intéragir avec les futures objets générés. Les commandes suivantes permettent de donner des privilèges de modifications de tables, d’utilisation de la base de donnée et du warehouse, et de modification du schéma.
grant all privileges on warehouse "new_wh" to role "new_role";
grant all privileges on database "new_db" to role "new_role";
grant all privileges on future tables in schema "new_db"."new_sch" to role "new_role";
grant all privileges on schema "new_db"."new_sch" to role "new_role";Créer un premier utilisateur
La commande suivante va respectivement créer un nouvel utilisateur, lui assigner un mot de passe ainsi qu’un identifiant de connexion, puis lui attribuer par défault un warehouse, une base de donnée, un schéma et un rôle.
create user "new1"
password = "new123"
LOGIN_NAME = "johndoe"
DEFAULT_WAREHOUSE = "new_wh"
DEFAULT_NAMESPACE = "new_db"."new_sch"
DEFAULT_ROLE = "new_role";Donner un rôle à un utilisateur
Maintenant que l’utilisateur est créé, il faut lui attribuer le rôle que l’on a établit auparavant.
grant role "new_role" to user "new1";C’est terminé ! Vous pouvez maintenant vous déconnecter de votre session et annoncer à votre utilisateur qu’il peut commencer à travailler.
!exitSurveiller l’utilisation des ressources
Une manipulation est à votre disposition pour vous permettre de surveiller l’utilisation de crédits.
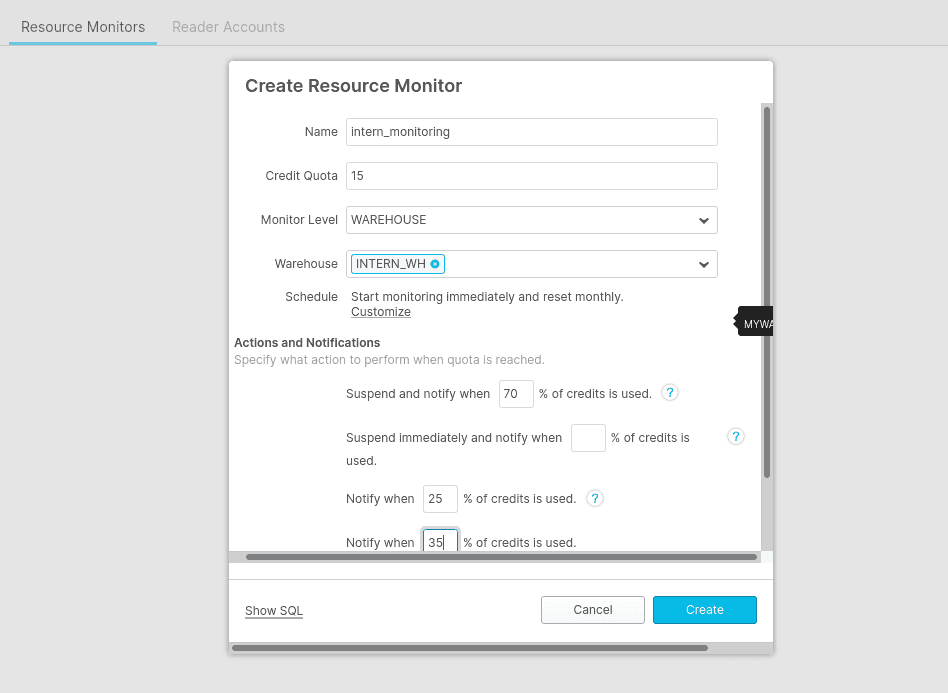
En se connectant via l’interface web à votre compte Snowflake en tant qu’administrateur de compte, il est possible de mettre en place un outil de surveillance sur un warehouse particulier.
En allant dans l’onglet Account puis Ressource Monitors, la définition d’un quota de crédit maximum est paramètrable. Ainsi, on peut configurer qu’à partir d’une certaine utilisation, les entrepôts et requêtes soient interrompus. Voici un exemple simple que vous pouvez configurer :
Télécharger des fichiers et faire sa première requête
Pour commencer à exécuter des nouvelles requêtes, vos nouveaux utilisateurs vont devoir se connecter, créer une nouvelle table, et télécharger des données.
Se connecter via SnowSQL
Le nouvel utilisateur doit ouvrir un nouveau terminal en ayant préalablement installé l’interface en ligne de commande et se connecter. Pour cela, nous prenons l’exemple de l’utilisateur "johndoe", crée auparavant.
snowsql -a [accountname] -u "johndoe"Un mot de passe sera demandé, qui correspond à celui renseigné lors de la création de l’utilisateur. Dans notre cas, le mot de passe est "new123".
Créer une table
Désormais connecté, le nouvel utilisateur peut créer une nouvelle table. Snowflake supporte de nombreux types de structure de donnée présent dans le langage SQL. Il est nécessaire de renseigner les futures colonnes que l’on souhaite intégrer ainsi que leurs types.
create or replace table "new_table"
(name string, age integer);Pour ce cas d’utilisation, nous prendrons comme exemple le fichier nommé new.csv, situé dans /home/bob/. Il se compose de deux colonnes nommées "nom" et "âge" avec des chaînes de caractères aléatoires pour la première et des entiers aléatoires pour la seconde.
Télécharger des données
Pour charger des fichiers dans la zone de stockage intermédiaire, il faut exécuter la commande suivante :
put file://[pathtoyourfile] @"new_db"."new_sch".%"new_table";Dans notre exemple la commande sera :
put file:///home/bob/new.csv @"new_db"."new_sch".%"new_table";Et pour copier de la zone staging à la table, la dernière commande à effectuer est :
copy into "new_table" from @%"new_table"
file_format = (type = csv field_delimiter = ',');Le nouvel employé peut désormais exécuter des requêtes SQL ! Il lui suffira d’écrire directement la requête via SnowSQL, et celle-ci sera exécutée par Snowflake.
Conclusion
Dans cet article, nous avons donc vu la configuration d’un espace de travail Snowflake pour un nouveau groupe d’utilisateur. Le second article de cette série traitera des performances de Snowflake, de leurs moyens de configurations, et de la comparaison de leur exécution.
Comparé à ses pairs, on peut identifier 2 grands axes sur lesquels Snowflake se distingue de ses concurrents :
- La scalabilité de son service :
- L’existance d’un processus de data replication dans une autre AZ (“Availability Zone”) de toute une base de donnée, ou bien de cloner localement une base de donnée déjà existance.
- Un nombre théorique infini d’utilisateurs en concurrence rendu possible grâce à un nombre théorique infini d’entrepôt en parallèle.
- La possibilité de changer la puissance des entrepôts pendant l’exécution de requête, et de multiplier leur nombre via le multi-clustering.
- La facilité d’utilisation :
- installation simple et accès rapide : L’accès à Snowflake est rendu aisé par son mode d’installation. On peut soit y accéder par une interface web, soit en installant une interface en ligne de commande qui ne nécessite aucune autre dépendance. Ainsi, la mise en place d’un utilisateur sur un poste vierge est généralement de l’ordre de quelques minutes.
- pas de configuration d’infrastructure requise : en renseignant un compte AWS, Azure ou GCP lors de l’inscription, tout stockage sera fait automatiquement par Snowflake sur leurs plateformes. Aucun chemin n’a besoin d’être renseigné, aucune machine virtuelle n’a besoin d’être lancée, Snowflake prend en charge le chargement des données via le fournisseur de cloud choisi. Cette centralisation des responsabilité permet à un utilisateur qui aurait peu de compétence en Data Engineering de directement travailler sur des données fraichement ingérée.
- facilité de compréhension pour l’accès aux données : la modification des règles de sécurité peut se faire soit via l’interface web, soit en utilisant une logique ANSI SQL directement dans un worksheet sur le site ou via SnowSQL. Cette simplicité peut donc permettre à une personne ayant des compétences techniques moyennes de configurer lui même la politique d’accès, d’utilisation et de modification d’une base de donnée.
- fonctionne comme un lac de donnée : Snowflake utilise une logique de schema-on-write et non schéma-on-read. C’est à dire que l’on peut charger des données directement dans Snowflake sans renseigner préalablement un schéma. Ainsi, on est dans un cycle ELT (Extract-Load-Transform) plutôt que ETL. Ce choix permet à Snowflake de pouvoir charger une grande variété de données sur lesquelles peu de métadonnées sont disponibles.
Actualité de la plateforme
En février 2020, Snowflake annonce une 8ème levée de fond d’un montant de 479 millions de dollar avec une évaluation à 12,4 milliards de dollars, mené notamment par Salesforce. On comprend mieux l’intérêt qu’on eu certaines sociétés comme IBM, Tibco ou Tableau à développer des connecteurs entre leurs produits et ceux de la “licorne française”.
